

Preventing Cyber Attacks: Why Vulnerability Management Needs Graphs
Discover how graph technology helps cybersecurity teams map connections between vulnerabilities and stop attack paths before they’re exploited.

What's The Role of Graph-Powered IAM Analysis in Cybersecurity
Understand the critical role of graph-powered Identity & Access Management (IAM) analysis in preventing cybersecurity breaches and visualizing complex access rights.

Tracing Cyber Threats Through Fraud and Anomaly Graph Patterns
Learn how graph databases enhance fraud and anomaly detection by uncovering hidden links across accounts, devices, and behaviors.

Why Cyber Threat Intelligence Needs a Graph
From scattered signals to actionable insight, see how graph-powered threat intelligence gives security teams an edge.

How to Build Knowledge Graphs Using AI Agents and Vector Search - Demo Overview
Learn how to turn ambiguous data into a high-quality, disambiguated knowledge graph via an agentic approach using Memgraph’s built-in vector search in this hands-on demo.

With Memgraph Lab 3.3, enters composable GraphChat
Memgraph 3.3 and Lab 3.3 are here! Alongside improvements in high availability, one of the standout features in this release is nested indices—a quite unique addition.

RAG and Why Do You Need a Graph Database in Your Stack?
Why graph databases are key to powering accurate, real-time RAG systems with LLMs and complex, connected data.

Cognee + Memgraph: How To Build An Intelligent Knowledge Graph Using Hacker News Data
Discover how to convert unstructured Hacker News content into structured, searchable insights using Memgraph’s graph database and Cognee’s AI-powered memory engine.

End-to-End Agents over Graphs with Memgraph’s AI Toolkit, LangGraph & MCP
Learn how to u Memgraph’s AI Toolkit with LangGraph and MCP to build agents that think, act, and query over graphs dynamically.

Memgraph AI Toolkit: A Codebase for Graph-Powered Applications
Discover the Memgraph AI Toolkit, an open-source Cypher-first codebase to build graph-powered AI apps using LLM agents, vector search, and GraphRAG techniques.

From Pixels to Knowledge: How We Built Visual Search Using GraphRAG
Discover how Memgraph and EBCONT turned car images into a queryable knowledge graph using a blend of computer vision, vector search, and GraphRAG in this hands-on Community Call demo.

Cypher Generation vs Tool Invocation: Designing Reliable AI for Graph Databases
Cypher generation vs tool invocation: which is better for building reliable graph-based AI assistants? Get the breakdown.

Why Knowledge Graphs Are the Ideal Structure for LLM Personalization
Find out why knowledge graphs are key to personalizing LLMs, improving context, relevance, and real-time insights with GraphRAG.

Vector Search Demo: Turning Unstructured Text into Queryable Knowledge
Discover how to turn unstructured text into a knowledge graph using Memgraph’s vector search in this hands-on demo.

G.V() + Memgraph: Query, Visualize, Explore
Connect Memgraph to G.V() to run Cypher queries, explore graph data visually, and manage your schema easily in one interactive interface.

Fine-Tuning LLMs vs. RAG: How to Solve LLM Limitations
Compare fine-tuning vs. RAG to overcome LLM limitations and make enterprise data accessible, dynamic, and useful.

How We Integrated 15+ Data Sources with Memgraph in a Day Using ChatGPT
Simplify loading your graph database. Learn about Memgraph's new data migration connectors for DuckDB, Spark, Iceberg, S3, and more enterprise sources.

Multi-Tenancy in Graph Databases and Why Should You Care?
Multi-tenancy and why it matters, trade-offs, and how Memgraph handles it without breaking your graph.

Options for Building GraphRAG: Frameworks, Graph Databases, and Tools
Discussing the best tools, databases, and frameworks to build a powerful GraphRAG system with real-time, relevant insights.

How NASA is Using Graph Technology and LLMs to Build a People Knowledge Graph
Missed NASA’s People Graph webinar? Catch the recap and see how graph technology and AI are shaping the future of workforce intelligence.

GraphQL vs REST API: Which is a Natural Fit for Graph Databases?
Explore the key differences between GraphQL and REST APIs and discover why GraphQL is a natural fit for graph databases like Memgraph.

Memgraph Recognised in MarketsandMarkets’ 360Quadrants in the Knowledge Graph Market
Memgraph has been recognised as a Responsive Company in the Knowledge Graph Market by MarketsandMarkets' 360Quadrants. Learn about this achievement, key industry trends, and how Memgraph 3.0 with GraphRAG technology is enhancing AI context capabilities for enterprise applications.

How to build Agentic RAG with Pagerank using LlamaIndex?
Learn how to build Agentic RAG with Pagerank using LlamaIndex.

RAG isn’t dead. It’s just getting started.
Here’s what our CEO thinks about RAG and how it’s changing

How to build multi-agent RAG system with LlamaIndex?
How to build multi-agent system with Memgraph and LlamaIndex.

Introducing KNIME Extension: Low-Code Graph Analysis is here
Learn how to use KNIME with Memgraph to run Cypher queries, build graph models, and analyse connected data using KNIME's low code environment.

Introducing Updated LangChain Integration and Memgraph Toolkit for Agents
We added a support for Memgraph toolkit, to build agentic application with LangGraph and Memgraph.

Why LLMs Need Better Context?
Stop fine-tuning LLMs. Give them real-time, secure context with Memgraph to deliver accurate, personalized answers.

How to build single-agent RAG system with LlamaIndex?
How to build single-agent system with Memgraph and LlamaIndex.

Introducing the Memgraph MCP Server
We're excited to introduce the Memgraph MCP Server, a lightweight server implementation of the Model Context Protocol (MCP) designed to connect Memgraph with LLMs.

LLM Limitations: Why Can’t You Query Your Enterprise Knowledge with Just an LLM?
Why LLMs like ChatGPT can't query enterprise data and how RAG adds context to make them work for your business.

How Do LLMs Work?
How LLMs work, their limits with enterprise data, and why tools like RAG and fine-tuning help fill the gaps.

How To Do GraphRAG with DeepSeek
How FI Consulting built a scalable RAG system with Memgraph and DeepSeek—no GPU overkill, no LLM hallucinations.

GraphChat: How to Ask Questions and Talk to the Data in Your Graph DB?
Query graph data without writing Cypher. GraphChat translates plain English into queries so even non-developers can get answers.

Memgraph Lab 3.0: What’s Changed and What’s Next
Missed our webinar on Memgraph Lab 3.0? Catch up on the key updates—smarter GraphChat, real-time schema, and team collaboration!

How Would Microsoft GraphRAG Work Alongside a Graph Database?
Check out how Hierarchical GraphRAG and Memgraph 3.0 improve knowledge retrieval with Leiden community detection and structured knowledge graphs.

How To Build Agentic GraphRAG?
Ditch rigid GraphRAG pipelines—build an AI-powered agent that picks the right tool for every query. Powered by Memgraph 3.0.

Memgraph’s GraphRAG: Your Shortcut to Personalized GenAI Apps
Build smarter, faster GenAI apps with Memgraph’s GraphRAG. Use LLMs, graph databases, and dynamic algorithms for real-time insights.

Memgraph 3.0 Is Out: Solve the LLM Context Problem
A fast graph database & context engine for GenAI, powering GraphRAG, vector search, and real-time AI-driven insights.

Graph Databases in Energy Management: How Volue Transformed the Power Grid with Memgraph
How Volue optimized power grid management with Memgraph’s real-time graph analytics—faster queries, better insights, smarter energy use.

How To Build Interactive Dashboards to Optimize Efficiency with Memgraph
RJ Visser built interactive dashboards with Memgraph to query linked data and integrate Python tools for efficiency.

Decoding Vector Search: The Secret Sauce Behind Smarter Data Retrieval
How to optimize semantic queries, handle high-dimensional embeddings, and query unstructured data efficiently.
Improved Knowledge Graph Creation with LangChain and LlamaIndex
Improvements to LangChain and LlamaIndex integrations simplify knowledge graph creation and enhance GraphRAG workflows.

TrustGraph and Memgraph: Knowledge Retrieval for Complex Industries
Read how TrustGraph uses chunking, GraphRAG, and Memgraph to tackle unstructured data in complex, regulated industries.

How to Extract Entities and Build a Knowledge Graph with Memgraph and SpaCy
How to extract entities from text with SpaCy, build knowledge graphs in Memgraph, and visualize insights in just a few steps!

Building a Movie Similarity Search Engine with Vector Search in Memgraph
Check out how to use Memgraph vector search to find similar movies by analyzing plot embeddings with a step-by-step guide.

Simplify Data Retrieval with Memgraph’s Vector Search
Read how Memgraph integrates vector search with graph databases for fast, semantic, and similarity-based queries.

Integrating Memgraph with LlamaIndex Building GenAI Apps
Learn how Memgraph and LlamaIndex build smarter GenAI apps by turning unstructured data into dynamic, queryable knowledge graphs.

How Memgraph Uses Skip Lists for Fast Indexes and Unique Constraints
Indexes and uniqueness constraints in Memgraph, a guide to skip list implementation.

Talking to Your Graph Database with LLMs Using GraphChat
Check out how GraphChat lets you talk to your graph database with LLMs, simplifying queries and insights.

Memgraph Lab 101: Simplify Graph Data Exploration with Visualization and Querying
Find out more about Lab for graph data visualization, Cypher queries, and real-time insights for experts and beginners alike.

Using Memgraph for Knowledge-Driven AutoML in Alzheimer’s Research at Cedars-Sinai
How Cedars-Sinai uses Memgraph to enhance AutoML for Alzheimer's research, driving predictive accuracy and drug discovery.

How Precina Health Uses Memgraph and GraphRAG to Revolutionize Type 2 Diabetes Care with Real-Time Insights
Precina Health using GraphRAG to help patients manage Type 2 diabetes at scale, using a mix of real-time data, AI, and personalized care.

Graph Databases for Crime-Fighting: How Memgraph Maps and Analyzes Criminal Networks
How Memgraph's graph database maps and analyzes criminal networks, enabling real-time insights for crime-fighting efforts?

How HIWE IT Leveraged Memgraph for Enhanced Supply Chain Insights
Discover how graph databases improve supply chain management and how HIWE IT uses Memgraph for powerful analytics apps.

Memgraph Snapshots Explained
Learn how Memgraph’s full snapshots and Write-Ahead Logging (WAL) ensure data durability and efficient recovery.

Building High Availability in Memgraph: License Differences
Compare high availability and replication features in Memgraph Community and Enterprise editions for database resilience.

Cypher Differences Between Neo4j and Memgraph
Key differences that developers need to be aware of when migrating between these two graph databases.

Enhancing Static Analyzers with Graph-Based Vulnerability Discovery
Using graph-based techniques with Memgraph to enhance static analyzers for precise vulnerability detection.

What Types of Data Are Supported in Memgraph?
Explore Memgraph's data typed and learn how to use them effectively in your graph database.

How to Optimize Performance with Memgraph Query Plans
Optimize Cypher queries with Memgraph. Learn about query plans, caching, and configurations for better performance.

Migrating a Neo4j Database to Memgraph: A Step-by-Step Guide Using Compare41
Here's how to migrate Neo4j to Memgraph using Compare41.

Memgraph or Neo4j: Analyzing Write Speed Performance
Check out how Memgraph outperforms Neo4j in write speeds with detailed benchmarks and insights on database performance.

Analyzing Lightning Network Payment Channels with Memgraph
Analyzing and optimizing Bitcoin's Lightning Network using Memgraph in real time.

Streamline Graph Database User Management with Memgraph’s SSO Integration
Enhance security and streamline user management with Memgraph's new SSO feature.

How To Build Automation Systems with Digital Twins and Graph Databases
Optimizing building automation with digital twins using Memgraph for real-time monitoring and efficient management.

Memgraph Operational Features Explained
Explore Memgraph's enterprise-ready features: multi-tenancy, high availability, monitoring, and Kubernetes integration.

Memgraph Cypher Implementation: Flexibility and Advanced Traversals
Learn more about the flexibility of Memgraph Cypher implementation with advanced path traversals and custom query modules.

Memgraph Security Features Explained: Authentication, Authorization, Encryption, and Auditing
Deep dive into how Memgraph's security features work to protect your data and ensure compliance.

Integrating Vector and Graph Databases: A Deep Dive into Gen AI and LLMs
Integrate vector and graph databases for AI. We cover semantic search, database optimizations, and future trends.

Memgraph Is Enterprise-Ready
Memgraph is enterprise-ready with multi-tenancy, high availability, security, and advanced monitoring features.

Building GenAI Applications with Memgraph: Easy Integration with GPT and Llama
Integrate LLMs with Memgraph using LangChain for RAG systems and build GenAI applications easily.

Memgraph Powers Sayari's Billion-Node Graph for Global Risk Analysis
How Sayari uses Memgraph for real-time analysis on a billion-node graph for risk analysis.

Migrate from Postgres to Memgraph in Just 15 Minutes with ChatGPT
Check out how our AI-driven approach, using ChatGPT, reduced PostgreSQL to Memgraph migration time to just 15 minutes.

Query Optimization in Memgraph: Best Practices and Common Mistakes
Optimize Memgraph queries. Explore profiling, indexing, and query parameterization for peak graph database performance.

Announcing Memgraph's High Availability Automatic Failover: Developer-Ready
Ensure uptime and performance with Memgraph’s High Availability Automatic Failover, offering resilience and real-time support.

Optimizing Real-Time Payment Authorization with Memgraph
See how Paysure Solutions uses Memgraph for real-time payment authorization, tackling technical challenges and optimizations.
Announcing: Memgraph as a Multi-Tenant Graph Database
Memgraph's new multi-tenancy feature enables isolated, secure, and cost-effective graph database management on a single server.
LLM Throws a Syntax Error Tantrum: Teaching AI to Craft Graph Style Scripts
How LLMs generate custom CSS-like GSS for dynamic graph visualization in Memgraph, training AI to create GSS.

How Microchip Uses Memgraph’s Knowledge Graphs to Optimize LLM Chatbots
Check out how Microchip uses Memgraph's graphs to enhance LLM chatbot accuracy and response quality in real-world use.

Memgraph’s Deep Path Traversal Capabilities
Learn about DFS, BFS, WSP, ASP algorithms, and optimize graph queries for large-scale environments.
Memgraph as a Graph Analytics Engine
Memgraph's in-memory analytical mode for efficient graph data management, optimizing rapid data imports and performance.
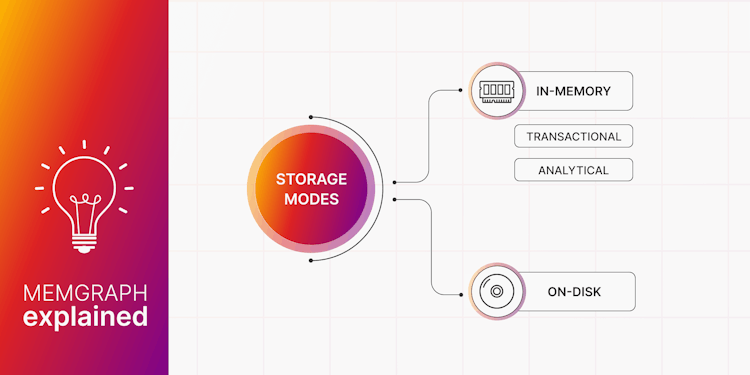
Memgraph Storage Modes Explained
Find out when and why to use Memgraph’s in-memory and on-disk storage mode. Our guide to performance and ACID compliance.

How to Import 1 Million Nodes and Edges per Second Into Memgraph
Read about the most efficient methods for large-scale, high-speed graph data import with minimal resources.

Using LLMs and Graph Database to Boost Community Engagement
Learn how LLMs and graph databases boost community engagement in our webinar with insights from Orbit's Steeve Bete.

Using Graph Algorithms to Enhance Machine Learning for Cyber Threat Detection
Discover how University of West Florida researchers used Memgraph to enhance ML accuracy for detecting cyber threats.

How to Build Secure Multi-Tenant Graphql API on Top of Memgraph
Get a behind-the-scenes look at how Orbit developed a secure and efficient GraphQL API on Memgraph.

Handling Large Graph Datasets
A short guide into the things to consider and optimize when dealing with large graph dataset.
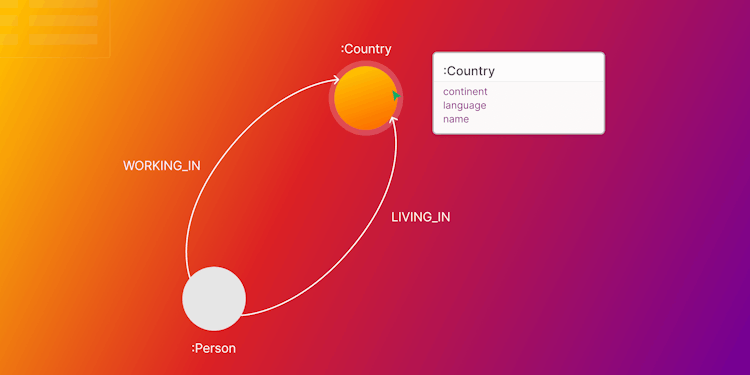
Using Schema Functions to Model Your Data in Memgraph
Discover Memgraph's tools for different schema generation.
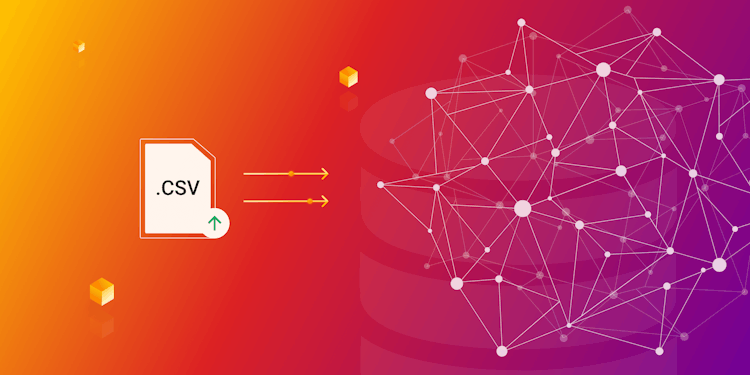
Data Import from Neo4j: Preserving relationships
Learn how to export your data from Neo4j and painlessly import it to Memgraph while preserving relationships

The Complete Cypher Cheat Sheet
Guide on querying Memgraph using the Cypher query language

Memgraph vs. Amazon Neptune: A Graph Database Comparison
Compare Memgraph's high-performance in-memory graph database with Amazon Neptune's cloud-native scalability and RDF support.
Natural Language Querying with Memgraph Lab
Enable natural language querying in Memgraph Lab with LangChain and LLMs, bridging Cypher expertise and AI-driven queries.

Integrating Confluent's Kafka Platform with Memgraph for Efficient Data Management
Integrate Confluent's Kafka with Memgraph for efficient data streaming and real-time IoT data analysis using Docker Compose.

Don’t just ask for a quote - here’s why we should talk first
Getting a quote is easy. But doesn’t paint a full picture. Here are the reasons why jumping on a quick call makes much more sense.
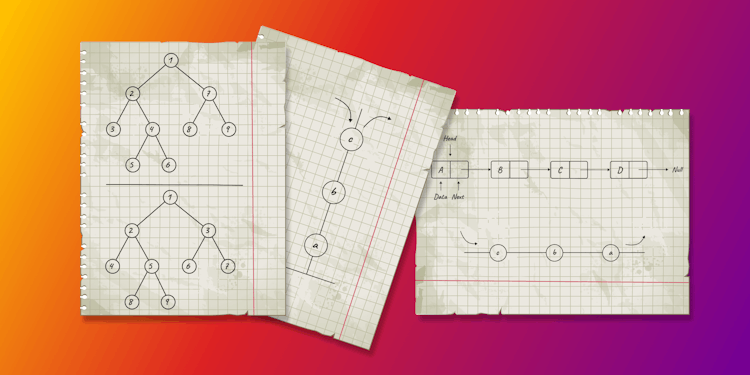
Data Structures Cheat Sheet
Introduction to data structures, offering examples of each structure and illustrating how they could be represented in Memgraph

ArangoDB vs. Memgraph
Compare ArangoDB's multi-model flexibility with Memgraph's in-memory graph performance for real-time analytics and complex queries.

Optimizing Graph Databases through Denormalization
Learn how denormalization boosts query speed and data retrieval in graph databases with large, interconnected datasets.

Neo4j Alternative: What are My Open-source Database Options?
Explore different open-source database options, their technical features and use cases most suitable for your current need

Writing Mutations and Complex Cypher Queries in Memgraph
Exploring how to write complex Cypher queries and mutations in Memgraph to effectively work with graph data

Graph Visualization in Python
Overview of few interesting visualization tools that can be used in Python and guide on how to implement and use them.

Riding the Berlin subway: a Graph Database Adventure with Memgraph Lab
Explore the Berlin subway system using Memgraph Lab, mapping subway stops as nodes and connections as edges in a graph database.

Guide to Transition from Py2neo to GQLAlchemy
Transition from py2neo to Memgraph's GQLAlchemy for enhanced graph database performance and modern Python support.

3 Signs It’s Time to Switch from Neo4j to Memgraph
Explore why transitioning from Neo4j to Memgraph enhances performance, reduces costs, and provides unmatched technical support.

Expert Support and Community Engagement: Memgraph's Commitment to Developer Success
Developer success is crucial in Memgraph and with the help of community channels our developers can enjoy their journey.

Visualizing graphs with Graphistry and Memgraph
Learn how to use Graphistry with Memgraph and visualize your data set.

Apache License 2.0
Explore Apache License 2.0, a permissive open-source license offering flexibility, freedom, and patent protection for developers.

Memgraph and Fiber Cookbook Recipe
Running Memgraph with the Go Fiber web-framework is a powerful combination for building high-performance web applications. Here is a the step-by-step recipe for integrating Memgraph with Go Fiber.

How Does Memgraph Ensure Data Durability?
Persisting data is one of the important features of every database. Stay with us to learn more about the durability theory and how Memgraph turns theory into practice!

Building a Backend for ODIN and RUNE: How to Make a Knowledge Extraction Engine
In this blog post, our very own intern, Patrik, shares his experience creating a backing for a powerful knowledge extraction engine.

From Contribution to Impact: LangChain Docs and Memgraph's LLM Story
In this article, Oleksandr, one of Memgraph’s amazing interns, shares insights on open-source contribution and the story behind Memgraph and LangChain.

Try Memgraph Enterprise for 30 Days: Experience What Memgraph Can do for Your Workload
Learn about advanced features of Memgraph Enterprise, tailored for larger organizations and more complex use cases.

Understanding Database Snapshots
How database snapshots optimize data management by capturing real-time changes efficiently and conserving storage.
RUNE — Our Journey to Creating a GitHub LLM Analytics Tool: Intern’s Perspective
Learn about Oleksandr's perspective on creating a GitHub LLM analytics tool as part of Memgraph's intern program this summer.

Obsidian Note-Taking with ODIN: Intern's Perspective
Explore how ODIN integrates Memgraph with Obsidian to transform note-taking into a dynamic knowledge graph for efficient data management.
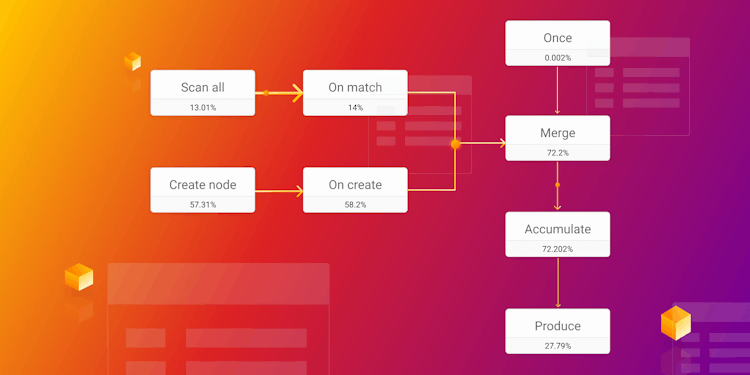
How to Read the Query Execution Plans to Optimize Your Queries
Understand the importance of query execution plans in optimizing your queries for better performance. Learn how to analyze and optimize your paths effectively.

Real-Time Graph Visualization of Bluesky
Read on to learn more about a brand new real-time graph visualization of Bluesky, a new social network for microblogging.

Memgraph vs NebulaGraph
Learn about the main differences between Memgraph and NebulaGraph to choose the one that suits your use case best.

Improve Query Execution Performance
Enhance the speed of query execution with our detailed guide. Optimize your database performance and boost productivity.
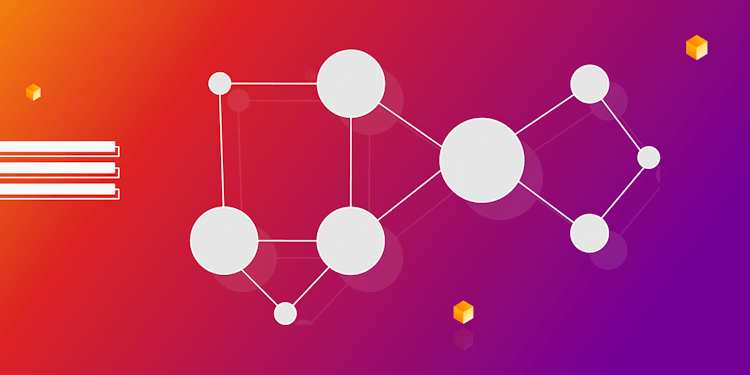
Betweenness Centrality and Other Essential Centrality Measures in Network Analysis
Explore centrality measures in network analysis, including betweenness centrality, to identify key nodes and optimize networks.

In-memory vs. disk-based databases: Why do you need a larger than memory architecture?
Both disk and in-memory databases have their pros and cons and can be used in a variety of applications. This blog offers insights into how larger-than-memory architecture can be used to get the best of both worlds!

Memgraph Helm Chart Kubernetes
Explore the possibilities of Memgraph and Kubernetes with our latest Helm chart repository.

Exciting News: LangChain Now Supports Memgraph!
Discover the exciting synergy of LangChain and Memgraph: An extraordinary integration that introduces an unmatched natural language interface to seamlessly interact with your Memgraph database.

Analyze Supply Chain with Graph Notebook and Memgraph
How to use Graph Notebook with Memgraph in Jupyter notebooks to analyze a supply chain effectively.
Security Analysis with JupiterOne’s Starbase and Memgraph
Learn how to use JupiterOne’s graph-based security analysis tool Starbase with intuitive graph view backed by Memgraph.

Memgraph vs. TigerGraph
Memgraph and TigerGraph are both powerful graph database solutions. This article compares the features, performance, and pricing models between Memgraph vs. Tigergraph to help you choose the right option for your needs.
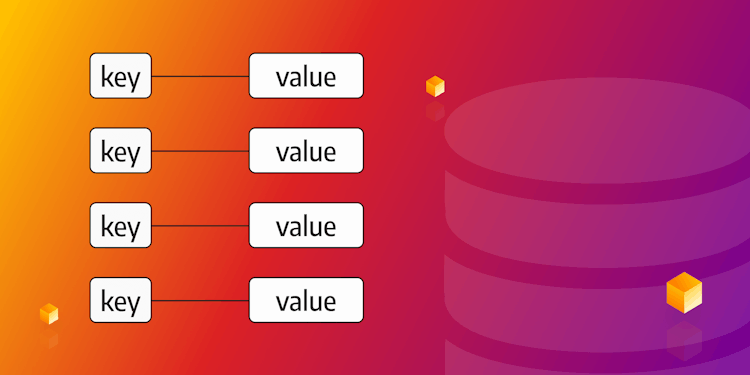
What is a Key-Value Database?
Dive into the world of key-value databases in this comprehensive guide. Uncover the unique characteristics, real-world applications, benefits, and limitations of key-value databases. Ideal for developers, tech founders, and researchers alike.

RedisGraph Alternative: What are my Options when RedisGraph is Dead?
This article delves into the world of graph databases, introducing Memgraph as a robust alternative to RedisGraph. As we dive into Memgraph's remarkable features and strengths, we'll uncover why it has emerged as an enticing option for graph-based applications.
When to Use a NoSQL Database
If you’re unsure when to use a NoSQL database, read this blog post and learn its advantages and disadvantages. Whether you’re a developer, data engineer, or decision maker, this blog post will provide insights into modern databases and how they can boost your projects and organizations.

What is a Graph Database?
Discover the power of graph databases and their role in modern data management. Explore the definition, advantages, and applications of graph databases in this comprehensive article.

Memgraph Community Call: Querying Memgraph through an LLM
Memgraph is preparing new community call and this time with a special guest, Brett Brewer, who will talk about querying Memgraph through an LLM.

From Losses to Savings: How Memgraph Helped Company X Save 7 Figures through Fraud Detection
In this case study, you will learn how the collaboration between Memgraph and Company X yielded impressive results, including a 135% increase in detection efficiency and savings in the seven-figure range.

What is PostgreSQL Database?
PostgreSQL, also known as Postgres, is an open-source relational database management system with a strong reputation for reliability, feature robustness, and performance. It is known for its ability to handle a diverse range of workloads, but what sets it apart from other databases? Uncover the unique advantages of PostgreSQL, explore its core features, and see why it might be the right choice for your next project.

5 Questions on Performance Benchmarks
Memgraph and benchmarking. We focuse on performance impacts of read/write operations, tail latency, and caching.

SQL vs NoSQL Databases
Explore the fundamental differences between SQL and NoSQL databases, get to know their features, advantages, and explore examples in this blog.
ACID Transactions: What’s the Meaning of Isolation Levels for Your Application
How databases ensure data consistency using ACID transactions and the impact of isolation levels on your application.
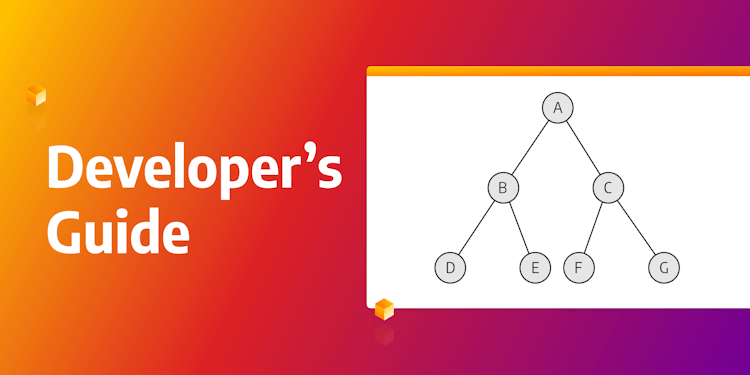
Graph Search Algorithms: Developer's Guide
Explore the foundations of graph search algorithms and learn how to leverage them effectively to unlock new possibilities for solving complex problems and advancing your development skills.

How to Choose a Database for Your Needs?
This article will guide you through all the factors to consider when choosing a database, providing insights into popular database models to help you make an informed decision.
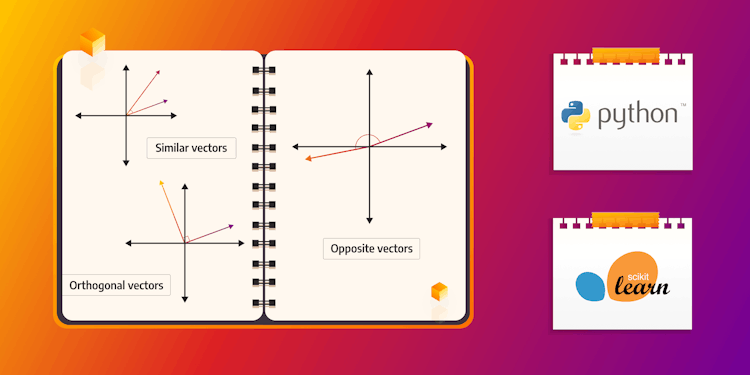
Understanding Cosine Similarity in Python with Scikit-Learn
Learn all about cosine similarity and how to calculate it using mathematical formulas or your favorite programming language. With the help of diverse Python libraries, you'll smoothly enter the world of machine learning, natural language processing, and information retrieval.

Utilizing Parallel Processing in Database Recovery
This blog post explains the nuisances of parallel processing and database recovery, how modern computer architectures can be utilized to better serve the needs of the user in the case of recovery, and how Memgraph specifically deals with this issue.

What is MIT License?
Unravel the terms and conditions of the MIT License, from permission notices to liability clauses, and understand its role in the distribution and modification of MIT licensed code. With the MIT License, developers and organizations alike can navigate the complexities of software distribution while shaping a healthy, collaborative, and inclusive community around their projects.
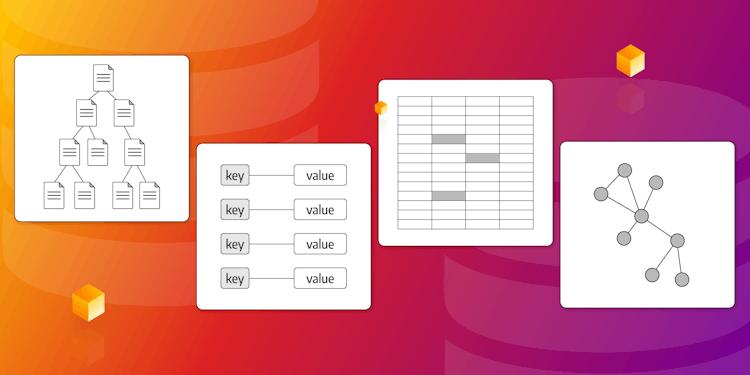
Types of NoSQL Databases: Deep Dive
This is the only deep dive you need to compare different types of NoSQL databases and explore their applications across various industries.
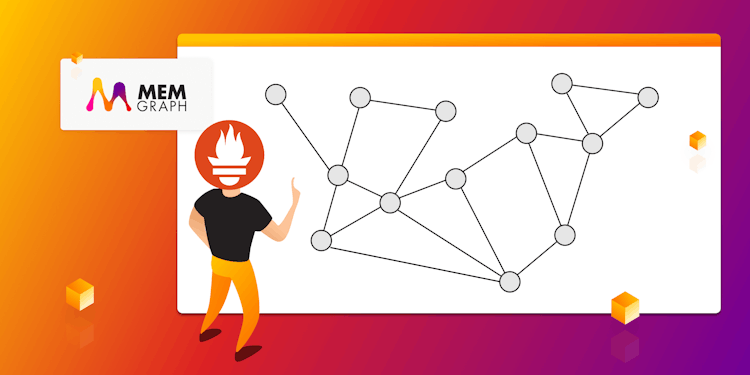
Use Prometheus to Monitor Memgraph’s Performance Metrics
Explore how you can use Prometheus, a time-series database that enables countless applications, to seamlessly monitor and react to performance changes in Memgraph.

Top 7 Graph Algorithm Books You Should Know About
How to find credible sources to help you learn more about graphs and apply them to your use case? Save these 7 graph algorithm books and e-resources in the bonus section.
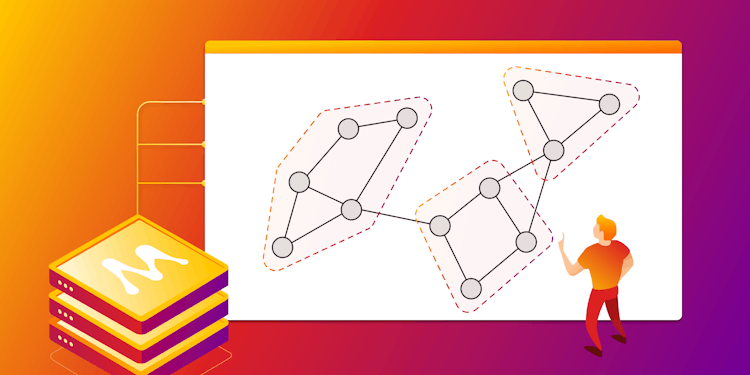
Graph Clustering Algorithms: Usage and Comparison
From social networks and biological systems to recommendation engines, graph clustering algorithms enable data scientists to gain insights and make informed decisions that create value.

Memgraph and Graphlytic Joined Forces to Offer Real-Time Visualization
Graphlytic has introduced support for Memgraph DB and Memgraph Cloud which enables seamless connectivity between your Memgraph instance and any Graphlytic installation.

DB-Engines Ranking: Top Graph Databases You Should Use
Choose wisely! The right graph database can make or break your project. Discover how DB-Engines rescues developers from regretful decisions.

Nuix and Linkurious join Memgraph on the Gartner Data & Analytics Summit!
Meet the three companies at the Summit and dive into the Integrated Link Analysis for unstructured data powered by AI, NLP and Graph Analytics.

Neo4j vs Memgraph - How to Choose a Graph Database?
In this article, we will compare two leading graph databases, Memgraph and Neo4j graph database, to help you choose the best platform for your needs.

Boosting Cybersecurity Defenses with Graph Technology
Improve cybersecurity with Saporo and Memgraph, achieving 10x faster performance and 2x quicker migration for attack surface management.

Graph Database vs Relational Database
Discover the differences between relational and graph databases, their respective characteristics, features, and applications. This article also delves into Cypher and SQL query languages, various data modeling techniques, and differences in performance.

Introduction to Streaming Databases
A streaming database is a real-time data repository specifically designed to store, accumulate, process and enhance a data stream.
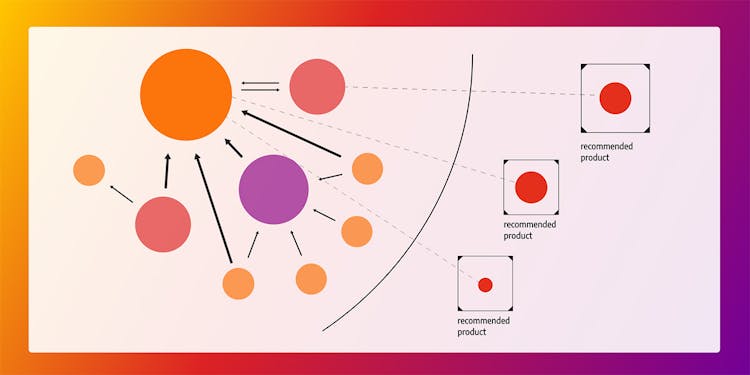
Five Recommendation Algorithms No Recommendation Engine Is Whole Without
How many recommendation algorithms do you need for a successful recommendation engine? Start with these five and we'll recommend you more!

Top 10 Streaming Analytics Tools
Learn how to pick the best streaming analytics tool for your use case

How to Query Your Database with ChatGPT: Memgraph Edition
Learn how to generate a data model for the popular TV show Money Heist, import the data, and query the database using ChatGPT.

Memgraph and Linkurious Partner to Provide Advanced Graph Visualization
Exciting news! Memgraph, the super-fast open-source graph database for streaming and a Neo4j alternative, is partnering with Linkurious, the expert in graph visualization and analytics solutions.
Benchgraph Backstory: The Untapped Potential
Optimize your Memgraph configuration with Benchgraph for actionable performance insights and enhanced efficiency.

History of Open-Source Licenses: What License to Choose?
Read on to learn about how open-source licenses emerged and which license to choose for your project.

What is an Open-Source License?
An open-source license is a legal agreement that allows users to access, use, modify, and distribute software or source code freely. This article explores the different types of licenses and their implications for developers.

Introduction to Benchgraph and its Architecture
Why Benchgraph? Developing and maintaining a product is a never-ending phase. And proper performance testing is necessary to maintain database performance characteristics during its whole lifecycle. To ensure the consistency of Memgraph’s performance, we’re introducing Memgraph's in-house benchmarking tool.
Improve Load CSV
LOAD CSV is a Cypher clause used for importing data from CSV file format. The clause reads row by row from a CSV file, binds the contents of the parsed row to the variable you specified, and populates the database if it is empty or appends new data to an existing dataset.

Why password encryption matters
One of the fundamental ways of securing online accounts and digital assets is using strong passwords. However, even the strongest passwords can be compromised if they are not properly encrypted and stored. So, how does password encryption work?

Disabling multi-version concurrency control for faster import: Analytics mode
Memgraph 2.7 now supports another storage mode, which enables you to work on data inside a database without ACID compliance. Once you understand how multiversion concurrency control works in Memgraph, you will also figure out why it can prevent you from importing data faster.
Choosing the optimal index with limited information
Developing a solution that will make the database select an optimal index is a challenging task, since there is incomplete information available. That is why it always boils down to a bunch of estimations. Find out what estimations Memgraph’s query engine uses as default, and how to make the engine to be even more precise.

In-Memory Databases That Work Great With Python
An in-memory database is a database that is kept in the main memory (RAM) of a computer and controlled by an in-memory database management system. When analyzing information in an in-memory database, only the RAM is used.

What Is Real-Time Graph Analytics?
Real-time graph analytics combines streaming data technology, graph databases, and graph algorithms to tackle problems not suited for relational databases and batch processing.

PageRank Algorithm for Graph Databases
What is PageRank algorithm? How can it be used in various graph database use cases? How to use it in Memgraph? If these questions are keeping you up at night, here is a blog post that will finally put your mind at ease.
Identify Patterns and Anomalies With Community Detection Graph Algorithm
Get valuable insights into the world of community detection algorithms and their various applications in solving real-world problems in a wide range of use cases. By exploring the underlying structure of networks, patterns and anomalies, community detection algorithms can help you improve the efficiency and effectiveness of your systems and processes
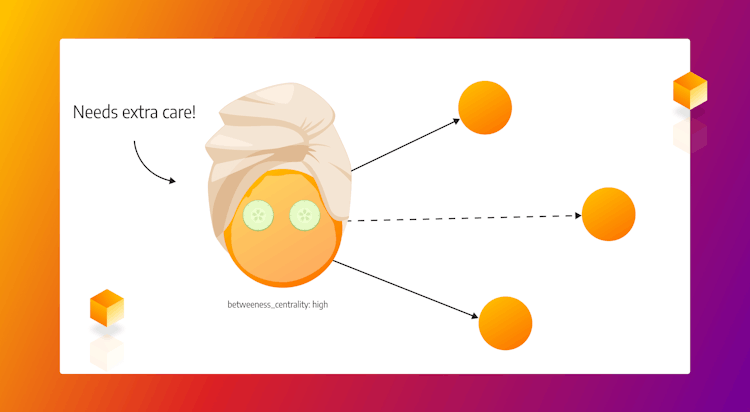
Why Are Nodes With a High Betweenness Centrality Score High Maintenance
Betweenness centrality is one of many measures you can get from performing a centrality analysis of your data. It identifies important entities in your network that are actually a vulnerability and can bring your processes to a standstill. Dive deeper into this important metric and how it can be used in various use cases.

How I Found The Most Influential Users on Hacker News
Hacker News is a website that contains content from the tech industry and to find yourself among its most popular posters sometimes seems a miracle! To break the mystery around it, I tried to knowledge-hack it with Kafka and PageRank algorithm - read on to find out what I discovered!

Synchronize Data Between Memgraph Graph Database and Elasticsearch
If you need to reap the benefits of both a graph database and Elasticsearch, the new module in Memgraph’s graph library MAGE enables you to easily synchronize those two components using triggers.

Breaking the Limits of Traditional Cyber Threat Detection with Memgraph
Optimize cybersecurity with Memgraph, high-performance graph database for efficient threat analysis and scalable data management.

Efficient Threat Detection in Cybersecurity with Memgraph
People tend to update versions of their code project dependencies without inspecting security impacts on their code. In this article, we use Memgraph to analyze Python package vulnerabilities when updating dependencies and provide you with a performant solution using known and reported vulnerabilities.

Stay Ahead of Cyber Threats with Graph Databases
With the rising number of cyber-attacks followed by the massive digitalization of companies, the right tool is needed to maximize performance and prevent further attacks from happening. We explain why graph databases offer a perfect choice in cybersecurity use cases and why they make your business more secure.

CIDR 2023 Database Conference from Memgraph’s Perspective
The Conference on Innovative Data Systems Research (CIDR) is a systems-oriented conference organized every two years since 2003. Check out what interesting people, talks and papers made Memgraph’s CTO Marko excited about the future of graphs.
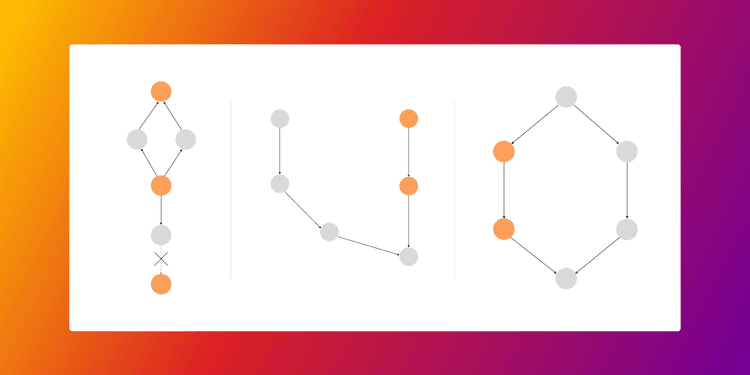
3 Powerful Queries to Find Patterns in Your Knowledge Graph You Haven’t Noticed Before
Learn how knowledge graphs and pattern matching in Memgraph can uncover hidden insights, optimize data, and detect fraud.
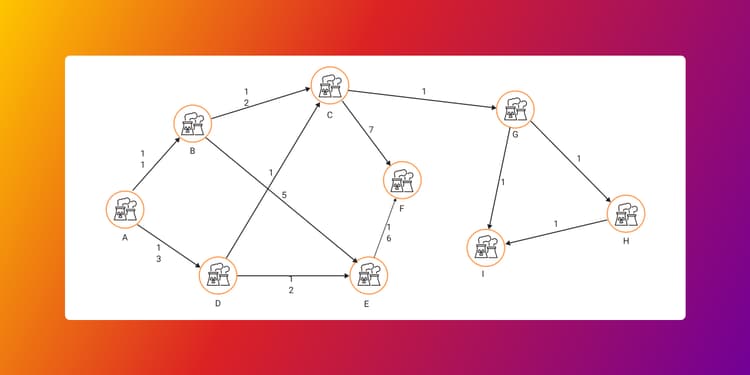
Perform What-if Analysis of Your Network Directly in Storage Without Compromising Data Integrity
Find out how you can minimize decision-making risks when dealing with networks by using Memgraph as the one-and-only tool for a complete analysis.

How Much Money Will You Spend on Hosting a Database
Little by little, the hosting cost of a graph database can turn out to be quite substantial. Hosting costs are highly correlated with how much resources a database uses, which is not as straightforward as you might think. Find out how expensive it is to host Memgraph and Neo4j instances and why.
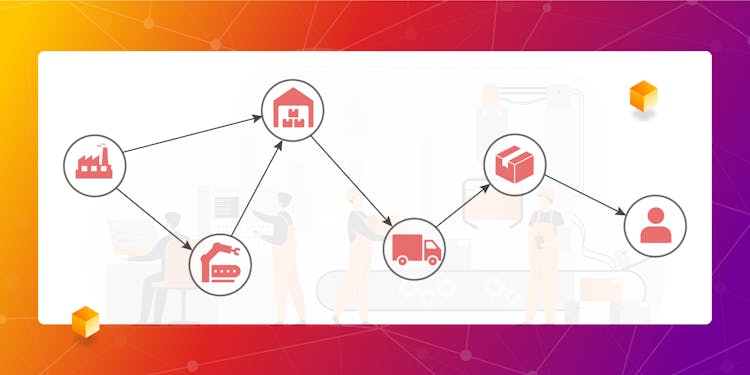
Optimize and Manage Supply Chain Network With Memgraph
Optimizing a supply chain network can get really messy if you can’t identify dependant products, correctly schedule processes and find critical points in the pipeline. With Memgraph, you can accelerate your supply chain pipeline and build a complete analysis tool to increase the shipments of your goods.
Get a Feature-Rich Open-Source Community Edition Graph Database Ready for Production
Compare Memgraph and Neo4j to find the best open-source graph database for your needs. Discover key features and differences.

Make Smarter Decisions Analyzing a Knowledge Graph Built With Memgraph
Making decisions that point your business in the right direction is much easier with knowledge graphs. But, to create a knowledge graph, you need to gather all the data scattered in different silos, analyze the current connections between data points and discover new connections. It’s a complex task, but graph databases, such as Memgraph, make it a manageable one.

Graph Data Zagreb 7 Report
Read about our seventh Graph Data Zagreb meetup and what topics were covered.

How to Choose a Graph Database for Your Real-Time Application
Building real-time analytical applications require capable infrastructure. Picking the right software infrastructure components can take time and effort. When it comes to graph databases, find out why Memgraph is a fast and powerful real-time graph database.
Perform Fast Network Analysis on Real-Time Data With Memgraph
As networks consist of highly connected data, with Memgraph’s in-memory storage you can analyze network topologies quickly to gain insights from static or real-time data. Discover critical points in the network or component dependencies, optimize resources and run what-if scenarios, then present those findings visually to extract every last bit of information.

4 Reasons Why Graph Tech Is Great for Knowledge Graphs
Use graph databases to unify dispersed data, enhance real-time analysis, and scale efficiently with dynamic algorithms.

New Memgraph Platform for Another Year of High Performance Graph Analysis
Start next year with a whole new range of features and graph algorithms to gain insights that will make it a happy year indeed! Developed features include improved security, benchmark tests, projected graph visualization, better code suggestion support, C++ API, node classification and link prediction, to name just a few.

Learn Graph Analytics With Python
With the Introduction to graph analytics with Python course, you will learn all about graphs and how to analyze them. Check out the overview of the graph analytics tools landscape and engaging examples to find out how to use the most powerful network analysis Python tools.
Graphs Databases Are the Future for Network Resource Optimization
Although networks are an easy concepts to understand, they are poorly managed in many various industries. Learn how graphs can help scale your network topologies and draw conclusions crucial for your business

Inferring Knowledge From Unused Siloed Stores Using Graphs
A lot of companies today have massive amounts of siloed data just sitting there and not being used. No information or knowledge was gained, and no conclusions were made. For the data to be useful, it needs to be interconnected and shaped into a knowledge graph that will produce value for the company. Read how graphs can help!
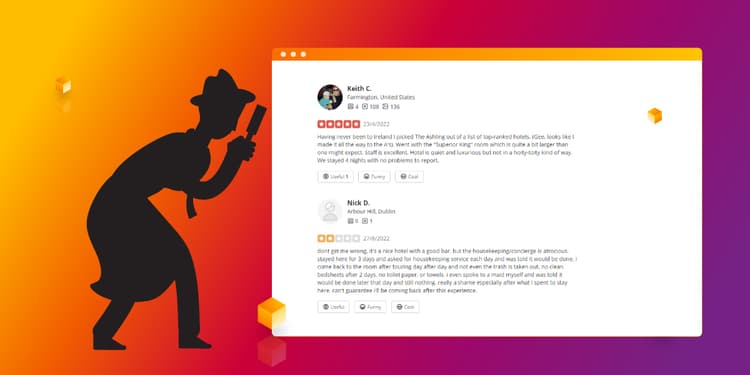
Become an Inspector for a Day and Detect Fraudsters With Graph ML on Memgraph!
How Graph Machine Learning and Memgraph can solve fraud detection using Node Classification on real datasets.

Run Link Prediction or Node Classification Algorithms and Write Custom Procedures in C++ With Mage 1.4
The new version of Memgraph’s open-source graph extension library, MAGE, now supports node classification and link prediction algorithms. Install the new version of MAGE if you would like to write custom algorithms faster by using the C++ API, need the igraph algorithms or k-means clustering.
A Hyperparametrization Is All You Need - Building a Recommendation System for Telecommunication Packages Using Graph Neural Networks
Explore GNNs, build a link prediction module, and create a recommendation system using Memgraph's MAGE library.

Why You Should Automate Mapping Data Lineage With Streams
Data lineage helps you make informed decisions that reduce costs, streamline operations and power innovation. Discover how stream tech helps with automatically mapping data lineage, and learn how Memgraph integrates with event streaming platforms.
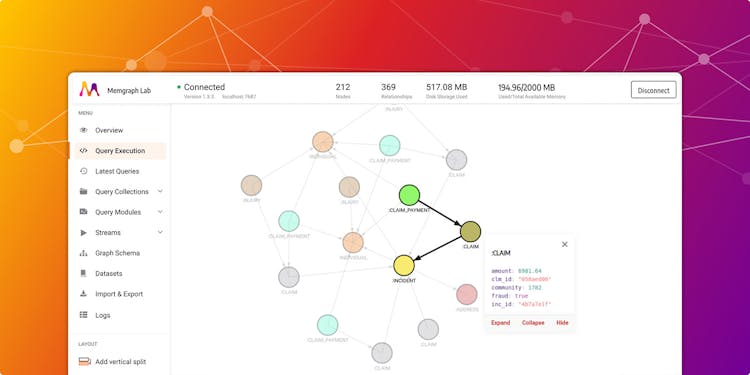
How to Visualize Connections in Insurance Data
Check out how Memgraph handles the visualization of complex graph structures found in insurance data that will allow you to comprehend and synthesize large amounts of new information more efficiently.
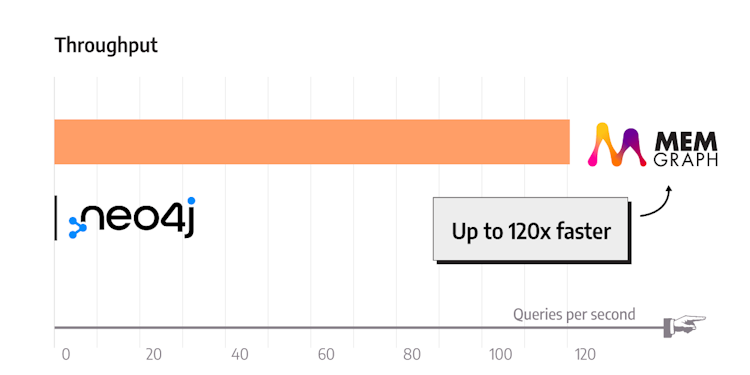
Memgraph vs. Neo4j: A Performance Comparison
Memgraph delivers results up to 120 times faster than Neo4j while consuming one quarter of the memory!

Manage All Your Data Lineage Needs With Memgraph Graph Analytics
The data lineage graph is the single source of truth about your organization’s data. Discover how Memgraph can competently handle this use case with its optimized architecture, power data insights and connect to other software.
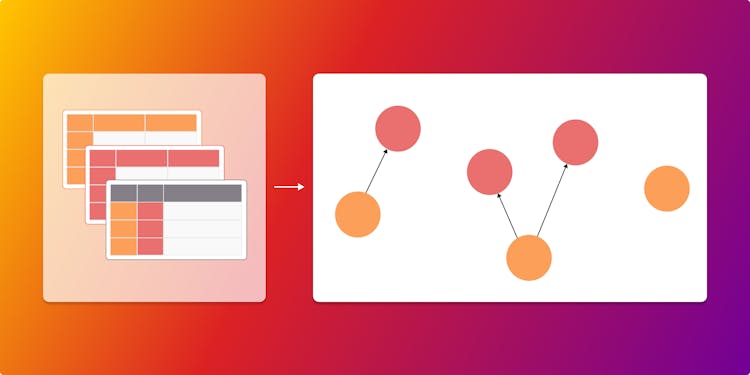
How to Model Insurance Data as a Graph
Find out how to organize data into a graph. Model vehicle insurance claims, incidents, policies and more while preserving the interconnected nature of individual insurance cases.
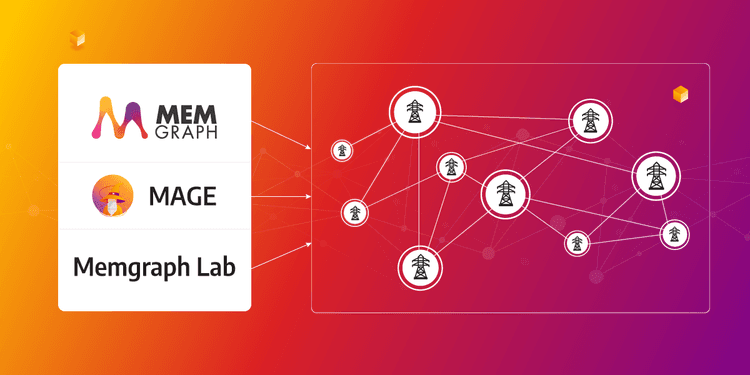
Most Common Problems in Energy Management Systems Solved With Graph Analytics
For every problem in the energy management system, there is a graph algorithm that can point you in the right direction! Here is an overview of the most useful graph algorithms for highlighting weak links, high-risk nodes and many more.

Graph Databases and PHP & Vaccine Distribution With Graphs
Join a number of graph enthusiasts on the last Graph Data Zagreb meetup in 2022.!

Recommendation Engines Faster Than Ever With Memgraph
It’s true every recommendation engine requires a performant database to analyze the data and provide the recommendation, but why exactly does Memgraph stand out? Easy - C++, in-memory, real-time analytics! Three things to change the recommendation game.

What Makes Memgraph Great for Real-Time Performance in IAM Systems
Find vulnerabilities and security issues, or perform any other data analysis in your Identity and Access Management system with Memgraph, and ensure you are running a smooth operation.

Why Should You Use Memgraph When Dealing With the Power Grid and Energy Topologies
If you require an energy management system that is scalable, fault-tolerant, and performant, Memgraph is the go-to solution! Analyze highly connected power grids or gas pipelines to make meaningful decisions and improve the impact on your business, the people and the environment around you.

Benefits Graph Databases Bring to Identity and Access Management
Improve IAM with graph databases for faster data traversal, dynamic vulnerability analysis, and scalable, flexible access management.

The Easiest Path to GDPR Compliance for Enterprises is the Graph Path
The GDPR has placed high demands on organizations doing business in the European Union, mainly focused on how personal data is collected and processed. However, this does not mean it can’t be business as usual again. Find out why graph databases are the best way to achieve GDPR compliance and how they get it done.
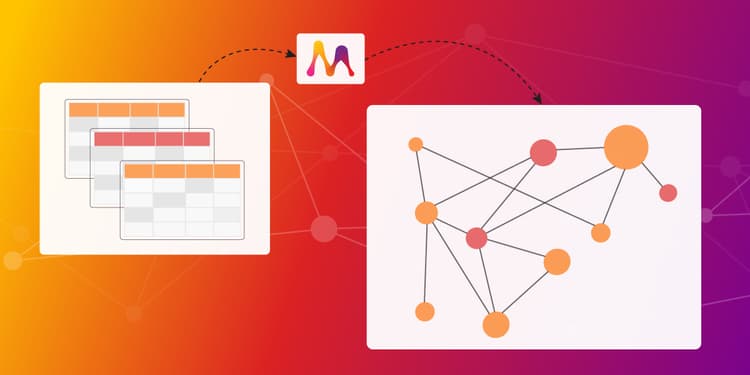
Embark on the Fraud Detection Journey by Importing Data Into Memgraph With Python
Are you reluctant to switch from a relational database to a graph databases to explore fraud because you believe you first need to be proficient in Cypher to correctly import the data? Be rest assured - there is a Python-friendly approach available within Memgraph!

In the Spotlight - Antonio Filipovic
Antonio, also known as Fico, joined Memgraph almost three years ago! He started as a student in the Cloud team, but his career path changed as his interest increased. Without further ado, let’s get straight to the point and find out more about Fico’s background, career path, and role in the interview below.
How Can Companies Meet Energy Management Demands in the New Era - A Graph Approach
With power being the most powerful asset, it’s still managed by inadequate tools and systems based on tabular data. Good for aggregations and mathematical operations but terrible for actually managing large-scale, highly connected dynamic systems. Luckily, graphs can regain control over energy systems and topologies, and help save millions.
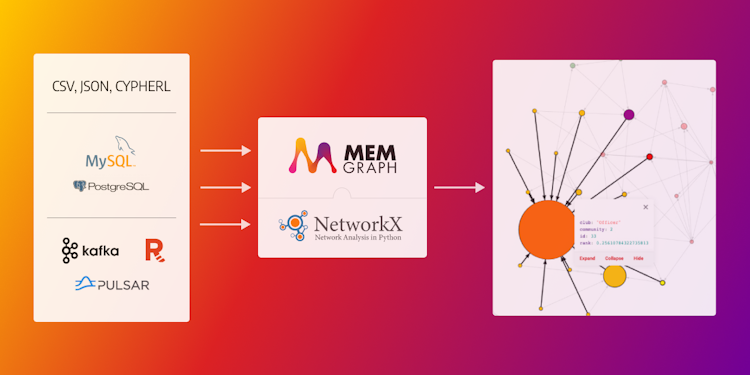
NetworkX Developers, Say Farewell to the Boilerplate Code
If you are spending more time writing code to develop, deploy and manage your graph projects, it’s time you tried Memgraph. It will allow you to focus on the data analysis and free you from all that time-consuming coding.

Three Reasons How Graph Databases Can Enhance the Insurance Industry
If your data is trapped inside tables and you can’t seem to get satisfying answers to questions that would enhance your business, it’s time to switch to graph databases. Here are three main reasons why!

How Graphs Solve Two Biggest Problems of Traditional IAM Systems
The world has changed a lot in the past couple of years, and it’s no different for business organizations. More and more businesses no longer have strict hierarchical organizations and people often change teams and projects they work on and resources they need. It is no wonder that if the IAM systems also don’t change, they will no longer be helpful in supporting the organization. Switching to graphs presents a change the IAM systems desperately need.
Better Data Management: Get Solutions by Analyzing the Data Lineage Graph
Optimize your data infrastructure with Memgraph's dynamic graph analytics, ensuring reliable, scalable data lineage management.

Who Ranks Better? Memgraph vs NetworkX PageRank
Are your NetworkX algorithms taking even more and more time to produce the results you need to finish up your research? Or the application reached a critical point and its starting to lag due to increase in data analysis? Could Memgraph tackle the same computations in less time? I think you probably know the answer is “Doh!” but here are the numbers to prove it.

Why Are SQL Databases Outdated for the Real-Time Recommendation Engines
If a recommendation engine built on relational databases is falling a part due to the bottlenecks made by complex JOINs and never-ending schema changes, there is only one permanent and game changing solution - graph databases.

Join the Dots: Data Lineage Is a Graph Problem. Here’s Why!
Complex JOINs necessary for tracking data lineage with relational DBs drag down the speed of analyzing and visualizing the lineage and pinpointing issues and solutions. That is why graph technology is perfect to model and manage data lineage! Not convinced? Read the post to find out more.
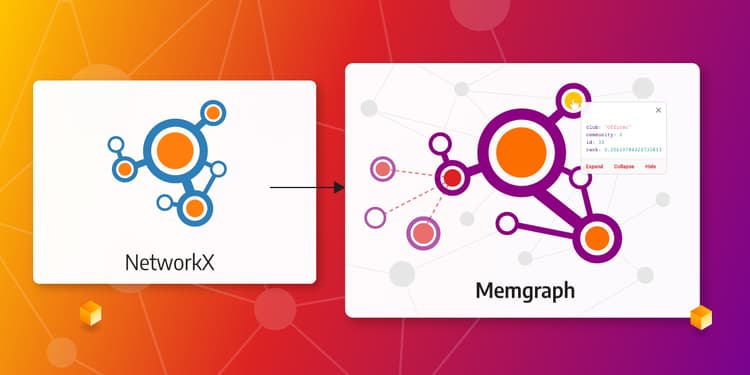
Data Persistency, Large-Scale Data Analytics and Visualizations - Biggest Networkx Challenges
When NetworkX can no longer handle the analysis and vizualisation requirements of your project, and you are tired of constantly reloading data, find out how you can utilize Memgraph to get your graph data analysis back on track.

Why Should You Combine Machine Learning and Graph Tech to Build Your Fraud Detection System?
Sometimes choosing graphs solutions isn’t the only step you can take to mitigate risks. In case fraudsters foolishly think they can outsmart an analytics team, they probably haven’t come across their new best friend - fraud detection systems enhanced with machine learning models.

How to Upgrade an Antiquated Identity and Access Management System
There are a couple of steps to follow to move off of your antiquated IAM system and make it more effective. Here is a to-do list to make it a smooth transition.
Meet the Team: DX
Have you ever wondered who writes all the technical documentation here at Memgraph or who’s answering questions and helping developers through Discord and Stack Overflow? Read more to find out.

Lost in Documentation? Let Our Docs Recommendation System Guide You Along!
DRS is a web application that helps to navigate through documentation by giving you page recommendations based on your input URL.
Modeling the Data: A Key Step in Using a Graph Database
Did you ever fall down some bottomless pit of bad data modeling? Our inter Adrian sure did, but he learned a lot from it - how to recognize the pitfalls and how to avoid them in the future! Hope his experience helps you… but let’s be honest, we never really learn from other people’s mistakes, so if you fall be sure to yell for help!

Build C++ Graph Analytics Without Worrying About Memory
Accelerate graph analytics with Memgraph's MAGE library, featuring a new C++ API for high-performance custom queries and modules.

Not Even ‘Remotely’ Challenging - Sasa’s Onboarding Experience
We want to introduce you to Sasa, a frontend engineer on the Platform team responsible for developing and designing Memgraph Lab. In this blog post, Sasa talks about his onboarding experience and how he got his socks knocked off during the technical interview.

Memgraph v2.4 is Live
Summer has been a busy time for us. This rainy but extensive release of Memgraph brings you four significant features that are bound to make your life easier. As always, there are also bug fixes and smaller but nice improvements to avoid painful debugging moments as much as possible.
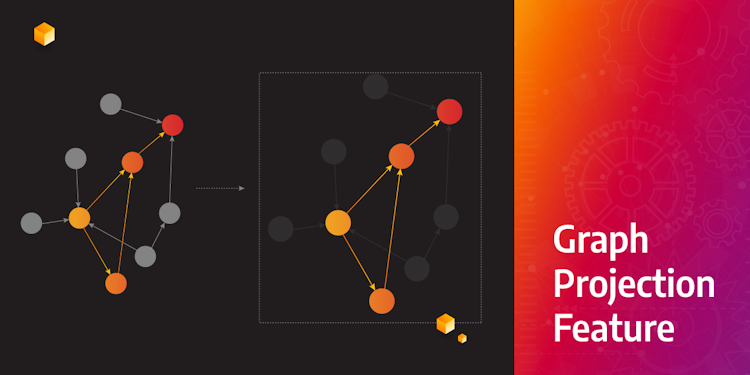
How We Designed and Implemented Graph Projection Feature
In recent months, users started to ask more frequently about the ability to run algorithms on a subgraph, and we in Memgraph listen to what our users need. Read more in this post How we designed and implemented graph projection feature
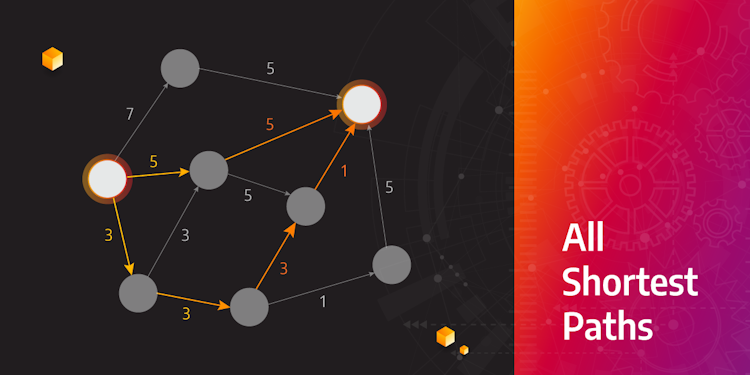
How to Find All Weighted Shortest Paths Between Nodes and Do It Fast
Our journey of creating an optimized shortest paths algorithm that returns all paths of same length. Starting from a MAGE query module and working within Memgraph's core, here is what we learned.

An Inside Look at Memgraph's Summer Internship
Discover what six summer interns learned and achieved during their time with us in Memgraph.
Label-Based Access Control in Memgraph - Securing First Class Graph Citizens
Security is playing a big role in the era of big data. To comply with the modern standards of privacy and compliance, we upgraded our security system to be able to authorize the graph on the node and relationship level. Find out how we did it here!

How to Build a Graph Visualization Engine and Why You Shouldn’t
Sometimes in life, you have to roll up your sleeves and do the dirty work yourself. It's exhausting but pays off big time. That's exactly how it felt to build a visualization engine from scratch and then watch with what speed and elegance it renders complex graph structures. So if you are thinking about building a visualization engine, stop right there... we already did it! Pay attention!

How We Integrated Custom CSS-Like Language to Style Graphs
Are you tired of bland-looking graphs with limited relationship and node styles? Do you need some color and pictures in your graph life? So did we, until we created Graph Style Script! Now our graphs are bursting with life, and so can yours! What is GSS and how to use it, read this blog post to find out!
Visualize Graphs in the Browser With Just a Few Lines of the New Orb Code
Orb is an open-source library developed by Memgraph you can use to visualize graphs by adding just a few lines to your frontend code. This blog post will show you all the cool features Orb offers and how to implement them in your project. Or don't and have slow and appalling graph visualizations - it's your choice. Seriously, use it... it's very easy and fun!

You Want a Fast, Easy-To-Use, and Popular Graph Visualization Tool? Pick Two!
You can't always get what you want, but if you try sometimes, well, you might find, you get what you need. We took The Rolling Stones' advice and tried really hard to find the visualization tool that we need... It didn't really turn out as we wanted, or needed, but at least we had fun testing some software.

Data Lineage and Memgraph Internship Projects
Another Graph Data Zagreb is behind us. This time we had two conversations. In the first part, Manta gave us presentation about Data Lineage, and in the second part students who had their summer internships at Memgraph showcased the projects they worked on.

MAGE - A Homage to the Team and the Magic
If you’re familiar with Memgraph or just started exploring its products, you must have heard about MAGE. But how did it all start, who came up with the idea, and who are the masterminds behind the product? Read more in this post!

How to Work With GitHub
The world of version control is getting more interesting each day. Learn what Git, GitHub, and GitHubCLI have in common and master version control!

Track Data Lineage With a Graph Database
The summer break is over and we’re back in action - it’s time for our 6th Graph Data Zagreb Meetup! This time we are having two talks: Track Data Lineage With a Graph Database + Memgraph Internship Projects.

Re-Treat Yo’Self!
Four days of summer, sea, company alignment, and fun pretty much sums up our second company retreat. We brought all of our employees together and spent a few amazing days both in Zagreb and on the island of Mali Losinj.
Ship It on ARM64! Or Is It AARCH64?
How to build docker images for multiple architectures

Summer Internship 2022 Kick-off
We kicked off this year’s summer internship with a meetup at our Zagreb office. Six amazing students from PMF and FER are eager to start this summer and gain real-work experience.

Graph Data Zagreb Meetup Season Finale Ends With AstraZeneca
A deep dive into Drug Discovery with Biomedical Knowledge Graphs by AstraZeneca ends the Spring season of Graph Data Zagreb.
Predicting Drug Interactions in Pharma With ChemicalX Integration
Industry leaders in the drug discovery and development area use graph technology. Here’s why

Memgraph Turns 6 - This Is Our Journey!
On the occasion of Memgraph 6th birthday, Founders Dominik and Marko made a video about their Memgraph journey while visiting San Francisco.

Honest Review - Memgraph
We are super excited to share a real honest review of Memgraph with you! The review was created by Ashleigh Faith, a data scientist and researcher, and she hosted our DevRel Engineers, Katarina Šupe and Ivan Despot.

Develop Faster and Smarter by Uncovering Insights Lying Low Inside Your Data Streams - Welcome Memgraph Cloud and Lab!
Dive into the new, in browser capabilities that Memgraph Lab and Cloud unlock when analyzing your data streams in the graph domain.

How to Analyze a Streaming Dataset of Movie Ratings Using Custom Query Modules?
Movie ratings from MovieLens are incoming, but you are still not sure what to watch over the weekend? Create your own movie recommendation system.

How to Analyze and Explore the World of Real-Time NFTS?
Analyze the Art Blocks transaction data, projects and communities in real-time with Memgraph

How to Analyze Commits in a GitHub Social Network in Real-Time?
Always wanted to identify the most influential developer within your GitHub network? Check out how by using PageRank.

How to Build a Real-Time Book Recommendation System on Amazon Books Dataset?
Recommending books is hard. Thanks to the Amazon books dataset and insights from graph analytics, you can build your own. Here’s how.

Graph Data Zagreb 5 - Accelerating Drug Discovery With a Biomedical Knowledge Graph
We have a special guest, Michaël Ughetto, a graph data scientist from AstraZeneca. Michaël will discuss how AstraZeneca ingests data sources in the Biological Insights Knowledge Graph (BIKG) and distribute it to data scientists and domain experts.

Graph Data Zagreb 4 Report - Bitcoin & Blockchain Burgers
Read about our fourth Graph Data Zagreb meetup and what topics were covered.

Using In-Memory Databases in Data Science
In-memory databases primarily rely on RAM storage instead of using hard or external disks for memory storage. Let’s take a look at how in-memory databases work along with some use cases in data science.

How to Orchestrate Your Graph Application With Docker Compose
Learn what is Docker Compose and how it can help you in the application development process.

Best Python Packages (Tools) For Knowledge Graphs
Top Python libraries for building and optimizing Knowledge Graphs, including Pykg2vec, PyKEEN, AmpliGraph connectivity.

Graph Database Query Languages You Should Try
Query languages used for graph data management are called graph query languages (GQLs). Below are the popular graphDB query languages that provide a way to unpack information in graphs. Let’s dive into the details of popular query languages with their pros and cons.

Graph Data Zagreb 4 “Unchained - How to Transform Bitcoin Blockchain Into a Graph”
Memgraph is organizing its fourth Graph Data Zagreb Meetup. The topic of our next meetup is “How to Transform Bitcoin Blockchain Into a Graph!”

Why So Slow? Using Profilers to Pinpoint the Reasons of Performance Degradation
Using profilers can be tricky, but by understanding and combining them you can pinpoint the bottleneck in your application. In this article you can read about how we combined Callgrind and gperftools to investigate the significant slowdown after rewriting our Bolt server.

What Do Game of Thrones, Star Wars and Tasty Burgers Have in Common? Read in Our Graph Data Zagreb Report!
Last week, at WESPA Spaces, on May 4, 2022, Memgraph held its the third edition of Graph Data Zagreb meetup for over 60 participants. Katarina Šupe, developer relations engineer created an excellent presentation for graph enthusiasts and Game of Thrones fans.

Announcing Memgraph 2.3 - Connect to Other Applications Stacks Fast
Load custom functions, Bolt over WebSocket implementation and FOREACH clause introduction will allow even easier development.

WASM All Things - A Tour of the WebAssembly Ecosystem
The second part of the series deep dives into the WebAssembly ecosystem. Compilers, build systems and more!

WASM to the Moon - Introducing the Very First WASM Based Client
The last part of the series introduces the very first Memgraph WASM client jsmgclient.

Memgraph, Client Adapters and WebAssembly. What?
In the first part of the series, Kostas explores the idea of introducing WASM based clients for Memgraph.

In the Spotlight - Kostas Kyrimis
Meet Kostas - a passionate C++ engineer from Greece who joined the Core team more than a year ago
Temporal Graph Neural Networks With Pytorch - How to Create a Simple Recommendation Engine on an Amazon Dataset
Build a graph recommendation engine using Temporal Graph Neural Networks (TGNs) for label classification and link prediction.

Game of Graphs - Graph Analytics on a GoT Dataset
Memgraph is organizing its third Graph Data Zagreb meetup. Join us to discuss the latest topics in the world of graphs.
Analyze Infrastructure Networks With Dynamic Betweenness Centrality
Online algorithms are key for rapid response to changes in streamed graph data

MAGE 1.2 - Meet Temporal Graph Networks and Dynamic Graph Analytics
MAGE 1.2 - Full package of dynamic graph algorithms
![How to Benchmark Memgraph [or Neo4j] with Benchgraph?](/_next/image?url=%2Fimages%2Fblog%2Fbenchmark-memgraph-or-neo4J-with-benchgraph%2Fcover.png&w=750&q=75)
How to Benchmark Memgraph [or Neo4j] with Benchgraph?
Simplify benchmarking with Benchgraph for custom workloads, performance insights, and comparisons on Memgraph or Neo4j.

How to Make Your Code More Secure?
Read about our second Graph Data Zagreb meetup and what topics were covered.

Announcing GQLAlchemy 1.2 - Developing Python Applications With Graph Databases
Say hello to GQLAlchemy 1.2, a Python OGM (Object Graph Mapper) that helps you work with graph databases.

How to Use GQLAlchemy Query Builder?
Through this guide, you will learn how to use different query builder methods to create, change, get, set, and remove data from Memgraph.
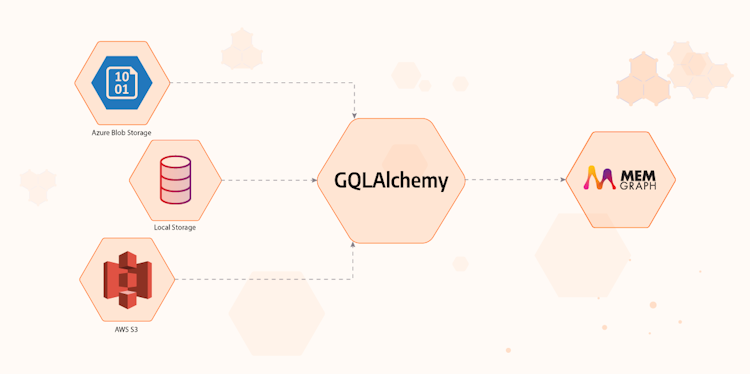
Importing Table Data Into a Graph Database With GQLAlchemy
Through this short tutorial, you will learn how to import table data from files stored in local or online storage systems to a Memgraph graph database using GQLAlchemy
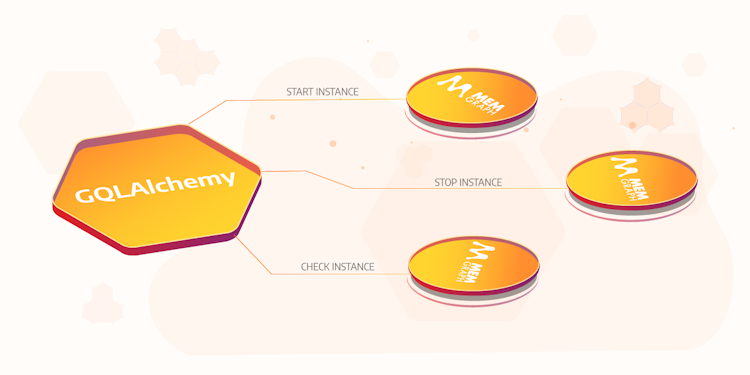
How to Manage Memgraph Docker Instances in Python
Through this guide, you will learn how to start, stop, connect to and monitor Memgraph instances with GQLAlchemy.

Come Meet Memgraph's DevRel Team in Amsterdam
Memgraph is coming to Amsterdam! Our DevRel team, Katarina and Ivan are visiting Amsterdam to present at some exciting meetup groups.

In the Spotlight - Benjamin Antal
Meet Benjamin - our only Netherlands' based software engineer who joined the Core team exactly one year ago

Exploring a Twitter Network With Memgraph in a Jupyter Notebook
Through this short tutorial, you will learn how to install Memgraph, connect to it from a Jupyter Notebook and perform data analysis using graph algorithms.

Detecting GitHub Repository Vulnerabilities With Graph Databases
Memgraph is organizing its second Graph Data Zagreb meetup, where you can discuss the latest topics in areas such as graph databases, graph processing, graph analytics, and graph theory.
How to Migrate From Neo4j to Memgraph
Learn how to migrate a dataset from Neo4j to Memgraph using CSV files.

Applications of the 20 Most Popular Graph Algorithms
This article will explore 20 of the most common graph algorithms and various ways to use them in real-life scenarios.

We Held the First Graph Data Zagreb Meetup!
Read about our first Graph Data Zagreb meetup and what topics were covered.

The Memgraph Onboarding Guide - Welcome Aboard!
Find out more about the onboarding process in Memgraph.

Graph Use Cases in Chemical Industry
Real-time process optimization and supply chain scheduling are just some of the use cases for graph technology in the chemical industry. Read more about graph use cases in the production of industrial chemicals and how Memgraph helps.

Graph Algorithms Cheat Sheet For Coding Interviews
When applying for developer roles, the interviewer might ask you to solve coding problems during technical interviews. This article will help you understand some of the most fundamental ones like BFS, DFS and Dijkstra's algorithm.
Use-Cases of the Shortest Path Algorithm
In today’s era of highly developed information systems, one of the key tasks is to seek out the shortest path in the network – from the beginning point to the endpoint.

Exploring the European Gas Pipeline Network With Graph Analytics
Analyzing the European energy crisis and dependency on Russian natural gas imports

Announcing Memgraph 2.2
Memgraph 2.2 is here! Welcome, Apple M1 and WebSocket!

Performance Management at Memgraph or How We Achieved Growth in the Pandemic Period
If you are interested in how performance management cycles improve Memgraph''s overall success, this blog post is for you.

Cypher Email Course Is Back!
Learn the Cypher query language through our simple and informative 10 day email course

Best Databases for Streaming Analytics
Choose the best streaming database for real-time analytics: Amazon Kinesis, Memgraph, Apache Storm, Apache Kafka, or StreamSQL.
19 Graph Algorithms You Can Use Right Now
The fastest to run any graph algorithm on your data is by using Memgraph and MAGE. It’s super easy. Download Memgraph, import your data, pick one of the most popular graph algorithms, and start crunching the numbers.

Team Core - Take a Look Inside the Team Behind Memgraph’s Engine
Did you ever wonder how databases are built and what’s going on in the background of everything you see? We asked Memgraph’s Core team to give us a glimpse into their everyday processes and experiences.

Advent of Code 2021 or Why Did Memgraph Engineers and CEO Wake Up at 5 AM to Solve Coding Puzzles?
how Memgraph engineers sharpened their coding skills and bonded during the Advent of Code 2021 challenge.

Hello, Graph World! Meet Graph Data Zagreb
Memgraph is organizing the Graph Data Zagreb meetup, where you can discuss the latest topics in areas such as graph databases, graph processing, graph analytics, and graph theory.

Introduction to Stream Processing
Stream processing is a type of big data architecture in which the data is analyzed in real-time

Batch Processing vs Stream Processing
Learn the key differences between batch and stream processing, their use cases, and when to use each approach.

Announcing GQLAlchemy 1.1
Say hello to GQLAlchemy 1.1, a Python OGM (Object Graph Mapper) that helps you work with graph databases.
Building Robust Applications Using GQLAlchemy
Learn how to build applications from bottom to top with the help of GQLAlchemy.
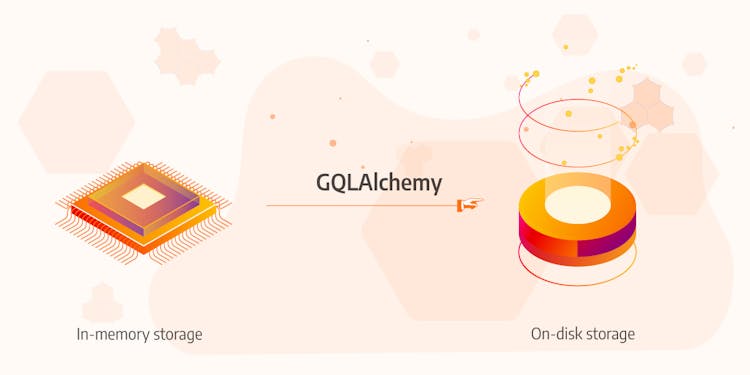
Using on Disk Storage With an In-Memory Graph Database
Choose to store python objects partially into an in-memory Graph Database and into an SQLite database on disk.

Streaming and Trigger Support With GQLAlchemy
Learn how to use the GQLAlchemy library to manage data streams and database triggers in Memgraph

Guide to Real-Time Analytics
Learn more about the benefits of real-time analytics and how they allow you to get key insights almost instantaneously.

The Benefits of Working for Memgraph - A Happier, Healthier Work-Life
From health insurance to home office budget - take a look at some of the benefits we offer to our employees
Real-Time Visualization With React and D3.js
Learn how to receive real-time data with WebSocket from Flask server using React on the client side and draw updates with D3.js

Mutimir 2021 - A Conference for Young Academic and Industrial Researchers
We attended the annual Mutimir conference organized by Penkala to learn about exciting research opportunities and meet Croatia's young scientists.

42 Graph Articles to Read on 2021 Holidays
Explore graph-related articles on algorithms, streaming data, and applications—perfect for holiday reading and learning.

What Remote Work Means in Memgraph
Remote, Work from home, or Hybrid - what does it all mean in Memgraph?

Announcing MAGE 1.1
MAGE 1.1 - Applying Graph Magic to Stream processing

Monitoring a Dynamic Contact Network With Online Community Detection
Explore rumor spreading in a contact network as it changes through time with online community detection

It's the Most Wonderful Time of the Year - Dynamic PageRank and a Twitter Network
Explore a network of retweets using a dynamic PageRank algorithm and a graph database
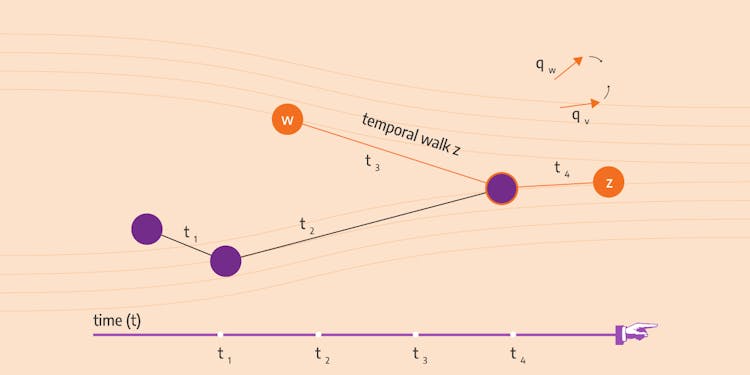
Understanding How Dynamic node2vec Works on Streaming Data
An in-depth guide to understanding the dynamic node2vec algorithm and its advantages over static algorithms on streaming data
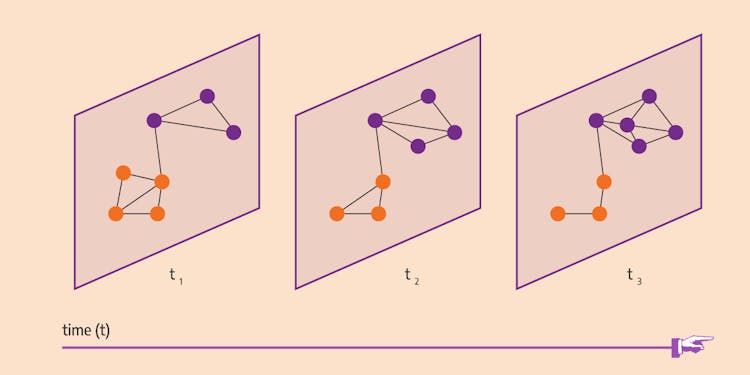
LabelRankT – Community Detection in Dynamic Environment
Discover how to detect communities in dynamic networks quickly with LabelRankT

Link Prediction With node2vec in Physics Collaboration Network
A guide to understanding how link prediction works with node2vec algorithm
Dynamic PageRank on Streaming Data
Learn the theory behind how to deal with streaming graph data by using Dynamic PageRank
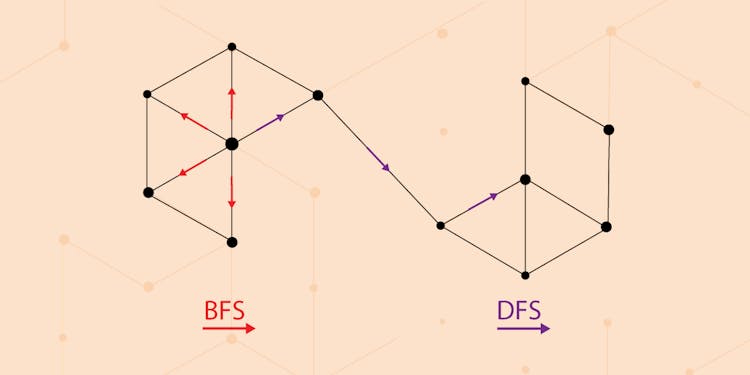
How Node2Vec Works – A Random Walk-Based Node Embedding Method
Learn about a graph-based embedding technique for mapping nodes into a low-dimensional space
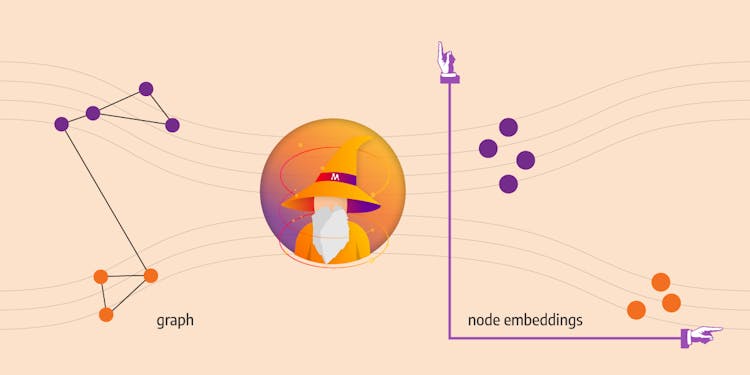
Introduction to Node Embedding
Find out what node embeddings are, how to generate them and where they can be used

Connect to a Pulsar Cluster and Analyze Streaming NFT Data With Memgraph
Learn how to connect to a Pulsar cluster, create an Art Blocks NFT database in Memgraph and analyze streaming sales

Apache Pulsar vs Apache Kafka - How to Choose a Data Streaming Platform
A basic overview of the architecture and features offered by Apache Pulsar and Apache Kafka

Analyzing Real-Time Movie Reviews With Redpanda and Memgraph
Through this tutorial, you will learn how to connect to a Redpanda stream from Memgraph and analyze the graph data

Chasing Messages and Offsets in the Land of librdkafka
A short story about working with librdkafka

Announcing Memgraph 2.1
Memgraph 2.1 is here! Welcome, Pulsar and Redpanda!

How to Identify Essential Proteins Using Betweenness Centrality
A step-by-step tutorial on how to identify essential proteins in protein-protein interaction networks using graph analytics

Identifying Essential Proteins Using Betweenness Centrality & Memgraph MAGE
A step-by-step tutorial on how to identify essential proteins in protein-protein interaction networks using graph analytics
How to Build a Graph Web Application With Python, Flask, Docker & Memgraph - Part 1
Through this tutorial, you will learn how to create a basic Flask server, Dockerize an app and connect to Memgraph

Recommendation System Using Online Node2Vec With Memgraph MAGE
Learn how to create a real-time recommendation engine with the Online Node2Vec embedding algorithm

From Solutions to Core Team - Meet Jure Bajic
I sat down with Jure Bajic, our Core Software Engineer to gain a deeper understanding of the process of changing teams, what he values at work and in Memgraph. author: Martina Dominkovic
How to Use Memgraph With Python and Jupyter Notebooks
Through this tutorial, you will learn how to work with Memgraph from a Python script or a Jupyter Notebook

Twitch Streaming Graph Analysis - Part 3
Learn how to get Twitch data, find the most interesting statistics from the Twitch network and visualize the output of different MAGE algorithms on ingested data in real-time

How We Got Our Ducks in a Row - Memgraph Company Retreat 2021
The whole company went together on a 4-day retreat, and this is what it looked like

Join the Memgraph App Challenge and Create Something Awesome
Join the Challenge and create graph solutions for awesome rewards!

The Memgraph App Challenge - Stream, Graph & Build
Join the Challenge and create graph solutions for awsome rewards!

Twitch Streaming Graph Analysis - Part 2
Learn how to get Twitch data, find the most interesting statistics from the Twitch network and visualize the output of different MAGE algorithms on ingested data in real-time

Twitch Streaming Graph Analysis - Part 1
Learn how to scrape Twitch data, find the most interesting statistics from the Twitch network and visualize the output of different graph algorithms

How to Build a Spotify Recommendation Engine Using Kafka and Memgraph
Check out what it takes to develop a recommendation engine with graph analytics

Hacktoberfest 2021 - Join the Festivities!
Join the annual Hacktoberfest and contribute to open source projects
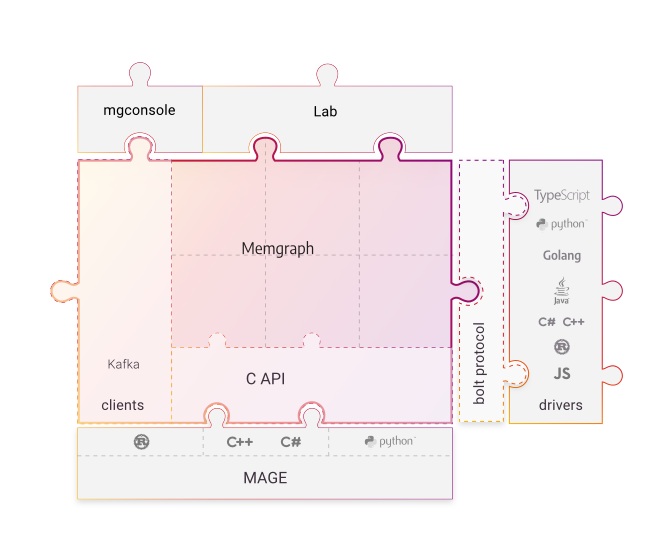
Memgraph Platform - What Is Under the Hood?
Find out how Memgraph works under the hood

Announcing Memgraph 2.0
Memgraph 2.0 is here! We are finally source available and ready to tame your streams.

High-Performance Graph Applications for Every Developer
We’re launching Memgraph to bring the power of Graph Applications to every developer
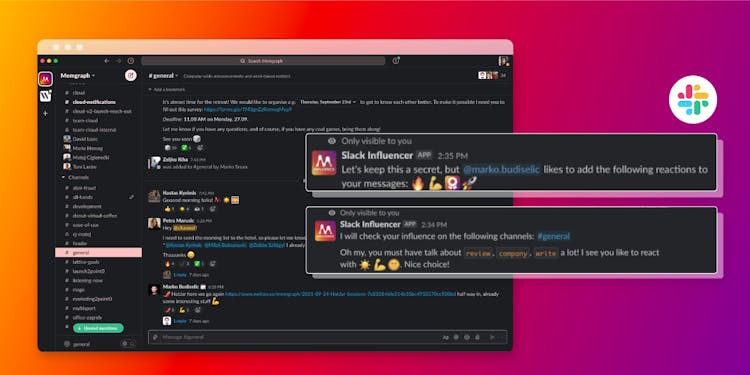
Analyzing Interactions in a Slack Communication Network
We created a Slack Bot that measures a user's influence and activity in a Slack workspace
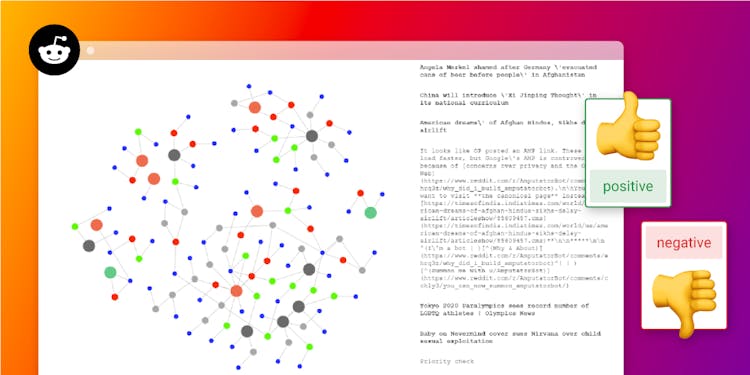
Visualizing and Analyzing Reddit in Real-Time With Kafka and Memgraph
Learn how to ingest Reddit data, visualize it as a graph and perform sentiment analysis.
How We Stay Connected In a Remote World
How we overcame the hurdles of working remotely

The Benefits of Graph Analytics - How Various Industries Can Utilize Network Analysis
Network analysis is rapidly gaining popularity throughout different industries. Find out why!

The Cypher Query Language - Best Practices
Learn how to write well structured and easily understandable Cypher queries
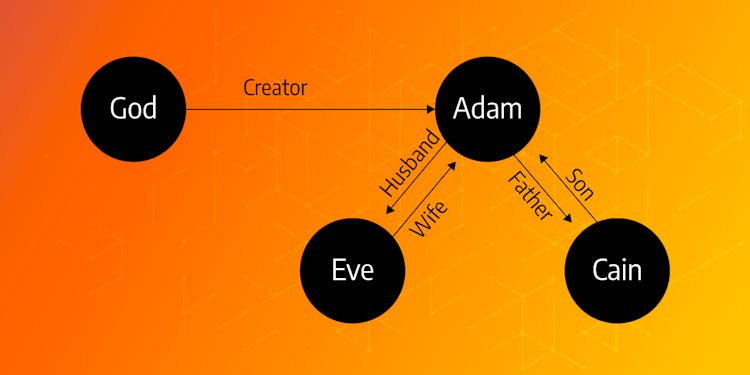
Exploring Interpersonal Relationships in the Bible
Learn how to visualize family trees and work with live data using Memgraph and Cypher

The Overflowing Timeout Error - A Debugging Journey in Memgraph!
A simple error often turns into a full-fledged developer journey when you're trying to find the best solution

Announcing Memgraph 1.6 - It's Time for Data Streaming!
Memgraph now includes a few more cool features such as Kafka connections and new isolation levels

Memgraph’s First Hackathon
The engineering team behind Memgraph spent a week developing some pretty cool apps with the power of graph analytics.

Memgraph Summer Internship - What We Did Last Year?
Take a look at how Memgraph organized a fully remote summer internship for its newest graph aficionados.

Announcing Memgraph Cloud 2.0
We are proud to announce the public launch of Memgraph Cloud 2.0. With a brand new UI, exciting new features, and simple pricing, building real-time graph applications has never been easier!

Diving Into the Vehicle Routing Problem
Learn more about the Vehicle Routing Problem on real-world examples and new approaches

MAGE Got One More Wizard Called Rust
An overview of the newly added Rust query modules support

Influencers Among Computer Scientists
Explore the world of science influencers whose papers are the most cited publications in the world of computer science

Learn the Cypher Query Language in 10 Days
Learn the Cypher query language through our simple and informative 10 day email course

How to Become a GQLAlchemist?
Use the GQLAlchemy library for easier and more intuitive interactions with Memgraph in Python"

Announcing the Memgraph 1.5 Release
Memgraph is back and trigger-happy!

Join Memgraph on the Microsoft Build Conference
Memgraph is participating in the Microsoft Build 2021 conference!

Analyzing the Eurovision Song Contest With Graphs
Analyzing Eurovision Song Contest results from 1975 to 2019 with graph analytics

BitClout - Who Are Content Creators Supported By? (Visualizing HODLers)
Analyze the BitClout network to find out which content creators have the most supporters and are worth investing in

Join Memgraph on the RockPaperStartups Conference!
Memgraph is participating in the RockPaperStartups 2021 conference!

Building a BitClout Social Network Visualization App With Memgraph and D3.js
Learn how to develop a simple application for visualizing and analyzing the BitClout social network using Memgraph, Python, and use D3.js.

Optimizing Telco Networks With Graph Coloring & Memgraph MAGE
In this tutorial, you will learn about the code assignment problem in telecommunication networks and how to solve it in a simple yet effective way using graph algorithms and Memgraph.

The Benefits of Using a Graph Database Instead of SQL
Learn about the benefits of using a graph database instead of SQL in terms of data modeling, querying, and development speed and flexibility.
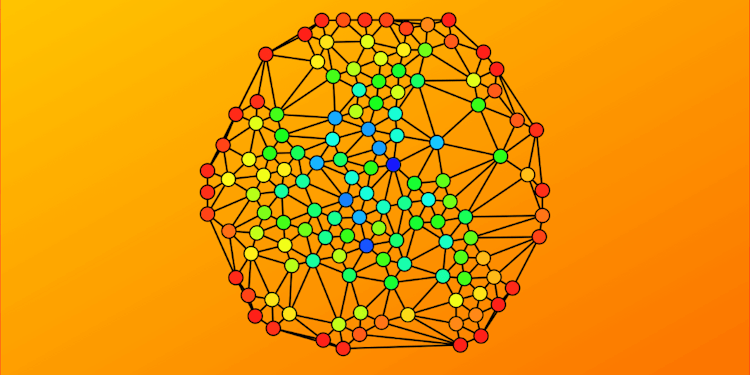
Running Community Detection With Memgraph and Python NetworkX
Learn how to productionize your NetworkX algorithms with Memgraph using Cypher procedures and query modules.
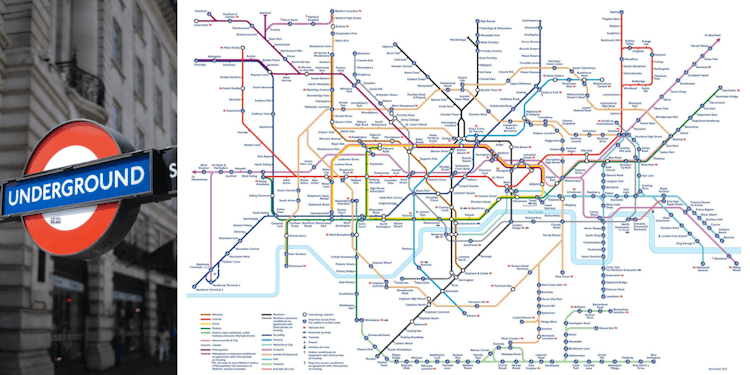
Modeling, Visualizing, and Navigating a Transportation Network with Memgraph
Learn how to model, visualize, and navigate a complex transportation network using graph algorithms, Cypher, Memgraph, and Memgraph Lab

Understanding Community Detection Algorithms With Python NetworkX
Learn the basic principles behind community detection algorithms, their specific implementations, and how you can run them using Python and NetworkX.
How to Build a Flight Network Analysis Graph-Based ASP.NET Application with Memgraph, C#, and D3.js
Learn how to build a flight network analysis graph-based ASP.NET application using Memgraph, C#, and D3.js.

How to Implement Custom JSON Utility Procedures With Memgraph MAGE and Python.
Learn how to extend the Cypher query language by implementing a few simple custom procedures to load and export data in a JSON format using Memgraph MAGE and Python.

How to Develop a Credit Card Fraud Detection Application Using Memgraph, Flask, and D3.js
In this tutorial, you will learn how to build a simple graph-powered Python fraud detection web application from scratch.

How to Write Custom Cypher Procedures With NetworkX and Memgraph
Learn how to implement custom Cypher procedures using query modules and the NetworkX Python library.

Implementing Data Replication in Memgraph
Learn about how we implemented replication capabilities in Memgraph. In this post, we discuss our approach, challenges, and solutions.

Announcing the Memgraph 1.3 Release!
Memgraph 1.3 is here and it brings you high availability replication!
Operation J-Pack or How Memgraph Organised 2020 Xmas Celebration
By using the LRP algorithm, we delivered J-Packs to everyone in the company for Xmas!
Vislet – Visualize Geographic Data in Memgraph Lab
Discover how to visualize graph data on a world map in Memgraph Lab
How to Style Your Graphs in Memgraph Lab
Discover how to customize your graph visualisations using the new scripting lanugage.

Memgraph 1.2 Release - Implementing The Bolt Protocol v4
Memgraph 1.2 is here! One of the biggest changes in this release is the addition of Bolt v4 and v4.1 support. In this post, we will explore what exactly is the Bolt protocol, what it brings to the table, and how we implemented it into Memgraph.

Memgraph 1.1 Up to 50% Better Memory Usage and Higher Throughput
Learn how by introducing a new storage engine, encoding and compressing properties on both nodes and edges, and leveraging skip lists as an indexing data structure, we were able to reduce memory usage by as much as 50% and improve throughput towards near-linear scalability.

Air Traffic Routing With Memgraph
How Memgraph Lab enhances air traffic control by optimizing flight paths, emergency landings, and storm evasion with graph databases.

Building a Recommendation System Using Memgraph
Learn how to build a recommendation engine with Memgraph using an objective approach.

How to Visualize a Social Network in Python with a Graph Database: Flask + Docker + D3.js
How to build a Python web application for visualizing a Social Network Graph in Python with Docker, Flask and D3.js

Why Your Business Should Use a Graph Database
Learn how graph databases can offer powerful data modeling and analysis capabilities your business can leverage to easily model real-world complex systems and answer challenging questions.

How to Build a Route Planning Application with Breadth First Search and Dijkstra's Algorithm
Learn how to leverage breadth-first search and dijkstra's algorithm to build a route planning application with Memgraph and Cypher.

Announcing Memgraph 1.0!
Memgraph 1.0 is now production-ready, offering high-performance, in-memory graph database with Cypher support.

How to Install Memgraph With Docker on macOS
A step-by-step tutorial for installing Memgraph Platform on macOS

Introducing The Memgraph Community Forum
The Memgraph community forum is the best place to get fast and accurate answers from both our team and other Memgraph developers.

How to Install Memgraph and Memgraph Lab on Windows 10
A step-by-step tutorial for installing Memgraph and Memgraph Lab on Windows 10

Official Memgraph Drivers Are Out!
We're happy to announce that Memgraph drivers for Python and C languages, as well as Memgraph CLI command line interface are now published.

How Interns Built Twitch App and Advanced Our MAGE
Over the course of ten weeks, we had four interns join Memgraph. They worked directly on the Memgraph product.
pymgclient 1.0.0 Release
This new release makes it possible to install the pymgclient 1.0.0 on Windows, and macOS. It also makes the installation on Linux much easier, and delivers improved stability.

Introduction to Real-Time Data
Learn about the differences between static and dynamic data, real-time data sources and ways of analyzing streaming data

Announcing Our Partnership with FactGem!
Memgraph and FactGem Partner to Give Clients Access to Real-Time, Transaction Based Analytics.