
How to Build Knowledge Graphs Using AI Agents and Vector Search - Demo Overview
Ever struggled with redundant data in your knowledge graphs? When the same entity appears under different names, it creates a chaotic mess. How do you turn this inconsistent, ambiguous information into a clean, disambiguated knowledge base?
In our latest Community Call, Carl Kugblenu, Senior Software Engineer at WithSecure and PhD researcher at Aalto University, joined us to share how he tackled exactly this challenge during a hackathon at VTT, Finland's national research institute.
He developed a custom-built agent pipeline that leveraged LLMs with Memgraph's built-in vector search. This innovative approach tackled the complex challenge of entity disambiguation head-on. The result was a high-quality, disambiguated knowledge graph, where each unique concept was represented only once.
Missed the live session? Watch the full Community Call on demand for a walkthrough of the pipeline, a live demo in Memgraph, and a detailed Q&A.
Here’s a breakdown of the key technical takeaways and live demo shared during the session:
Talking Point 1: Entity Disambiguation in Innovation Data
VTT struggled with data quality where the same innovation entity appeared as different innovation mentions, varying significantly in phrasing:
- "Protein from air"
- "New carbon food tech"
- "Solar Foods breakthrough"
Same innovation, different text. This made it nearly impossible to analyze trends, track contributions, or understand who did what. Without a way to reliably group and resolve these mentions, graph quality was suffering and analytics became unreliable.
So, Carl’s challenge at the VTT hackathon was to:
Build a canonical knowledge graph where each unique innovation appears only once as a single node, effectively linking all repeated mentions back to it.
The provided input data included pre-processed innovation mentions complete with valuable metadata like source URL, organization, and domain. This real-world context was particularly useful.
Talking Point 2: Solution Stage One: Context-Aware Similarity Search Analysis
How did Carl achieve this? By combining several powerful tools and concepts:
- Exploratory Data Analysis: First, understanding the dataset was key. This involved analyzing preprocessed dataset of innovation mentions from VTT and partner websites.
- Vector Embedding: OpenAI's
text-embedding-ada-002was used to run embeddings. Each innovation mention was embedded into a 1536-dimensional vector. - Cosine Similarity: A FAISS index was built from these embeddings. For each mention, the system found top-K nearest neighbors using cosine similarity, then filtered results by a score threshold.
- Rule-Based Confidence Boost: Metadata like source domain, publishing organization, and publication date proximity were used to refine raw similarity scores. This "boost" significantly improved candidate pair identification.
The result? More meaningful similarity scores, with better candidates for disambiguation.
Talking Post 3: Solution Stage 2: LLM-Powered Agent Pipleline
With candidate pairs identified, Carl passed them through a GPT-powered agent resolution pipeline, in which each agent:
- Received a pair of mentions plus their metadata and boosted similarity score.
- Decided whether they referred to the same innovation.
- Either merged them or created a new canonical node in Memgraph.
This logic lived inside a set of agent tools wrapped with context-rich JSON prompts that made decisions repeatable, auditable, and easy to track.
The resolution pipeline used the Model Context Protocol (MCP) to manage agent tools for node creation and merging. Memgraph’s built-in vector search played a crucial role in detecting similar embeddings directly within the graph. This allowed the agent to efficiently compare new mentions against existing innovations before deciding to merge or create a node.
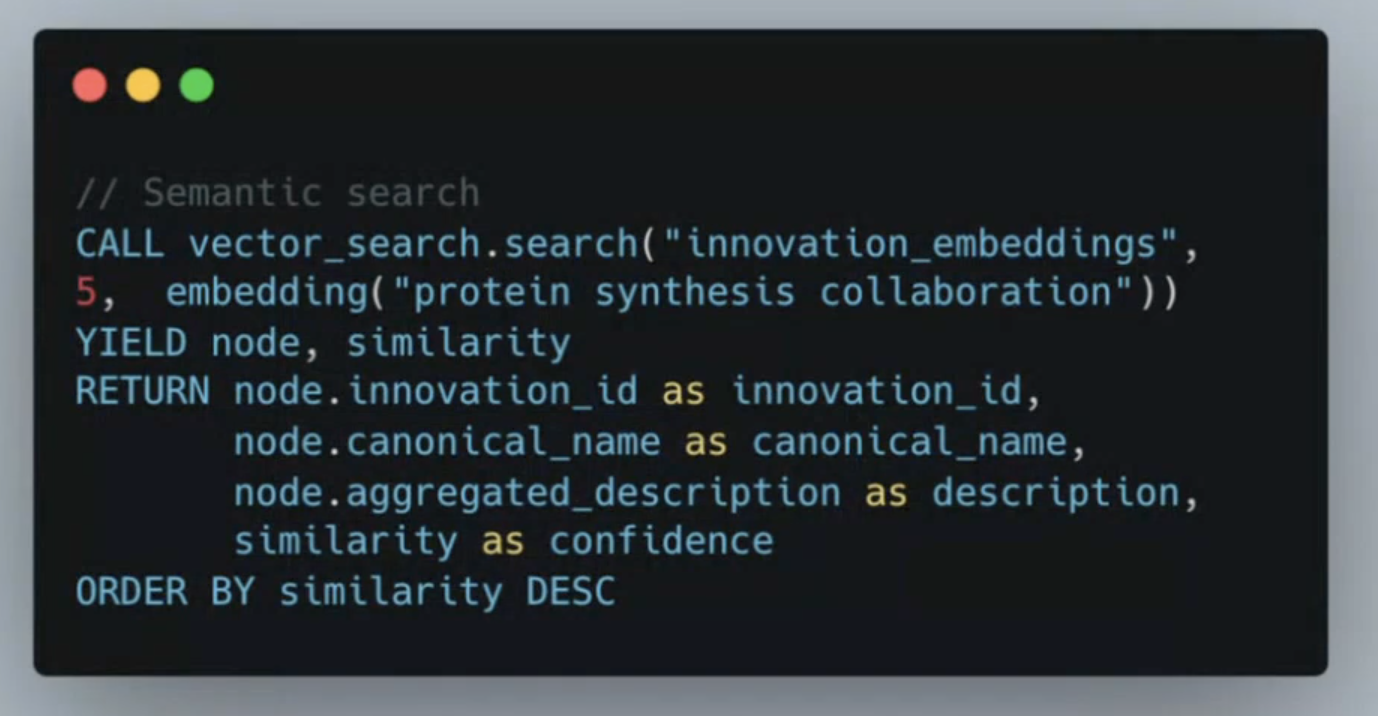
Importantly, the ingestion was sequential, not batched. This approach allows each newly added node to enrich the context for future decisions, creating a positive feedback loop.
Talking Post 4: Live Demo Highlights: Building a Canonical Graph
Carl ran the full pipeline live using Memgraph and a command-line interface. Some of the key steps included:
- Purging the Memgraph database and loading organizations using VAT IDs.
- Running the similarity detection script in Memgraph to extract top candidate pairs.
- Watching agent decisions in real time as it resolved or created new innovation nodes.
- Visualizing the graph grow, with nodes connected to multiple organizations and mentions.
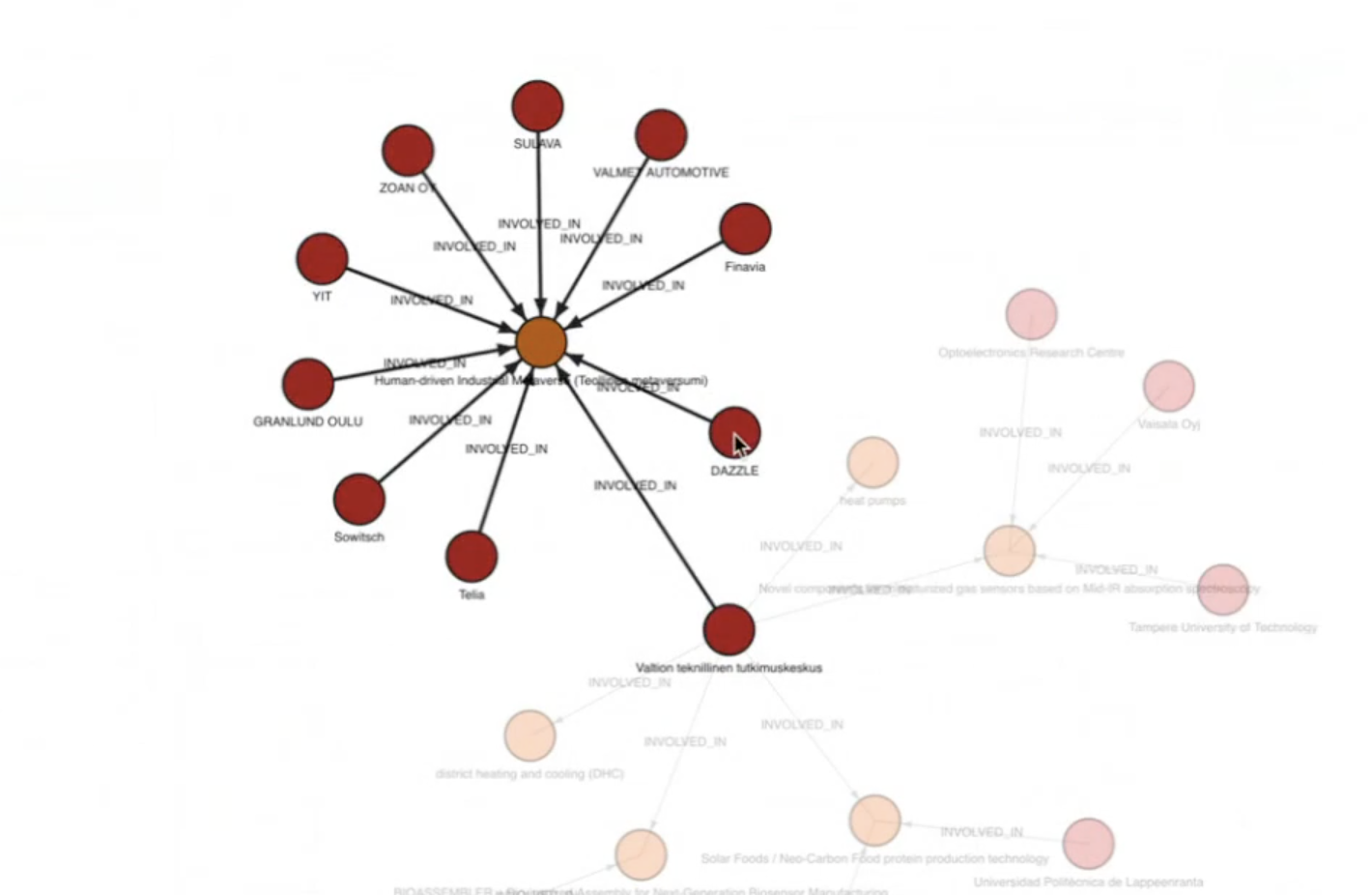
By the end of the session, a clean, canonical innovation graph is showcased with ambiguity resolved:
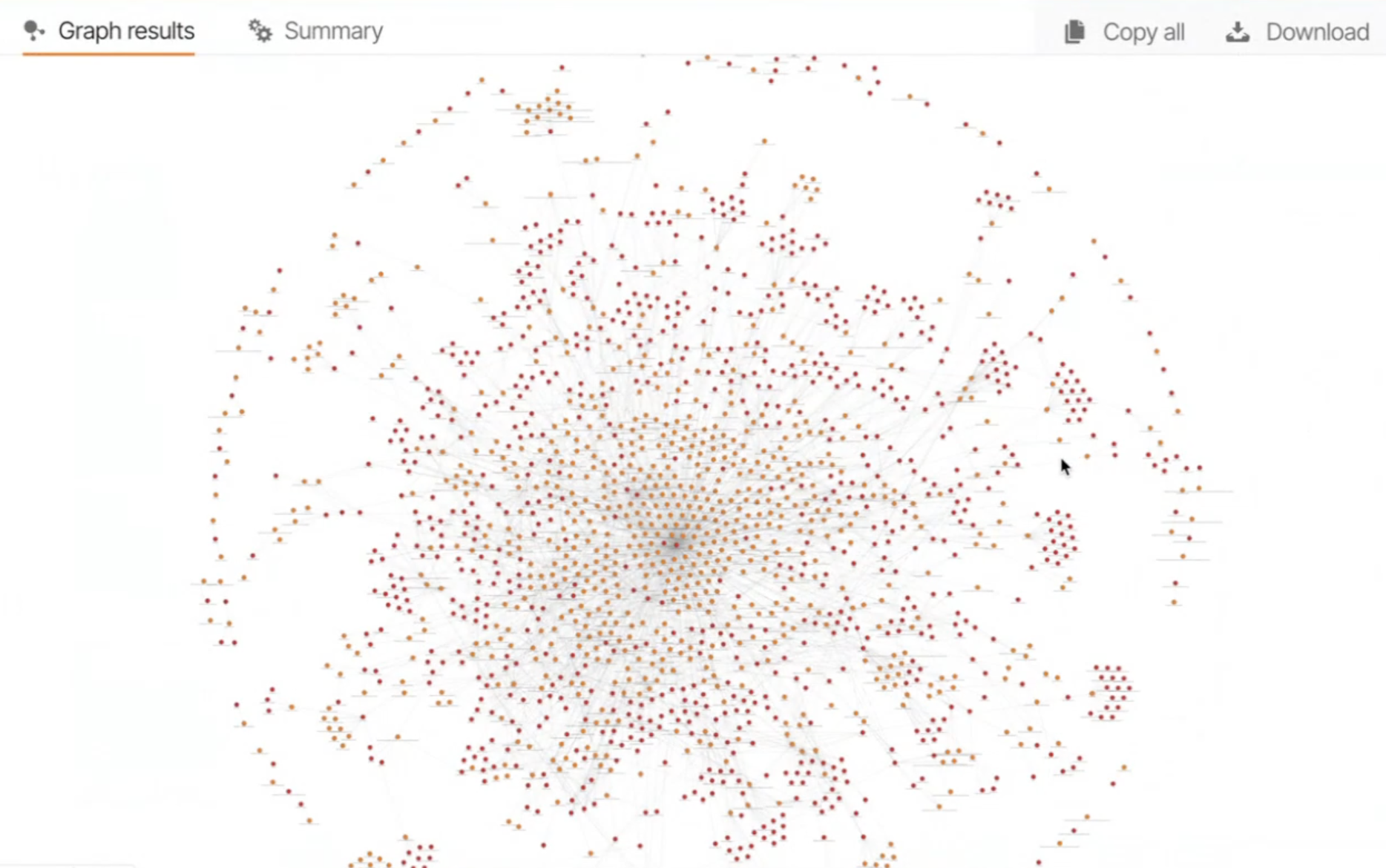
Talking Post 5: Graph Analytics Possibilities
Once built, the graph opened up a range of analysis options:
- PageRank to identify the most influential organizations
- Community detection to cluster innovations
- Natural language queries through Memgraph’s agent tool interface
Carl’s pipeline made all of this accessible without duplication, and with full auditability.
Talking Post 6: Technical Challenges
No complex project is without its hurdles. Carl shared some key challenges and how they were resolved:
| Challenge | Solution |
|---|---|
| LLM hallucinations | Used metadata-rich context and few-shot prompts |
| Embedding dimension issues | Standardized vector sizes (1536-dim) throughout |
| Duplicate nodes | Used agent decisions + vector search pre-check |
| Ingestion speed | Sequential updates instead of batch resolution |
| Traceability | JSON audit logs for each agent decision |
Q&A
Weʼve compiled the questions and answers from the community call Q&A session.
Note that weʼve paraphrased them slightly for brevity. For complete details, watch the entire video.
- Did you stumble upon any technical challenges in leveraging Memgraph Spectre Search?
- Yes. Initially, I experimented with different embedding sizes, but Memgraph didn’t like the inconsistency. I had to remove and restart with fixed-size embeddings. Otherwise, graph export would break.
- Did you find a sweet spot for embedding dimension?
- The sweet spot depends on the model used. For OpenAI’s text embedding, we used 1536. But it varies, especially when experimenting with local OLAMA models.
- What is the average time for a decision from the agent?
- Around 30 seconds to a minute per resolution.
- What is the largest dataset you've disambiguated?
- So far, thousands of innovation mentions. Not yet tens or hundreds of thousands.
- Do you find different challenges with disambiguating homogeneous vs heterogeneous graph models?
- Not particularly. It’s more about how well the prompting defines the graph schema. With few-shot examples, LLMs perform quite well.
- What advice would you give to an organization trying to implement a similar pipeline?
- Ensure the data is rich in context. Metadata is vital. Preprocessing plays a big role. Don’t rely solely on LLMs or similarity—combine both, and always have human oversight.
- Did anything surprise you during the hackathon?
- That it actually worked! I was worried it might fail overnight, but the prompt engineering held up. Also, the metadata boost helped much more than expected.
- Any lessons from comparing this agentic system to traditional GNN or link prediction models?
- GNNs need retraining and can be opaque. Agent tools are interpretable and easier to iterate. The audit trail makes debugging and contributions easier.
Further Reading
- Docs: Vector Search
- GitHub Repo: VTT Hackathon Challenge
- Docs: Memgraph in GraphRAG Use Cases
- Webinar: Vector Search in Memgraph: Turn Unstructured Text into Queryable Knowledge
- Blog: Showcase Building a Movie Similarity Search Engine with Vector Search in Memgraph
- Blog: Decoding Vector Search: The Secret Sauce Behind Smarter Data Retrieval
- Blog: Simplify Data Retrieval with Memgraph’s Vector Search
- Webinar: Talking to Your Graph Database with LLMs Using GraphChat
- Blog: GraphChat: How to Ask Questions and Talk to the Data in Your Graph DB?