
Options for Building GraphRAG: Frameworks, Graph Databases, and Tools
Building a GraphRAG (Graph-based Retrieval-Augmented Generation) system requires combining structured data (often stored in a knowledge graph) with LLMs to improve the precision and relevance of responses. But how do you go about building one?
Let’s break this down using the key steps and tools from the screenshot:
- Structure and model your data.
- Find and extract relevant information.
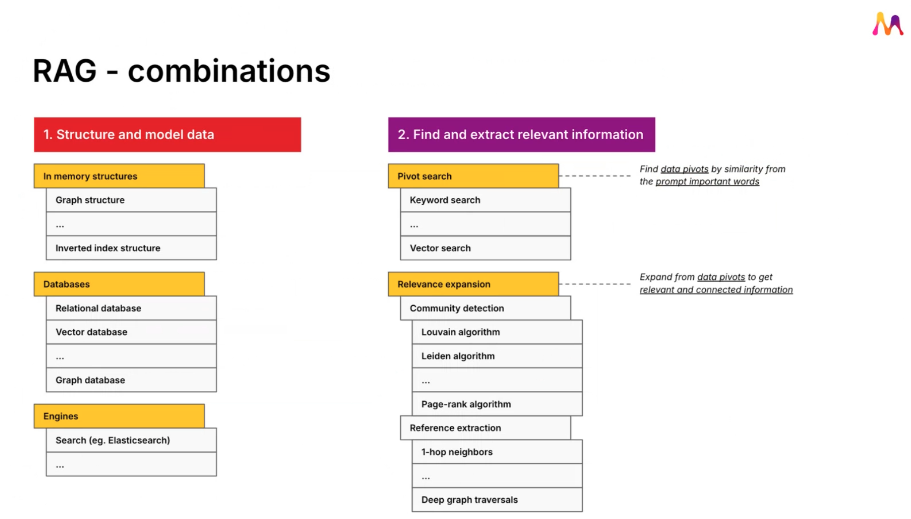
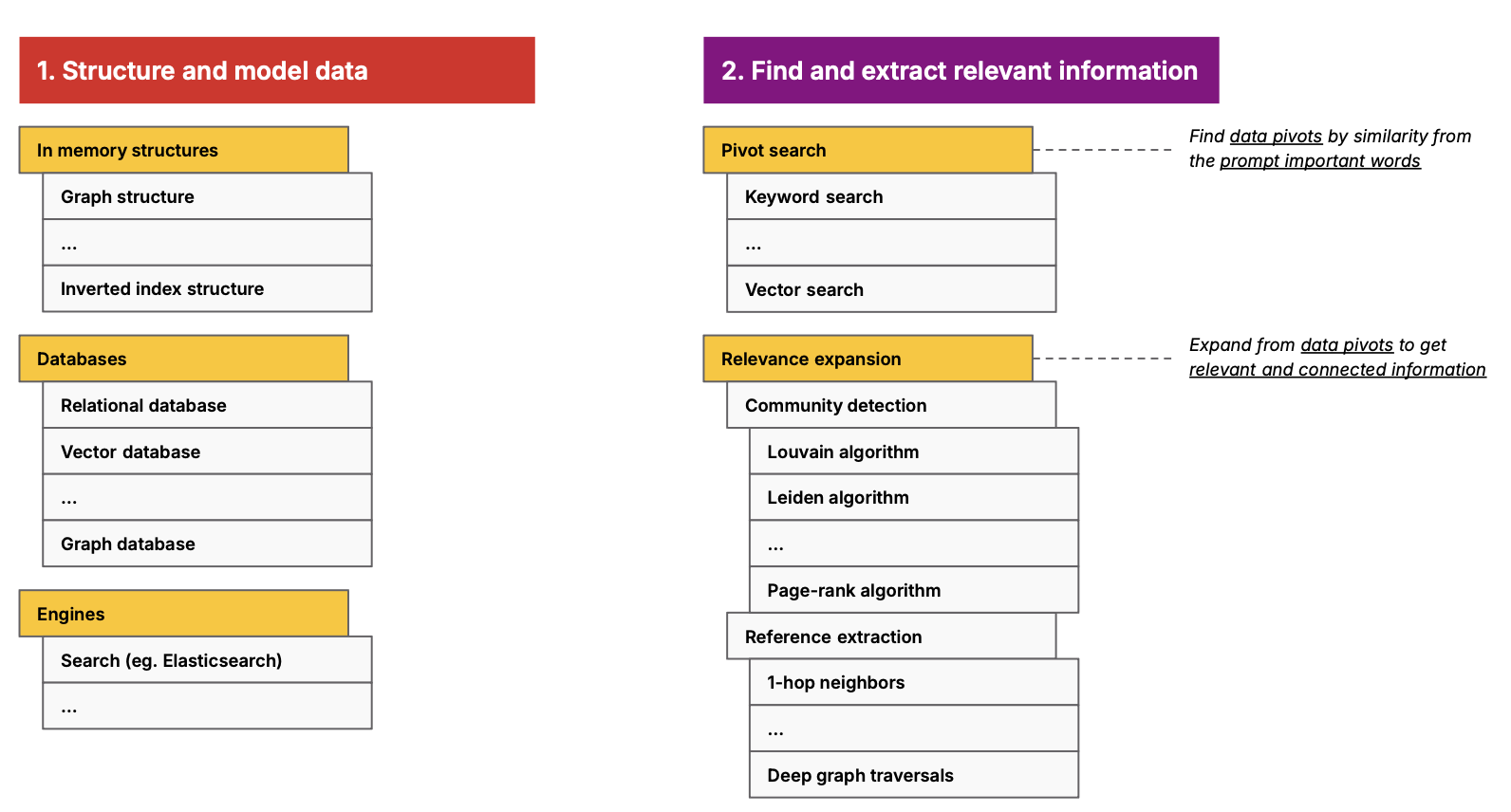
1. Structuring and Modeling Data
Before you can query a graph, you need to build it. Structuring your data is the foundation of GraphRAG, and the tools you choose here are what’s important.
In-Memory Structures
For smaller, dynamic datasets, you can use in-memory structures like:
- Graph structures. Efficient for traversing relationships and handling real-time updates.
- Inverted index structures. Useful for keyword or document-based retrieval.
Read more: Memgraph docs - Graph Modeling
Databases
Choosing the right database depends on your use case.
Read more: How to Choose a Database for Your Needs?
Graph Databases
We recommend you use Memgraph. An in-memory graph database optimized for real-time processing and algorithms like Louvain and Leiden. Ideal for dynamic GraphRAG systems that require real-time updates.
Vector Databases
Weaviate or Pinecone. They are great at ****handling semantic searches using embeddings generated by LLMs.
Relational Databases
Useful for legacy systems, but they lack the multi-hop reasoning capabilities of graph databases.
Read more: Graph Database vs Relational Database
Engines
Elasticsearch. It’s perfect for indexing and querying large datasets with keyword or text search. Combine it with a graph database for hybrid search capabilities.
2. Finding and Extracting Relevant Information
Once your data is structured, you need to make it useful. This step involves pivot search and relevance expansion.
Pivot Search
Identify key data points based on similarities from the query prompt. Options include:
- Keyword search for exact matches.
- Text search for roader than keyword search, supports partial matches.
- Vector search: Uses embeddings to find semantically similar results (e.g., FAISS or Pinecone).
- Geo search: For location-based queries.
Read more: GraphRAG with Memgraph
Relevance Expansion
Expand your search to find related, connected data. Popular techniques:
- Community detection algorithms:
- Louvain algorithm: Detects clusters in your data.
- Leiden algorithm: Similar to Louvain but optimized for large graphs.
- PageRank algorithm: Prioritizes nodes based on importance. Includes a dynamic PageRank algorithm.
- Graph traversals: Explore multi-hop relationships in your graph (e.g., 1-hop neighbors or deep traversals).
Read more: Memgraph’s Deep Path Traversal Capabilities
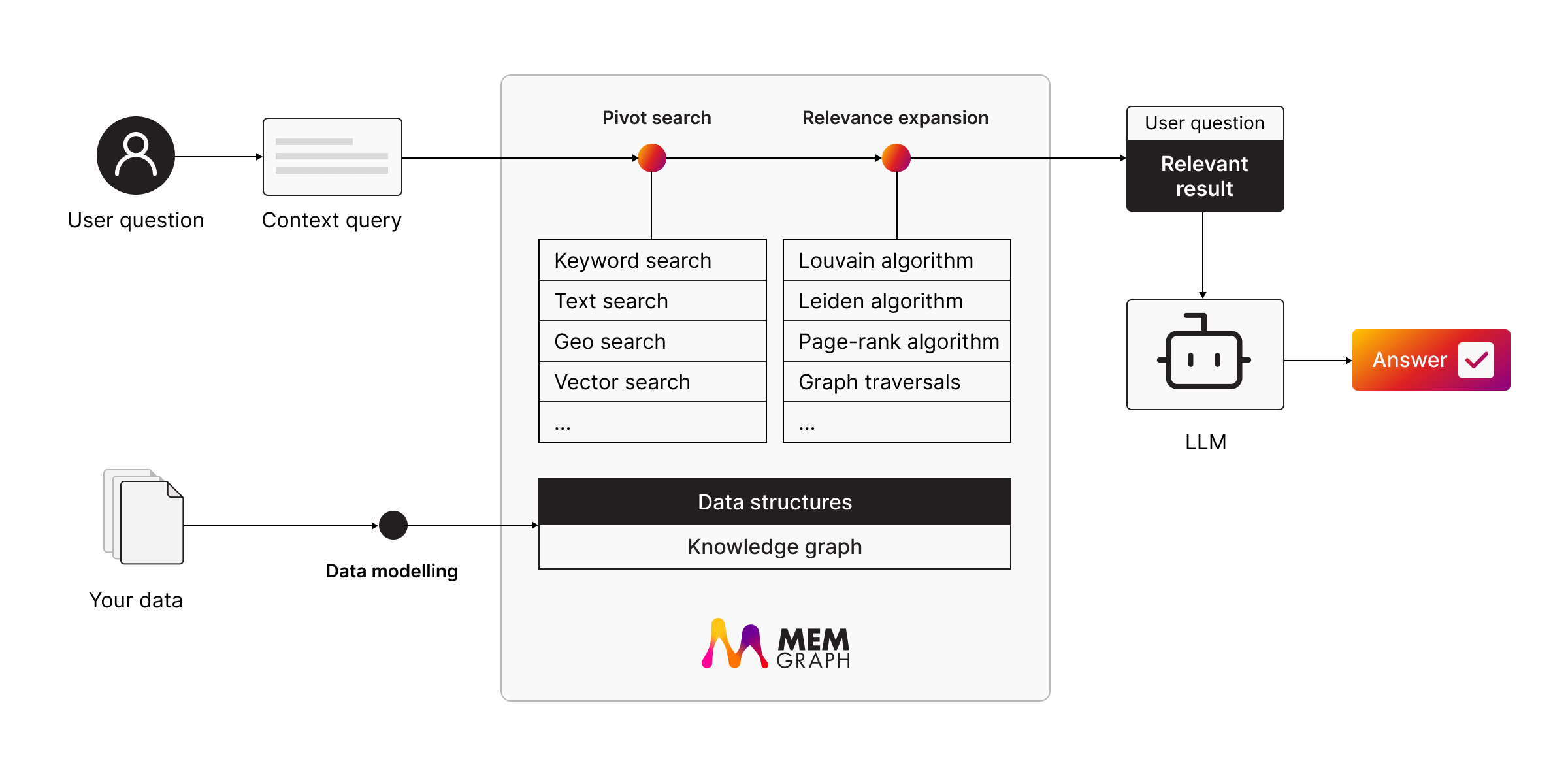
Building GraphRAG with Memgraph
Here’s how a GraphRAG system works with Memgraph:
Step 1: Data modeling. Structure your data as a knowledge graph. Use graph schemas to organize entities and relationships.
Step 2: Pivot Search. Use keyword, text, or vector search to identify key data points from the query.
Step 3: Relevance expansion. Apply community detection algorithms like Louvain or graph traversals to gather connected information.
Step 4: Enrich the prompt. Append the relevant data to the user’s query.
Step 5: Send to LLM. Provide the enriched prompt to the LLM for a context-aware response.
This system use Memgraph’s in-memory performance, real-time updates, and integration with LangChain or LlamaIndex for seamless LLM interaction.
Read more: Building GenAI Applications with Memgraph: Easy Integration with GPT and Llama
If you are curious to know about real life use cases of companies using Memgraph for GraphRAG, check out:
- Using Memgraph for Knowledge-Driven AutoML in Alzheimer’s Research at Cedars-Sinai
- How Precina Health Uses Memgraph and GraphRAG to Revolutionize Type 2 Diabetes Care with Real-Time Insights
- Memgraph and GraphRAG: Transforming Diabetes Management in Healthcare
- Enhancing LLM Chatbot Efficiency with GraphRAG (GenAI/LLMs)
Combining Tools for a Hybrid GraphRAG
In some cases, you might need a hybrid approach:
- Graph Database (e.g., Memgraph). For relationships and reasoning.
- Vector Database. For semantic search.
- Search Engine. For text-based retrieval.
TL;DR
- Start with data modeling. Use graph databases like Memgraph for structured data.
- Retrieve and expand. Apply pivot searches and algorithms like Louvain for relevance.
- Integrate with LLMs. Use frameworks like LangChain or LlamaIndex to connect your data to LLMs.
- Customize based on your needs. Choose tools that match your scale, budget, and real-time requirements.
By combining the right tools and techniques, you can build a GraphRAG system that allows you to do more with your data and enhance LLM performance.