
Implementing Data Replication in Memgraph
Introduction
Memgraph's biggest new feature in the v1.3 release is the support for replication.
Although replication isn't a new idea in the database world, it's a great example to illustrate how often, a simple solution can be the best one.
In this post, we will discuss the concept of replication, and explain how Memgraph implements essential replication capabilities. We will discuss our approach, the challenges we faced, and how we overcame them. Finally, we'll explain in detail how do we allow you to pick what property should the replication satisfy for each replica you connect to an instance of Memgraph.
A Brief Introduction to Data Replication
Uninterrupted data and operational availability in production systems is critical and can be achieved in many ways.
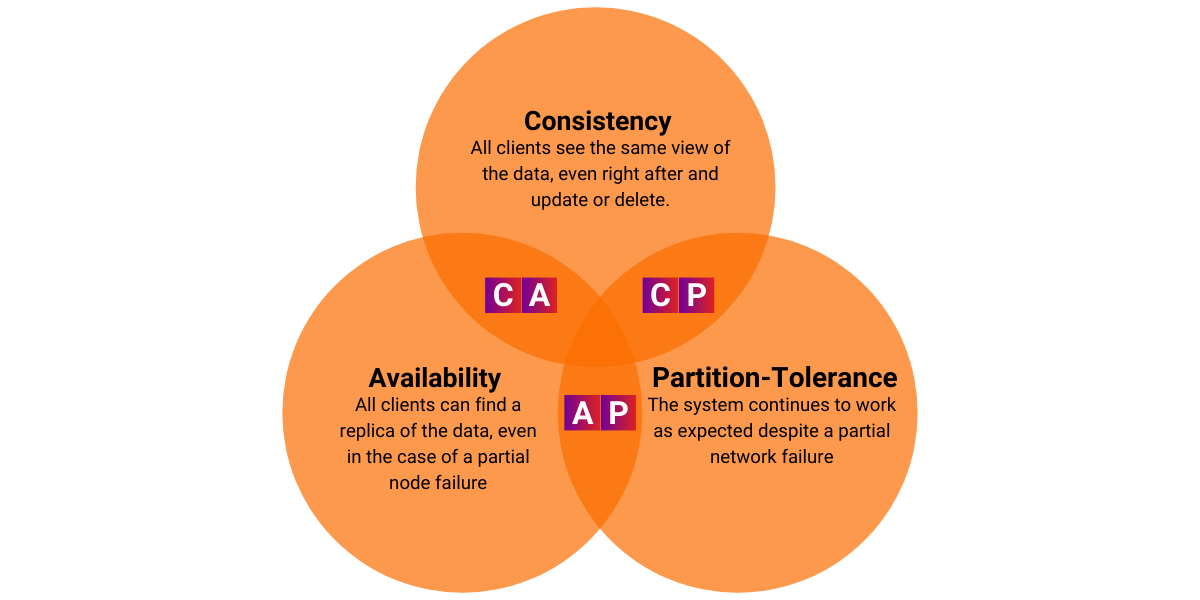
In distributed systems theory, we talk about the CAP theorem (Consistency, Availablity, Partition Tolerance). Out of the three, a distributed system can simultaneously satisfy at most two. Modern systems often implement a hybrid approach where some systems ensure consistency and push availability as high as possible, and others are eventually consistent but available at all times, etc.
Algorithms like Raft and Paxos are well known to ensure CAP properties. E.g., Raft provides consistency, partition tolerance, and availability if the majority of the cluster is healthy. It also comes with many complexities, which produces performance issues and introduces complexity not required for most known Memgraph use-cases. Mostly running analytical graph workloads on real-time data.
You can achieve those properties by using a much simpler concept called replication. It basically consists of replicating the data from one storage to other storages. Because the concept is simple, achieving all three of the CAP properties at the same time is not possible. Having a combination of two of those three properties, on the other hand, is achievable.
Implementing Data Replication
Even though the idea of replication is simple, trying to add it to a system that has been in development for a few years, is not a trivial task. When the database was designed, the replication hadn't been taken into consideration, so the biggest challenge was to implement the replication while minimizing the changes to the current implementation of the database.
First, let's see what are the specifications of the replication we wanted to implement.
What Can you do with Memgraph's Data Replication?
Before we started with the development we had worked out what do we want from our replication feature. As always, that specification evolved throughout the development, even forcing us to delay some features for future releases. We ended up with these basic key points:
- Every instance can take the role of MAIN or REPLICA, where the MAIN instance is replicating its data to its replicas.
- The MAIN instance can register and drop a replica by specifying its endpoint.
- The MAIN instance can have multiple replicas registered.
- Only the storage is replicated.
- Write queries are forbidden on replicas.
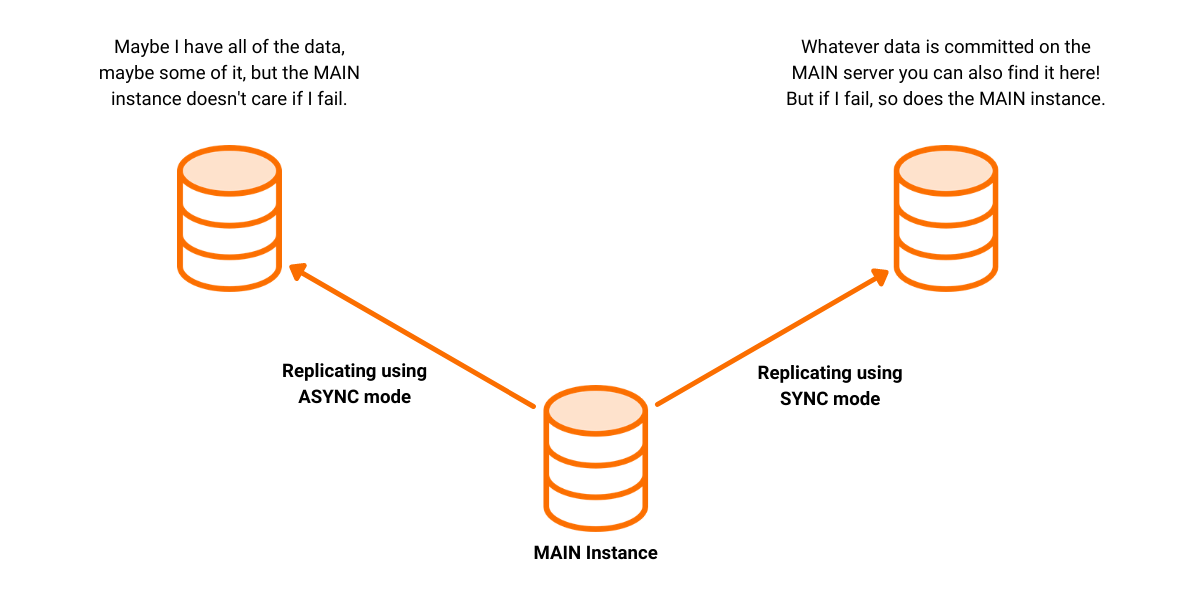
- The MAIN instance can replicate its data in three ways or, as we call them, modes:
- SYNC - The MAIN instance cannot commit a transaction until the replica has confirmed it received the same transaction.
- SYNC WITH TIMEOUT - Same as sync but waits for some set time for confirmation. If the response timeouts, the replica is demoted to an async replica.
- ASYNC - The MAIN instance can commit a transaction without waiting for the replica to confirm that it received the very same transaction.
Using Multiple Data Replication Modes
As we said before, satisfying all three properties of the CAP theorem is practically impossible. But, using these modes, you can pick which of these properties you would like to have for each of your replicas. By replicating the data using the SYNC mode you achieve consistency, by using the ASYNC mode you get availability, and by using SYNC WITH TIMEOUT you try to hold the consistency until something unexpected happens forcing you to give up and accept that availability is good enough.
Replication, no matter how simple the idea is, introduces a great number of edge cases that need to be handled in some way or another. This makes it hard to be confident in your implementation (we will never be 100% confident, which is practically a law for multithreaded and distributed applications).
In the next section, we will discuss the basic idea behind our implementation of the replication feature and some of the interesting challenges we faced.
Data Replication Implementation Basics
The information necessary to implement replication is contained in transaction timestamps and so-called durability files (snapshot files and WALs).
Timestamps allowed us to establish a way of communication between two instances as it represents the current state of an instance. Using the timestamp, the MAIN instance can know what is the current state of the REPLICA and send the correct data for synchronization.
When you apply some changes to the MAIN instance, all those changes are represented by a "delta". The concept of deltas is not new as we use them for our WAL files. Those deltas contain enough information to be sent to the replicas and be applied correctly.
What if a REPLICA is trailing behind the MAIN instance?
We simply use the durability files to "recover" the REPLICA to the state of MAIN instance. This is more or less how we implemented the replication.
Now, let's delve into some specific parts!
Understanding Different Data Replication Modes
Supporting different replication modes means supporting different ways of waiting for the response after transaction deltas were sent to the REPLICA.
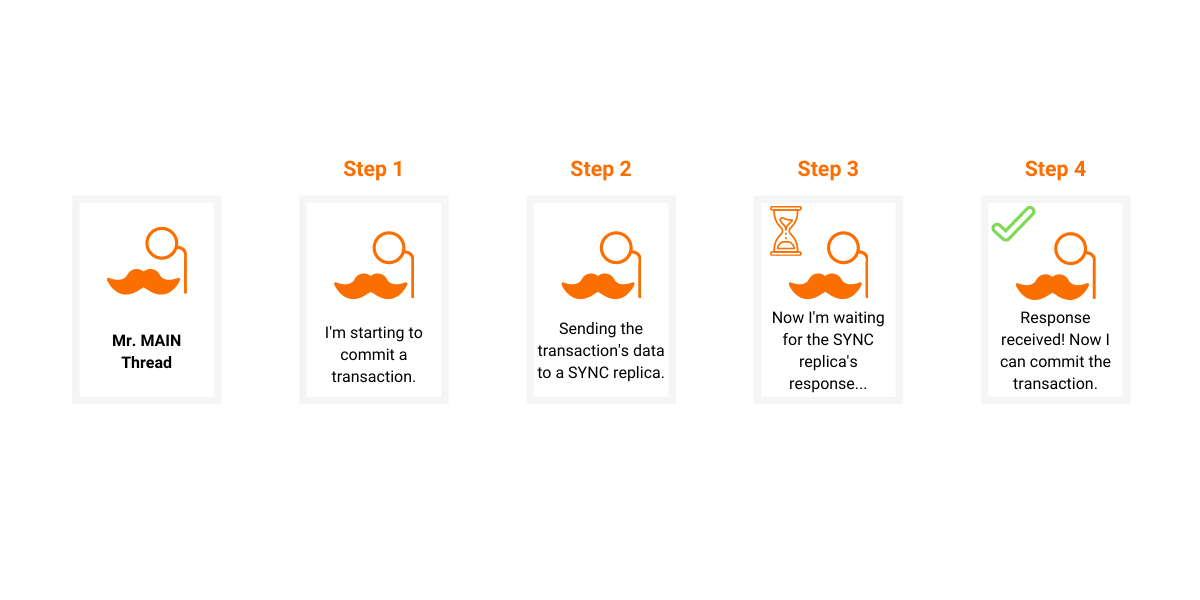
The most straightforward mode is the SYNC mode as the main storage thread simply waits for the response and cannot continue until the response is received.
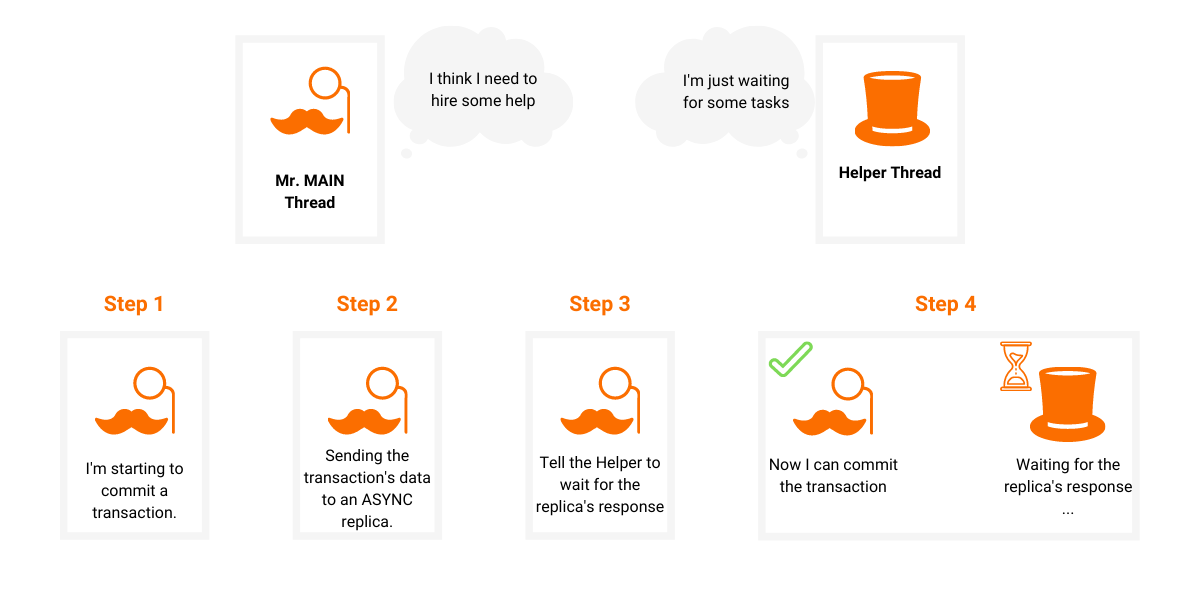
Next in line is the ASYNC mode. Okay, we don't wait for the response in the main thread but in some other thread and we're done.
Well, there are multiple possibilities here. We can create a thread every time we want to replicate a transaction to the REPLICA, or we can use a single thread every time and simply queue a task that will be executed on that thread. Since creating a thread is not cheap and committing transactions is not something that happens once in 100 years we picked the latter.
The only problem was that we hadn't implemented something like that.
The idea of creating a thread once and dispatching tasks on it isn't something new. It's one of the most popular patterns in multithreaded applications, also known as thread pool. So, to support the ASYNC mode we had to add a thread pool implementation. Although we could've used an off-the-shelf threading library, like folly, we didn't need all the functionality provided by one so we decided to write our own.
Finally, we have the SYNC WITH TIMEOUT mode. Things are not so simple here. We have a main thread that wants to commit a transaction, but first, it needs to wait for the REPLICA to commit the same transaction, BUT only for some time after which it should continue replicating the transaction and any future transactions in the background. Let's split that sentence into 3 key points:
- Wait for a REPLICA to commit a transaction.
- If the timeout triggers, commit the transaction on the MAIN instance regardless and switch the REPLICA to ASYNC mode.
- Don't stop the replication of the current transaction.
The third point tells us to wait for the REPLICA's response in a background thread so that the main thread can continue its execution even if the replication is not done.
The first point tells us that the main thread needs to wait for a certain time. Now our threads need to communicate somehow. Of course, we use a condition variable that can be notified by a background thread.
And the second point means that we need to have an additional background thread containing a timer that can also notify the main thread.
At first, it seemed easy, but it wasn't. Our implementation of this looks something like this:
active = true
replication_background_thread({
replicate...
active = false
notify main thread
})
timeout_thread({
finished = false
while (active && not timeouted)
sleep for some time
finished = true
active = false
notify main thread
})
while (active)
wait
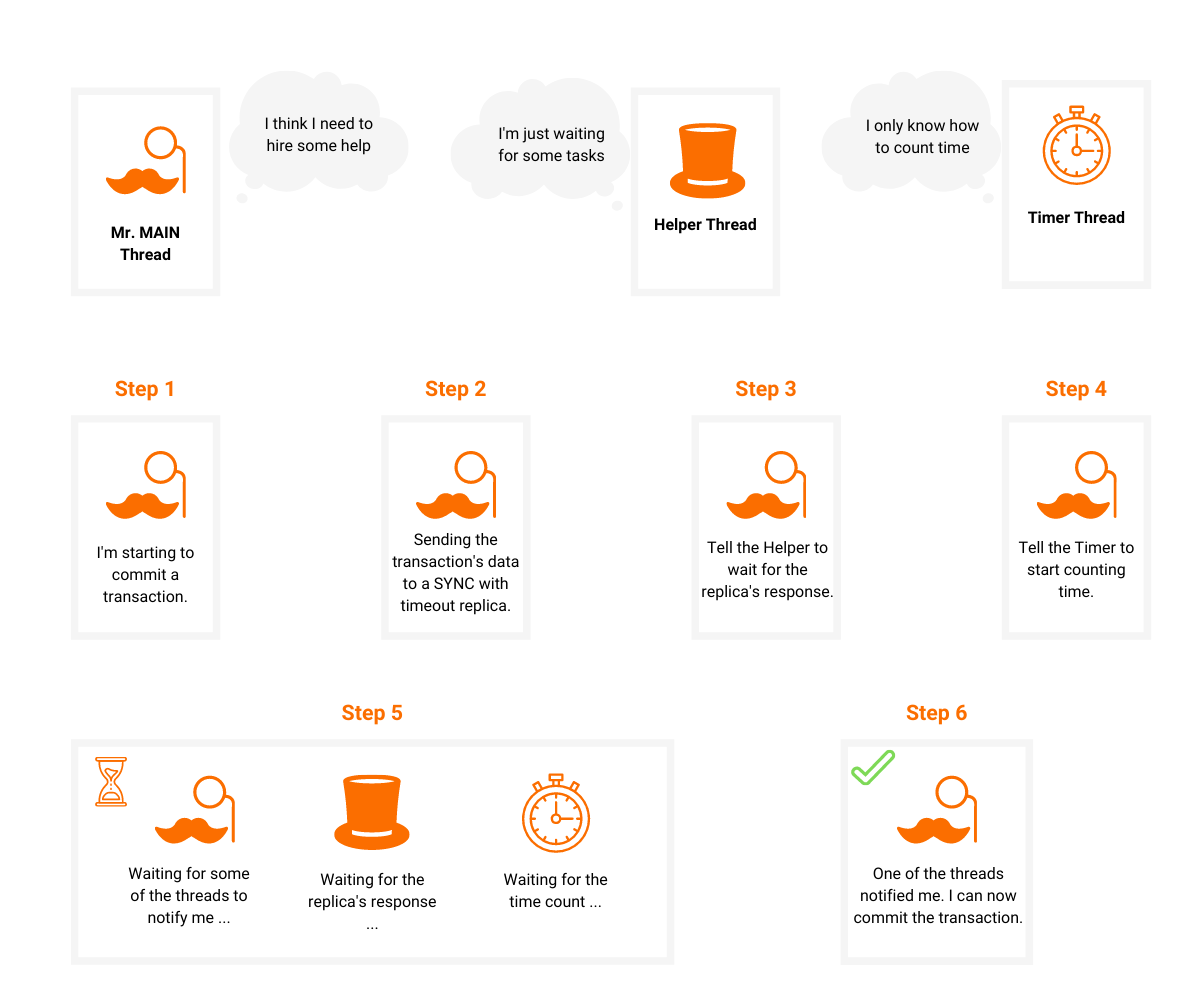
By using only 3 threads, we already had many interesting edge cases.
For example, we introduced the finished flag because the timeout thread sleeps for some time while it's active so it doesn't register immediately that the replication thread finished. During that time another transaction can come in and try to replicate something to the same REPLICA, queue the timeout task, and after that anything is possible because the previous timeout task needs to finish first. This means that it can execute the lines after the while loop at any time which notify the main thread that the response timeouts.
To have things consistent we keep the sleep time at a reasonable value and before waiting for the response we wait for the previous timeout task to finish.
This was really important to do because we want to have the timeout time as exact as possible. If the user-specified the timeout to be 5 seconds, timing out after 10 milliseconds would probably result in angry questions on StackOverflow and/or our Forum.
We also wondered if using concurrency concepts like semaphore would make our lives easier in these cases while not sacrificing the performance.
How Should the REPLICA Catch up to the MAIN?
If the MAIN instance concludes that the REPLICA is missing some earlier transactions, the REPLICA goes into a RECOVERY state and remains in this state until it catches up with the MAIN instance.
There are 2 ways of sending the missing data to the REPLICA. The first one is by sending a snapshot, and the second one is by sending the WAL files. One important difference between those 2 files is size. Because snapshot files represent an image of the current state of the database they are much larger than the WAL files which only contain the changes, deltas. Based on that we try to favor the WAL files as much as possible.
For example, imagine you have a snapshot created after some transactions and 5 WAL files where the first WAL file contains the first transaction and 2 of those WAL files contain transactions that were committed after the creation of the snapshot. We have 2 possible ways of syncing a replica with the MAIN instance:
- Option 1: we send the snapshot file and the 2 latest WAL files.
- Option 2: we send the 5 WAL files.
Both options are correct, but the second one will send much less data. While in the RECOVERY state, the MAIN instance tries to find the optimal synchronization path based on the REPLICA's timestamp and the current state of the durability files.
By now, we have an idea of how to handle the synchronization of two Memgraph instances, but the durability files are not used just for replication. They are constantly being created, deleted, and updated. Also, each replica could need a different set of files to catch up. How do we ensure that the necessary files persist and read the WAL file that is currently being updated while not affecting the performance of other parts of the database?
Here's how we did it!
Locking the Files
As explained before we use the durability files for the recovery process. They can be deleted at some point in time because we want to eliminate the redundant data as much as possible. The problem is that those files can also be deleted while we're using them to synchronize a replica with the MAIN instance, so we need a way to delay the deletion of, not only a single file but multiple files at a time.
To achieve this, we designed a file retainer.
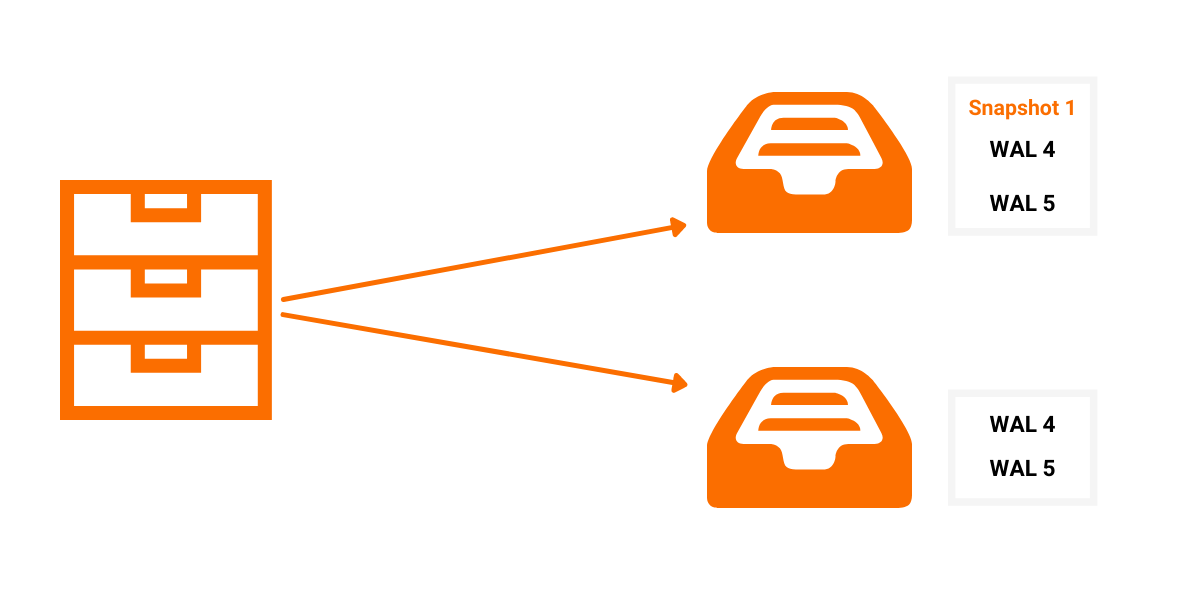
The File retainer consists of multiple lockers, and you can access those lockers and lock a file or a directory inside of them. When you try to delete a file, using the file retainer it first checks all the lockers to see if it should add the file to the queue for deletion or if it can be deleted immediately. At some point, the file retainer cleans its queue of files ready for deletion by deleting every file which is now not contained in any of the lockers. Also, when you access a locker, no files can be deleted, so you can safely add multiple files to the locker without worrying that while adding the first file, the second file can be deleted.
Leveraging this simple utility class, we can be sure that all the files we found while searching for the "optimal recovery path" are still there while we are sending them to the REPLICA. Also, each thread can have its own, independent locker so removing a file from one locker doesn't allow the file retainer to delete it if it's contained in another locker. After we finish using the file we ensure that the files are deleted if another thread tried to delete it before (if it's not contained in any other locker).
Using the same file retainer, we managed to develop an additional feature to let you lock the data directory, which is explained here.
Writing and Reading Files Simultaneously
Preventing the deletion of files wasn't the only challenge caused by the durability of files.
While synchronizing a replica we can be sending the latest WAL file, to which we're currently writing deltas. We use our own internal file buffer while writing the data to a file so the data of a current WAL can be contained in two places.
When we finish reading the file and start to read its internal buffer, the buffer can be flushed right before we start reading it. This way we miss a chunk of data and send the replica an invalid file. The worst case would be if some other thread writes a transaction to the internal buffer after which the main instance will send a valid WAL file that is missing a transaction.
Also, we would like to avoid flushing the buffer every time we want to send the current WAL to a REPLICA. This forces us to use the file and its internal buffer when replicating the current WAL file. It's also important to emphasize that blocking any writes to the current WAL file will block all new transactions when they try to commit.
We decided to simply disable the flushing of that buffer while we're sending the current WAL to a replica. That way, new data can be written to the internal buffer so the threads that are committing a transaction are not blocked by the replication thread which is sending the current WAL. First, we read the content directly from the file, and then we read how many bytes are written in the buffer and copy them to another location. Now, we can enable the flushing of the buffer again and replicate the transaction using the copied buffer.
We can read the size of data contained in the buffer in a non-blocking fashion because we know that the data can only be appended after that point. Also, the flushing is disabled so the data cannot be lost until we enable the flushing again. The only situation in which a committing thread can block is when the buffer is full and it needs to be flushed so that the new data can be appended.
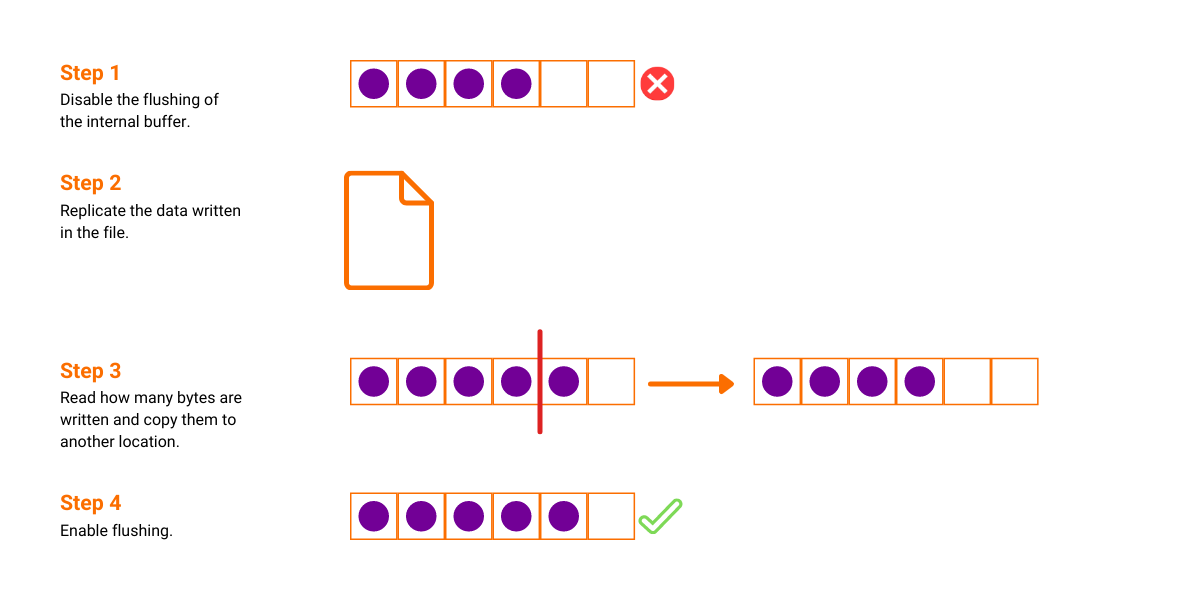
Fixing Timestamp Consistency
When we're sending a transaction using the deltas, we send its timestamp which we use on the REPLICA. This caused some interesting problems.
First, we used the current timestamp for the global operation, like creating an index or creating a constraint, without increasing its value. This way, we cannot know by a single timestamp which of those operations the REPLICA has applied and which it hasn't because sequential global operations will have the same timestamp. To solve this, we decided to assign a unique timestamp to each global operation.
Second, the replicas allow read queries. Each of those queries will get its own timestamp with which the snapshot isolation is satisfied. This is a problem because the replicated write transaction will probably contain an older timestamp. So a read transaction can have different data from the same read query if a transaction was replicated in between, so the snapshot isolation doesn't hold anymore. To mitigate this problem, we don't increase the timestamp on replicas because the read transaction doesn't produce any changes, so no delta needs to be timestamped.
Incompatible Instances
While connecting instances, a lot of interesting scenarios could happen. Before we added the replication we had similar problems with durability. What if a data directory contained in the same folder the durability files of two different database instances?
To mitigate this, we added a unique id to each storage instance. By adding that same id to the durability files we can be sure that the database can read only compatible files. Replication uses the storage's unique id to validate that the files are correct and that the databases are compatible. But, replication adds another twist to it!
Let's try to imagine the following scenario. We create two instances:
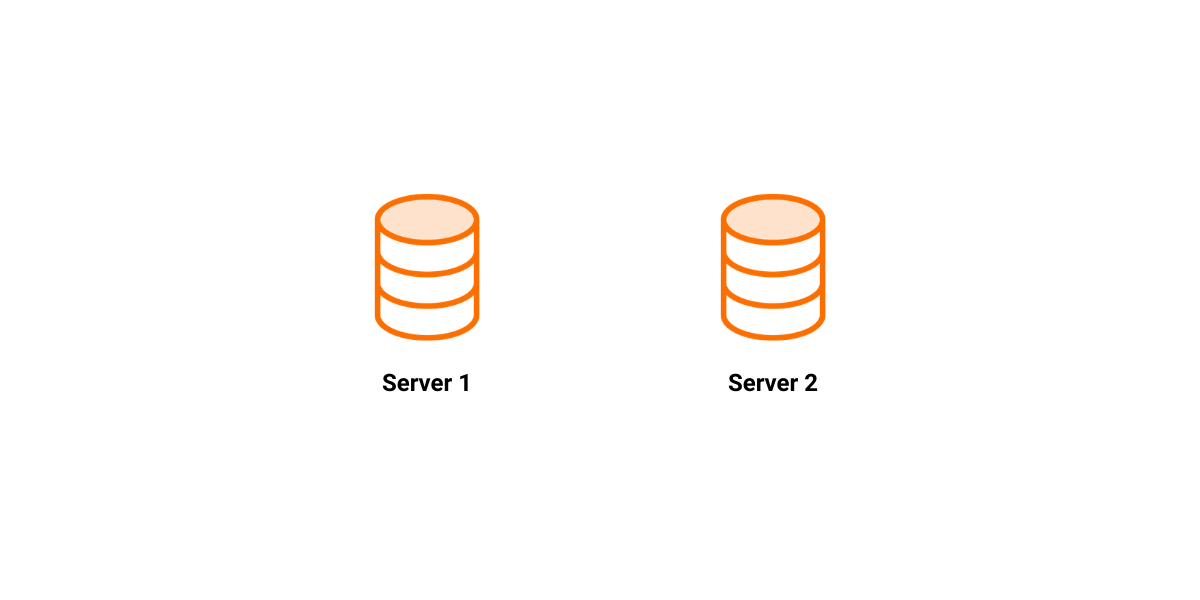
One of them takes the MAIN role while the other becomes a REPLICA. Also, we register the REPLICA on the MAIN.
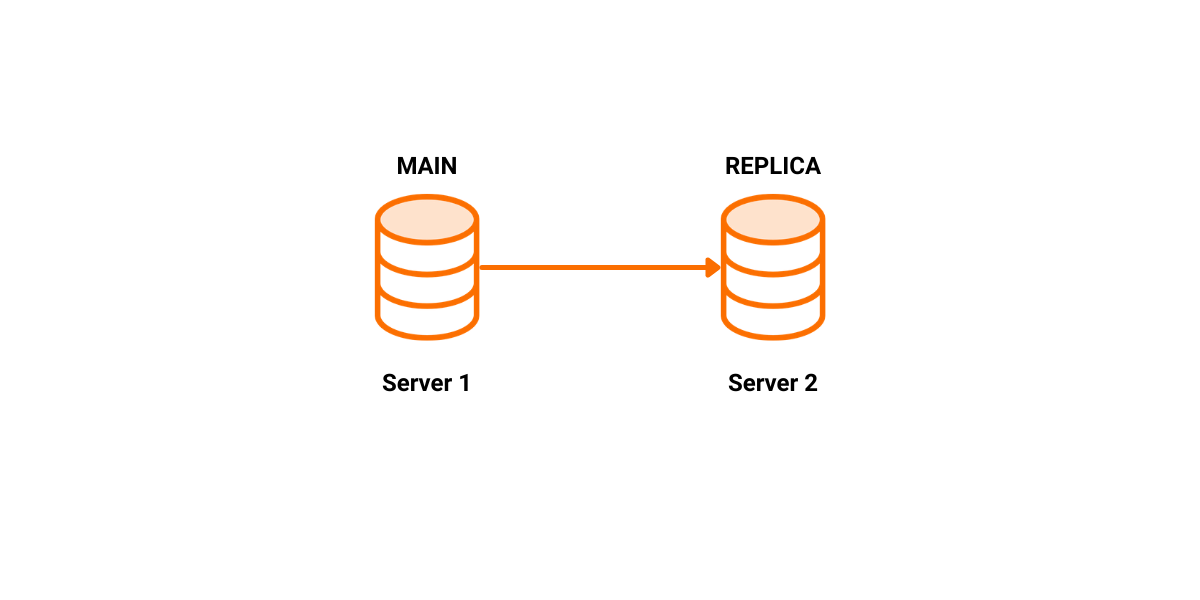
We write a couple of transactions on SERVER 1, which are replicated to SERVER 2. On timestamp 25, SERVER 1 crashes.
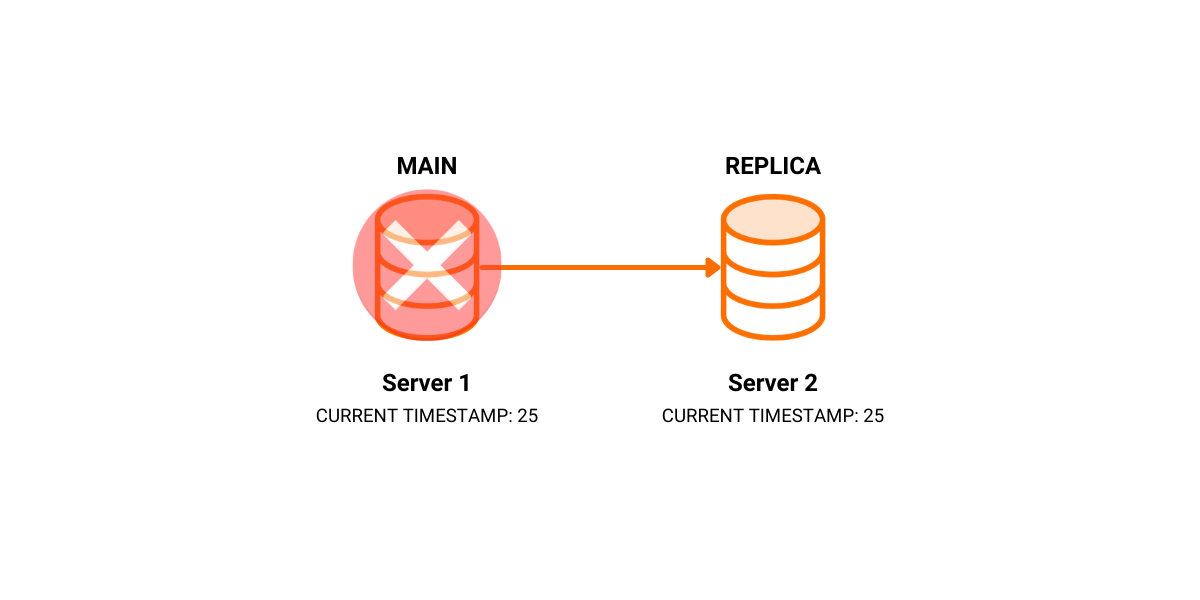
We set SERVER 2 to be our new MAIN and we continue to write transactions to it.
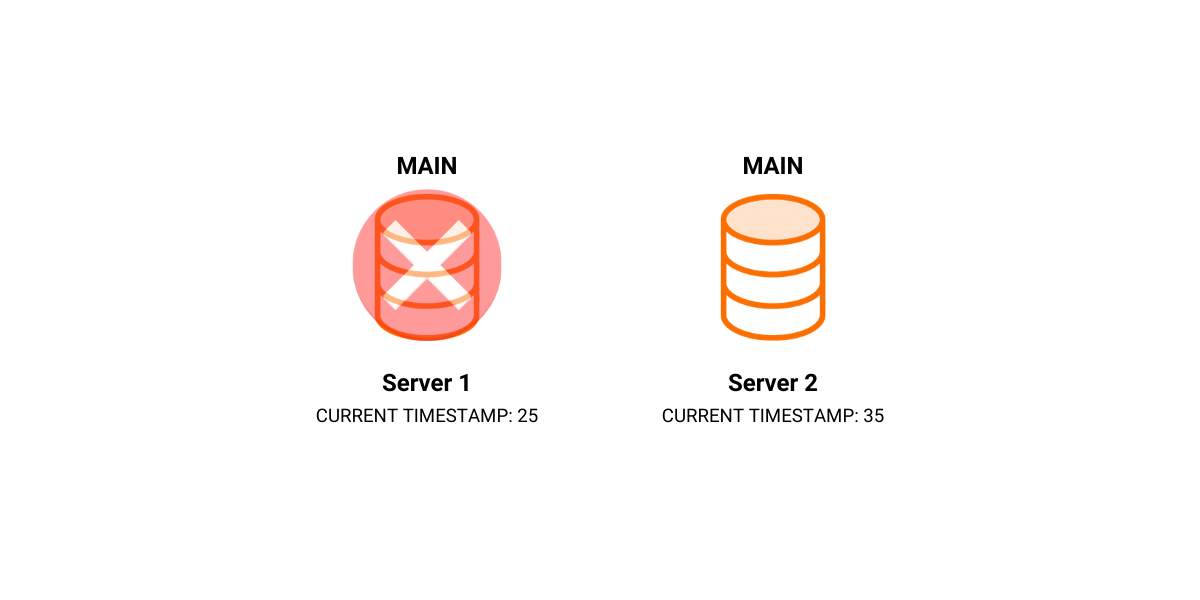
After some time, we recover SERVER 1 and set it as MAIN.
The first edge case is simple, if we set SERVER 2 to be a REPLICA and try to register it on SERVER 1, we can conclude using the timestamps that the replication is not possible because SERVER 1 is behind SERVER 2. But what if we write some transactions to SERVER 1 until its timestamp becomes larger than the timestamp on SERVER 2?
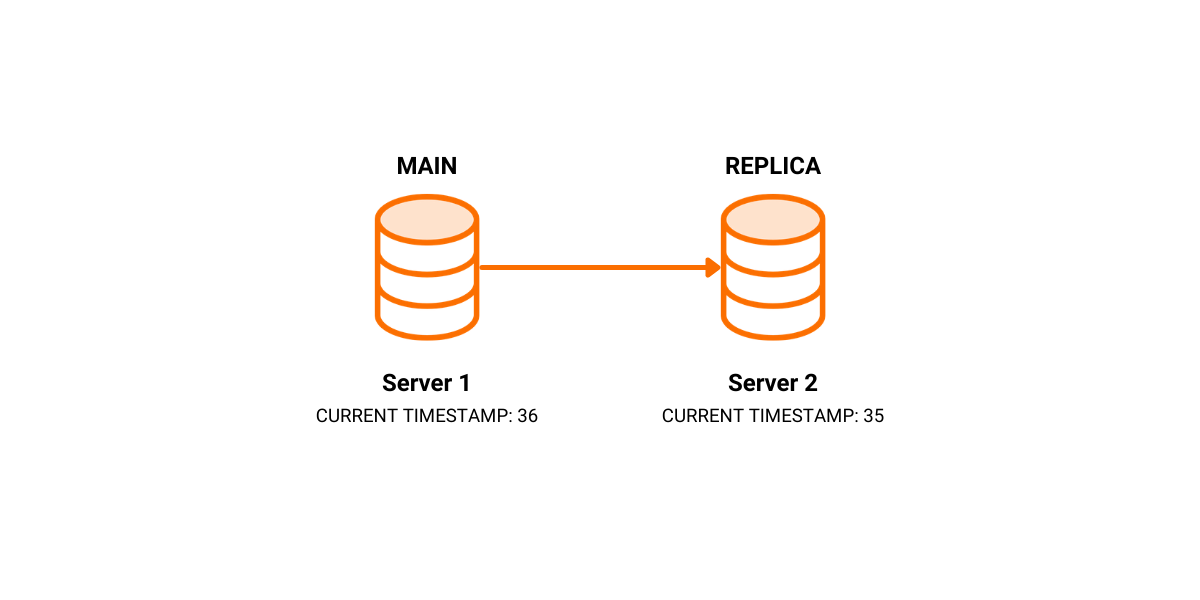
The unique id of the storage is the same on both instances, and the timestamp is larger on the MAIN instance. Everything seems okay, but replicating the transactions that are valid on SERVER 1 produces an undefined behavior on SERVER 2.
To avoid this situation, we add a unique id to each "run" of an instance as the MAIN instance in the replication process. We call that id the epoch_id. E.g., every time an instance takes a role of a MAIN, we generate a new epoch_id allowing the instances to check if their data is compatible enough.
In our example, our 2 instances will have different epoch_id causing the registering of SERVER 2 on SERVER 1 to fail.
Thank you Jepsen!
Writing tests is something you don't appreciate until they find some bugs that you wouldn't even notice if you went through the code line by line.
While we were developing the replication feature, we tried to cover all functionalities with unit tests as much as possible. But for something as complex as replication they weren't enough. When you have multiple multithreaded applications that communicate over a network, an incredible number of things can go wrong. Also, there are many cases that happen while using the database that are hard to simulate. For example, the random crashing of a server or network partitioning.
One option is to write you're own E2E test that tries to simulate some of those situations. The other possibility is to use a testing library that already does that for you.
In our case, that library is jepsen. If you don't know what it is, a single line from their README explains it best:
Breaking distributed systems so you don't have to.
This beautiful library comes with all the tools necessary to test your distributed system. The only parts you have to write yourself are the transactions that you want to run and their desired results. Crashing the servers, simulating the networking, running the queries at a random time are all handled by the jepsen library.
Also, the library is written in Clojure and for many of us, it was the first time we tried that language. After you get a hang of the language, you're going to love it!
We wrote 3 cases for a cluster that consists of a single main instance and 4 replicas using different modes. Those cases are:
- A bank test where you do a random money transfer from one account to another, while doing random reads on any of the instances, ensuring that the total amount of money is consistent.
- A sequential test where we add a new node with the id set to the one after the current maximum id. Also, we delete the lowest id after some fixed time. While modifying the data, we do random reads on any of the instances ensuring that all ids present in the graph are sequential.
- A large test where we write a huge chunk of data to the main instance while doing random reads on any of the instances ensuring that the whole chunk is replicated or none at all.
Using those tests, we fixed many bugs connected to the timestamp and the recovery of a REPLICA which we wouldn't be able to find so easy if we had to write our own simulations. Also, it pushed the replication to its limits ensuring that it can handle the more extreme cases.
Conclusion
Developing the replication feature has proved that adding a new feature to a complex system is not something that's straightforward as it seems at first. As the system grows, more and more constraints are added making each subsequent feature harder to implement.
With careful planning and proper tests, we managed to release something in which we're confident while validating that the correct behavior for every part of the system was preserved while not taking any performance hits.
Memgraph Replication is just the first step. There are still missing features, but we'll add more and more as we go with the use-cases.