
What is a Graph Database?
While relational databases have been the go-to choice for data storage, they fall short when it comes to handling complex relationships and traversing interconnected data, which puts graph databases in a special spotlight. A graph database is a specialized database system designed to store, manage, and query highly connected data using graph theory principles. As data volumes continue to explode, companies need efficient and scalable solutions to handle the complexities of their data.
Specialized database systems like graph databases offer a more natural and efficient way to model, query, and store data, leading to improved performance and better data insights.
Understanding graphs
In simple terms, at the core of graph databases lies the concept of a graph. In mathematics and computer science, a graph is a collection of nodes (also known as vertices) connected by edges. Nodes represent entities or objects, while edges depict the relationships or connections between them. This straightforward yet effective structure forms the foundation of graph databases.
Components of graphs
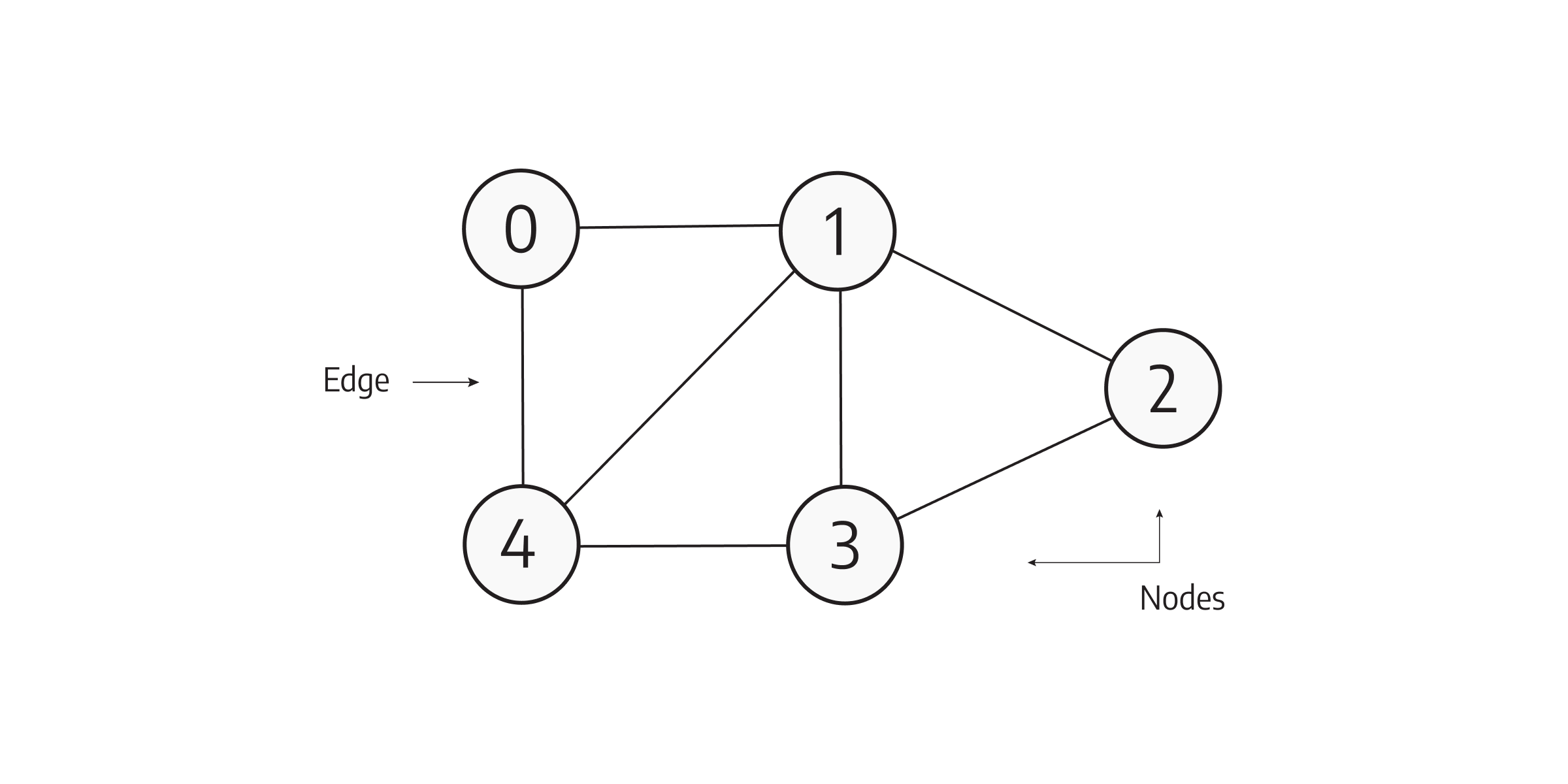
It's your time to shine! Let's reiterate on what we've learned so far. Graphs consist of two fundamental components: nodes and edges.
- Nodes represent entities or objects and can have various attributes associated with them.
- Edges, on the other hand, depict the relationships or connections between nodes and can also carry properties.
Together, nodes and edges create a rich network of connected data.
Graph theory basics
Another common term you may hear here and there, alluding to graphs or graph databases, is graph theory, which is a branch of mathematics, that provides the theoretical underpinning for understanding and analyzing graphs. It defines vertices as the fundamental building blocks of a graph and edges as the connections between vertices. Relationships in a graph can be represented by directed or undirected edges, capturing the nature and direction of the connections.
Relational databases vs. graph databases
Opinions split when it comes to choosing a database, however, the debate around relational vs. graph databases is still hot. Relational databases have long been the dominant database model, organizing data into structured tables with predefined schemas. They excel in handling structured data and transactions but face challenges when dealing with complex relationships and traversing connected data. This is largely due to their rigid tabular structure.
Joining multiple tables and navigating through numerous relationships can lead to performance bottlenecks and complex query formulations. This limits their effectiveness in scenarios where relationships play a crucial role.
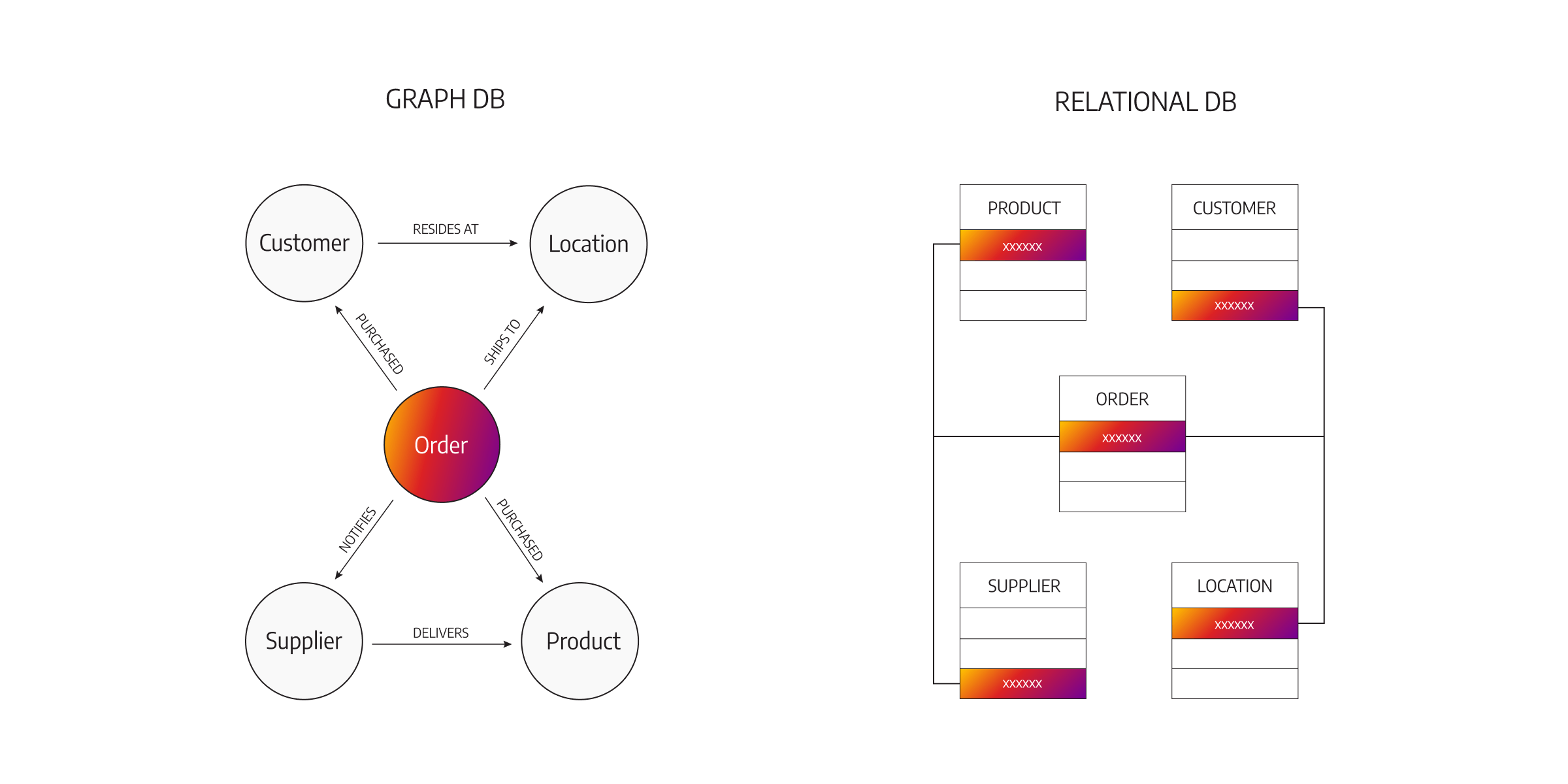
Graph databases excel in modeling and querying relationships. They store connections explicitly, allowing for efficient traversals between nodes and enabling complex relationship queries with ease. And of course, graph databases provide flexibility, scalability, and performance advantages over a relational database when it comes to handling interconnected data.
Characteristics of graph databases
So far, you've been introduced to a few qualities that are typical to graphs, so let's put the learnings into structure and build off of what you've grasped.
Schema-less nature
Unlike relational databases, graph databases are schema-less, meaning they do not require a predefined structure or schema for data. This flexibility allows for the dynamic addition of new node types, properties, and relationships, making graph databases highly adaptable to evolving data models.
Native graph processing
Graph databases are purpose-built for processing graph data. They employ optimized algorithms and data structures to efficiently traverse and manipulate the graph structure, resulting in faster query response times and improved performance compared to non-native graph databases.
Graph traversal and pattern matching
One of the key strengths of graph databases is their ability to traverse and explore relationships between nodes. Graph traversal algorithms can efficiently navigate the graph to discover patterns, uncover hidden connections, and retrieve data based on specific criteria. This capability is particularly valuable in applications such as recommendation engines, fraud detection, and knowledge graphs, which we will explore in the sections to come.
Use cases of graph databases
Unlike a traditional relational database that relies on tabular data, a graph database utilizes a flexible and intuitive data model, allowing for the representation of intricate relationships between entities. With its ability to efficiently capture and traverse vast networks of data, a graph database has emerged as an advanced tool for diverse domains, including:
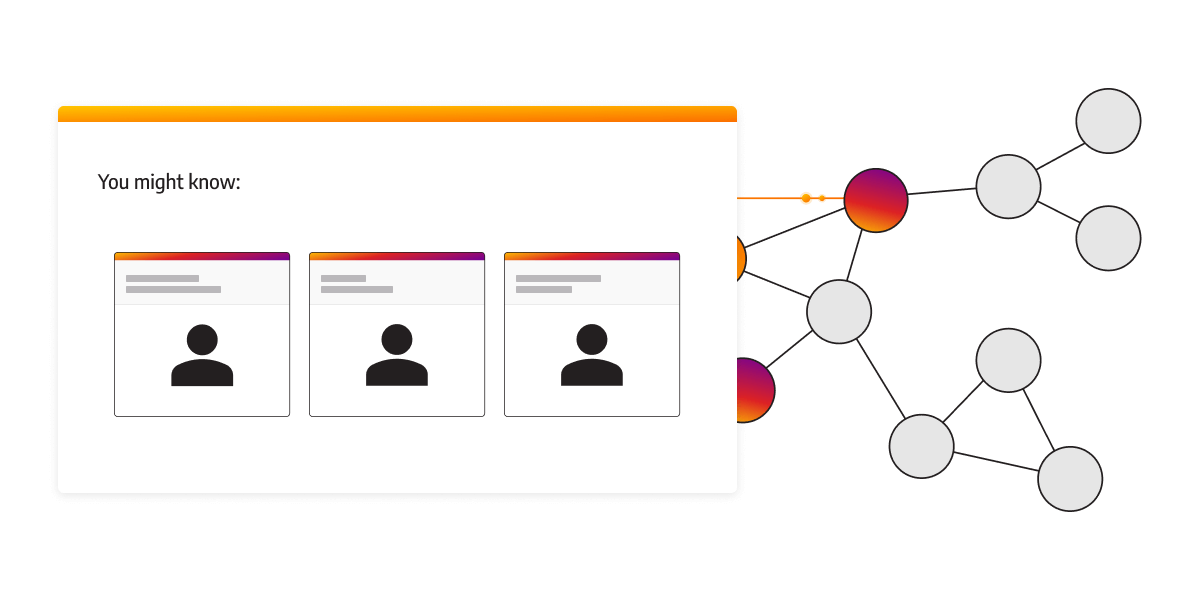
Social networks and recommendation engines
Graph databases have revolutionized social networking platforms and recommendation engines. They enable personalized recommendations, friend suggestions, and social network analysis by leveraging the rich network of connections between users, interests, and entities.
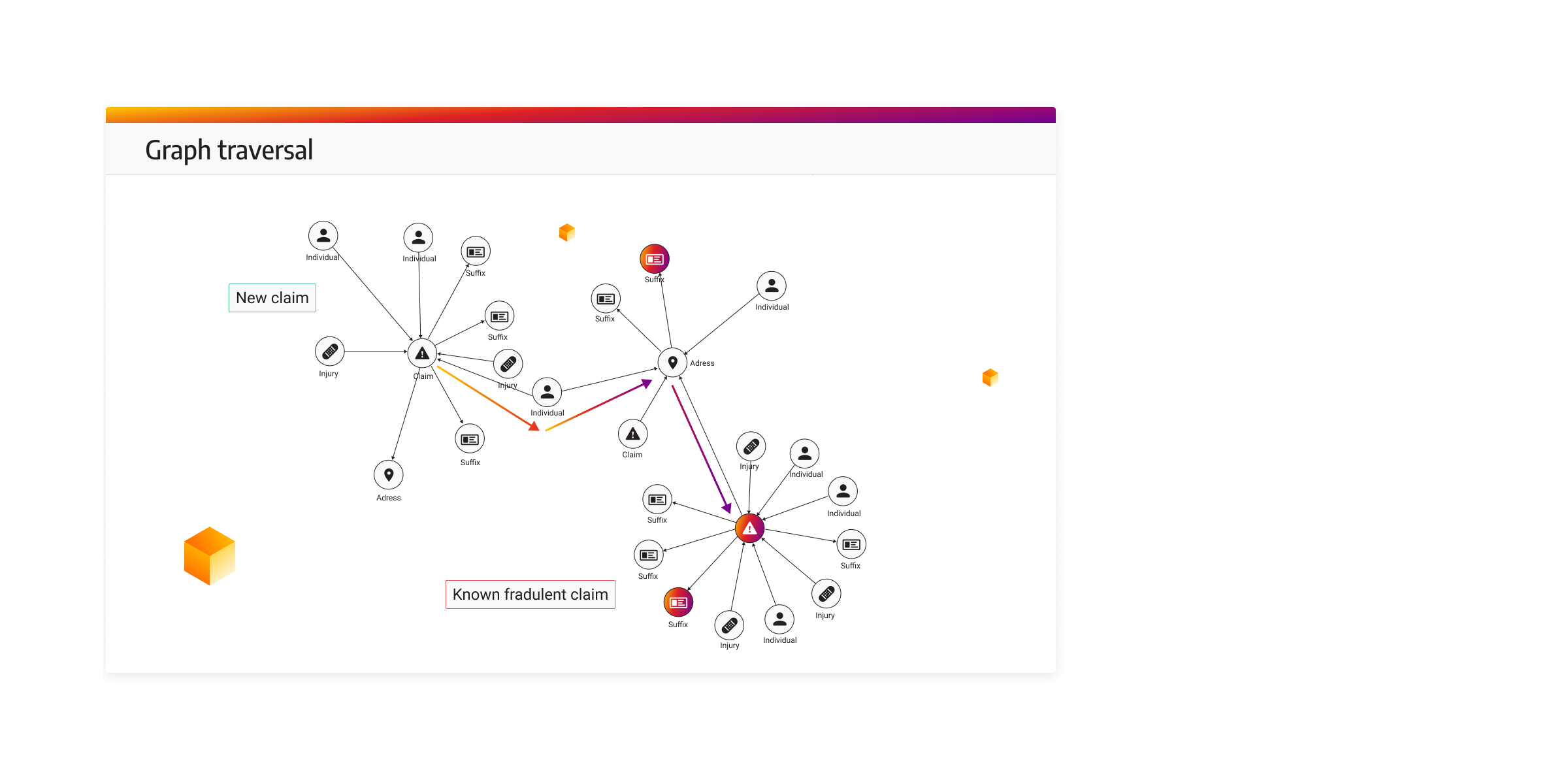
Fraud detection and network analysis
Graphs also excel in fraud detection and network analysis. By representing complex networks of relationships, they can identify suspicious patterns, detect fraudulent activities, and uncover hidden connections that might indicate illicit behavior, making them an invaluable tool for cybersecurity.
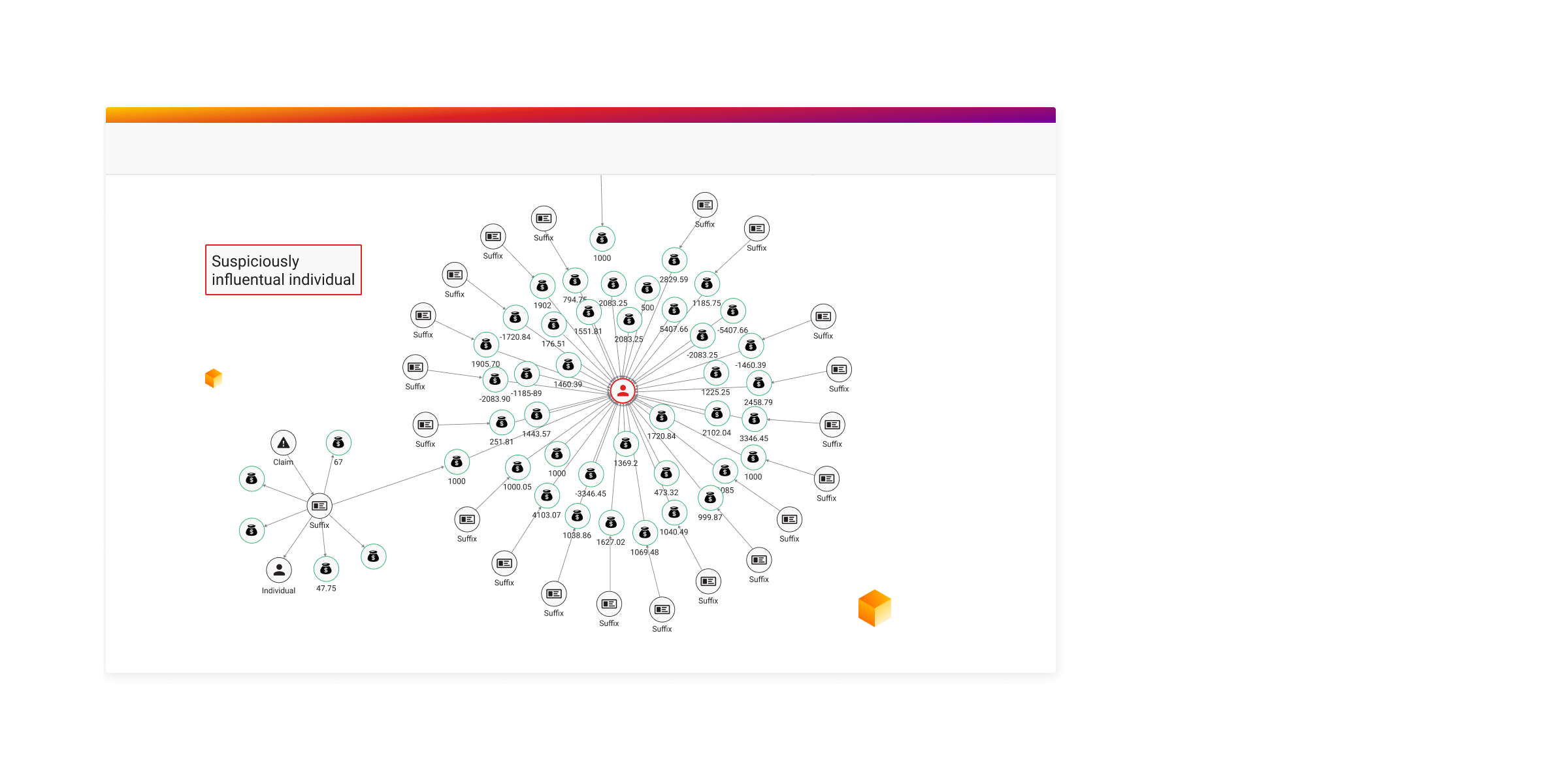
Knowledge graphs and semantic networks
Last but not least, graph databases serve as a foundation for building knowledge graphs and semantic networks. By representing data as nodes and relationships, they capture the semantics and context of information, enabling sophisticated knowledge discovery, semantic search, and data integration across disparate sources.
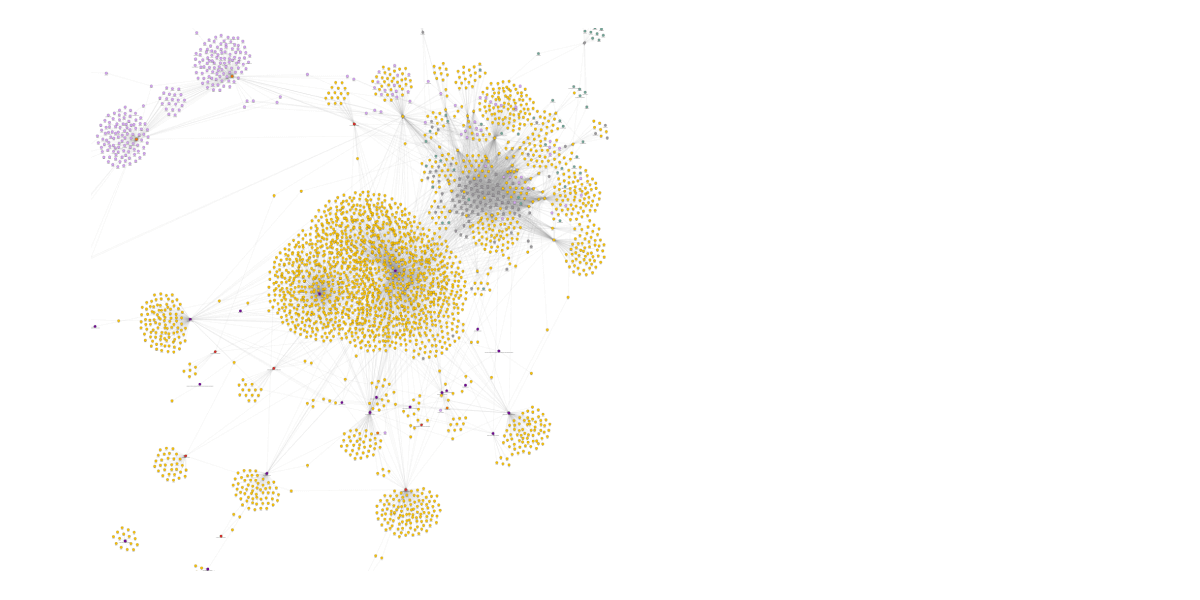
Sneak peek into graph algorithms
Surely enough, graph algorithms play a crucial role in leveraging the power of graph databases and unlocking valuable insights from connected data. In this section, we provide a sneak peek into some fundamental graph algorithms that form the backbone of graph database operations.
Breadth-First Search (BFS): Breadth-First Search is a fundamental algorithm used to explore and traverse a graph in a breadth-first manner. Starting from a given source node, BFS systematically explores all the neighboring nodes before moving deeper into the graph. This algorithm is commonly used to find the shortest path between two nodes, identify connected components, and perform level-based analysis.
Depth-First Search (DFS): Depth-First Search is another crucial graph algorithm that explores a graph with a depth-first principle. DFS starts from a given source node and traverses as far as possible along each branch before backtracking. The algorithm is useful for identifying cycles in a graph, performing topological sorting, and searching for specific nodes or patterns.
PageRank algorithm: Developed by Google's founders, PageRank is a graph algorithm used to measure the importance or relevance of nodes in a graph, particularly in web graphs. PageRank assigns each node a numerical value based on the number and quality of incoming links, and plays a vital role in search engine ranking, recommendation systems, and social network analysis.
These are just a few examples of the numerous graph algorithms available, however, graph databases employ a wide range of algorithms to perform tasks such as community detection, centrality analysis, graph clustering, and more.
Sum up
In this article, we explored the world of graph databases and their significance in modern data management. We defined graph databases and highlighted their importance in handling complex relationships and interconnected data. If you're curious and want to learn more about the fascinating world of graphs, make sure to check out our blog and give us a shout in our community.