Modeling the Data: A Key Step in Using a Graph Database
A data model is the structure of data within a given system. It defines how data is related and how it can be accessed. A good data model is important in graph databases because it helps to ensure data integrity and improve performance. A well-designed data model can also make it easier to query and update data. In this article, I'm going to show you how I went from an inefficient data model to a good one while working on my internship project at Memgraph.
Data modeling
Graph databases are powerful tools for managing and analyzing data. However, like all databases, they require careful design and planning to be effective. The data model is a critical part of this process, as it defines the structure of the data and how it’s related.
When it comes to graph databases, there are a few things that can indicate a bad model. Here are three key things to look out for:
-
Lack of relationships: Graph databases are most effective when you have a lot of tightly linked nodes. There is not a huge performance gap between relational databases and graph databases if your model generates, for example, a tree graph.
-
Data duplication: If your model generates duplicate nodes or relationships, that generally means you should optimize your model. It’s better to increase the number of relationships so you have fewer nodes.
-
Overly complex queries: If you find that you constantly have to write overly complex queries in order to get the data you need, it could be a sign that your model is not optimized. This can lead to performance issues and make it difficult to query the data.
If you find any of these issues in your graph database, it could be a sign that your model is not optimized. By addressing these issues, you can improve the performance of your graph database and make it easier to query the data.
About the project
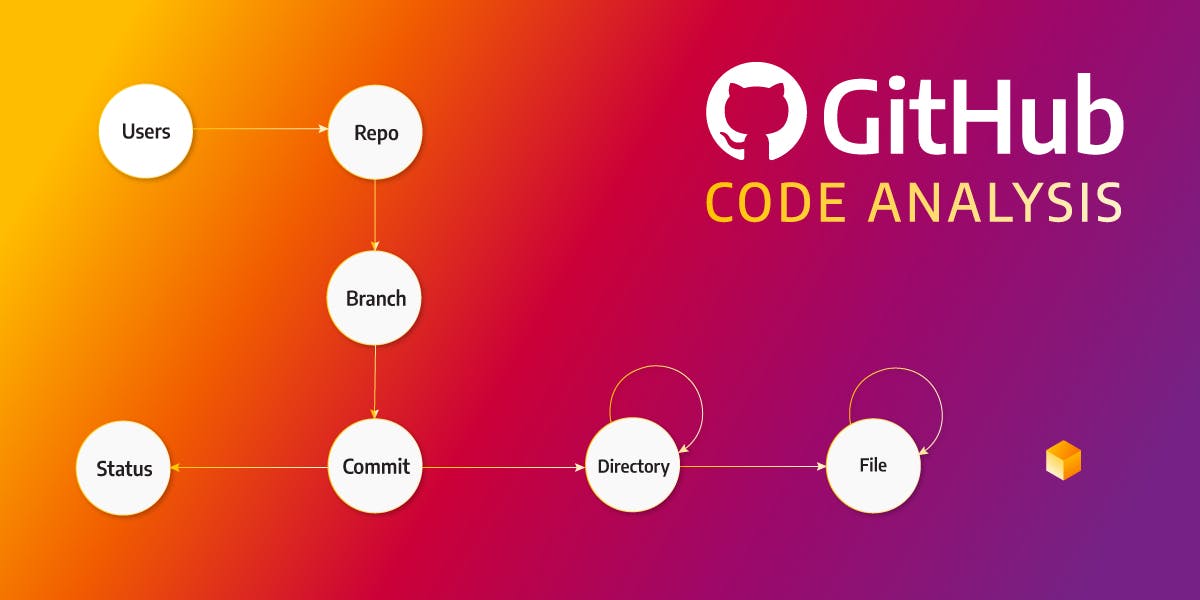
The project I have been working on during my internship is called GitHub Code Analysis. The project was made in Python and I used Memgraph as my database. The general idea was to create a graph where a user could see how every file in a GitHub repository interacts with other files. The side feature is to create a file tree of every commit in a repository and we'll focus on that issue now.
Control data
As my control data, I chose to download the latest 100 commits of the main branch from the GQLAlchemy GitHub repository. I chose that repository because it’s of medium size and because the changes between commits aren't that significant.
Initial data model
Because we’re only focusing on the file tree aspect, let’s take a look at the naive approach to the model for the file tree part.
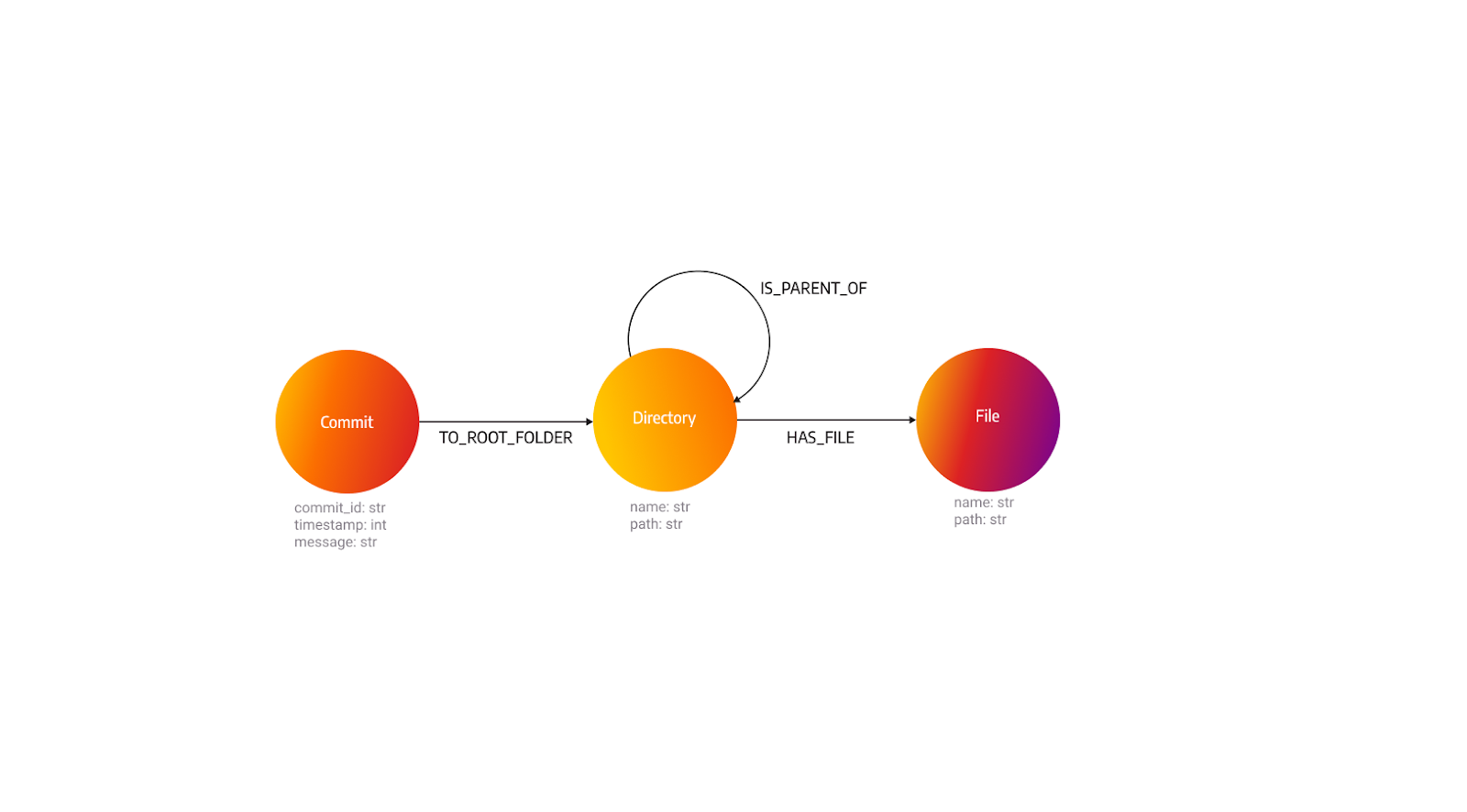
We can use the model and the control data to see how well the model performs.

From the picture, we can see that the number of relationships is equal to the number of nodes - 100. From that equation and the fact that we’re analyzing the file tree of 100 commits, we can conclude that the graph is a tree. If we take a look at the indicators of a bad model we can see that this model lacks relationships and has duplicate nodes. While this model has some flaws it’s not bad but we can do better.
How to improve on the model
Let's analyze the input data. We can notice there are a lot of files that are the same, meaning they haven't changed. We're going to take a look at how to change the file model so we can reduce the number of duplicate nodes. The question is, how do we easily check if the file already exists in the database? The answer is hashing. By hashing the file, in this example with the SHA-1 algorithm, and changing the file model to only save the file hash, we can kill two birds with one stone.
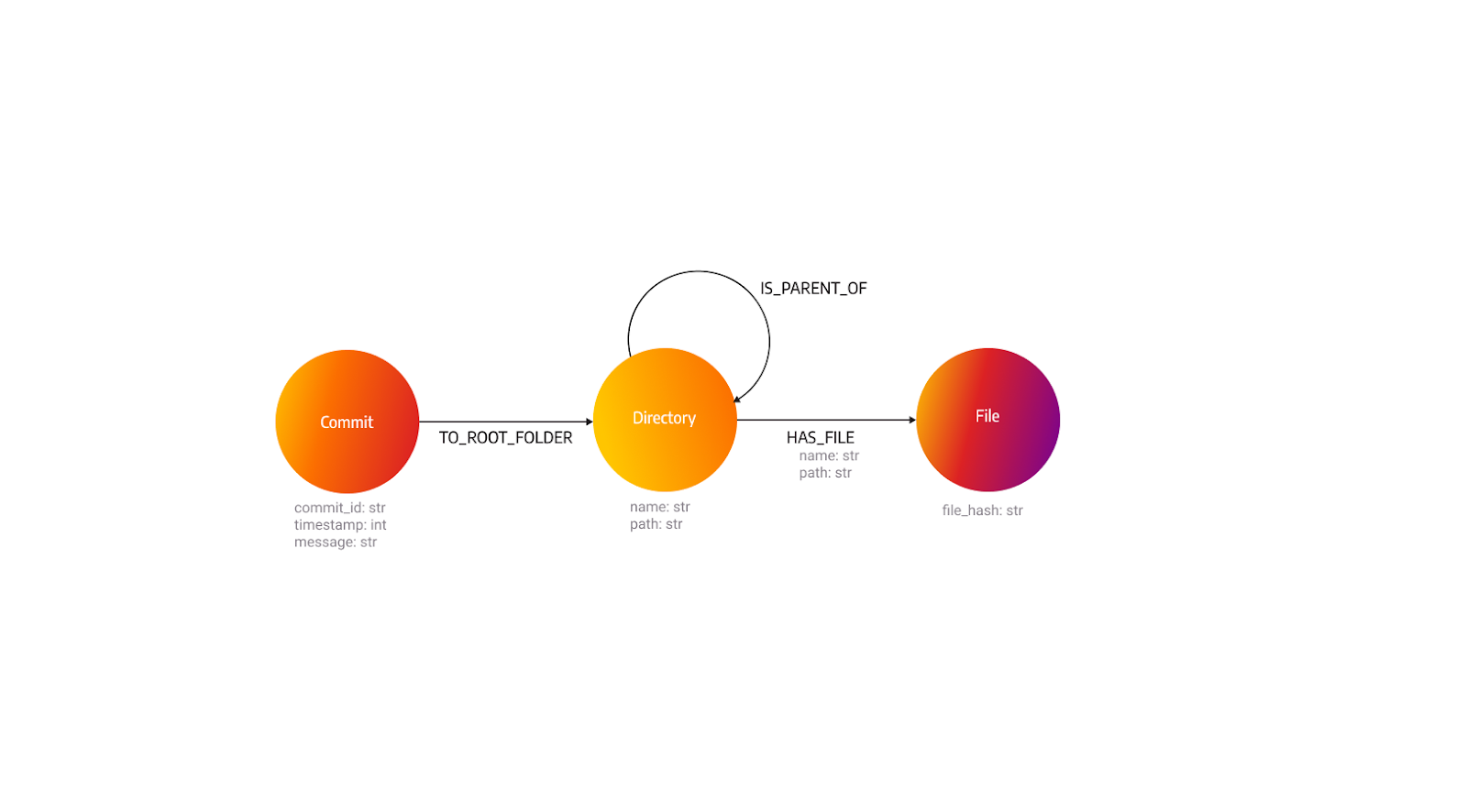
While we're reducing the number of duplicate nodes, the number of relationships stays the same, but that means that individual nodes have more connections. The filename and the path of the file will be saved in the relationship between the directory and the file.
Let’s take a look at the number of nodes and relationships for the control data.

One thing we have to keep in mind is that the complexity of queries increased because now we can’t simply search for the file node but we have to search for the relationship between a directory and a file.
What’s next? We can also optimize the directory model.
Optimizing the directory model
What if we take a similar approach to the file model, but apply it to the directory model? Let's take a look at how that would work. The first issue is the same as we had with the file: How can we ensure that the node won’t be duplicated? Fortunately, we already have the data for that - the path. The second question is: How can we connect the directories together? We can put the commit ID in the connections between directories because we need a way to differentiate directories between commits. We also need to add the commit ID to the connection between the directory and the file.
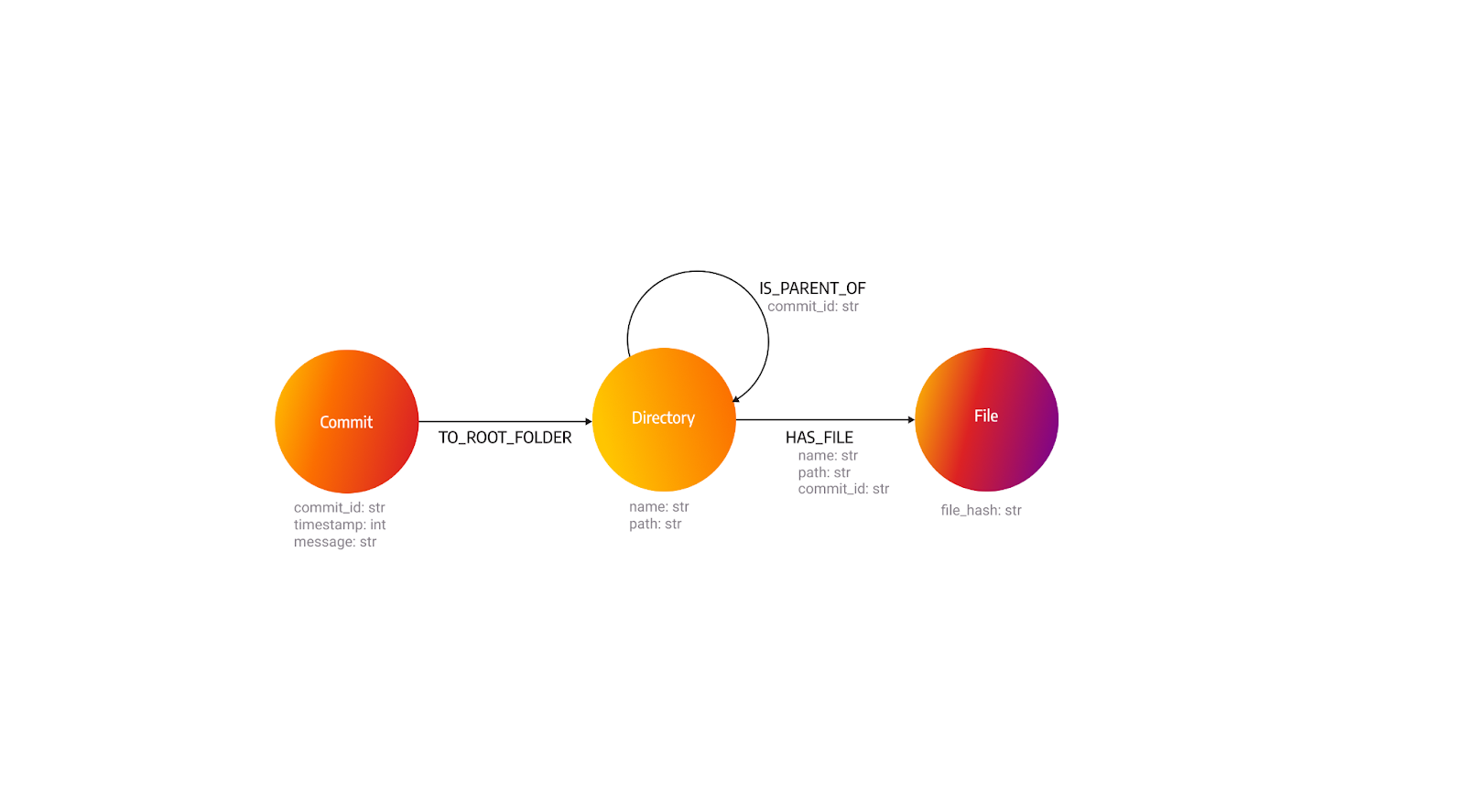
And now for the resulting number of nodes:

Again we can see that the amount of connections hasn’t changed but the amount of nodes is reduced.
Difference in performance
The difference in the time it takes to input the data is not noticeable, but the difference is noticeable when we look at the search speed. Let’s see what happens when we want to get the entire file tree for a specific commit. We’ll be using Breadth-first search as the algorithm for traversing the nodes. Between the first and the second model, the search speed is pretty similar, but when we compare the second and the third model the search is slower when querying data modeled with the third model. The reason for this is that, for every node that the algorithm visits, it has to find the exact relationship for the specific commit. This is done iteratively, meaning that the database has to go through every relationship and find the specific relationship. And it gets slower with every new commit. This is the reason I chose the second data model for my application.
Conclusion
The data model is really important because it can determine the memory usage, and the speed of your graph database and it can also determine what you can do with your data. It’s not always better to reduce the amount of memory you’re using because that can affect the speed of your graph database. My recommendation is to analyze the data you’re trying to model before you create the model. Changing the model in the middle of the project is pretty annoying. Also, if your model is really complex to the point you’re trying to work it out for hours, chances are your model is probably not efficient.