
Manage All Your Data Lineage Needs With Memgraph Graph Analytics
Enterprises often work with large amounts of data scattered across data warehouses without a common data model. Making sense of the entire data landscape is accomplished with data lineage, but this is often easier said than done.
Just building the lineage graph can often mean funneling data from multiple sources into a database. Once you’ve done that and deployed the DB on a server, you probably want to access it with familiar tools to maintain productivity. This is only possible if there are adequate interfaces. Moreover, no matter what interface you use, the DB needs to be fast so that queries don’t hang on the server.
Memgraph was built with performance and compatibility in mind precisely so that it can tackle these kinds of challenges – the rest of this post lays out how it rises up to the task.
Optimized architecture
A data lineage DB is the single source of truth for all data assets in your organization. When you connect to the database server, you can track and analyze data flows by running queries or interfacing with the database via no-code data intelligence apps. It is important for the database to be high-performance. Otherwise, operations can take an eternity to execute and jeopardize reliable systems by hanging the server.
When selecting a database, you should consider ease of use and the following technical concerns: speed and resource usage.
The speed of the two most frequent database tasks (data updating and retrieval) is determined by memory read/write cycles. In light of this, Memgraph is an in-memory database in order to leverage the higher speed of primary storage (RAM & cache) over disk storage.
For economical resource usage, Memgraph is written in C++ because of the following advantages:
- reduction of memory footprint by manual memory management
- C++ code can be immediately run because it compiles to binaries (no need for code interpretation at runtime, unlike with the Java-based Neo4j)
However, this is not the whole story. When you switch to high-performance DBs like Memgraph, you will also see ease-of-use gains. As faster queries are less likely to hang your server, reliability is higher and development smoother.
Database model
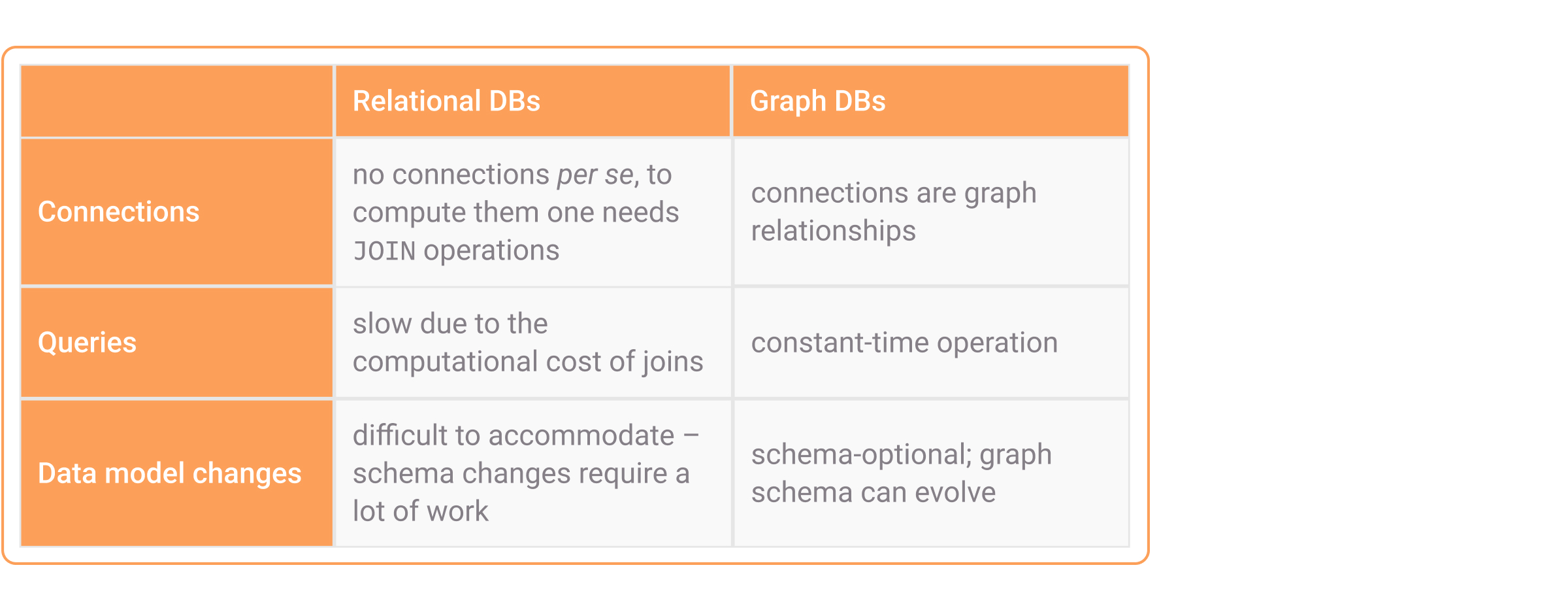
Lineage data is highly connected and sensitive to changes in the data landscape. Graph databases like Memgraph have fast, simple connection operations, and incorporating lineage updates is often as simple as adding a graph relationship. Compare them point-by-point with relational DBs below:
Real-time analytics
Graph analytics is used alongside visual tools to make sense of data lineage graphs and find answers to business problems. Organizations with complex data landscapes find analytics especially useful because it is easier to study large graphs with exact, objective methods than with visual tools.
For example, one can do impact analysis assisted by centrality algorithms, or identify data redundancies by applying similarity metrics - for a deeper dive, check this post out.
Memgraph Platform includes MAGE, a library of graph data science & ML methods. With MAGE, running analytics is as simple as calling graph methods from queries.
The highlight of MAGE are the dynamic algorithms, which update previously computed values without the need to process the entire graph. Dynamic algorithms are faster if your lineage graphs frequently receive small updates, for example:
- in organizations with complex data infrastructures
- when assessing possible changes to the data landscape
If you have specialized data questions, you can implement custom analytics in Python or C++ using Memgraph’s optimized graph APIs. As the APIs work with the graph itself, they don’t waste resources creating an internal copy of the graph. The MAGE API distinguishes two types of graph methods:
- functions: for light-weight methods returning single values
- procedures: full-featured (return a result stream, may modify the graph)
Convenient interfaces
No man is an island, and neither is Memgraph. On the software side, mapping the data lineage is a “team effort” that involves not only the database but also various utilities that do tasks such as data ingestion, parsing query logs and track data transactions, transform collected information into lineage data, and so on.
You can work around this conundrum and use streams to pass the information collected from logged queries and data transactions to Memgraph. Effectively, a streaming DB acts as a real-time data repository when connected to data streams.
Interfacing with the database that stores lineage data is easier for data engineers and analysts when they can use the tools they’re familiar with. To this end, one can access Memgraph with clients. This way, it is possible to use it as the backend of data lineage dashboards and other tools that need to interface with the DB. There are clients for a total of 8 programming languages and devs can easily pair Memgraph with tools they know the best. All in all, the clients are there so that users can work productively.
Why Memgraph?
In data lineage solutions, the database has the main role on account of storing the lineage – the single source of truth about your organization’s data.
Memgraph is a fast in-memory graph database whose data model allows efficient handling of lineage data, and real-time analytics with the MAGE library. Developers can easily connect the DB to streams in order to load it up with data and, beyond that, use clients to interface with it in the programming language they know the best.
Get Memgraph to make sense of your data landscape and solve tasks in compliance, impact analysis, and more! You can discuss your work on Discord or contact our Solutions team there.