
Announcing Memgraph's High Availability Automatic Failover: Developer-Ready
As your applications transition from development to production, there’s a demand for constant availability and robust performance. Recognizing this, Memgraph announces developer-ready High Availability Automatic Failover (HA), designed for resilience and ease of deployment. This feature ensures that your database not only supports your application in real-time but also remains resilient in the face of potential failures.
High Availability in Memgraph
For production environments, it's important to have a database that is both resilient and performs well. Memgraph’s High Availability Automatic Failover, which comes with the Enterprise license, provides a straightforward and effective solution to keep your database strong and always running.
Automatic Failover with Enterprise License
Previously, setting up high availability with Memgraph required manual code. Now, with the Enterprise license, no additional coding or extensive setup is needed. Our system is designed to automatically detect failures and reroute traffic to maintain continuous availability.
MAIN and REPLICA Dynamics
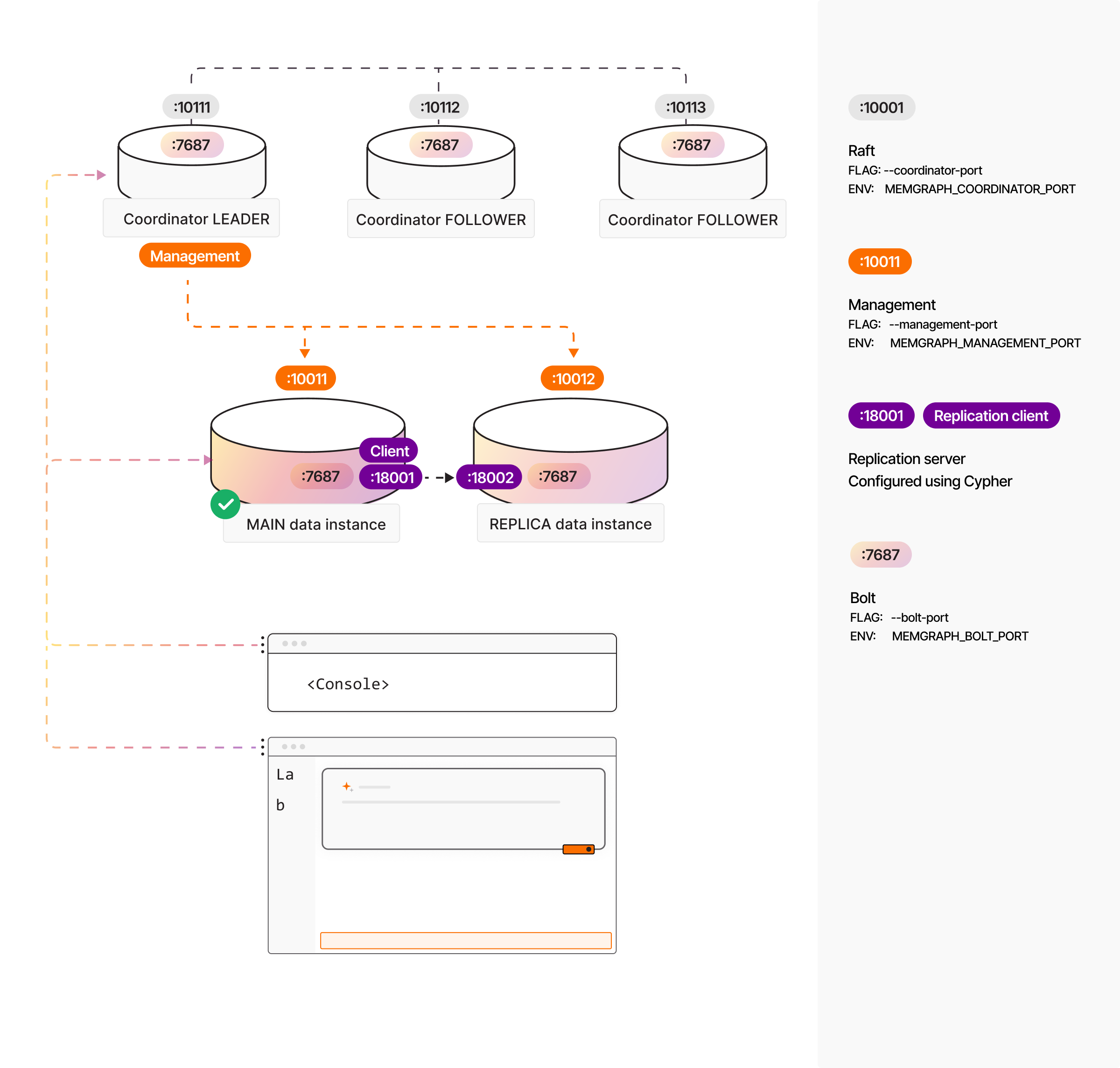
At the core of Memgraph's high availability feature is the MAIN-REPLICA mechanism. The MAIN instance, responsible for all write operations, is automatically replicated across multiple REPLICA instances. These replicas handle read operations and are ready to be promoted to a MAIN instance if the current MAIN fails, ensuring minimal disruption.
Synchronous and Asynchronous Replication Modes
Memgraph supports synchronous (SYNC) and asynchronous (ASYNC) replication modes. SYNC mode prioritizes data consistency and partition tolerance, ideal for scenarios where data integrity is paramount. ASYNC mode, on the other hand, emphasizes availability and partition tolerance, suitable for environments where write availability is crucial.
Enhanced Through the Raft Consensus Algorithm
To achieve high availability, Memgraph implements the Raft consensus algorithm, eliminating single points of failure by adding redundancy to the system. Memgraph achieves high availability through a combination of replication for data instances and Raft for coordination among the coordinators. This means that as long as a majority of the servers are operational and can communicate with each other and with clients, the cluster will remain fully functional. We recommend setting up an odd-sized cluster to maximize resilience.
Why High Availability Matters
The nature of applications that use graph databases demands that the database remains available and ensures transactional integrity and performance consistency across its network of nodes and relationships. This capability is vital for maintaining business continuity, protecting revenue, and enhancing customer satisfaction.
Disruptions in availability can lead to significant delays in decision-making and operational inefficiencies. High availability ensures no disruption in service and minimizes downtime, which is vital for customer satisfaction and regulatory compliance.
When to Use High Availability (Use Case)
Memgraph's high availability automatic failover feature is ideal in scenarios where data and its availability directly impact business outcomes. For example, in financial services, where transaction continuity and accuracy are paramount, ensuring that there's always a MAIN instance available to handle writes without interruption is crucial. Similarly, in e-commerce platforms, where customer experience can directly influence revenue, maintaining uninterrupted service during high-traffic events like sales or promotions is essential.
Setting Up Memgraph High Availability
This quick start guide outlines the basic steps for setting up the high-availability cluster using Memgraph. For detailed step-by-step instructions, refer to the Memgraph docs.
Overview
High Availability in Memgraph is achieved through replication and coordination managed by the Raft protocol. A typical high availability setup includes:
-
MAIN instance: Handles all write queries.
-
REPLICA instances: Handle read queries.
-
COORDINATOR instances: Manage the state of the cluster.
Initial Setup
Step 1: Enable High Availability. Start Memgraph with the high availability flag enabled.
--experimental-enabled=high-availability
Step 2: Configure cluster nodes.
-
Data instances. Distinguish using the
--management-portfor RPC network communication. -
Coordinator instances. Start with
--coordinator-idand--coordinator-portto manage Raft protocol communications.
Step 3: Instance roles.
-
At startup, set data instances with
--replication-restore-state-on-startup=trueto ensure they maintain their role (MAIN or REPLICA) across restarts. -
Coordinators need to ensure there's always one writable data instance and manage transitions and failovers.
Configuration and Management
-
Register Instances: Coordinators register new instances and continually check their status.
-
Failover Management: Coordinators monitor the health of instances and initiate failover procedures when necessary.
-
Configuration Changes: Use bolt+routing for client connections, ensuring clients always communicate with the correct MAIN instance.
Example Setup Commands
Start Coordinator Instances
docker run --name coord1 -p 7687:7687 -p 7444:7444 -p 10111:10111 memgraph/memgraph-mage --experimental-enabled=high-availability --coordinator-id=1 --coordinator-port=10111
docker run --name coord2 -p 7688:7687 -p 7445:7444 -p 10112:10112 memgraph/memgraph-mage --experimental-enabled=high-availability --coordinator-id=2 --coordinator-port=10112
docker run --name coord3 -p 7689:7687 -p 7446:7444 -p 10113:10113 memgraph/memgraph-mage --experimental-enabled=high-availability --coordinator-id=3 --coordinator-port=10113Start Data Instances
docker run --name instance1 -p 7690:7687 -p 7447:7444 -p 10011:10011 -p 10001:10001 memgraph/memgraph-mage --experimental-enabled=high-availability --management-port=10011 --replication-restore-state-on-startup=true
docker run --name instance2 -p 7691:7687 -p 7448:7444 -p 10012:10012 -p 10002:10002 memgraph/memgraph-mage --experimental-enabled=high-availability --management-port=10012 --replication-restore-state-on-startup=true
docker run --name instance3 -p 7692:7687 -p 7449:7444 -p 10013:10013 -p 10003:10003 memgraph/memgraph-mage --experimental-enabled=high-availability --management-port=10013 --replication-restore-state-on-startup=trueDisclaimer
Note that the information provided in this blog post about Memgraph's High Availability Automatic Failover is subject to change as we continue to develop and improve our features. We recommend regularly consulting the official Memgraph documentation for the most up-to-date and detailed instructions and information. The procedures and configurations described here may evolve, and the documentation will always provide the latest guidelines and best practices for implementing high availability with Memgraph.
Register Instances and Configure Cluster
Start the mgconsole with the following command:
mgconsole --port=7687 # Connect to a coordinatorRun the following commands within mgconsole to configure your instances:
ADD COORDINATOR 2 WITH CONFIG {"bolt_server": "127.0.0.1:7688", "coordinator_server": "127.0.0.1:10112"};
ADD COORDINATOR 3 WITH CONFIG {"bolt_server": "127.0.0.1:7689", "coordinator_server": "127.0.0.1:10113"};
REGISTER INSTANCE instance_1 WITH CONFIG {"bolt_server": "127.0.0.1:7687", "management_server": "127.0.0.1:10011", "replication_server": "127.0.0.1:10001"};
REGISTER INSTANCE instance_2 WITH CONFIG {"bolt_server": "127.0.0.1:7688", "management_server": "127.0.0.1:10012", "replication_server": "127.0.0.1:10002"};
REGISTER INSTANCE instance_3 WITH CONFIG {"bolt_server": "127.0.0.1:7689", "management_server": "127.0.0.1:10013", "replication_server": "127.0.0.1:10003"};
SET INSTANCE instance3 TO MAIN;Deployment Options
To ensure a healthy cluster state and optimal setup for various environments, Memgraph offers multiple deployment strategies tailored to meet the specific needs of different types of users. Below we detail the key deployment options available:
-
FLAGS - A suitable deployment option for developers who prefer a hands-on approach when setting up their environment.
-
Environment Variables (ENV VARS) - An efficient way to deploy in cloud environments. This method simplifies configuration management by decoupling it from the application code. It is especially well-suited for services such as AWS Elastic Container Service (ECS) where environment variables can be managed as part of the service configuration.
-
Kubernetes - With the release of Memgraph v2.17 on May 22, 2024, we are introducing foundational support for Kubernetes. Further developments are underway to provide a comprehensive Kubernetes setup including a Helm Chart and a custom operator, which will facilitate high availability (HA) configurations. For the latest updates and resources, visit our GitHub repository.
Monitoring and Maintenance
Coordinators perform regular health checks and manage the state of each instance.
To verify the status and role of each cluster component, use this code snippet:
SHOW INSTANCES;This is only a brief overview to get you started with Memgraph's High Availability feature. For comprehensive details, including handling node failures and configuring advanced Raft parameters, please consult the official Memgraph High Availability docs.
To quickly get you started, here's a demo video from our Engineering team!
Conclusion
If you're ready to see how Memgraph can enhance your system architecture or if you have any queries about setting up high availability for your specific use case, don’t hesitate to reach out.
Book a 30-minute call with one of our engineers or join the Discord community to connect with other developers engaged in real-time graph analytics with Memgraph. Your journey towards a resilient, always-available application starts here.
Book a Call with Memgraph DX Team or Join Memgraph Discord Community