
Apache Pulsar vs Apache Kafka - How to Choose a Data Streaming Platform
While Apache Kafka may be the most popular solution for data streaming needs, Apache Pulsar has picked up a lot of popularity in recent years. While both have their pros and cons, there are specific use cases that fit each product better, but it seems that Kafka has become the de-facto solution for most problems, given its popularity. We will try to provide you with a high-level overview of their similarities and differences so you can make a more informed and clear choice.
Apache Kafka
Apache Kafka is a distributed event streaming platform used by thousands of organizations, making it the most famous data streaming platform at the moment. It's an open-source software platform developed by the Apache Software Foundation, and it's implemented in Scala and Java. The project aims to provide a unified, high-throughput, low-latency platform for handling real-time data feeds.
Apache Pulsar
Apache Pulsar is a cloud-native, distributed messaging and streaming platform originally created at Yahoo! and now a top-level Apache Software Foundation project. Pulsar is a multi-tenant, high-performance solution for server-to-server messaging. It was implemented to address the shortcomings of Kafka by enabling easier scalability and adding missing features like geo-replication.
Overview
| Apache Kafka | Apache Pulsar | |
|---|---|---|
| Open-source | Yes | Yes |
| License | Apache License 2.0 | Apache License 2.0 |
| Architecture | Kafka + ZooKeeper* | Pulsar + ZooKeeper + BookKeeper + RocksDB |
| Message consumption | Pull | Push |
| Storage | Log | Index |
| Managed Cloud service | Confluent Cloud | StreamNative Cloud |
| Clients | C/C++, Python, Go, Erlang, .NET, Clojure, Ruby, Node.js, Perl, PHP, Rust, Storm, Scala DSL, Clojure, Swift | Java, Go, Python, C++, Node.js, WebSocket, C# |
*ZooKeeper is being phased out from Kafka
License
When it comes to the license, both Apache Kafka and Apache Pulsar are fully open source projects of the Apache Software Foundation. All of your open-source needs should be covered.
Architecture
In terms of architecture, Pulsar seems to be a bit more complex. Each Pulsar instance can consist of multiple clusters. These clusters in term consist of multiple brokers as well as ZooKeeper and BookKeeper clusters. This is a result of decoupling brokers from the storage layer, which has its pros and cons.
This means that Pulsar isn't quite as easy to understand and operate, especially considering that Pulsar, ZooKeeper, and BookKeeper are distributed systems. Pulsar also introduces more configuration parameters than Kafka, which makes it a bit harder to get started.
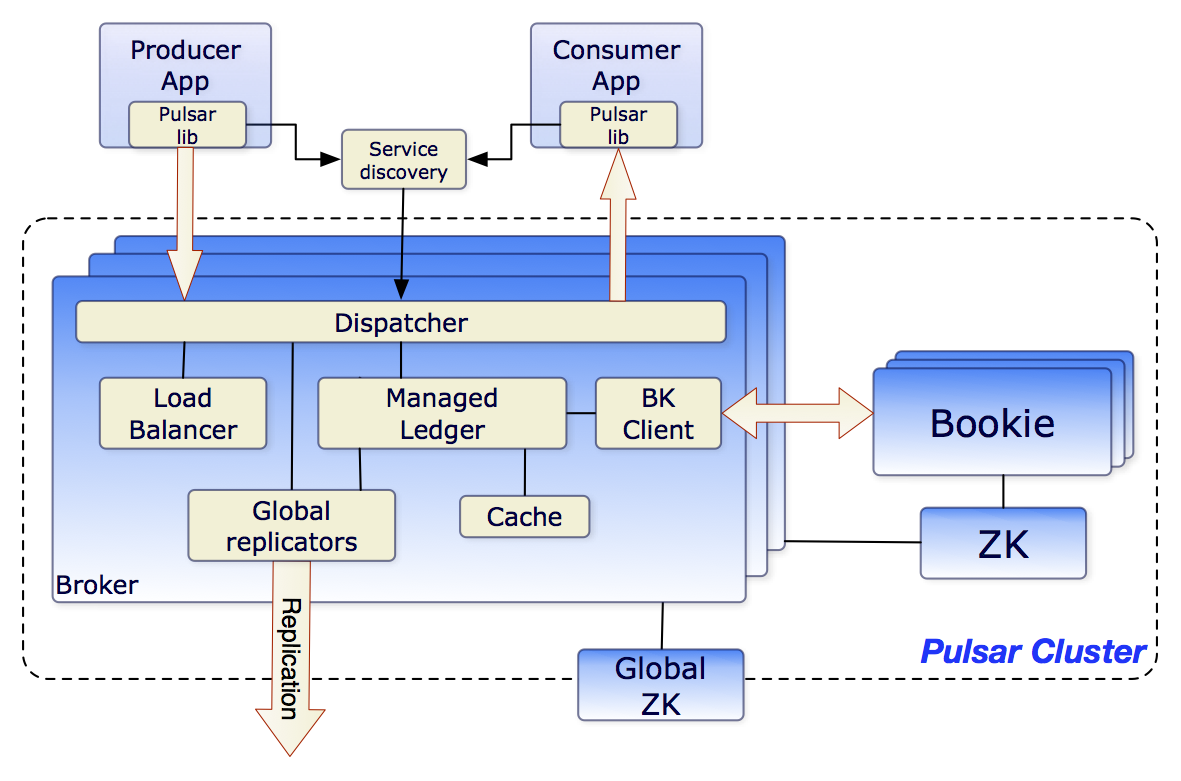
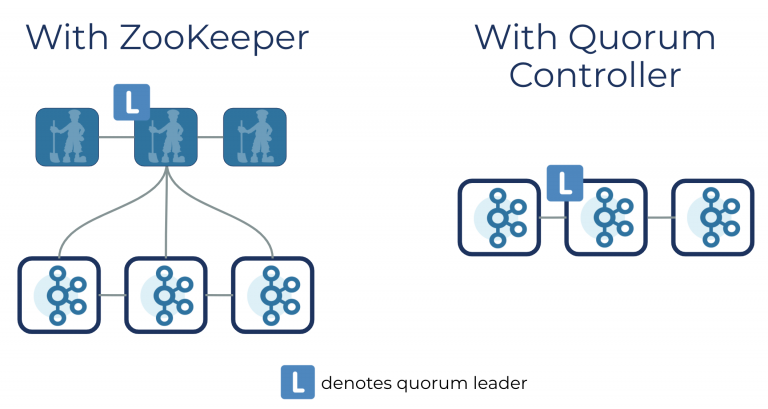
Kafka, on the other hand, only uses ZooKeeper, which is being phased out at the moment. This results in a much simpler architecture that is easier to understand and operate. Once ZooKeeper becomes completely obsolete and replaced with the new quorum controller, all the metadata responsibilities will be handled by the Kafka cluster itself.
Message consumption
When it comes to Kafka, consumers pull messages from the server. Long-polling ensures that new messages are consumed almost instantaneously.
Pulsar is based on the pub-sub pattern (publish-subscribe). Producers publish messages to the server while consumers need to subscribe in order to receive them.
Storage
Is it possible to store data within Kafka and Pulsar? The answer is yes, both systems offer long-term storage solutions, but their underlying implementations differ widely. While Kafka uses logs that are distributed among brokers, Pulsar uses Apache BookKeeper for storage.
BookKeeper also offers tiered storage, which means that older and less used data can be stored on cost-saving solutions.
Brokers
A Kafka client communicates with Kafka brokers to write or read events. Once received, the brokers will store the events in a durable and fault-tolerant manner for as long as needed. A big selling point of Apache Pulsar is stateless brokers. These brokers can be started quickly and in large numbers to accommodate higher demand.
In Kafka, each broker uses a complete log for its partitions. These brokers need to synchronize data with all the other brokers for the same partition as well as their replicas. Pulsar, on the other hand, stores the state outside of the brokers which separates them completely from the data storage layer.
Stream processing
Both Kafka and Pulsar provide some kind of stream processing capability, but Kafka is much further along in that regard. Pulsar stream processing relies on the Pulsar Functions interface which is only suited for simple callbacks. On the other hand, Kafka Streams and ksqlDB are more complete solutions that could be considered replacements for Apache Spark or Apache Flink, state-of-the-art stream-processing frameworks. You could use them to build streaming applications with stateful information, sliding windows, etc.
Performance
There are many benchmarks out there, but it always comes down to the specific use case and setup. Members from both communities have argued in favor of their respective platforms, but it's very hard to declare a clear winner. The most likely scenario is that you will be happy with both systems when it comes to performance and if not, you always have the option of trying Redpanda.
A good rule of thumb would be that Kafka aims for high throughput while Pulsar is invested in low latency. If you want to check out the benchmarks by yourself, I suggest you take a look at:
- Benchmarking Apache Kafka, Apache Pulsar, and RabbitMQ: Which is the Fastest? by Confluent
- Benchmarking Pulsar and Kafka - A More Accurate Perspective on Pulsar’s Performance by StreamNative
Documentation, community and support
Even if both platforms cover your needs, it often comes down to other factors, such as the availability of support and educational resources. Because Kafka is more popular and established, the size and activity of its community are far greater than that of Pulsar. With over two hundred thousand questions on Stack Overflow, it's not a surprise that working with Kafka could be considered a safer bet.
But all is not lost for Pulsar in this regard. They provide extensive documentation, and the smaller size of the community allows them to interact in a more direct and personal manner with most developers who are using their product.
Conclusion
As with any other software solution out there, it is essential to consider your own specific needs. You should try out all the available options whenever possible, as theoretical benefits can quickly be overshadowed by lacking documentation or complex maintenance.
I would love to provide a definitive answer on which platform is better, but both Pulsar and Kafka are viable production-ready platforms that offer similar features. However, their architecture sets them very much apart and could turn out to be a deal-breaker depending on your use case.
If you want to keep the conversation going or have some questions regarding the topic, join our Discord server and leave us a comment. You can also check out our stream processing example using Redpanda and Memgraph.