
How Do LLMs Work?
When someone says "AI," most people think, "Oh, you mean ChatGPT, right?" And they're not wrong—ChatGPT has become a de facto standard of a Large Language Model (LLM). It powers some of the coolest generative AI tools out there today that everyone uses. But let’s zoom out because LLMs, through a slick UX of ChatGPT, are just one slice of the big AI pie.
The AI Family Tree
Think of AI like a sprawling family tree. At the top, you've got AI—a catch-all term for anything that makes machines "smart." Branching off are areas like search algorithms, machine learning, and deep learning. Then, if you narrow it down further, you’ll hit generative AI—the cool sibling that creates stuff.
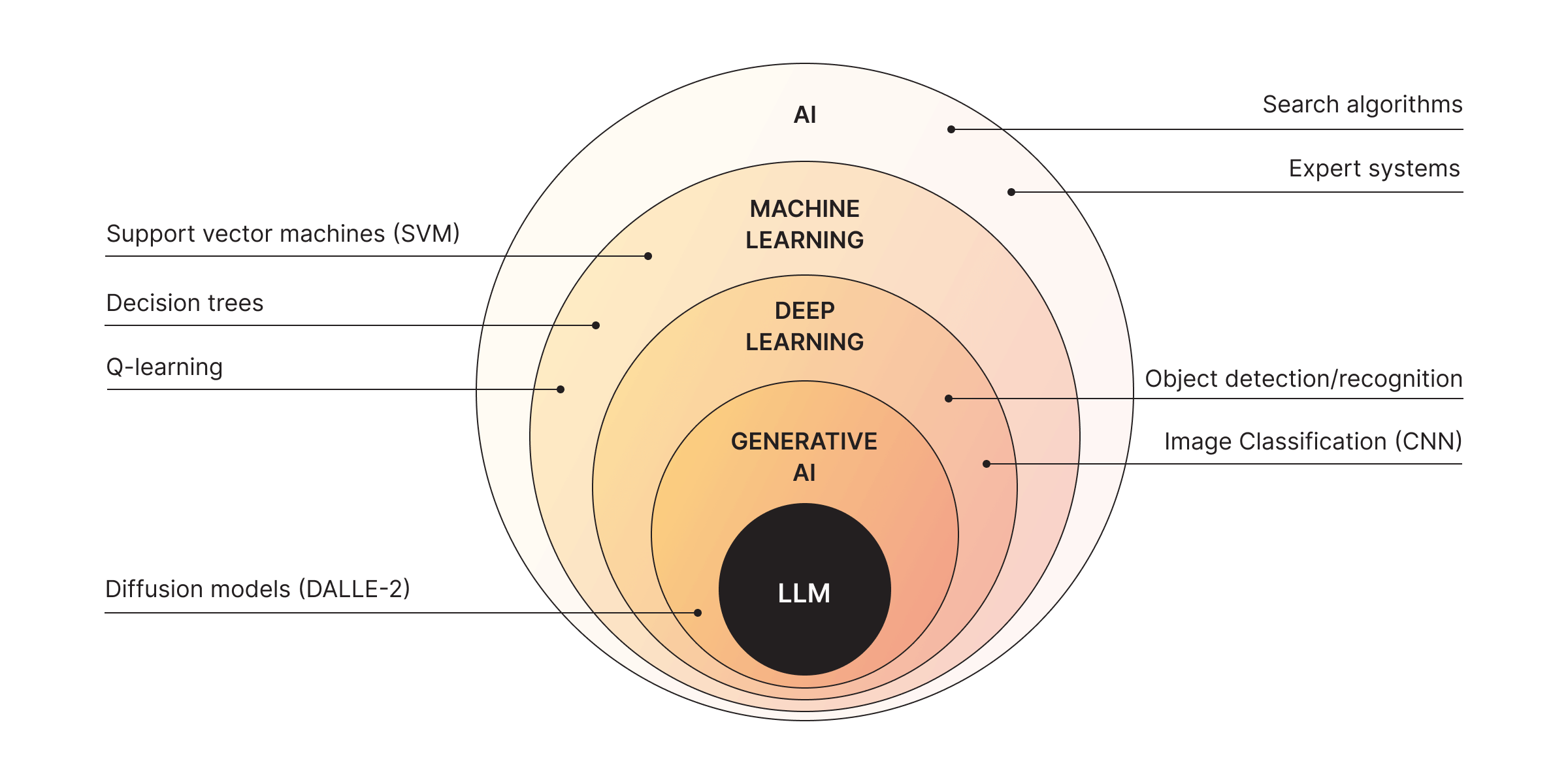
Generative AI includes tools like DALLE-2, which generates new images from prompts, and yes, ChatGPT, which does the same magic but with text. ChatGPT and its cousins rely on LLMs, which are trained on enormous datasets of text.
So, how do LLMs work? Let’s take a peek under the hood.
What LLMs Actually Do
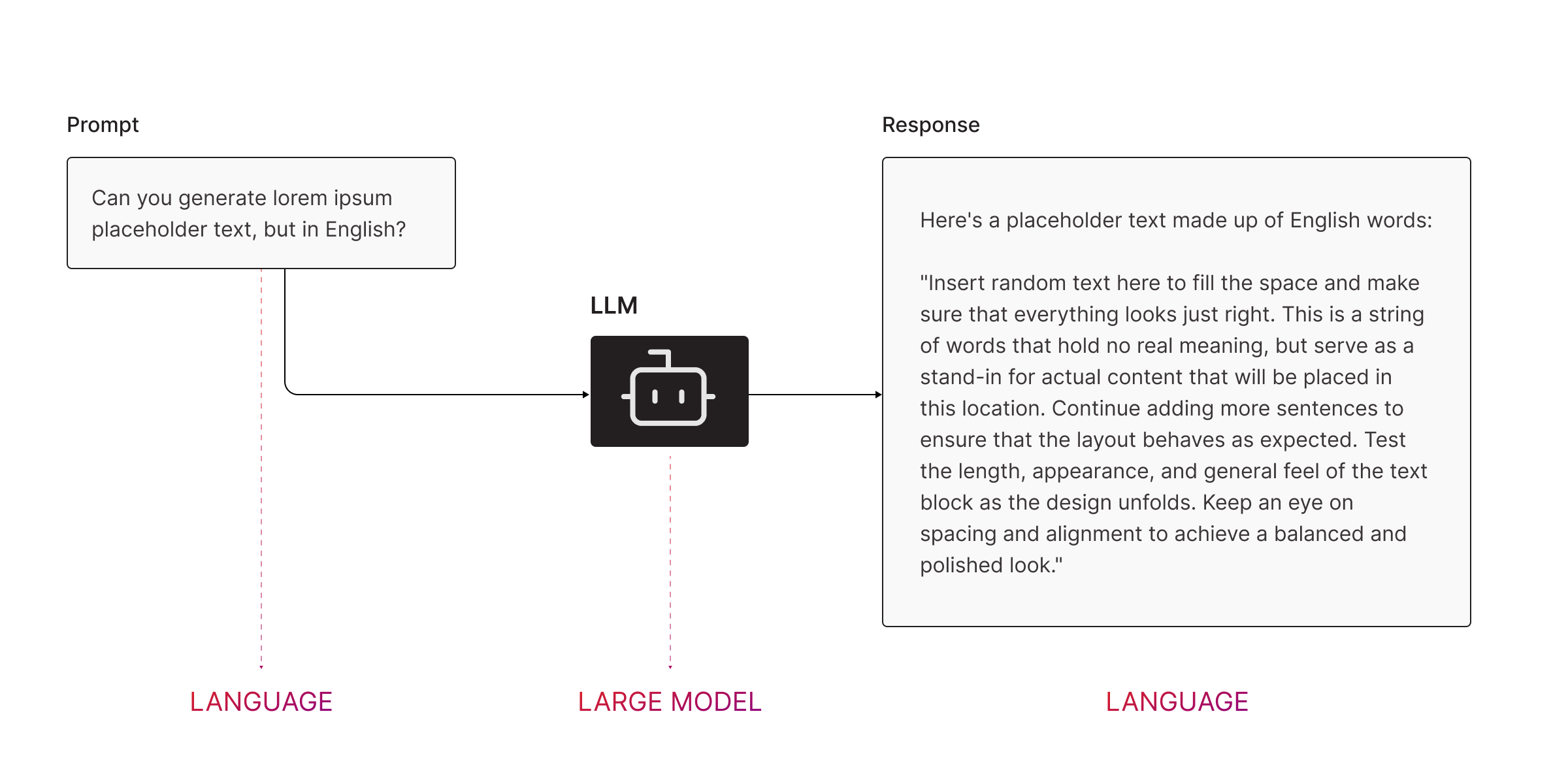
At a high level, here’s how an LLM works:
- You ask it a question (prompt). Example: “Write a summary of the latest Marvel movie.”
- It predicts the most likely next word. That’s right—it’s all just a giant, super sophisticated and heavily weighted guessing game. The LLM uses probabilities to decide, word by word (or token by token if you want to be precise), what should come next.
- It spits out a response. After weighing each word against a dozen others and making a decision between them hundreds or thousands of times in a row, voilà, you have your answer.
What’s the Secret Sauce?
LLMs are "large" because they’ve been trained on massive datasets—think everything from Wikipedia to Reddit comments to books (some pirated, some not, as highlighted by Meta's alleged use of pirated books to train its AI models). They’ve crunched through billions (or even trillions) of words, learning patterns, associations, and grammar.
But here’s the twist:
**LLMs don’t *understand* anything.** They’re not "thinking" or "reasoning." They’re essentially sophisticated parrots, mimicking patterns they’ve seen in their training data.
Two Big Limitations of LLMs
Now, if you’ve ever used ChatGPT and thought, “Wow, this is amazing,” and then five minutes later thought, “Wait, what is it even talking about?”—you’re not alone. That’s because LLMs have some serious limits:
1. The Context Window
If you want relevant answers based on your data—pulled from all the gazillion of things an LLM was trained on—it needs to be fed that information first. But LLMs can only “remember” so much at once. For example, ChatGPT (based on GPT-4) has a context window of 8,000 tokens. That’s like reading 5–10 pages of a book. Want to feed it more? Sorry, it’s out of memory.
Even the LLM with the biggest context window—Gemini 1.5 Pro—doesn’t cut it. Sure, it can handle up to 1 million tokens, which sounds impressive. But in the real world, an enterprise might have 10 times that in documents, emails, and reports. At that scale, even the biggest context window quickly runs out of room.
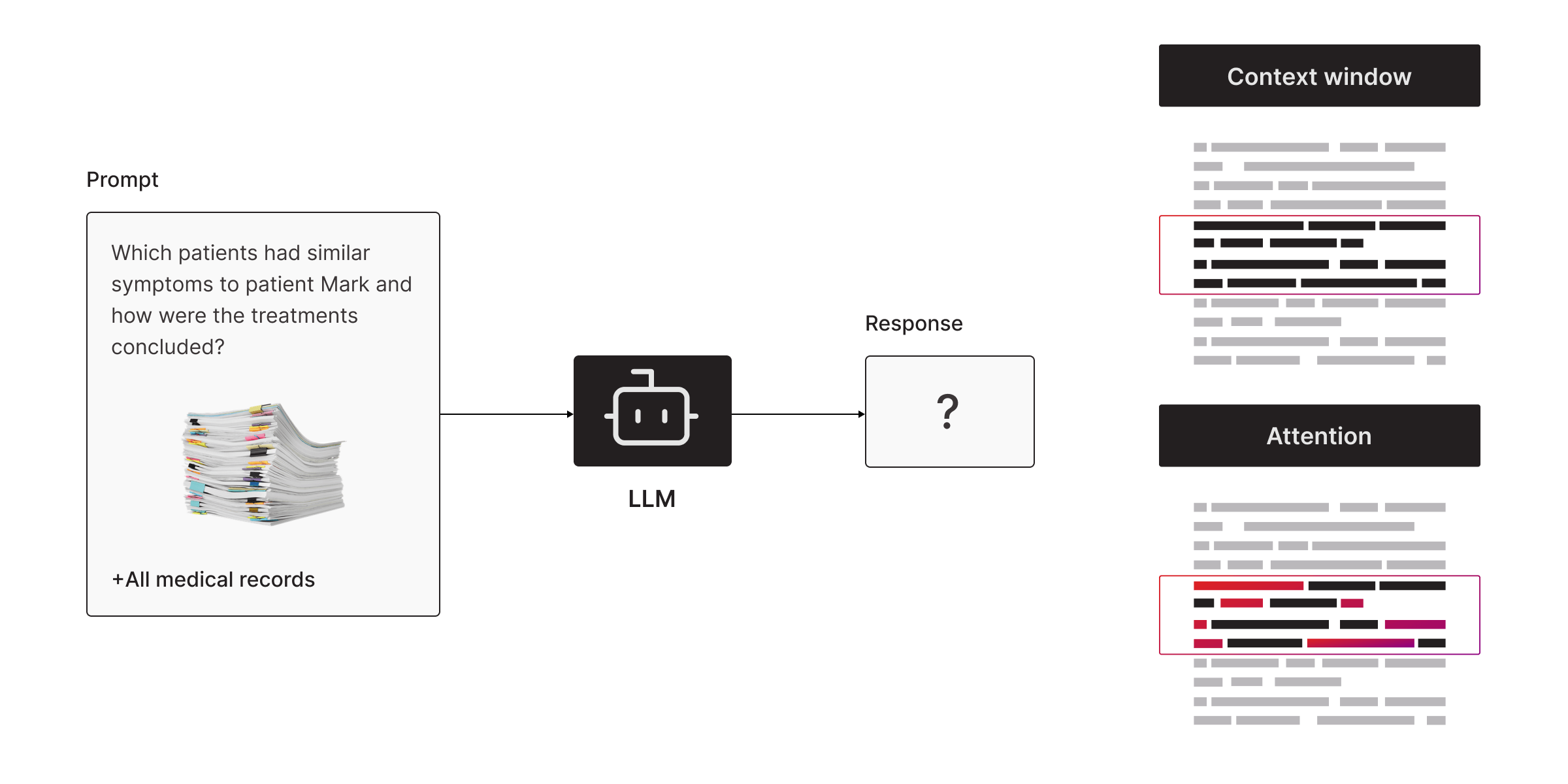
2. Attention Issues
Even within that context window, the LLM may focus on the wrong details. It’s like a dog getting distracted by a squirrel—it grabs onto whatever seems most relevant but might miss the big picture.
Why Do These Limitations Matter?
Imagine you’re a doctor asking an LLM to analyze medical records for a patient named Mark. You want to know which patients had similar symptoms and how they were treated. Here’s what happens:
- The LLM doesn’t know your specific data because it wasn’t trained on it. It only knows general medical knowledge.
- Even if you dump all your records into the prompt, it might miss critical details because of the context window and attention limits.
So, while LLMs are great at generic tasks, they struggle with specific, nuanced questions based on proprietary data.
Making LLMs Smarter: RAG and Fine-Tuning
How do you overcome these limitations? There are two popular approaches:
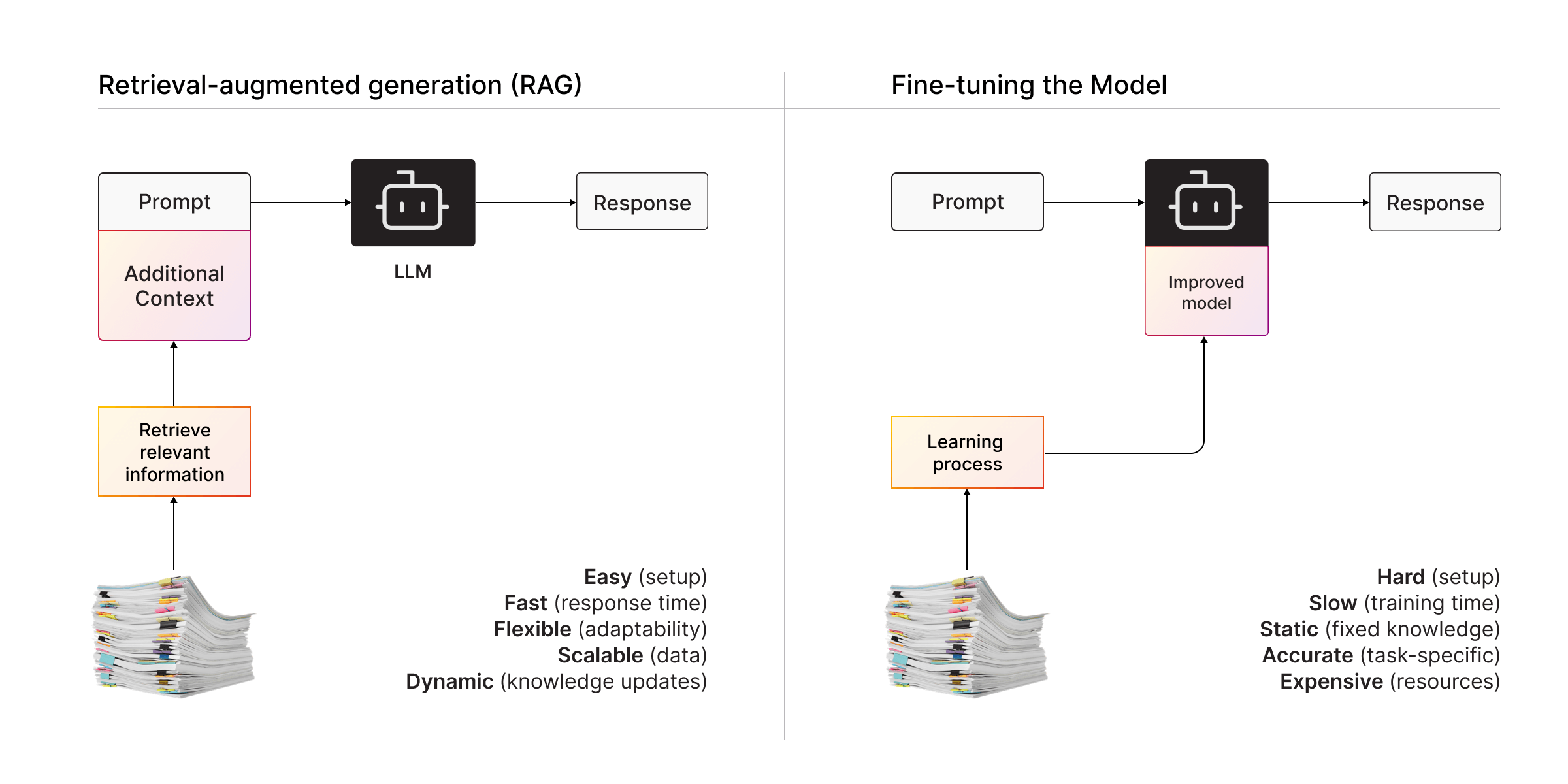
1. Retrieval-Augmented Generation (RAG)
With RAG, you don’t try to cram all your data into the LLM. Instead, you:
- Search through your records for the most relevant info.
- Add that info to your prompt to give the LLM extra context.
Think of RAG as a cheat sheet for the LLM—it doesn’t need to know everything, just what’s most important.
2. Fine-Tuning
On the other side, fine-tuning is like giving the LLM extra training. You feed it your data (e.g., all your medical records) so it learns your specific needs. This makes it better at answering your questions but comes with trade-offs:
- It requires serious technical skills and resources to fine-tune.
- It’s slow and expensive to train.
- It needs constant updates if your data changes.
TL;DR
LLMs are incredible at generating general text, but they’re not perfect, especially not in a proprietary data environment. They guess what to say based on patterns, but they lack real understanding. Tools like RAG and fine-tuning help bridge the gap by giving LLMs more context or additional training.
So next time ChatGPT stumbles over a tricky question, remember—it’s not magic; it’s just probabilities playing word games.
Want to dig deeper into how we can supercharge LLMs with tools like RAG? Stick around for our next post: LLM Limitations. Why Can’t You Query Your Enterprise Knowledge with Just an LLM?