
How to Build a Real-Time Book Recommendation System on Amazon Books Dataset?
Some of you probably know that feeling of being lost in the pages of a good book. The question is, how do you stumble upon those good books? It depends from person to person, but recommendations most likely come from friends, social media, bookstores, and maybe a few websites. Wouldn’t it be great if everyone could get popular book recommendations in seconds? Wait, sounds familiar? Amazon does this for you. It dynamically recommends new books to read when you buy, view, or rate books on the website. We at Memgraph decided to have some fun building graph-based recommendation engines and to get the wheels in motion, we created Awesome Data Stream, a data streams website, to make things dynamic and real-time. There, you can also find all the details about the Amazon books dataset used in this blog post.
Data coming from these streams can be run through Memgraph, which you can set up using the new Memgraph Cloud or by running a local instance of Memgraph DB. The latest version of Memgraph Lab, an application you can use to query and visualize data, has a new feature that guides you through the process of connecting to streams. All the information necessary to connect to a stream is available on the Awesome Data Stream website. If these tools spark your interest, feel free to browse through the Cloud documentation or check out the guide on how to connect to streams using Memgraph Lab. If you are one of those traitors who prefer movie adaptations over linguistical masterpieces, watch the video tutorial that goes through both of these processes.
This blog post will explore the Amazon streaming dataset to get some best-rated books that can be part of the must-read list and can be recommended to anyone who didn’t read them. There are also popular books that users read a lot but have mixed feelings about how to rate them. In order to find those, you will have a chance to use the PageRank algorithm.
Checking the setup
Assuming you are successfully running your Memgraph instance, you’ve connected to it with Memgraph Lab or mgconsole, and the database is ingesting the Amazon books data stream, run the following Cypher query to be sure everything is connected and running smoothly (in Memgraph Lab, switch to Query Execution):
MATCH (u:User)-[r:RATED]-(b:Book)
RETURN u, r, b LIMIT 100;
If everything is set up correctly, you should see 100 book ratings, and in Lab you can switch between graph results and data results returned by the query as seen in the image below. Let’s leave Cypher queries a bit and move on to writing a custom query module in Python.
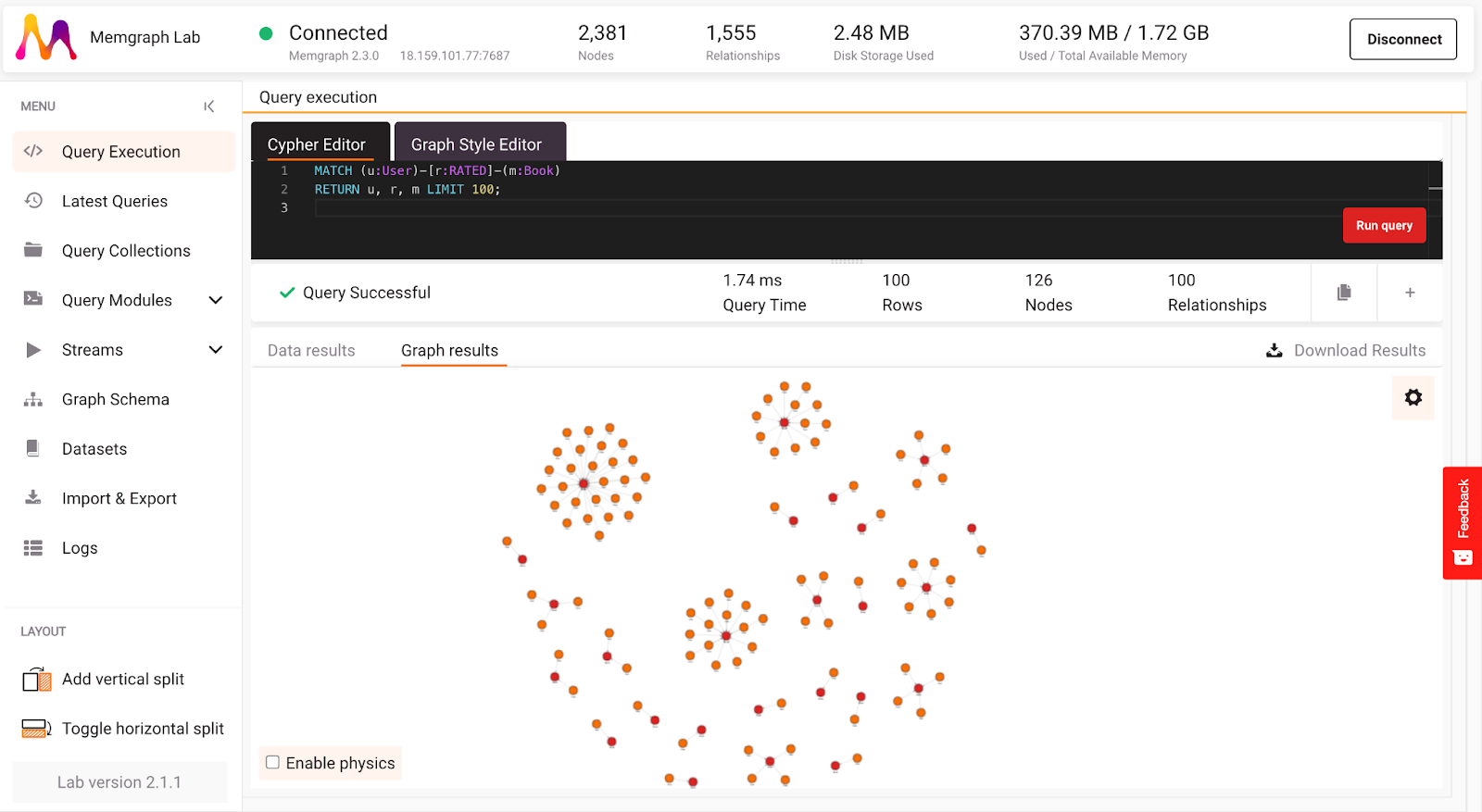
Fresh and Clean Dataset
Custom query modules enable you to write Python code to extend the Cypher query language and explore graphs even more efficiently. The new version of Memgraph Lab supports writing custom query modules directly in Lab. You can also write your query modules locally, so be sure to check Memgraph’s reference guide on query modules for any questions left unanswered by this blog.
In Memgraph Lab, select Query Modules in the left side menu, create + New module give it a name, such as amazonbooks_demo:
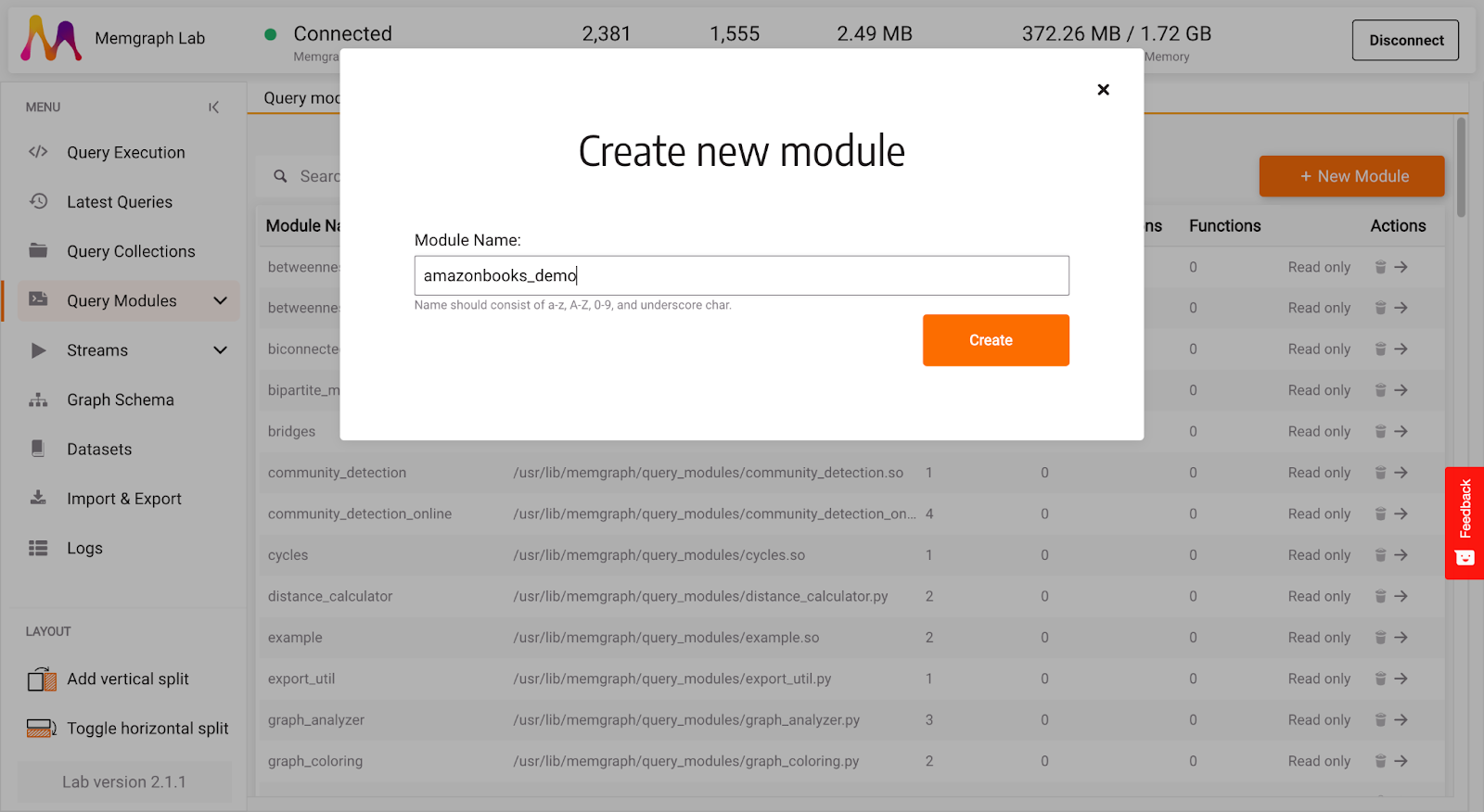
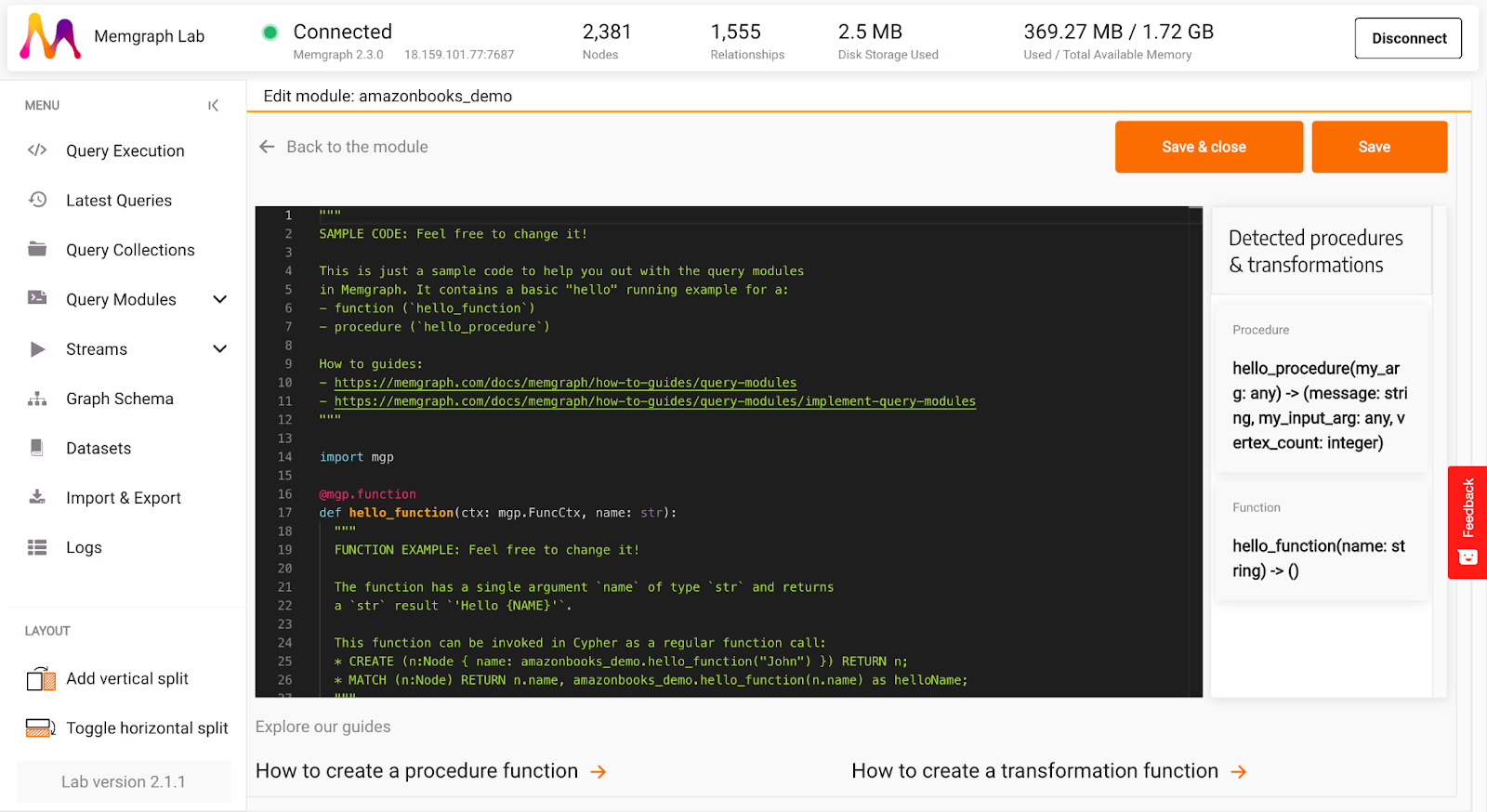
After creating a new query module, a query module editing section will open. You can notice that by default, there is some sample Python code written there. Most of the code is helpful comments and links to guides. Feel free to explore everything, but let’s start with a clean slate in this blog.
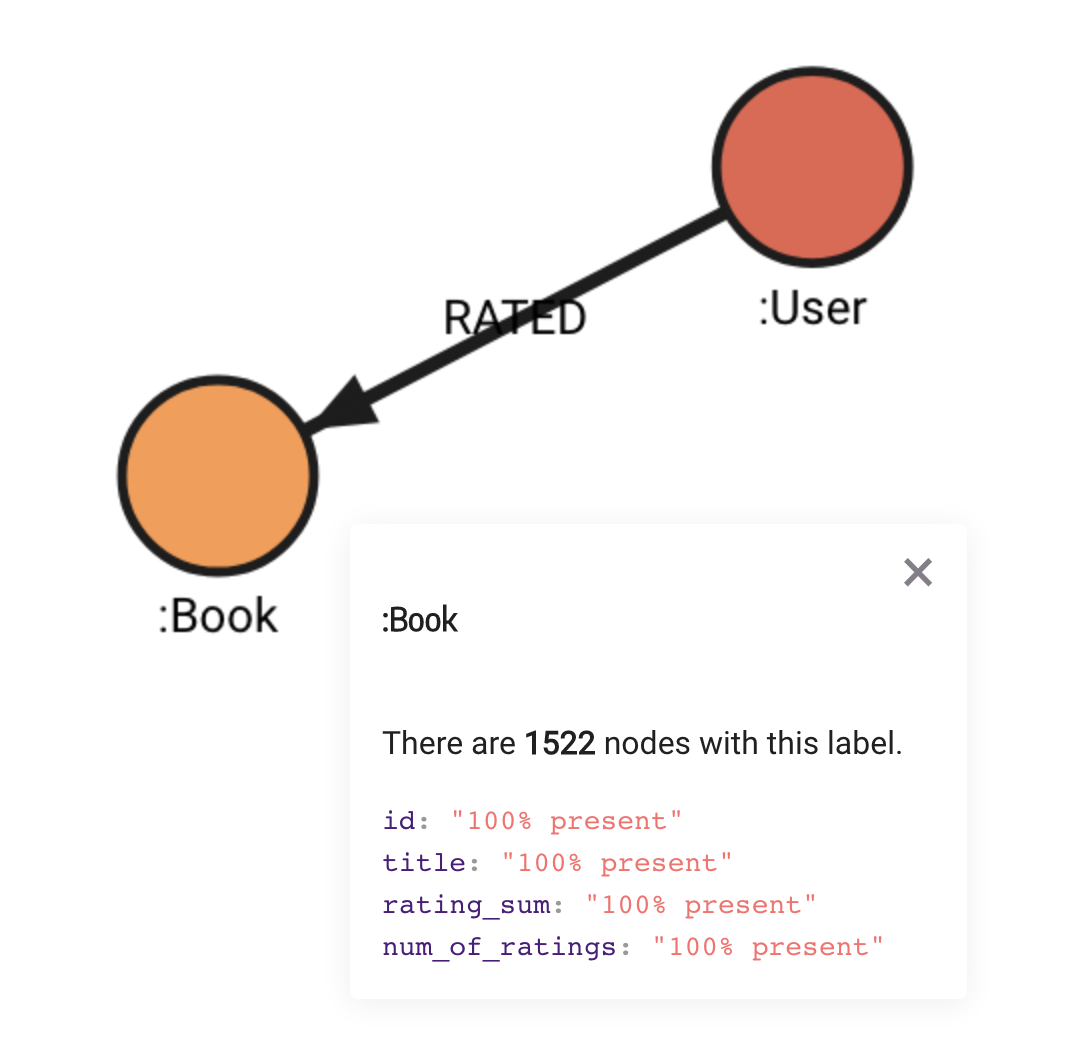
As you can see on Awesome Data Stream website, Amazon books graph data model is quite simple. There are only User and Book nodes, connected by a RATED relationship.
The obvious step in building a recommendation engine is finding the best-rated books that are a must-read for everyone. To do it, you have to get all book ratings and calculate the average rating score of every book in the dataset. After each book has a rating, the best books are easily extracted. It really depends on how many books you want to recommend.
As in building any recommendation engine, things always change dynamically, so updating the dataset in real-time is necessary.
This can be achieved by writing a custom query module in Python:
@mgp.write_proc
def new_rating(
context: mgp.ProcCtx,
rating: mgp.Edge
) -> mgp.Record(Rating = mgp.Nullable[mgp.Edge],
Book = mgp.Nullable[mgp.Vertex]):
if rating.type.name == "RATED":
book = rating.to_vertex
book_rating = rating.properties.get("rating")
rating_sum = book.properties.get("rating_sum")
if rating_sum == None:
book.properties.set("rating_sum", book_rating)
book.properties.set("num_of_ratings", 1)
else:
current_rating = rating_sum + book_rating
book.properties.set("rating_sum", current_rating)
book.properties.set("num_of_ratings", book.properties.get("num_of_ratings") + 1)
return mgp.Record(Rating=rating, Book=book)
return mgp.Record(Rating=None, Book=None)
This query module takes user input rating scores and updates Book nodes with properties num_of_ratings that define how many users have rated the book and rating_sum, the total sum of ratings. The total sum of ratings must be divided by the number of ratings to calculate the average book score.
To ensure this query is executed when a new rating comes from the data stream, a trigger needs to be set up. Below is the Cypher query that will set up the trigger:
CREATE TRIGGER newBookRating
ON CREATE BEFORE COMMIT EXECUTE
UNWIND createdEdges AS e
CALL amazonbooks_demo.new_rating(e) YIELD *;
Now, as soon as a new edge is created, the custom query procedure will be triggered and update the Book nodes with new properties previously set up by the running trigger.
Generally speaking, it is good practice to set up database triggers before data is loaded because triggers should be executed consistently on all data coming from the stream. This will ensure that data inside the database is consistent. To do so, just stop the stream, clean the database, prepare triggers, and start the stream again. But at the moment, we are having fun, so it isn’t necessary to do it.
Now that the dataset is updated in real-time, there are some cool insights you can uncover.
Recommending best-rated books
Building recommendations engines is quite a big topic involving different aspects of user interaction with books. Everyday interactions with books on the digital platform are that books can be bought, read, viewed, and rated by the user. Building recommendations can also include recommendations based on similar user ratings, but in this blog, the focus will be on the book's popularity and ratings in general. Personalized recommendations involve finding a target user to recommend different books. Let’s start by finding a target user in the list of readers that rated the most books. You can find those readers by running the query below:
MATCH (u:User)-[r:RATED]->(b:Book)
WITH u, count(b) AS num_of_books
RETURN u.id AS user_ID, num_of_books
ORDER BY num_of_books DESC
LIMIT 10;
The query will return 10 users that have the most book ratings. The number of book ratings is contained in the num_of_books variable.
| user_ID | num_of_books |
|---|---|
| "A1E1IC8458ZDUA" | 16 |
| "A68JKMYIVL72O" | 14 |
| "AF92FSKQLIRQ" | 12 |
| "A20Y0TCBU79GXU" | 10 |
| "A18Z12Y7HU3VL0" | 9 |
| "AKXENF3IORDF" | 9 |
| "A29EFQOCZL3R78" | 9 |
| "A2HX0B5ELOPP5Z" | 9 |
| "ABZCOPZLR8G87" | 9 |
| "A1EWZ12TU55G2X" | 8 |
Let’s focus on the user with ID:”A2HX0B5ELOPP5Z”. This user has 9 book ratings. If you execute the query below, you will see all the books user with ID:”A2HX0B5ELOPP5Z” rated:
MATCH (u:User {id:"A2HX0B5ELOPP5Z"})-[r:RATED]->(b:Book)
RETURN u.id, r.rating, b.title;
Notice the first book that the user rated with a rating of five, a book with title:”Fixed Forever (Volume 5)”
| u. id | r.rating | b.title |
|---|---|---|
| "A2HX0B5ELOPP5Z" | 5 | "Fixed Forever (Volume 5)" |
| "A2HX0B5ELOPP5Z" | 4 | "More Than Words: A Love Story" |
| "A2HX0B5ELOPP5Z" | 5 | "Lord of Secrets (Rogues to Riches) (Volume 5)" |
| "A2HX0B5ELOPP5Z" | 5 | "The Highlander/'s Promise: Highland Brides" |
| "A2HX0B5ELOPP5Z" | 4 | "Broken Promise: A Romantic Thriller (Sons of Broad)" |
| "A2HX0B5ELOPP5Z" | 5 | "The Darkest Warrior (Lords of the Underworld)" |
| "A2HX0B5ELOPP5Z" | 5 | "Moonlight Seduction: A de Vincent Novel (de Vincent series)" |
| "A2HX0B5ELOPP5Z" | 4 | "Sandpiper Shore (Harmony Harbor)" |
| "A2HX0B5ELOPP5Z" | 5 | "Detective Barelli/'s Legendary Triplets (The Wyoming Multiples)" |
In order to build personalized recommendations, the goal is to find the best-rated books and recommend only those that the user didn't rate so far. Because the dataset is dynamic, the results are temporary and depend on current ratings in the database, so if you try to replicate the results they may differ.
A Python query module that will get the best rated books looks like this:
@mgp.read_proc
def best_rated_books(
context: mgp.ProcCtx,
number_of_books: int,
ratings_treshold: int
) -> mgp.Record(best_rated_books = list):
q = PriorityQueue(maxsize=number_of_books)
for book in context.graph.vertices:
label, = book.labels
if label.name == "Book":
num_of_ratings = book.properties.get("num_of_ratings")
title = book.properties.get("title")
if num_of_ratings != None and num_of_ratings >= ratings_treshold:
rating = book.properties.get("rating_sum")/num_of_ratings
if q.empty() or not q.full():
q.put((rating, title))
else:
top = q.get()
if top[0] > rating:
q.put(top)
else:
q.put((rating, title))
books = list()
while not q.empty():
books.append(q.get())
books.reverse()
return mgp.Record(best_rated_books=books)
The query above will calculate the average book rating based on the variables that were mentioned previously in updating the dataset. To execute the procedure within the query module, run the following command:
CALL amazonbooks_demo.best_rated_books(10, 60)
YIELD best_rated_books
UNWIND best_rated_books AS Book
WITH Book[0] AS Rating, Book[1] as Title
RETURN Rating, Title;
You will get the 10 best movies with more than 60 ratings, these parameters can be changed. Here is the list of best-rated books:
| Rating | Title |
|---|---|
| 4.98969 | "When the Man Comes Around: A Gripping Crime Thriller (Lawson Raines) (Volume 1)" |
| 4.89823 | "Iron and Magic: (The Iron Covenant Book 1) (Volume 1)" |
| 4.89247 | "A Merciful Silence (Mercy Kilpatrick)" |
| 4.85238 | **"Fixed Forever (Volume 5)" ** |
| 4.8439 | "Beneath a Scarlet Sky (Center Point Large Print)" |
| 4.79348 | "Play Dirty (Jordan/'s Game) (Volume 4)" |
| 4.67347 | "Black Rules (Black Edge)" |
| 4.66667 | "Heaven Adjacent" |
| 4.65468 | "Shelter in Place" |
| 4.64773 | "A Steep Price (Tracy Crosswhite)" |
Notice that the list of best-rated books also includes the book with title:”Fixed Forever (Volume 5)”.
Obviously, if the user has rated this book, there is no need to recommend it. Let’s upgrade the procedure within the query module to recommend only the books the user didn't rate by adding a node that represents the target User for which recommendations are generated:
@mgp.read_proc
def recommend_books_for_user(
context: mgp.ProcCtx,
user : mgp.Vertex,
number_of_books: int,
ratings_treshold: int
) -> mgp.Record(recommended_books = list):
rated_books = []
for user_ratings in user.out_edges:
user_book = user_ratings.to_vertex
rated_books.append(user_book.id)
q = PriorityQueue(maxsize=number_of_books)
for book in context.graph.vertices:
label, = book.labels
if label.name == "Book" and book.id not in rated_books:
num_of_ratings = book.properties.get("num_of_ratings")
title = book.properties.get("title")
if num_of_ratings != None and num_of_ratings >= ratings_treshold:
rating = book.properties.get("rating_sum")/num_of_ratings
if q.empty() or not q.full():
q.put((rating, title))
else:
top = q.get()
if top[0] > rating:
q.put(top)
else:
q.put((rating, title))
books = list()
while not q.empty():
books.append(q.get())
books.reverse()
return mgp.Record(recommended_books=books)
You can execute the above procedure using the following query:
MATCH (u:User{id:"A2HX0B5ELOPP5Z"})
CALL amazonbooks_demo.recommend_books_for_user(u, 10, 60)
YIELD recommended_books
UNWIND recommended_books AS Book
WITH Book[0] AS Rating, Book[1] as Title
RETURN Rating, Title;
In the query, you first need to match the target user (in this case, the user with the ID:”A2HX0B5ELOPP5Z”) and pass it to the query module. When using the upgraded procedure, the book with the title:”Fixed Forever (Volume 5)” is no longer recommended because the user has already rated it.
| Rating | Title |
|---|---|
| 4.98969 | "When the Man Comes Around: A Gripping Crime Thriller (Lawson Raines) (Volume 1)" |
| 4.89823 | "Iron and Magic: (The Iron Covenant Book 1) (Volume 1)" |
| 4.89247 | "A Merciful Silence (Mercy Kilpatrick)" |
| 4.8439 | "Beneath a Scarlet Sky (Center Point Large Print)" |
| 4.79348 | "Play Dirty (Jordan/'s Game) (Volume 4)" |
| 4.67347 | "Black Rules (Black Edge)" |
| 4.66667 | "Heaven Adjacent" |
| 4.65468 | "Shelter in Place" |
| 4.64773 | "A Steep Price (Tracy Crosswhite)" |
| 4.6044 | "The Fragile Ordinary" |
Rating is not the only factor that can be used for the recommendation of books reading list. Let’s see what books are popular and recommend a few of those.
Recommending the most popular books
Finding the best-rated books requires some coding, but you’ll be happy to hear that finding the most popular book will require almost no coding, and you will still get appropriate recommendations for the user. Time to harness the power of MAGE, an open-source repository of graph algorithms. If you are using Memgraph Cloud or Memgraph Platform, MAGE is already locked and loaded, and in it, you will find the famous PageRank algorithm that Google was built on. In short, the algorithm returns the most important nodes in a dataset. In the case of books, that means those with the most ratings, but not necessarily the best ones. Let’s see what are the most popular books by executing the query below:
CALL pagerank.get()
YIELD *
WITH node, rank
WHERE node:Book
RETURN node.title, rank
ORDER BY rank DESC
LIMIT 10;
Here are the most popular books in the dataset according to the PageRank algorithm. Notice there is a book with title:”Fixed Forever (Volume 5)” :
| node.title | rank |
|---|---|
| "Iron and Magic: (The Iron Covenant Book 1) (Volume 1)" | 0.00550566 |
| "Beneath a Scarlet Sky (Center Point Large Print)" | 0.00504825 |
| "The Thinnest Air" | 0.0048216 |
| "Fixed Forever (Volume 5)" | 0.00455591 |
| "Shelter in Place" | 0.00339992 |
| "When the Man Comes Around: A Gripping Crime Thriller (Lawson Raines) (Volume 1)" | 0.00239032 |
| "A Merciful Silence (Mercy Kilpatrick)" | 0.00228524 |
| "Lies That Bind Us" | 0.00215955 |
| "Black Rules (Black Edge)" | 0.00199761 |
| "A Steep Price (Tracy Crosswhite)" | 0.00198627 |
The algorithm does return the most popular books but doesn’t exclude the books the user read. Rewrite the query a bit in order to filter out the books the user already rated from the results of the PageRank algorithm:
MATCH (:User{id:"A2HX0B5ELOPP5Z"})-[:RATED]->(b:Book)
WITH collect(b.id) AS book_set
CALL pagerank.get()
YIELD *
WITH node, rank
WHERE node:Book AND NOT node.id IN book_set
RETURN node.title, rank
ORDER BY rank DESC
LIMIT 10;
| node.title | rank |
|---|---|
| "Iron and Magic: (The Iron Covenant Book 1) (Volume 1)" | 0.00550566 |
| "Beneath a Scarlet Sky (Center Point Large Print)" | 0.00504825 |
| "The Thinnest Air" | 0.0048216 |
| "Shelter in Place" | 0.00339992 |
| "When the Man Comes Around: A Gripping Crime Thriller (Lawson Raines) (Volume 1)" | 0.00239032 |
| "A Merciful Silence (Mercy Kilpatrick)" | 0.00228524 |
| "Lies That Bind Us" | 0.00215955 |
| "Black Rules (Black Edge)" | 0.00199761 |
| "A Steep Price (Tracy Crosswhite)" | 0.00198627 |
| "Play Dirty (Jordan/'s Game) (Volume 4)" | 0.00192202 |
As you can see, results now show only the books the user didn’t rate. There is still room for improvement! Because data is being ingested in real-time and the dataset is changing, every time the PageRank is executed, it needs to be executed on a whole graph. This is fine when the graph is small, but it could become a bottleneck as it grows larger. Meet the dynamic PageRank algorithm. Dynamic PageRank is optimized for streaming data applications because it recomputes the changes on parts of the graph that are affected by incoming streaming data, which means that calling PageRank will be faster if the dataset grows larger. In order to set up a dynamic PageRank, run the following query:
CALL pagerank_online.set(100, 0.2)
YIELD node, rank
LIMIT 10;
The query will precompute the page rank on the data currently in the database and store rank property on each node. Arguments passed to set function define the number of walks per node and walk stop probability.
In order to recompute the rank values related to the page rank on each dataset change, setup the trigger:
CREATE TRIGGER pagerank_trigger
BEFORE COMMIT
EXECUTE CALL pagerank_online.update(createdVertices, createdEdges, deletedVertices, deletedEdges)
YIELD node, rank
SET node.rank = rank;
Trigger will ensure that rank value on nodes is up to date. After that, you can run the following query to get results of a dynamic PageRank, which represents the most popular books in the dataset:
MATCH (b:Book)
WHERE b.rank IS NOT NULL
RETURN b.title, b.rank
ORDER BY b.rank DESC
LIMIT 10;
| b.title | b.rank |
|---|---|
| "Iron and Magic: (The Iron Covenant Book 1) (Volume 1)" | 0.00586429 |
| "Beneath a Scarlet Sky (Center Point Large Print)" | 0.00560447 |
| "The Thinnest Air" | 0.00536306 |
| "Fixed Forever (Volume 5)" | 0.00506722 |
| "Shelter in Place" | 0.00377416 |
| "When the Man Comes Around: A Gripping Crime Thriller (Lawson Raines) (Volume 1)" | 0.00265569 |
| "A Merciful Silence (Mercy Kilpatrick)" | 0.00242583 |
| "Lies That Bind Us" | 0.00239971 |
| "Black Rules (Black Edge)" | 0.0022221 |
| "A Steep Price (Tracy Crosswhite)" | 0.00217343 |
As you can see, there is no need to call the PageRank algorithm explicitly this time. Matching all the books and sorting them by rank is enough.
But if you look closer, you’ll see that the recommendation includes all the popular books the user has already read. To fix this, run this query to filter out the books the user has already rated:
MATCH (:User{id:"A2HX0B5ELOPP5Z"})-[:RATED]->(b:Book)
WITH collect(b.id) AS book_set
MATCH (book:Book)
WHERE NOT book.id IN book_set AND book.rank IS NOT NULL
RETURN book.title, book.rank
ORDER BY book.rank DESC
LIMIT 10;
| book.title | book.rank |
|---|---|
| "Iron and Magic: (The Iron Covenant Book 1) (Volume 1)" | 0.00586429 |
| "Beneath a Scarlet Sky (Center Point Large Print)" | 0.00560447 |
| "The Thinnest Air" | 0.00536306 |
| "Shelter in Place" | 0.00377416 |
| "When the Man Comes Around: A Gripping Crime Thriller (Lawson Raines) (Volume 1)" | 0.00265569 |
| "A Merciful Silence (Mercy Kilpatrick)" | 0.00242583 |
| "Lies That Bind Us" | 0.00239971 |
| "Black Rules (Black Edge)" | 0.0022221 |
| "A Steep Price (Tracy Crosswhite)" | 0.00217343 |
| "Play Dirty (Jordan/'s Game) (Volume 4)" | 0.00214594 |
Conclusion
Building recommendation engines can be such an exciting and complex topic. This blog opted for an easy and intuitive approach, finding the best-rated and most popular books and recommending them to people who didn't read them to showcase how to write query modules using Python API. This part included a bit of coding. You also got a chance to set up a trigger for dynamic dataset update and use MAGE query modules, which let you harness the power of graph algorithms in seconds.
However, if books are not your cup of tea, feel free to explore another dataset available on the Awesome Data Stream website. For example, you can check out another tutorial on how to get real-time movie recommendations based on the MovieLens dataset.
If you have any issues or want to discuss something related to this article, drop us a message on our Discord server. Happy reading!