
Using Memgraph for Knowledge-Driven AutoML in Alzheimer’s Research at Cedars-Sinai
Alzheimer’s research depends on connecting patient data, genomics, clinical studies, and drug information without losing the relationships between them. In a recent community call, Jason H. Moore, Chair of the Department of Computational Biomedicine at Cedars-Sinai Medical Center, explained how his team uses Memgraph to build a knowledge graph that supports explainable AutoML and graph-powered biomedical discovery.
This post summarizes the main takeaways from that session, including how Moore’s team structures biomedical data, where KRAGEN and ESCARGOT fit, and why connected graph context improves predictive modeling and drug discovery in Alzheimer’s disease.
Watch the full webinar recording here: Cedars-Sinai: Using Graph Databases for Knowledge-Aware Automated Machine Learning.
Here’s a quick rundown of the key insights from the session.
AutoML for Alzheimer’s Research
Jason H. Moore highlighted how AutoML (Automated Machine Learning) is central to his team’s work on disease-risk prediction and drug discovery. AutoML automates key parts of the machine learning pipeline, including model selection and hyperparameter tuning, but it still depends on high-quality, structured data.
Memgraph provides the graph layer for a knowledge base that connects complex biomedical data sources, including patient health records, genetic data, and clinical trial results. Those connected data points give the team a stronger foundation for training AutoML models, improving disease-progression predictions and helping identify potential drug therapies.
Alzheimer’s research is data-heavy and relies on large datasets to extract meaningful insights. Memgraph’s ability to work with connected data at this scale makes it a practical fit for the AutoML pipeline.
Structuring Biomedical Data with KRAGEN and ESCARGOT
Biomedical data is often siloed and difficult to integrate across sources. Memgraph supports the team’s knowledge graph-enhanced RAG (Retrieval-Augmented Generation) workflow for biomedical problem-solving with LLMs, alongside tools like KRAGEN and ESCARGOT.
KRAGEN (Knowledge-Rich AI for Genomics and Environmental Networks) and ESCARGOT are pivotal to how Jason H. Moore’s team structures data within Memgraph. With KRAGEN, the team integrates diverse data sources like genomic data, clinical trial results, and electronic health records (EHRs) into a cohesive knowledge graph, allowing retrieval and exploration of relationships among biological entities—genes, proteins, symptoms, and more. This approach, powered by Memgraph, supports the Graph of Thoughts (GoT), a technique that layers contextual knowledge for LLM-driven biomedical insights, enabling researchers to ask complex queries that would be prohibitively time-consuming in traditional relational databases.
With Memgraph, KRAGEN, and ESCARGOT working together, Moore’s team can visualize and explore relationships in the data quickly. That helps researchers test new hypotheses around disease progression and intervention strategies without stitching together disconnected datasets by hand.
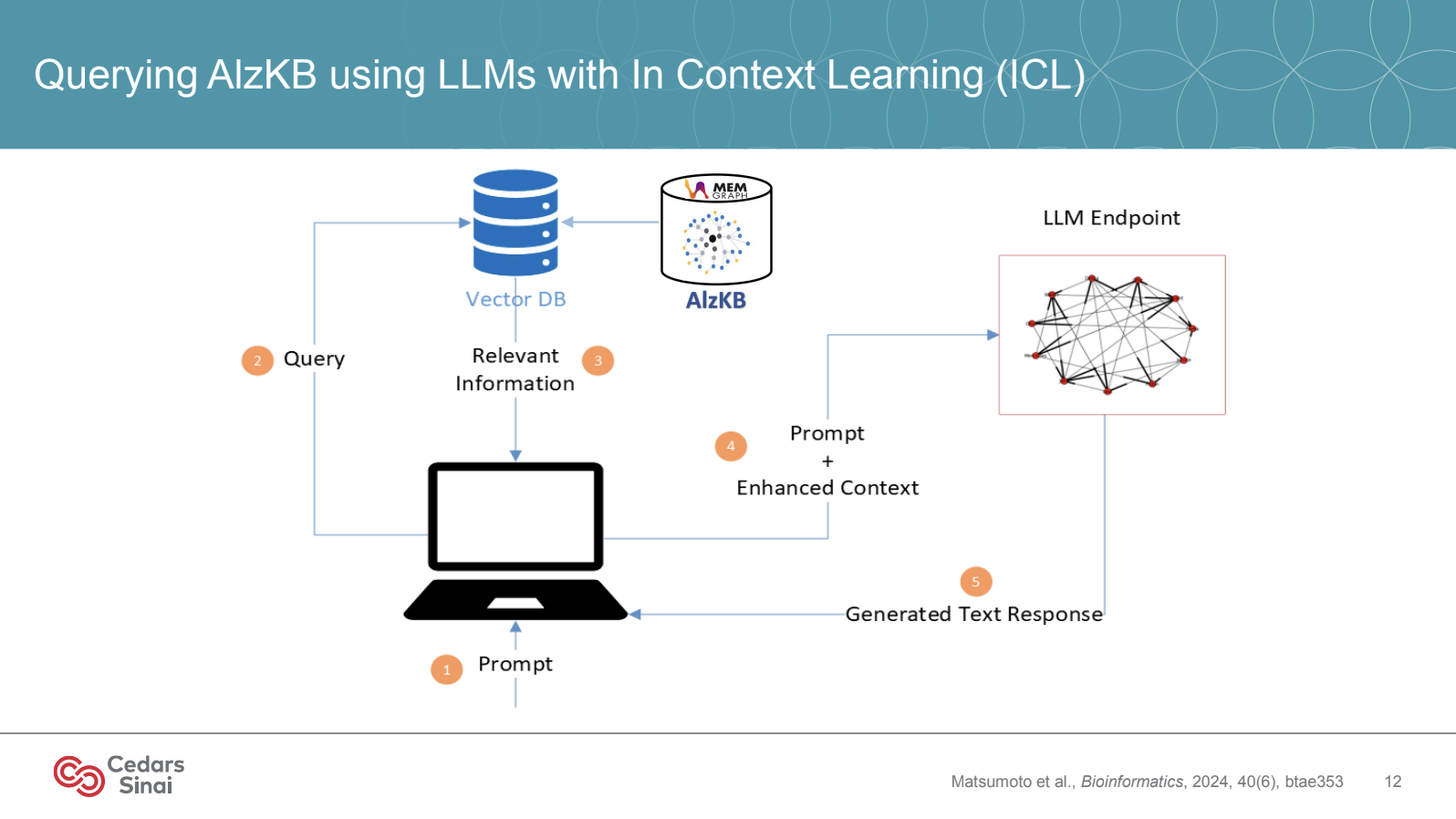
How Knowledge Graphs Improve AutoML
One of the key advantages of using a graph database like Memgraph is that it gives the AutoML pipeline contextualized data. The knowledge graph built with Memgraph includes interconnected data that adds context to individual data points, improving the quality and interpretability of machine learning models.
For example, when predicting disease risk, the system can incorporate not just patient demographics and genetic factors but also historical medical conditions, drug interactions, and lifestyle factors—all linked through the graph. This extra layer of contextual information allows the AutoML system to deliver more precise and explainable predictions, which is essential in biomedical research, where understanding why a model makes a specific prediction is critical.
Knowledge graphs also enhance the adaptability of AutoML models, allowing researchers to refine models as new data is continuously integrated.
TPOT and Memgraph in the AutoML Pipeline
TPOT, a Python-based tool for AutoML, is used with Memgraph to streamline the machine learning process further. TPOT automates model selection and hyperparameter tuning, which can be time-consuming when done manually.
Memgraph complements TPOT by ensuring the data feeding into the AutoML process is well-structured and connected. This reduces the time spent on data wrangling and preprocessing, enabling researchers to focus on model optimization and evaluation.
This integration allows for faster experimentation and quicker drug discovery insights in Alzheimer’s research, accelerating the identification of promising therapeutic candidates.
Scaling the Research Graph
Scalability is a major requirement in Alzheimer’s research, where datasets grow continuously as new patients are enrolled, new biomarkers are discovered, and new therapies are tested. Memgraph offers the scalability needed to support this ongoing research.
The knowledge graph is constantly updated with the latest findings from clinical trials, genomic research, and patient outcomes, ensuring that models use the most up-to-date data. Memgraph’s ability to handle large, complex datasets makes it a strong foundation for scaling both the knowledge base and the machine learning models built on top of it.
As the research expands, Memgraph helps the team add new data sources and continue optimizing AutoML models without disrupting risk-prediction and drug-discovery workflows.
Wrapping Up
Use Memgraph for workflows like this when your ML or GraphRAG system depends on connected biomedical context rather than isolated tables or vector search alone. A graph database is especially useful when researchers need to trace relationships across genes, drugs, symptoms, trials, and patient records while keeping those links queryable and explainable.
If you want to build a similar graph-backed workflow, start with the Memgraph getting started guide and then watch the full webinar for the Cedars-Sinai-specific implementation details.
Watch the full webinar recording here: Cedars-Sinai: Using Graph Databases for Knowledge-Aware Automated Machine Learning.
Q&A
We’ve compiled the questions and answers from the community call Q&A session.
Note that we’ve paraphrased them slightly for brevity. For complete details, watch the entire video.
-
In ESCARGOT, you moved away from using a vector database alone to using both a vector and a graph database. Why did you choose a graph database initially, and what added benefits does it bring when combined with vector embeddings? Specifically, how does the graph structure enhance what you can achieve over a basic RAG setup that relies solely on vector databases?
- Jason: Memgraph's graph database is crucial for this problem because the ontology and graph structure represent the higher-order relationships among all the entities we’re analyzing. This knowledge is critical—and it’s something ChatGPT can’t provide because this specific information isn’t publicly available in a searchable way that a model like ChatGPT would have been trained on. The graph structure allows for a higher-level synthesis of these relationships.
-
Does the ESCARGOT tool support natural language questions that are automatically translated into queries for the knowledge graph?
- Jason: Exactly. Moore said the workflow was being added to the AlzKB website, where users would be able to enter natural language questions through the ChatGPT interface while KRAGEN and ESCARGOT processed those queries against Memgraph’s knowledge graph and returned answers in natural language.
-
How critical is performance for your use case? Do real-time aspects play a significant role for you?
- Jason: Performance has been very good—answers return within seconds. So far, performance hasn’t been an issue. Having Memgraph as an in-memory graph database certainly speeds up the Cypher queries ESCARGOT performs on the fly. Our knowledge graph is relatively small, especially compared to some larger knowledge graphs others may have developed.
-
Does this graph expand over time, or is it mostly static?
- Jason: It will grow over time as we add more entities. While we don’t anticipate adding a large number of new entities, the ones we plan to add will introduce more edges and increase the graph’s size. Even with these additions, the graph will remain well within the memory limits of most computers or laptops used in this application.
-
Can this process be applied to other types of diseases beyond Alzheimer's?
- Jason: Absolutely. Moore said the team was preparing an addiction knowledge graph and building one for ALS, another neurodegenerative disease, with several others in the pipeline as well. Because the system is open source, the same approach can be adapted for other diseases by replacing the Alzheimer’s-specific knowledge graph data.
-
How critical is having the right ontology for the accuracy of Retrieval-Augmented Generation (RAG)?
-
Jason: That’s a great question. We haven’t specifically tested how critical ontology is to accuracy in answering questions based on the knowledge graph. The questions we see in the table here on the slide are all derived from the graph, so the way the graph is constructed inherently shapes these questions. ESCARGOT or RAG's ability to answer then depends on the methods used.
However, a broader question to ask is: how accurate are the answers we get for Alzheimer’s disease, and how relevant is the knowledge captured by our queries in the context of Alzheimer’s research? For example, does it inform experimental or clinical studies? For this type of question, ontology is indeed very important. It defines the relationships between entities, and the accuracy of these definitions will directly impact the relevance of results to Alzheimer’s disease specifically.
-
-
How rich is the schema of the graph? Are you using multiple properties on both nodes and edges?
- Jason: Right now, our graph is relatively simple. Moore said the team had started a project to add more properties to both nodes and edges, including inferred probabilities for relationships. The goal is to “color” the graph with more information and make it richer and more informative.
-
How do you quantify and address uncertainty and inconsistency in knowledge graphs, especially when integrating information from various databases?
- Jason: That’s a great question, and yes, there is inherent uncertainty in each knowledge source we use. The quality of our knowledge graph is only as strong as the sources we’re pulling from and the ontology we’ve constructed, so that uncertainty is always a factor. Personally, I’m not an expert in quantifying that uncertainty, but I agree it’s something we should be addressing. It would be incredibly valuable to communicate to users the degree of uncertainty associated with any relationship in the graph or within the graph as a whole. However, achieving this isn’t straightforward, primarily because we didn’t create the foundational knowledge sources ourselves. We have to rely on their validity, trusting that they’re reliable and well-vetted. Most of our sources have been around for years, are peer-reviewed, published, and widely used in research. While uncertainty exists, we can still place reasonable trust in these knowledge sources because respected research groups continually maintain and update them.
-
How do you dynamically update a knowledge graph database and ensure it remains complete?
- Jason: We update our AlzKB knowledge graph at least every few months to align with changes in the underlying knowledge sources. Each time we refresh the graph, we assign a new version number. Our team is dedicated to keeping the graph current, typically with updates on a monthly or bi-monthly basis. Maintaining a continuously updated graph isn’t easy, especially with more frequent updates. However, Memgraph supports dynamic graph updates using triggers and allows data flow in from multiple streams. Memgraph also has online dynamic graph algorithms, which enable the recalculation of values as new data arrives. This setup facilitates a continuously evolving knowledge base, and I believe we’ll see more use cases using dynamic knowledge graphs in the future.
Further Reading
- Blog post: How Precina Health Uses Memgraph and GraphRAG to Revolutionize Type 2 Diabetes Care with Real-Time Insights
- Webinar recording: Optimizing Insulin Management: The Role of GraphRAG in Patient Care
- Blog post: Building GenAI Applications with Memgraph: Easy Integration with GPT and Llama
- Blog post: How Microchip Uses Memgraph’s Knowledge Graphs to Optimize LLM Chatbots
- Webinar recording: Microchip Optimizes LLM Chatbot with RAG and a Knowledge Graph
- User story: Enhancing LLM Chatbot Efficiency with GraphRAG (GenAI/LLMs)
- GitHub Repo: TPOT
- GitHub Repo: KRAGEN
- GitHub Repo: ESCARGOT
- KnowledgeBase: The Alzheimer's KnowledgeBase