How to Build a Spotify Recommendation Engine Using Kafka and Memgraph
We recently held a company-wide hackathon where we challenged each other to build compelling, useful applications using a streaming data source, Kafka, Memgraph, and a Web Application backend. This week we're looking at building a Spotify song recommendation engine on top of Memgraph.
We have a lot of music lovers in our company, and when one of our teammates came across an open dataset of Spotify playlists, we knew it would let us scratch our itch to try out building a recommendation engine on top of Memgraph. It was a lot of fun -- we're excited to show it off.
The Data Source
Our application works with the Spotify dataset which contains songs, playlists and users. If you want to try out the app yourself, all you have to do is visit the GitHub page and follow the installation instructions, and if you want to learn more about it, join our Discord Community Chat!
The Data Model
The Spotify playlist dataset contains 5 million song playlists from different users. Each playlist contains a list of music tracks. The data model sample is given below:
{
"name": "musical",
"collaborative": "false",
"pid": 5,
"modified_at": 1493424000,
"num_albums": 7,
"num_tracks": 12,
"num_followers": 1,
"num_edits": 2,
"duration_ms": 2657366,
"num_artists": 6,
"tracks": [
{
"pos": 0,
"artist_name": "Degiheugi",
"track_uri": "spotify:track:7vqa3sDmtEaVJ2gcvxtRID",
"artist_uri": "spotify:artist:3V2paBXEoZIAhfZRJmo2jL",
"track_name": "Finalement",
"album_uri": "spotify:album:2KrRMJ9z7Xjoz1Az4O6UML",
"duration_ms": 166264,
"album_name": "Dancing Chords and Fireflies"
},
// 10 tracks omitted
{
"pos": 11,
"artist_name": "Mo' Horizons",
"track_uri": "spotify:track:7iwx00eBzeSSSy6xfESyWN",
"artist_uri": "spotify:artist:3tuX54dqgS8LsGUvNzgrpP",
"track_name": "Fever 99/u00b0",
"album_uri": "spotify:album:2Fg1t2tyOSGWkVYHlFfXVf",
"duration_ms": 364320,
"album_name": "Come Touch The Sun"
}
],
}The Application Architecture
This is what the app looks like:
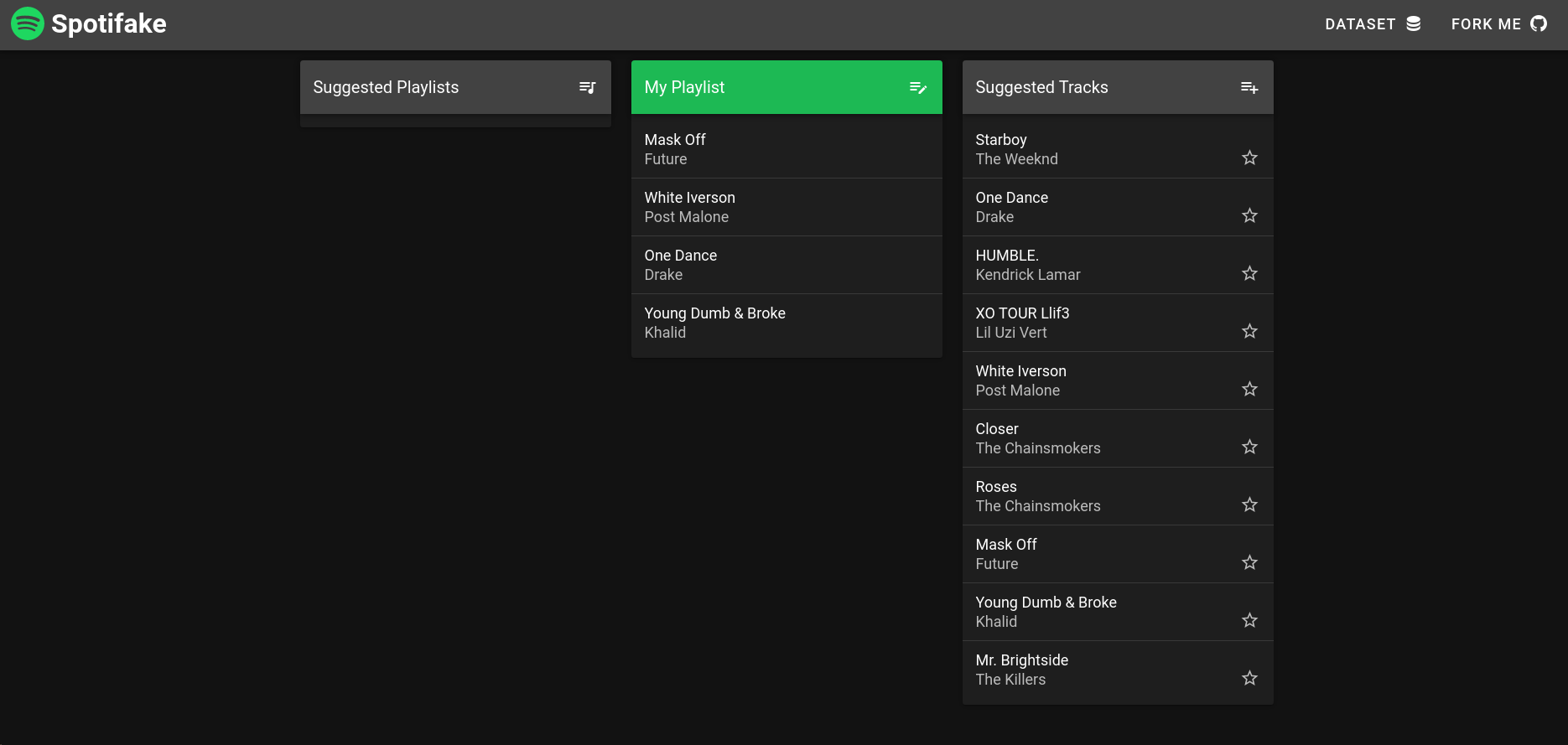
The application interface offers the user a means of creating a website. The middle column is the place where users can add songs to their playlists. The suggested songs are listed in the right column. The left column shows suggested playlists. Users can inspect songs from suggested playlists and add them directly to their playlist. As the user playlist contains different songs, the suggestions change automatically.
To understand how songs are recommended, let's dive in.
The initial data is in the form of JSON files. Each JSON file contains a list of
Spotify playlists. With the script
producer.py
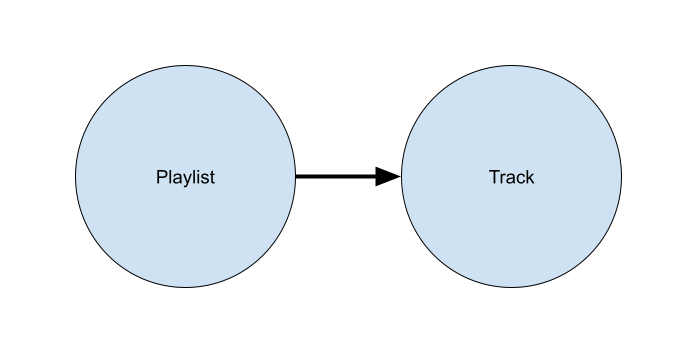
they are sent into Kafka under a topic named spotify. Memgraph reads the
playlists from Kafka and stores them in a graph data model with two types: Track
and Playlist. Playlists are connected to Tracks via HAS edges.
Over on the user side, we have a Vue.js application for creating playlists and suggesting music tracks similar to users' tastes. The website calls the Flask backend, which queries Memgraph using custom MAGE algorithms. Upon receiving a new playlist, Memgraph can detect rising hits and send them to Kafka directly. The backend then keeps a table of trendy songs and suggests them to all users in a separate "Trendy" section.
The Recommendation Algorithms
Before any songs are added to the user's playlist, tracks contained in the most playlists are suggested. Once a user adds a song to his playlist, Memgraph traverses the graph starting from all the songs contained in the user's playlist and does a breadth first search to all other songs that can be reached, and grades them based on distance, number of playlists that the track is contained in, influence, and order.
Similarly, similar playlists are calculated based on the number of songs contained in them and the user's playlist, combined with the similarity of other songs in the playlist to the user's playlist. This has one big flaw, the more songs a playlist has, the more likely it is that it gets recommended.
Using MAGE To Develop Recommendation Algorithms
We used the open-source MAGE project to develop custom query modules that perform recommendations. This way, we can just call the procedures from Cypher queries. The following procedures have been implemented:
-
similar_tracks.get(playlist_id: int) -> mgp.Record(track_ids=list[int]) """Returns a list of track_ids that are similar to the tracks in the given playlist. Calculates similar tracks by calculating the proximity of each track to the given playlist. :param int playlist_id: User playlist. :return: List of track ids. :rtype: mgp.Record(track_ids=list[int]) """ -
similar_playlists.get(playlist_id: int) -> mgp.Record(playlist_ids=list[int]) """Returns a list of playlist_ids that are similar to the given playlist. Calculates similar playlists by calculating the proximity of each to the given one. :param int playlist_id: User playlist. :return: List of playlist ids that are currently trendy. :rtype: mgp.Record(playlist_ids=list[int]) """ -
trendy_tracks.get() → mgp.Record(tracks=list[dict[str][Any]]) """Returns a list of track_ids of trendy songs. Calculates recently popular tracks by comparing the popularity of songs using the `followers`, `created_at`, and proximity to other popular songs (pagerank). :return: List of track ids that are currently trendy. :rtype: mgp.Record(track_ids=list[dict[str][Any]]) """
The Backend Server
The backend is a Python Flask application that offers the following REST endpoints:
-
GET
/serves the homepage -
POST
/create-playlist- payload
{ "playlist_name": str } - returns
{ "status": int, "message": str, "playlist_id": int, }
- payload
-
PUT
/rename-playlist- payload
{ "playlist_id": int, "playlist_name": str } - return
{ "status": int, "message": str, "playlist_name": str }
- payload
-
POST
/add-track- payload
{ "playlist_id": int, "track_uri": int } - returns
{ "status": int, "message": str, "track": { "artist_name": str, "track_uri": str, "artist_uri": str, "track_name": str, "album_uri": str, "duration_ms": int, "album_name": str, } }
- payload
-
POST
/track-recommendation- payload
{ "playlist_id": int, "tracks": [ { "track_id": int, "artist_name": str, "track_uri": str, "artist_uri": str, "track_name": str, "album_uri": str, "duration_ms": int, "album_name": str, }... ] } - returns
{ "status": int, "message": str, "tracks": [ { "track_id": int, "artist_name": str, "track_uri": str, "artist_uri": str, "track_name": str, "album_uri": str, "duration_ms": int, "album_name": str, }... ] }
- payload
- POST
/playlist-recommendation- payload
{ "playlist_id": int, "track_ids": [ int, int, ... ] } - returns
{ "status": int, "message": str, "playlists": [ { "playlist_id": int, "playlist_name": str, "tracks": [ { "track_id": int, "artist_name": str, "track_uri": str, "artist_uri": str, "track_name": str, "album_uri": str, "duration_ms": int, "album_name": str, }... ] }, { "playlist_id": int, "playlist_name": str, ... } ] }
- payload
-
GET
/trending-tracks- returns
{ "status": int, "message": str, "tracks": [ { "track_id": int, "artist_name": str, "track_uri": str, "artist_uri": str, "track_name": str, "album_uri": str, "duration_ms": int, "album_name": str, }... ] }
- returns
-
GET
/top-tracks/<number_of_tracks:10>- returns
{ "status": int, "message": str, "tracks": [ { "track_id": int, "artist_name": str, "track_uri": str, "artist_uri": str, "track_name": str, "album_uri": str, "duration_ms": int, "album_name": str, }... ] }
- returns
-
GET
/top-playlists/<number_of_tracks:10>- returns
{ "status": int, "message": str, "playlists": [ { "playlist_id": int, "playlist_name": str, "tracks": [ { "track_id": int, "artist_name": str, "track_uri": str, "artist_uri": str, "track_name": str, "album_uri": str, "duration_ms": int, "album_name": str, }... ] }... ] }
- returns
Conclusion
We learned a lot and had a lot of fun implementing song recommendation algorithms on top of Memgraph. We think we have some room for improvement when it comes to developer ergonomics and setup, which is something we've been working on a lot lately. If you give this a shot, we'd love to know what you think!
If this project sounds cool to you, check out the GitHub repo, and let us know what you think in our Discord Community Chat! You can also download Memgraph and start exploring your own networks or analyze your streaming data.