3 Powerful Queries to Find Patterns in Your Knowledge Graph You Haven’t Noticed Before
Today, there are not a lot of companies worry about the lack of data. Everything is logged and stored in different databases and technologies. The current issue is that companies can’t conclude anything from all that data, which is especially disastrous if the data indicates that it’s time for the company to change how it does business.
Creating a large web of interconnected data as a graph is the crucial first step for companies to get a complete picture of their business and understand its direction.
First, data is gathered in one place. Then a graph is created with a semantics layer placed on top, containing information about the data, thus creating a knowledge graph. Analyzing the knowledge graph uncovers new information in the data.
To create a knowledge graph, you must be careful about which toolset you choose. If you need to use several different solutions, it is impossible to gather data entirely and thus impossible to analyze it. The ultimate result is slow decision-making. An excellent tool are graph databases, which are designed to explore relationships and hop through data. Using tools that cannot explore relationships and hopping requires a lot of coding to make just a few initial steps in the analysis.
As a graph database, Memgraph fits perfectly into the knowledge graph use case. It also offers free and open-source graph analytics algorithms. As each business needs to deal with unique problems, one algorithm cannot solve all of them equally well. That’s why the library tries to offer an extensive range of analytics algorithms. The best part is that your team doesn’t have to worry about writing a single line of code. They can focus on creating knowledge graphs, understanding data and making sense of it.
Graph analytics is just one of many big pluses. Memgraph is also an in-memory graph database, which means you won’t have to wait a whole day for graph analytics algorithms to spit out your results or get obsolete results. But having an in-memory database doesn’t mean losing your data is possible since backups and data persistence are obtained using disk storage.
Modeling data using property graphs, as you would with Memgraph, makes sense since you can see all the nodes and how they relate to each other by examining their relationships. After dealing with relational databases for years, it’s hard even to imagine what complex questions graph databases can answer. Relational databases cannot provide such answers, or the execution takes so much time you don’t even try it.
In the rest of this blog post, you will see what algorithms you can use to ask specific questions and query the graph database, which will help you uncover knowledge hidden within your data.
Pattern-matching questions
The easiest way to discover new knowledge in graphs is pattern matching. Pattern matching is a basic exploration of data in which the database searches for nodes with a specific label connected with a relationship of a specific type to another node. In other words, it searches for the shape of the data you defined and retrieves results.
Content and connectedness
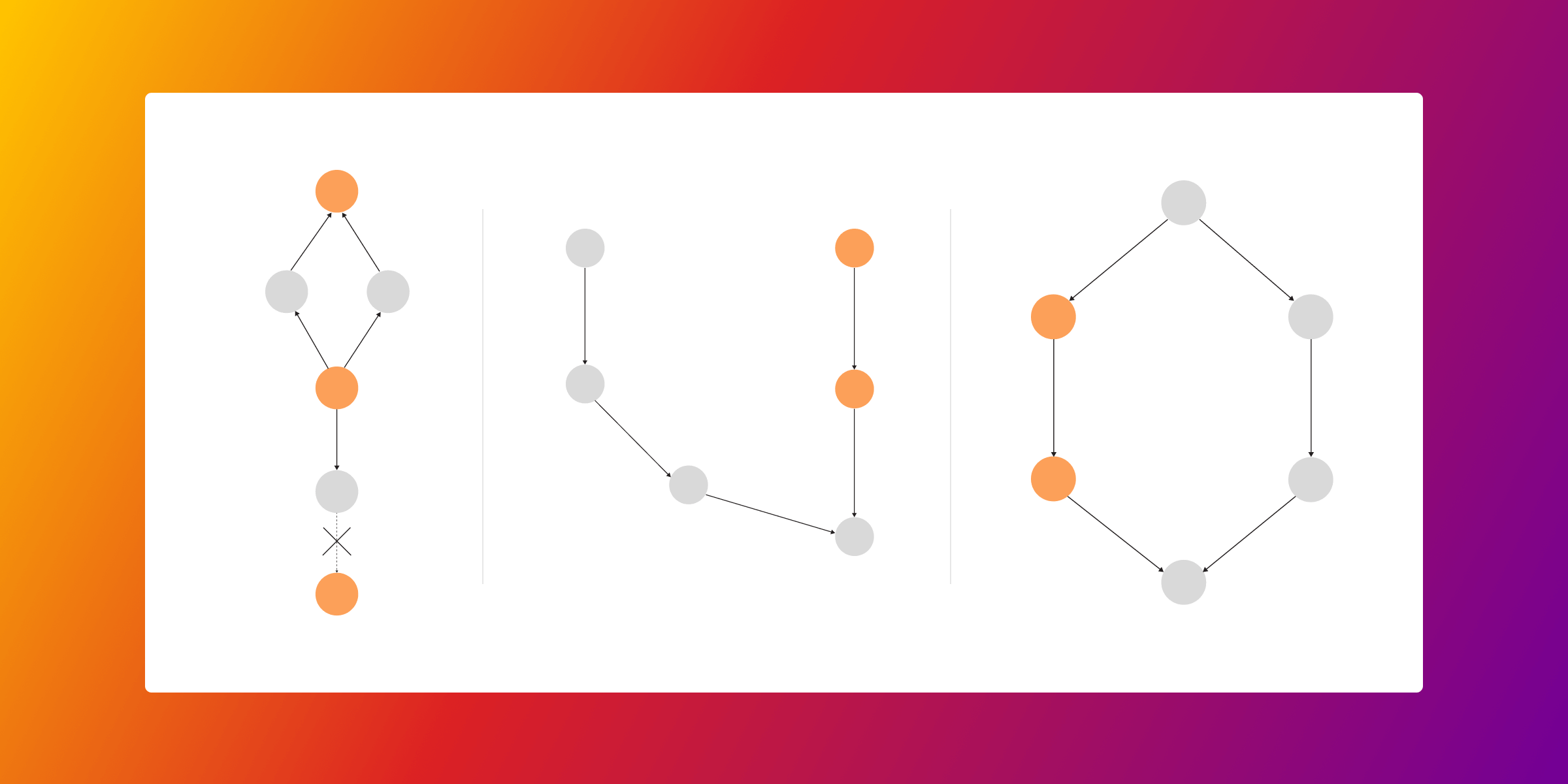
In finance, companies often question whether an account is connected to another account known for fraudulent activity. If one account is connected to fraudulent activity, all the intermediary accounts might also be connected to it, like a neverending string of handkerchiefs.
With Memgraph and basic pattern matching, you can uncover such connections with the following query:
MATCH p1=(n:Node1)-[*]->(m:Node2), p2=(n)-[*]->(m), (n)-[r]->(f:FraudulantActivity)
WHERE p1!=p2
RETURN nodes(p1)+nodes(p2)The query above looks for different paths p1 and p2 between node named n and node named m and returns such nodes on those different paths. As we mentioned above, such nodes could be part of some fraudulent activity.
Commonality
Graph analytics make it easier to think about cause and effect. Knowledge graphs particularly enable using some a priori knowledge about business processes to infer new knowledge.
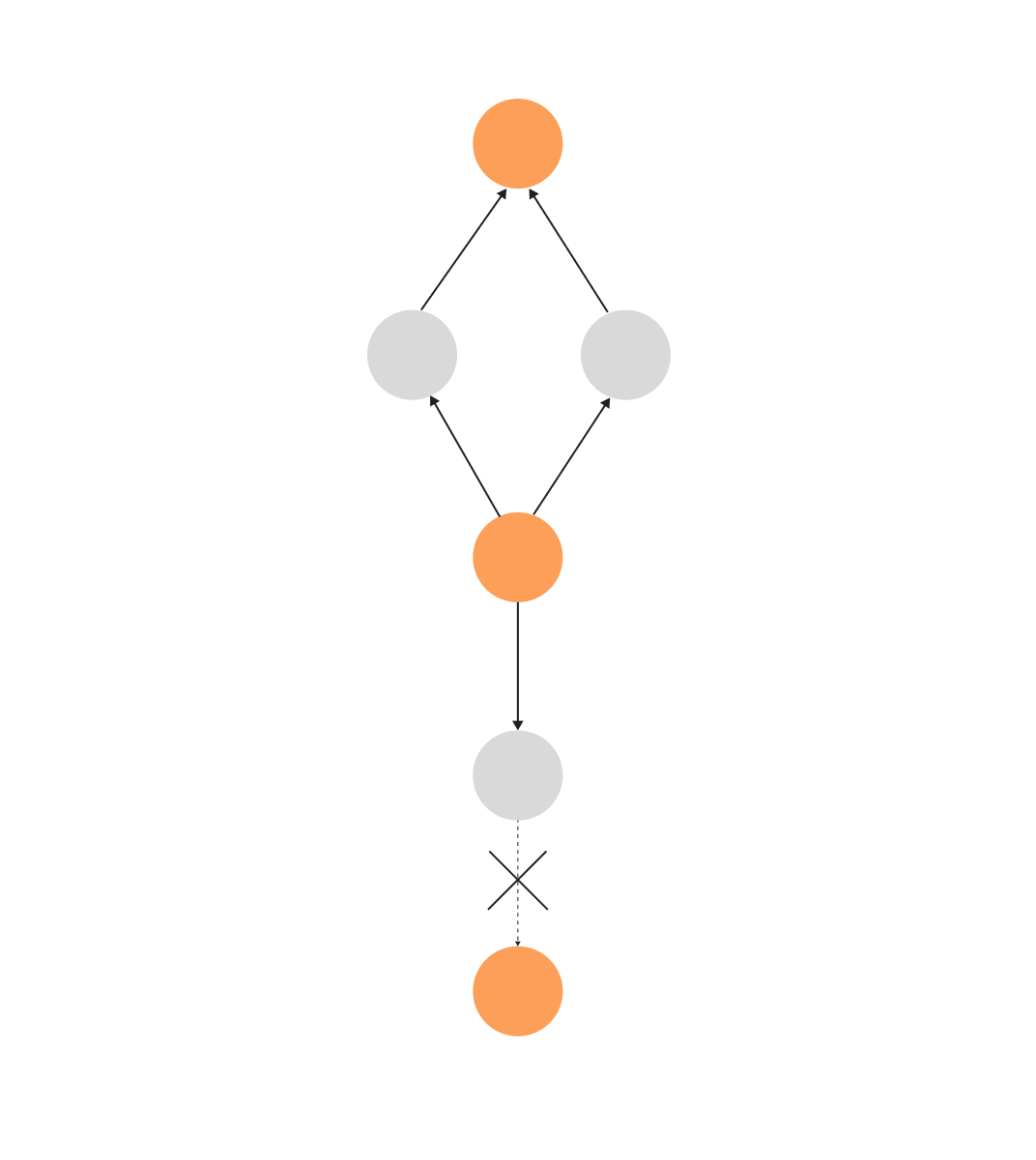
In finance, when the same person controls certain companies, it can be a hint of illegal activities. It’s quite hard to find a common denominator using a relational database since it’s impossible to know how deep into company ownerships you need to dive into, and there might be different numbers of owners.
Graph databases can search for a common ancestor or successor of a certain entity, like in the picture below, regardless of the depth or number of companies the database needs to search through:
A query written in Cypher would be as follows:
MATCH (n1:Node1 {prop:"a"})
CALL graph_util.descendants(n1) YIELD descendants as descendants_n1
WITH descendants_n1
MATCH (n2: Node2 {prop:"b"})
CALL graph_util.descendants(n2) YIELD descendants as descendants_n2
UNWIND descendants_n1 as dn1
WITH dn1
WHERE (dn1 IN descendants_n2) = true
RETURN dn1;The query above will first find all the descendants of node n1 and all the descendants of node n2. If there is some descendant of node n1, which is also in descendants of node n2, then we have found a common descendant, which is exactly what commonality is looking for.
Alternative action
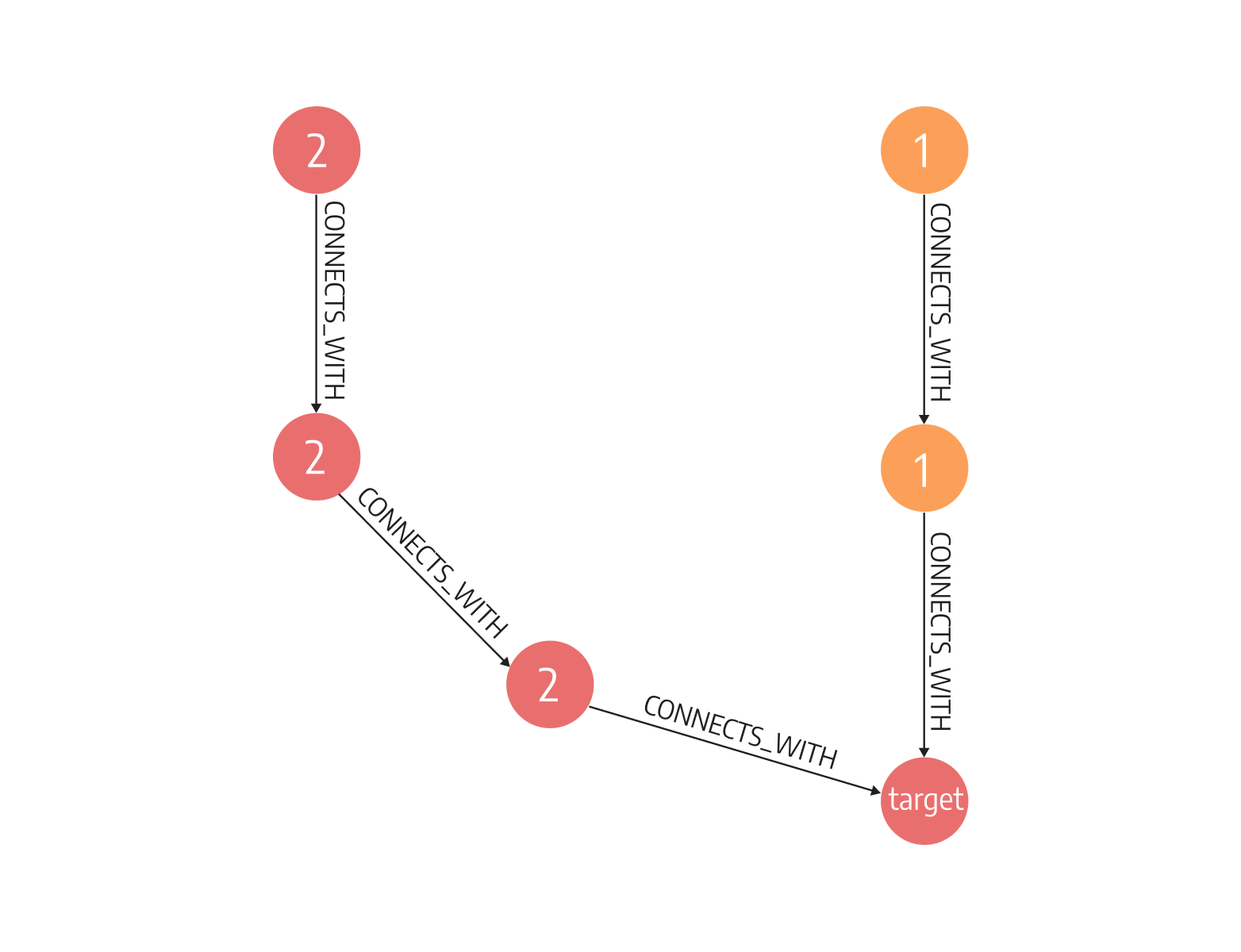
Mistakes happen all the time. Once they do, the most important question is how to soften the blow. In finance, once a certain branch is deactivated, we need to find another way to get money transferred.
To do so, we need to find content equivalence. Content equivalence finds a similar path between two nodes. It helps protect the business from future failures at certain points in the finance chain. And it does so by finding alternative paths between two nodes. It involves node hopping and pattern matching, two operations graph databases, especially Memgraph are optimized for.
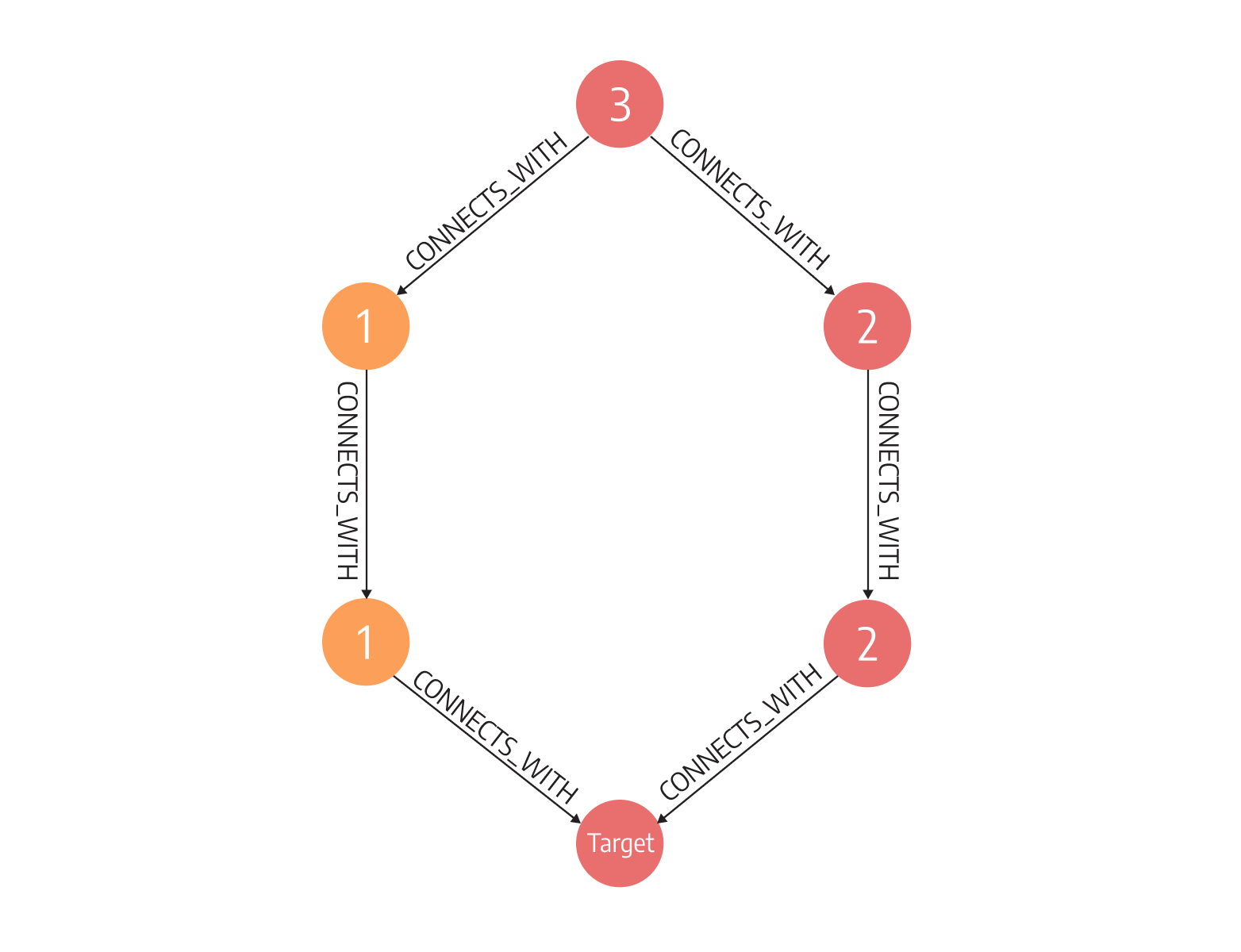
In Memgraph, you would ask such a question with the following query:
MATCH p=(n:Node3 {prop:"c"})-[r *wShortest (e,v | 1) sum]->(t:Target), (n2:Node2 {prop:"b"})
WHERE not n2 in nodes(p)
RETURN p
ORDER BY sum DESC;The following query finds shortest paths between starting node n and end node t. It returns paths starting with the shortest one; thus, you can see the most effective way to substitute your current solution in case something fails along the way.
Conclusion
Pattern matching doesn’t sound like a flashy analysis tool but combined with graph analytics algorithms, it is a powerful tool that can analyze almost any real-world graph regardless of how complex it is. So, if you are struggling with your highly interconnected data being scattered all over the place, don’t hesitate to use a graph database and employ graph analytics and pattern matching to discover new knowledge. The one relational databases can’t even start thinking about, let alone provide. Use a knowledge graph to uncover fraudulent activities or find alternative actions that can help avoid risks.