
Benefits Graph Databases Bring to Identity and Access Management
Identity and Access Management (IAM) includes technologies and processes that enable organizations to provide users with appropriate access to systems, apps, and data. In other words, it defines who gets access to what, for what reason, and at what time. The definition of identity and the individual structure of each organization defines the access management and, therefore, the company’s IAM.
In the digital world, people, services, and devices have an identity, sometimes even more than one, and those identities are becoming increasingly interconnected with rich and deep relationships. The job of IAM is to manage these relationships and permissions entities have to access resources.
The problem with traditional IAM systems and why they are failing is because they are mainly still using CSV files to extract data from the HR systems. And although CSV files are great for regular tabular data, grocery shopping lists, spending lists, and so on, analyzing patterns, exploring access rights, and dynamic checking for vulnerabilities is impossible with CSV files. To complete these tasks, CSV files need to be analyzed in their entirety, which is a long and complicated task.
But when the IAM data is modeled as a graph, the database can make such analysis out of the box, making any critical analysis and decision-making drastically easier and more performant. Traditional IAM systems struggle with certain issues, but graphs can make them all disappear.
But except for solving those problems, graph databases are always a better choice for IAM systems compared to traditional relational databases because they make the system perform faster and offer flexibility and scalability, which we will discuss in this blog post.
How graph databases increase performance
Within systems made out of millions of nodes and relationships, graph database access lookups over large, complex structures are executed in milliseconds. Upon new information, dynamic graph algorithms avoid the update of the whole graph and performance degradation. The changes are only applied to the parts of the graph affected by the new data. These features make graph databases faster and more efficient at analyzing highly interconnected data, such as the one found in IAM systems, than any other system built with relational databases.
Traversals through data are easier when using BFS or DFS hops
To completely understand data analysis in graph databases, you need to understand the concept of index-free adjacency. Index-free adjacency enables graph databases to explore neighboring nodes quickly, that is, perform hopping. Exploring neighbors is important to check whether the user has the right to access a file. In the following example, we’ll show you how graph databases increase performance in IAM systems.
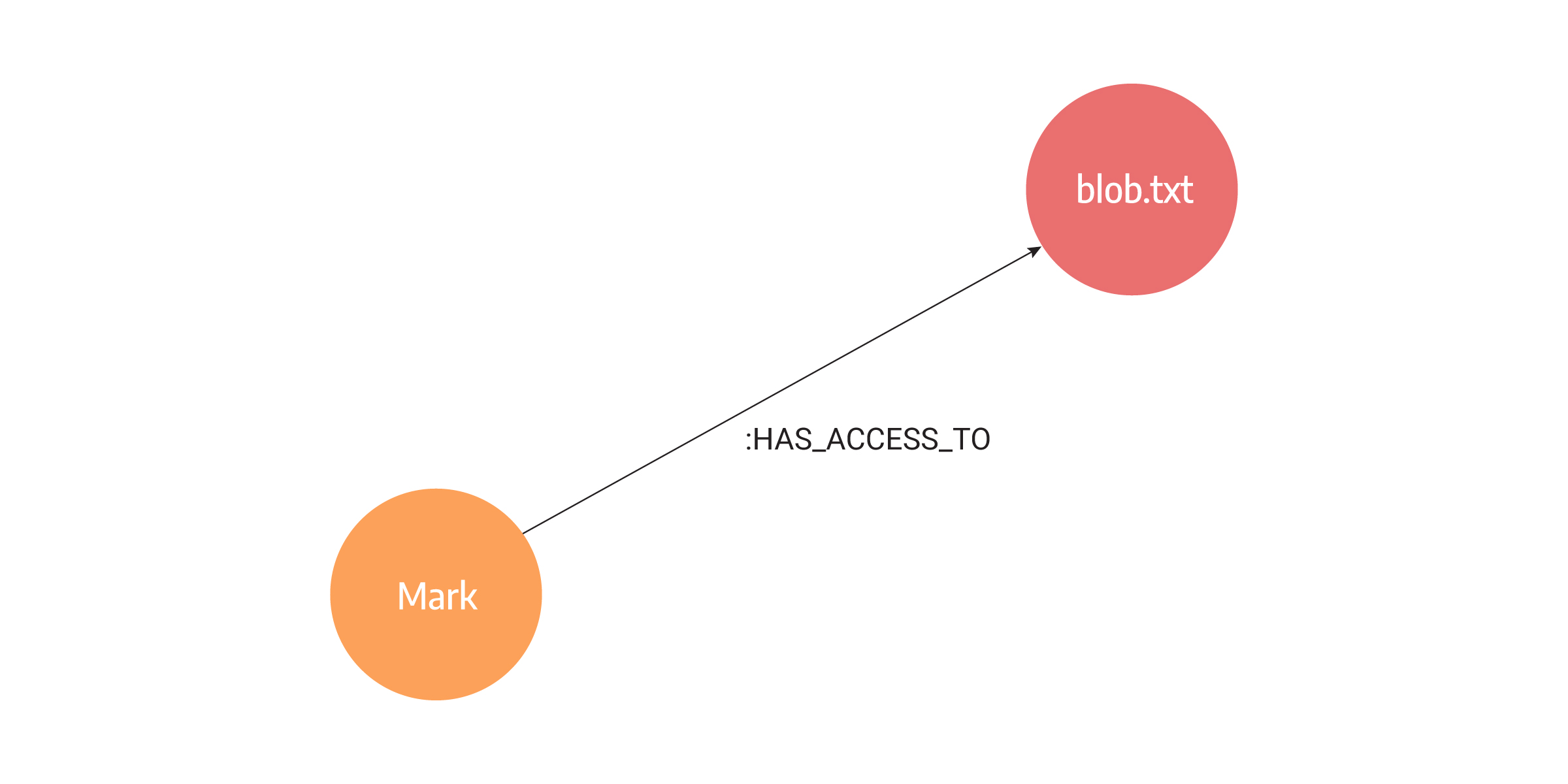
The image below depicts that concept by modeling Mark’s access to the blob.txt file. Here is an example that will clarify how the access checking process in the IAM system that uses graphs would look like:
- Mark wants to access the blob.txt file.
- Graph database finds Mark in the database.
- Mark node has a pointer to the blob.txt file, that is, the node is connected to the blob.txt file with a relationship indicating Mark has permission to access the file.
- Mark gets granted access to the blob.txt file.
By performing pointer hopping, a direct walk of memory, graph databases look up adjacent nodes in a graph. This is the fastest way for computers to look at relationships. In the case of the Mark node, the database holds direct physical RAM addresses of all the other neighboring nodes in the graph, in this case, the address to the blob.txt file node.
Most importantly, these relationships are created when the data is loaded, not during querying. For the IAM systems querying data is a far more crucial step than loading since querying answers the question of user permissions. Also, graph databases don’t have to work with any other data structures or indexes to hop between neighboring nodes. Also, related nodes are sometimes even stored next to each other in memory, which maximizes the chances that the data is already in the CPU’s cache.
In comparison, the primary design goal of relational databases is fast row-by-row access. That happened because COBOL systems that read from cards read one card at a time and were designed to group all the fields in their rows. Relational databases ended up inheriting the COBOL flat-file designs and retrofitting relationship lookups later as an afterthought. Worse than that, each relational JOIN operation is a search that typically doubles as the database doubles in size, meaning it results in O(log(n)) binary search operation. The more JOINs there are, the slower the search is. Relational databases excel at queries on small datasets with a uniform flat structure.
So graph databases are fast, but how fast are they? Expect a computer to hop between roughly a million nodes every second for each core it has on the server. If the server has 16 cores, the number rises to 16 million hops per second. For those with an NSA-scale budget, Cray Graph Engine with 8,192 cores is available that can do 12.8 billion (Giga) Traversal Edges Per Second (GTEPS) on the graph500 SSSP benchmarks. That’s a lot of row-to-row searches!
Compared to relational databases, the main problem is finding relationships. Let’s say we have one table for relationships(R) and another for people names (P). With nested loop JOIN, the cost would usually be O(|R| |P| |P|), where |R| is the cardinality of relationships, and |P| is the cardinality of people. For graph databases, going through relationships doesn’t require any table joining since relationships are already there.
Dynamic algorithms for system vulnerability
With traditional algorithms, you need to analyze the system every time new data comes in to check whether new changes create some vulnerabilities. With dynamic analysis, it’s possible to analyze only a subset of the graph where the changes happened.
Let’s paint a story from a telecommunications provider company using a graph database for Identity and Management Systems.
Data for telecommunication providers constantly arrive in the system. It contains the phone numbers, price plans, users of subscriptions, billing accounts, and any corporate or residential agreements providing discounts for all agreement members. To continue to provide security to its users, the telecommunication company relies on its IAM system to find specific security issue patterns before it impacts other users or files. Such checks prevent serious damage. Since updates are local and impact only part of the graph network there is no need to analyze the complete state of the IAM system every time.
This yields the need for dynamic analysis of the Identity and Access Management system. The need for dynamic implementation arises at the moment when different users, resources, and relationships between them arrive in a short period. The dynamic algorithms allow the previously processed state to be preserved, and new changes are updated in such a way that only the neighborhood of the arriving entity is processed at a constant time. This saves time and allows us to have updated and accurate information about correct rules in the Identity and Management System.
Flexibility and scalability
As companies grow, new teams are formed, changed, reorganized, or completely fall out. Most importantly, company partners and customers grow. Older Identity and Management Systems force rigid hierarchies. Such systems worked before, but as we mentioned, things change.
A company that doesn’t change and adapt will never grow. Moreover, rigid hierarchies force every relationship to be identical. In flexible teams, people may be at the same hierarchy level but need completely different access rights. And some companies have decided to abolish hierarchies altogether. Such organizations are difficult to shape in IAM systems relying on a strictly hierarchical structure of relational databases.
So companies are faced with two issues in their life cycle - the flexibility and scalability of Identity and Access Management systems.
Update the system easily by creating new rules
When a data model is inconsistent and demands frequent changes, using a graph database is certainly the way to go. Because graph databases are more focused on the data itself rather than the schema structure, they allow a degree of flexibility.
Moreover, a graph database is useful if:
- additional attributes have to be added at a certain time in the future
- not all entities share the same attributes and
- the attribute types are not strictly defined.
In Identity and Access Management, there are constant changes. Customers and partners are diverse and it makes more sense to have different data models for each partner. In some cases, the date of birth is important because the permission to access files depends on that information. In others, the location is the key, as there might be a regional dependency on file access.
One company using a graph database reported that one AI function helped them measure risk visibility and increase operational efficiencies by eliminating many management, incident, and reporting processes that security admins previously had to perform manually. Searching for specific nodes makes it easy to query a database to update certain rights to resources. In contrast, a relational database must always scan through every record in a table which often results in joining multiple tables to find which records are impacted by the update. The problem becomes more complex as the number of records in a relational database grows.
Scalability to multi-million model
Scaling is more than just putting more data on one machine or distributing it on various machines. It comes down to the acceptable performance of your queries. A question that often arises for graph databases is, does the performance speed remain acceptable when working with large or growing datasets?
For example, when tracking permissions to files millions of customers should have access to, the problem is how to store everything in one machine. Graph databases have found such a solution in distributed systems.
The query engine within the graph database knows where the data needed during a graph traversal is stored and sends the query to the query engine of each machine where data is stored. When a request is processed, it merges data locally and in parallel. Afterward, it sends the result to the client. With this approach, graph databases allow for performance characteristics close to a single instance. It is safe to say that databases with implemented distributed systems allow for outstanding performance and scalability.
Conclusion
This blog post explained how graph databases bring performance for Identity and Access Management. Graph databases enable AIM systems to find patterns faster, explore vulnerabilities dynamically, and traverse data swiftly.
In recent years, it seems even more natural to use graph databases for Identity and Access Management systems, given all the advantages graph databases have compared to the strict and rigid hierarchical structures of old IAM systems. And making the transition has never been easier. On the other hand, if such antiqued structures are valid for your company and your use case, it is best to stick to the old practices.