
How I Found The Most Influential Users on Hacker News
At the beginning of my internship and before starting this project, I had no idea what Hacker News was. So for people like me, here’s a quick intro - Hacker News is a website that contains content from the tech industry. Users submit stories from different web pages to the Hacker News community. Posts are upvoted or downvoted, depending on the community's liking of the post. If the submitted news is so popular, its score rises and the post climbs the popularity ladder until it reaches the most prestigious Hacker News place - the first page. While researching Hacker News, I kept coming back to the question to which everyone wants the answer: What determines if the post will land on the first page? Also, I was wondering if posts submitted by more experienced users have a better chance of landing on the first page of Hacker News.
How Hacker News works
From what I have seen, the total score depends on several factors. First, the time that passes from when the story is published on some website to the moment it is posted on Hacker News. Newer stories will always have a better score than older stories. Of course, upvotes also matter, but they influence the overall score in a way you wouldn’t expect. The story with a steady rise of upvotes over time will have a better score than the story which gains upvotes fast. The same applies to story comments. Having that in mind, I concluded that the story with more comments eventually stays on the first page longer, making the topic more interesting and influential.
Implementing Hacker News API and Kafka
To get data that will confirm or rebuff my predictions, I decided to connect to Hacker News API, made with Firebase, collect new data in real-time, and use Memgraph to save top stories and run PangeRank algorithm to find story gems. Once I could get the data, I wanted to live stream all the top stories because I’ve never worked with streams, so I thought it would be fun. The API endpoint provides only an array of IDs of the 500 top stories, but I needed only the first 35. I wanted to showcase users who wrote those first 35 stories and all the other stories those users wrote. I had to get every single one of those stories by their IDs. Fortunately, the comments on the story were also bundled up in that data, so I didn’t have to send more GET requests. Since I wanted my application to be real-time, I decided to use Kafka. So my Firebase service was a producer for Kafka.
After getting the data into a stream, finally came the easy part - implementing Memgraph and Kafka. I used a transformation module for all the incoming messages from Kafka. Then I connected Memgraph with the Kafka stream and - the data started coming in!
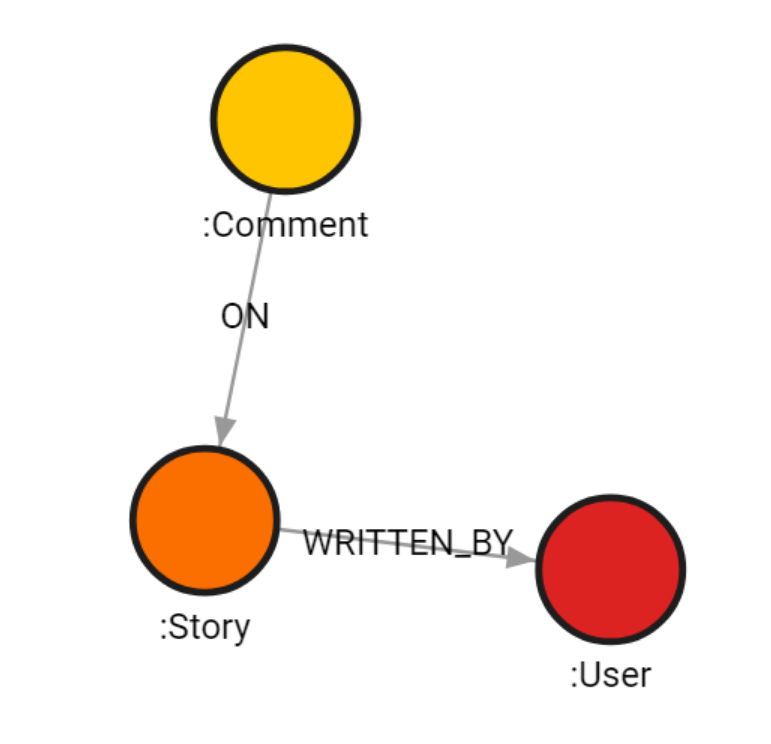 Picture 1. : How nodes are connected in Memgraph
Picture 1. : How nodes are connected in Memgraph
Memgraph and PageRank
I needed an algorithm to calculate the users’ scores. PageRank came to my mind and it worked great. Memgraph has PageRank already implemented, so I could easily use it. Next, I had to make the backend and the frontend part of the application. On the backend, I used Fast API and on the frontend, I used Material UI with the new graph visualization library Orb.
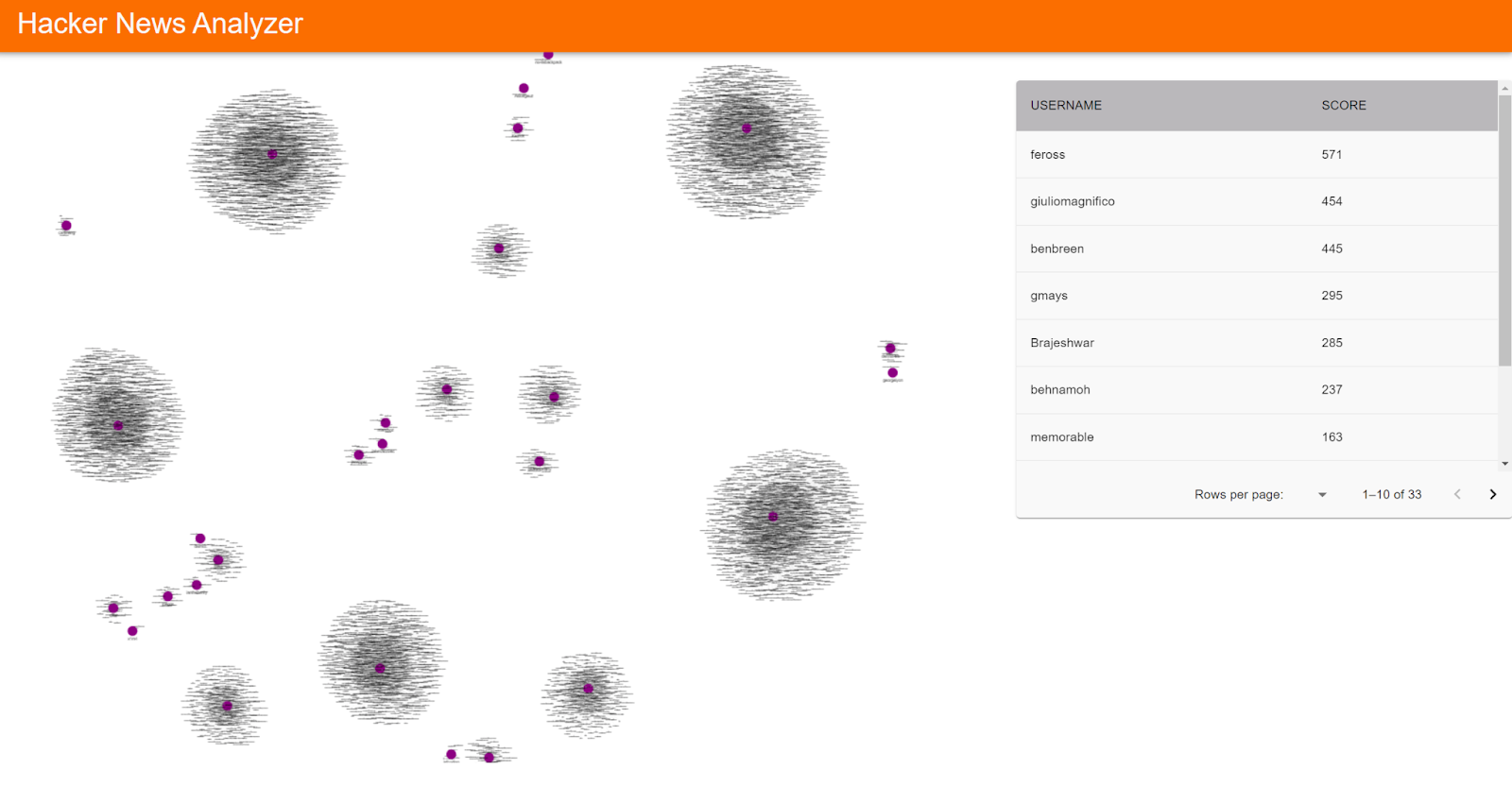
Picture 2. : Finished application 1

Picture 3. : Finished application 2
The answer to the question
After running the application a couple of times and seeing which users have a better score, I concluded that users with more experience writing posts on Hacker News DO have a better chance of landing on the first page. But, I believe this is due to how they write their stories and they already know what interests the Hacker News users. In general, it turned out that none of that factors make a real difference because luck is always the most significant factor. If you wish to check my application and run it for yourself, here you go! :)