
Why Your Business Should Use a Graph Database
Your business is operating in an ever more connected world where understanding complex relationships and interdependencies between different data points are crucial to many decision-making processes. This is the main reason why graph databases have gained a lot of interest in the past few years and have become the fastest-growing database category. They offer powerful data modeling and analysis capabilities your business can use to easily model real-world complex systems and answer challenging questions previously hard to address.
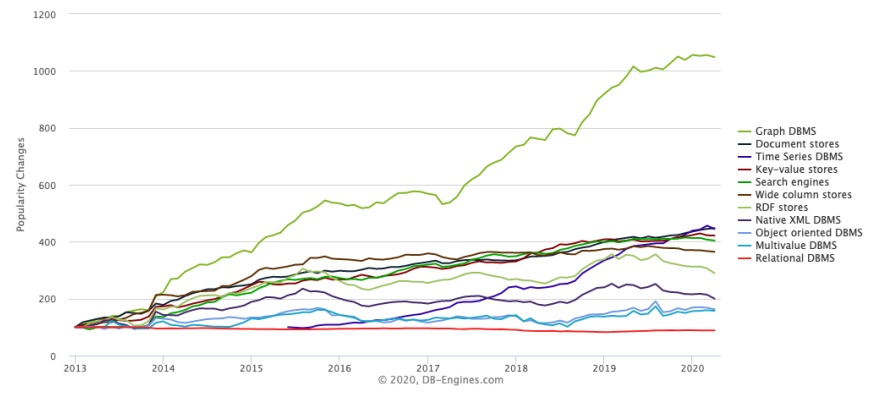
What is a Graph Database?
You might not be aware of it, but many of the services you use daily are powered by a graph database. Such examples include Google’s search engine, LinkedIn’s connection recommendations, UberEats food recommendations and Gmail’s autocomplete feature. Simply put, a graph database is a data management system specifically engineered and optimized to store and analyze complex networks of connected data where relationships are equally important to individual data points. As a result, they offer a highly efficient, flexible, and overall elegant way to discover connections and patterns within your data that are otherwise very hard to see.
Let’s take the example of an insurance fraud network.
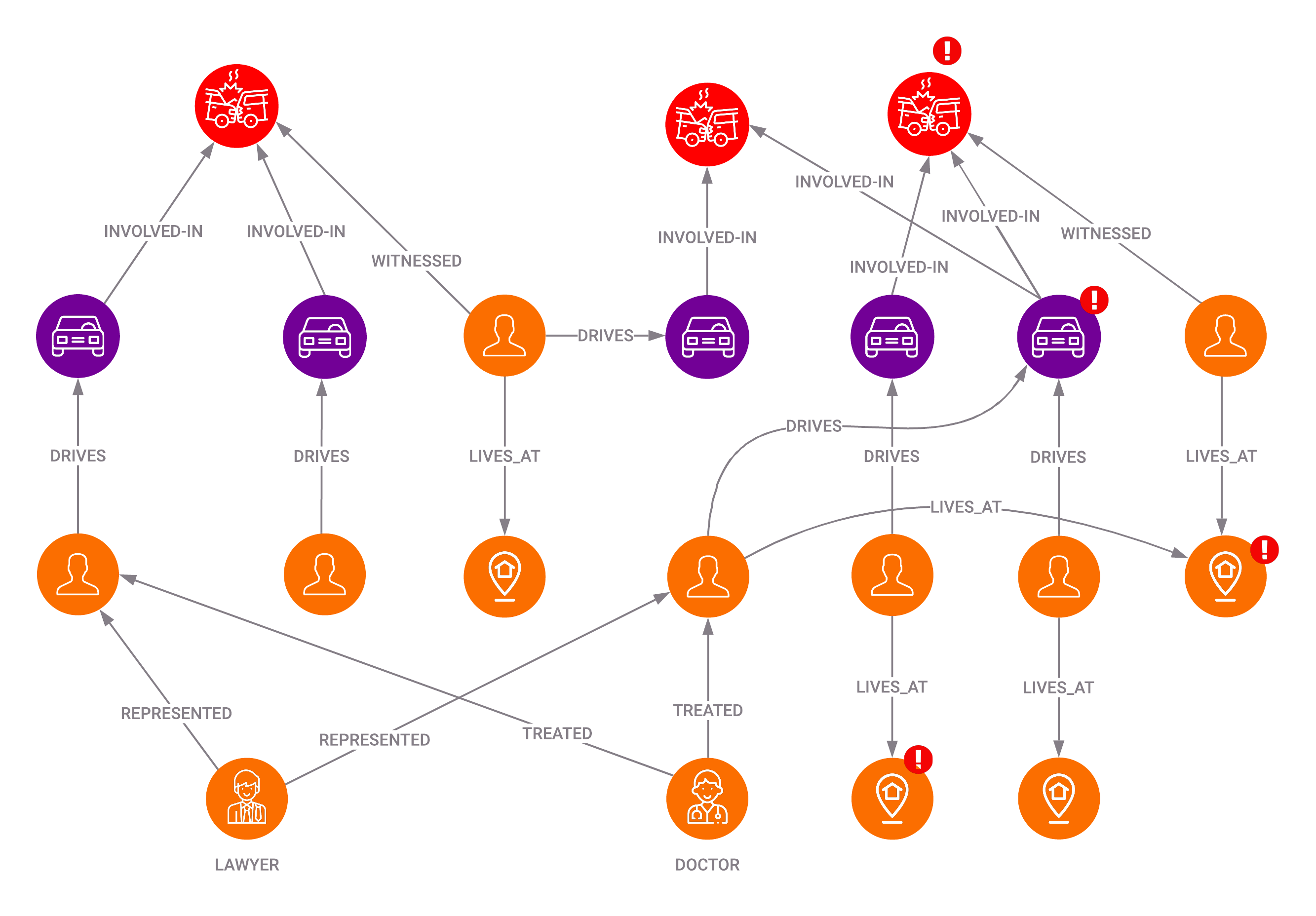
As we can see, there are suspicious relationships indicative of collusion between the different parties. The same individuals are linked to different cases, and the different parties use the same service providers. Of course, this situation is simplified, but it should give you an idea of how a network analysis approach can bring value in such a use-case. You would have a much more complex network involving millions of customers, claims, and conflicting information in a real-world scenario. In that case, you must analyze millions of relationships and data points to uncover anomalies and sophisticated rogue behaviors when detecting these fraud rings. Looking at events as isolated data points don’t make much sense.
Although modeling such a scenario might be possible using a variety of tools, including traditional databases, it will likely be a laborious, slow, and frustrating processing for your development team resulting in sub-optimal results and serious limitations. The reason behind this is straightforward. SQL and other NoSQL databases were not built to deal with highly complex interconnected data.
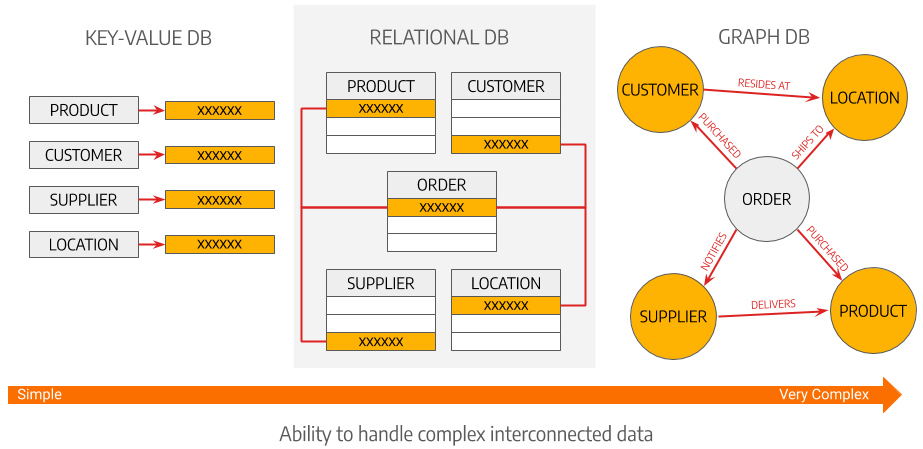
Graph databases strongly contrast with traditional SQL databases by taking a relationships-first approach to data from the ground-up. SQL systems treat relationships as second-class citizens and work hard to infer data relationships and navigate complex networks by leveraging a number of workarounds in the way they store and query the data. On the other hand, graph databases treat relationships as first-class citizens through every part of the data lifecycle from the model, to the storage engine, to the query language. As a result, when it comes to tackling some of the most complex data challenges, graph databases can offer the following business advantages:
- Performance at scale - One of the main drawbacks of relational databases when dealing with interconnected data is the severe degradation in performance as the number and depth of relationships increases. This means that with the right optimization, a SQL database can perform acceptably for small datasets on queries with a depth of two or even three hopes, but it will most definitely fail as your data scales. In contrast, graph databases are designed to maintain predictable performance for queries with 3+ hopes on datasets with millions and even billions of relationships.
- Flexibility and agility - With a graph database, your team can easily model complex business scenarios in an intuitive and easy manner due to the fact that the graph data model maps very well to the way we think about real-world problems. A modeling process that could take days in SQL could be done in a few hours. But it doesn’t stop there. The graph data model is also very flexible and can be easily changed at any time. This means that, unlike with the relational model, your team doesn’t have to spend hours to get the model right ahead of time and then spend a long time adjusting it when the business use-case changes.
- Low total cost of ownership - When using a database that was not built to store and query highly interconnected data, your team will need to put in place several workarounds and redundancies in an effort to get the job done. This might lead to the need to combine different systems, which could be expensive to maintain or use much more hardware to improve performance and scalability. With a graph database, you will avoid operational complexity and keep the total cost of ownership low and predictable.
How Does a Graph Database Work?
For many people, graph technology is much easier to understand than other database models as it’s very close to the way we think about the world.
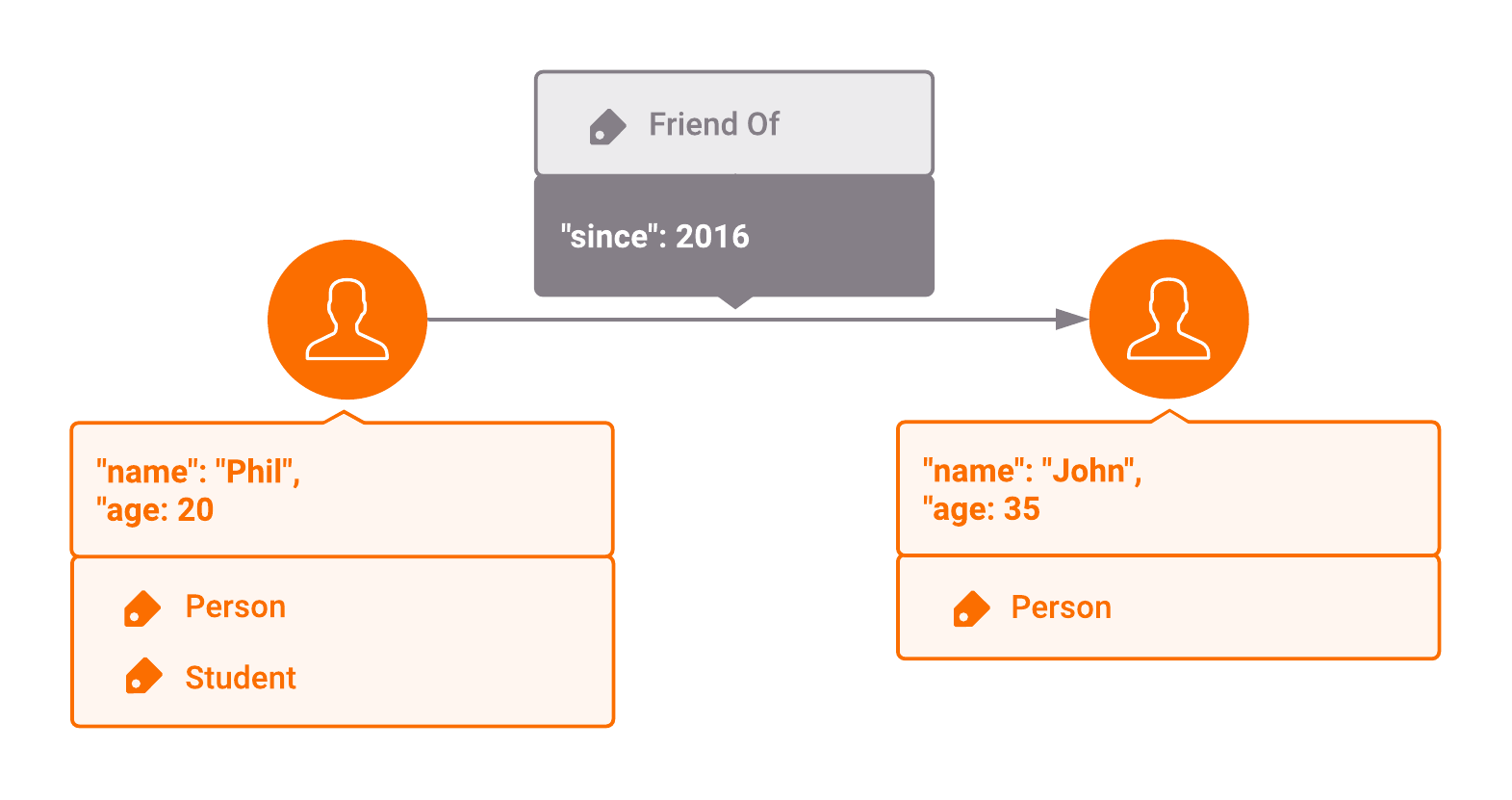
A graph is simply a collection of nodes (sometimes called vertices) and relationships (sometimes called edges). Nodes usually represent entities (people, places, objects, etc.) and relationships represent the connections between them. Both nodes and relationships can be enriched with additional information using Labels (usually used to assign a category, e.g., person) and properties(usually used to specify attributes, e.g., age, name, ID).
Graph Database Use-Cases
Businesses across every major sector are leveraging graph databases to tackle use-cases, including supply chain optimization, fraud detection, anti-money laundering, customer intelligence, risk analytics, product and service recommendations, and machine learning.
Graph databases are, of course, not suitable for every scenario, and you should always use the right tool for the job. Still, generally speaking, if your data has a high number of many-to-many relationships or even one-to-many relationships that go 3+ depths, you probably need a graph database. With this in mind, let’s look at two common graph database use-cases.
Fraud Detection
Although many fraud detection tools exist, these often rely on simple rules (e.g., is the transaction amount over or under 10K) and tend to analyze the behavior of an individual entity in isolation looking for deviations in factors like transaction frequency. In many cases, this could be enough. However, fraudsters are improving their methods and are increasingly using much more sophisticated tactics that combine synthetic identities and legitimate information, making them indistinguishable from regular customers.
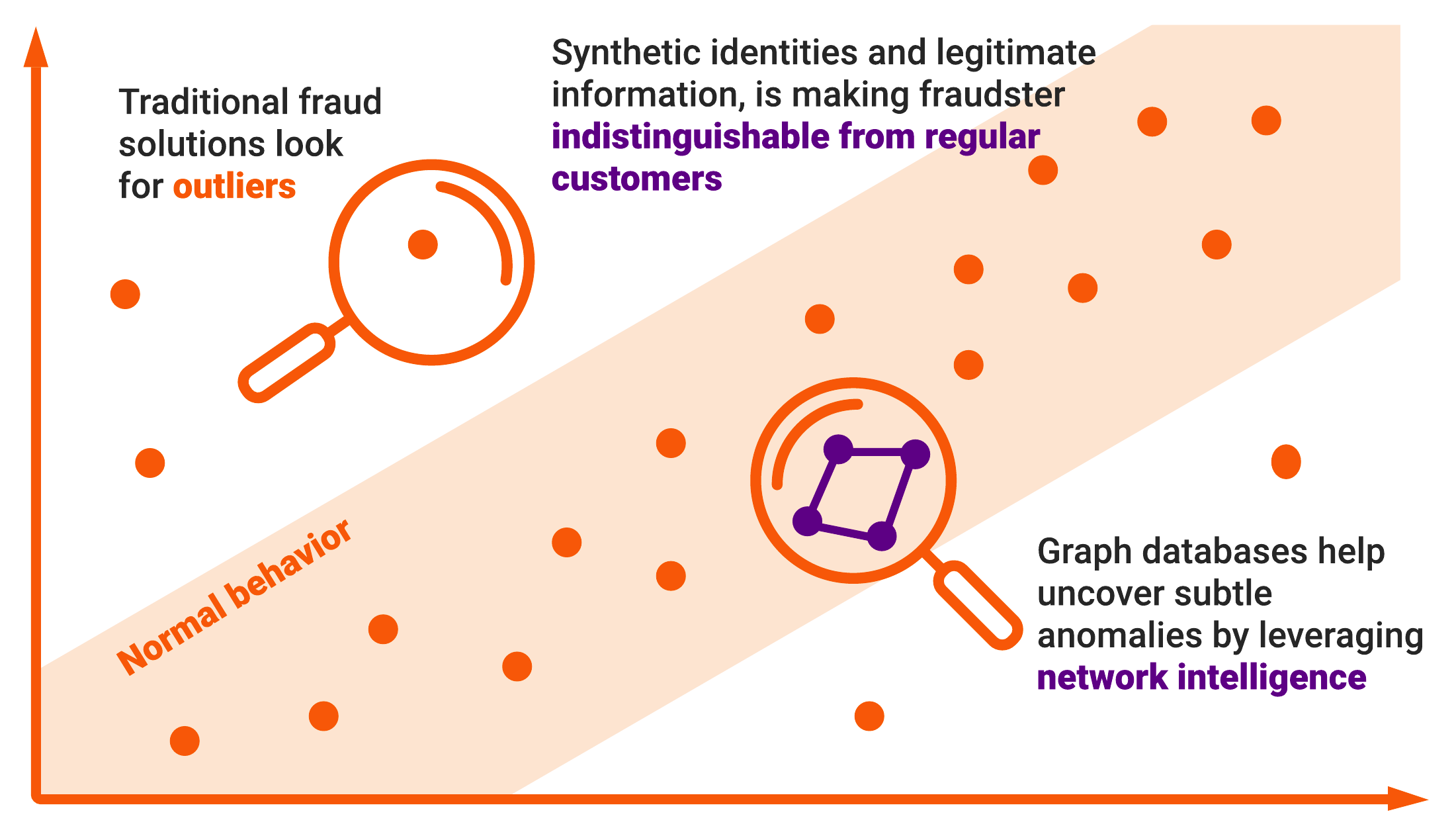
A graph database enables businesses to build sophisticated fraud detection capabilities by analyzing the behavior of multiple users across a period of time to detect anomalies that are otherwise very hard to see or encapsulate in hard-coded rules. A high-performance graph database system like Memgraph can analyze high-dynamic networks with millions of transactions and users to identify potential fraudulent activities as they’re happening, at sub-second speeds.
Real-time Product and Service Recommendations
Businesses are always looking at ways to maximize revenue and customer satisfaction with every interaction. The most effective way to achieve this goal is to match the right customers with the right products or services at the right time, much like Amazon or Netflix. These companies accomplish this sort of hyper-personalization due to their capability to analyze and contextualize everything they know about a specific user or product and recommend relevant products in real-time without relying on outdated pre-computed results.
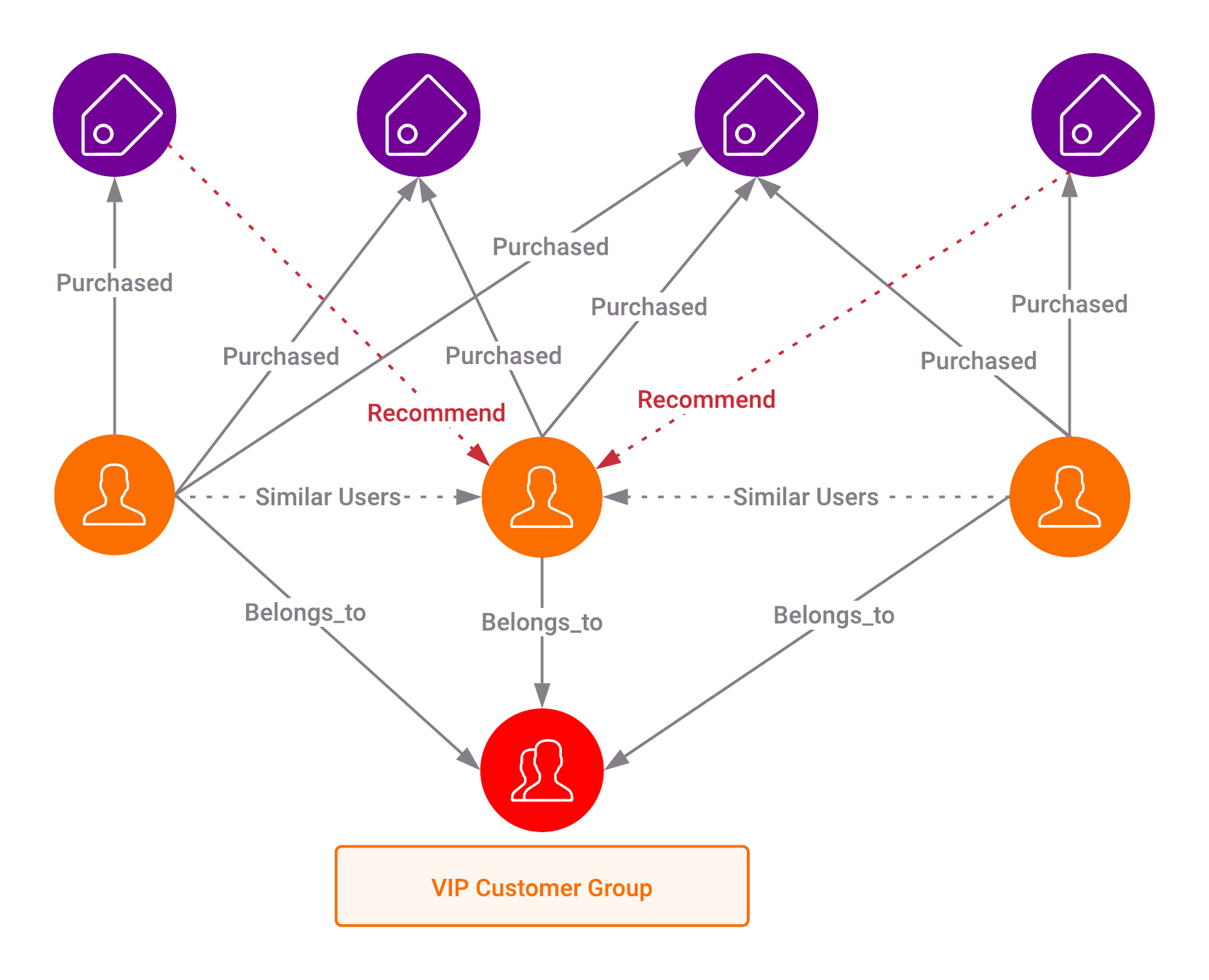
A graph database enables businesses to combine multiple data sources (customer information, purchase history, production information, clickstream data, etc.) into a single dynamic 360º model and run similar algorithms to recommend news products and services to the right customers at the right time. This results in more accurate and timely recommendations, leading to more transactions and a better customer experience.
Conclusion
When starting a project, it’s always important to pick the right tool for the job. When it comes to tackling use-cases where you’re looking to analyze complex networks of interconnected data at scale, graph databases are definitely the right option for you. They’re specifically engineered for such tasks and, as a result, provide your team with the performance, flexibility, and agility they need to build sophisticated business applications while keeping the total cost of ownership of your data infrastructure low and predictable.
Check out how graph databases compare to relational databases, how to model a relational data model as a graph and how various industries utilize graph databases.