
How Does Memgraph Ensure Data Durability?
Memgraph is an ACID-compliant graph database that ensures all changes are atomic, consistent, isolated from each other, and, at the commit time, become durable. In the database community, the database is considered durable if all committed changes persist, and no partial changes are ever visible once the transaction aborts. However, by no means is this an easy task to accomplish.
In this blog post, I’ll try to give a brief overview of durability theory in databases and how Memgraph achieves durability.
Which failures do databases suffer from?
Databases have to successfully deal with several types of errors to be considered durable. Transaction failures happen when a database error occurs (e.g., deadlock) or when the database’s internal state is inconsistent (e.g., logical constraint violation).
System failures can be divided into software and hardware failures. Software failures occur because of a bug in the database or OS implementation. Hardware failures are further divided into repairable and non-repairable. Repairable hardware failures assume all issues from which the database can recover since the non-volatile storage hasn’t been damaged. There are also non-repairable hardware failures from which no database can recover. An example of such a failure is when the HDD or SSD is destroyed.
Memgraph’s implementation of durability
Most of the databases today (including Memgraph) use Write-Ahead Logging (WAL) together with checkpoints to ensure persistence. The biggest advantages of such an approach are a small overhead added to the runtime performance and several tunable parameters that can be used to tailor the database to the customer’s needs. The main idea behind WAL is to write changes to the disk-persisted log file before committing.
The only real alternative to WAL + checkpoints is shadow paging, Shadow paging works by having two copies of the database, the master and the shadow. The master database stores only changes from committed transactions while the shadow database is a temporary one, storing changes only from uncommitted transactions. However, such an approach leads to fragmented data, requires a garbage collection process and is inefficient because of the constant need to copy data between two databases. That’s why this approach has been abandoned in recent years, and the last big name that used shadow paging was SQLite.
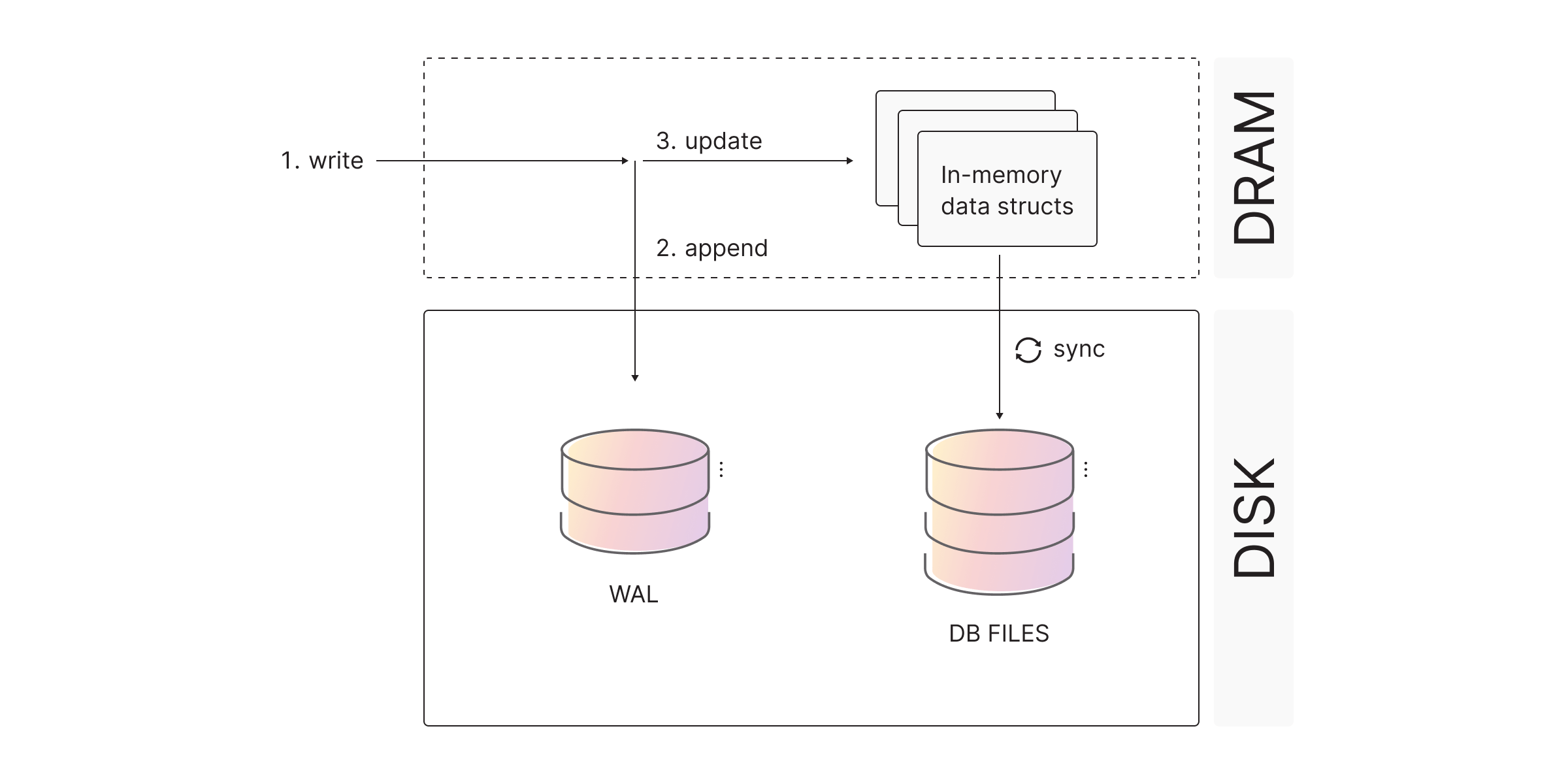
Recovering data
Writing queries to a persistent log file for recovery purposes would be inefficient because of the size of the query string. Therefore, Memgraph reuses delta storage to store changes to the log file. In the implementation of concurrency control, all changes are stored in the undo chain. Using such an approach is very convenient since objects (vertices and edges) can store their latest versions and then depending on the active transaction, objects’ visible version can be obtained by traversing the undo chain. For the purpose of recovery, the undo chain is converted into a redo chain so that when the recovery starts, actions can be redone by simply traversing the redo chain in a log file from the past to the future.
Why bother with checkpoints?
One obvious problem with Write-Ahead Logging is that it can grow indefinitely since the database constantly logs updates to the log file. That’s where checkpoints come into play. Every N seconds, Memgraph takes a snapshot of a database by serializing the whole graph to the disk. The parameter N can be tuned in a specific manner since it very elegantly represents the tradeoff between the runtime overhead and the memory occupied by WAL buffer: the smaller the N, checkpoints are taken more often which increases the runtime overhead but the WAL buffer is cleared more often.
How do we ensure consistent snapshot-taking?
Serializing the whole graph to the disk is an expensive process and must be carefully done since the database must make sure that it serializes only the committed changes. One could ask, then, isn’t that extremely inefficient in a concurrent environment since all other transactions must be paused? Memgraph uses a very nice trick: the snapshot-taking is implemented by creating a separate transaction with a snapshot isolation level. The biggest benefit of this is that the snapshot transaction then blocks only global storage operations, like index and constraint creation/deletion. All RW operations on vertices and edges can freely operate without lock contention.
In retrospect
Ensuring the persistence of data is an important aspect of every database. In this blog post, we tried to briefly summarize and highlight Memgraph’s most important design decisions without diving into many technical details. You will find much more info on our documentation pages. As always, if something is unclear, feel free to contact us; we are more than happy to help. Until next time 🫡