
High-Performance Graph Applications for Every Developer
First things first, some news in TL;DR format!
- We’re launching Memgraph to bring the power of Graph Applications to every developer, and you can try it here!
- Open Source developers will be able to use Memgraph for free, under our innovative Business Source License! You can check it out on GitHub.
- We’ve raised $9.34M led by Microsoft’s venture fund M12 with participation from Heavybit Industries, In-Q-Tel, Counterview Capital, ID4 Ventures, and Mundi Ventures to scale our team and take the next steps toward
proving out our vision for a graph-inclusive future, and we couldn’t be
happier to have everyone on board!
And a little bit about how we got here
We first started working on Memgraph in 2016 to address what we thought, at the time, were the main barriers to adoption for Graph Applications, namely the enterprise-focused, heavyweight, existing Graph Database solutions and the accompanying platforms that required an all-or-nothing approach that didn’t fit in with modern tech. On top of that, they weren’t especially fast as well. So we strapped in and created a super fast, in-memory graph database that used modern protocols and the popular choice for query languages. It worked with the languages developers actually wanted to use, and we've set off to take over the world.
Well, things didn’t go exactly as we planned. Sure, in a few short years we had accomplished some really amazing things -- our database was super fast, had a decent developer experience, was extensible, and worked really well for the typical in-memory workloads we had seen while we were consulting. So what was the problem? While we were busy making a better mousetrap, the world had changed -- people were solving problems in different, frankly better ways.
So we recalibrated a bit (while keeping true to our roots of high-performance, in-memory, graph first design), and we’re super excited to present our first big, public step toward doing what we’ve really wanted to do all along: bring the power of Graph Applications to every developer.
Not only FAANG employees or companies with giant data science teams -- but to every developer, from the Open Source hobbyist to the small business building new exciting things as well as to the Enterprises who are adapting to the same changes and pressures we’ve felt before.
Sounds cool? Here’s a breakdown of what we’re announcing:
We’re introducing Memgraph: a super fast, in-memory graph application
platform that plugs into your existing architecture and supercharges your data
capabilities with the power of The Graph.
Memgraph is available to download and try today, under a Business Source
License that is truly the best of both worlds for Open Source and
application developers.
Memgraph is ready to help you get the most out of your streaming data, or to
help you incorporate new sources: Memgraph consumes data directly from
Kafka, or can easily consume data from other static sources.
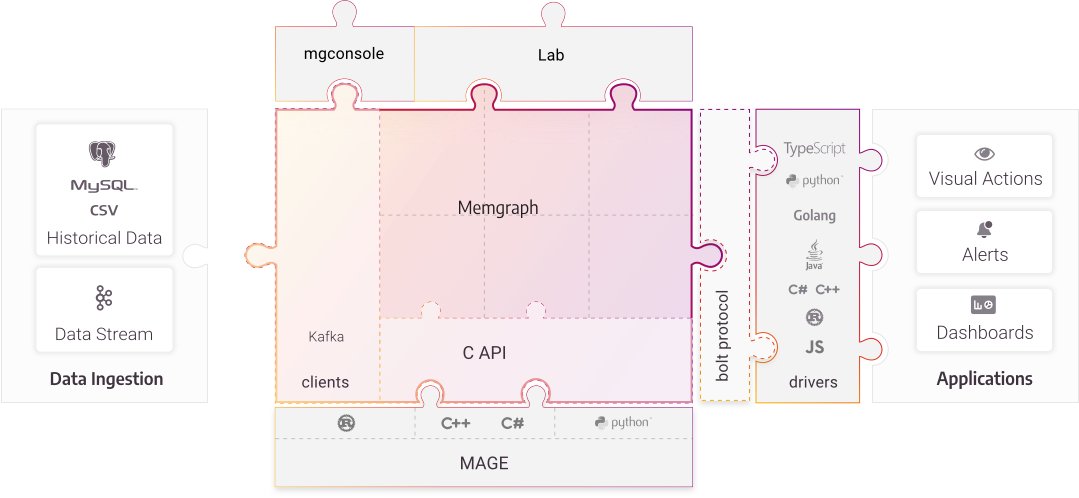
We’ve made a ton of headway into making high-performance graph applications accessible for everyone, and if you have streaming data sources you’d like to build on top of, Memgraph is an excellent solution. You’ll be hearing much more from us soon, but for now, here’s how you can get started:
- Join our community - there are some really cool things going on
- Get on the mailing list - we’ll keep you up to date
- Download it now - you’ll be graphing in minutes
- Try the Playground - just a few clicks to see what it’s all about
- Join our Launch livestream - it’s going to be excellent
As always, please get in touch if you have any concerns, comments, or want to share what you’re making!