Natural Language Querying with Memgraph Lab
Memgraph uses Cypher - the most widely adopted, fully specified, and open query language for property graph databases to query the database. With Cypher, you express what to retrieve but not how. This allows you to focus on the problem domain instead of worrying about the syntax.
Although Cypher is intuitive, switching from one tech stack to another within your team is sometimes hard. With the rise of AI technology and improvements in large language models (LLMs), it is possible to translate natural language into Cypher queries, given the appropriate context. By making it possible to query a graph database with the natural language, we bring graph technology closer to any user. In that way, almost anyone can query a graph database.
Learn Cypher or use LLM, that is the question
We asked ourselves: what is the best approach? Should we work more towards education in Cypher or utilize LLM for Cypher query generation? There are a lot of materials online on Cypher, and we also did our share. Memgraph Playground offers lessons on various difficulty levels to learn Cypher and get a jump start on your project. Besides that, with the Cypher manual, you can learn how openCypher is implemented in Memgraph and get a good sense of how to apply it in your use case. Ideally, we would fill the knowledge gap with LLM, and more people could use graphs to help them with their use cases. We’re aware of the power that artificial intelligence brings to the table, so we decided to try it out.
Integrating Lab backend with LangChain
Memgraph Lab is Memgraph’s visual user interface that enables you to visualize graph data using the Orb library, write and execute Cypher queries, import and export data, manage stream connections, view and optimize query performance and develop query modules in Python.
To enable natural language querying in Memgraph Lab, we integrated the Lab backend with LangChain. LangChain is a framework for developing applications powered by language models, and in our case, we decided to power this new feature with OpenAI LLM.
The backend in Lab is written in Node.js, so we extended the GraphCypherQAChain from the LangChain.js library to work properly with Memgraph. To do that, we had to create a new connection object that connects to the running Memgraph instance and creates a new chain with the OpenAI LLM. Additionally, we implemented a query function defining how Memgraph should be queried and a function that correctly refreshes schema from data stored in Memgraph.
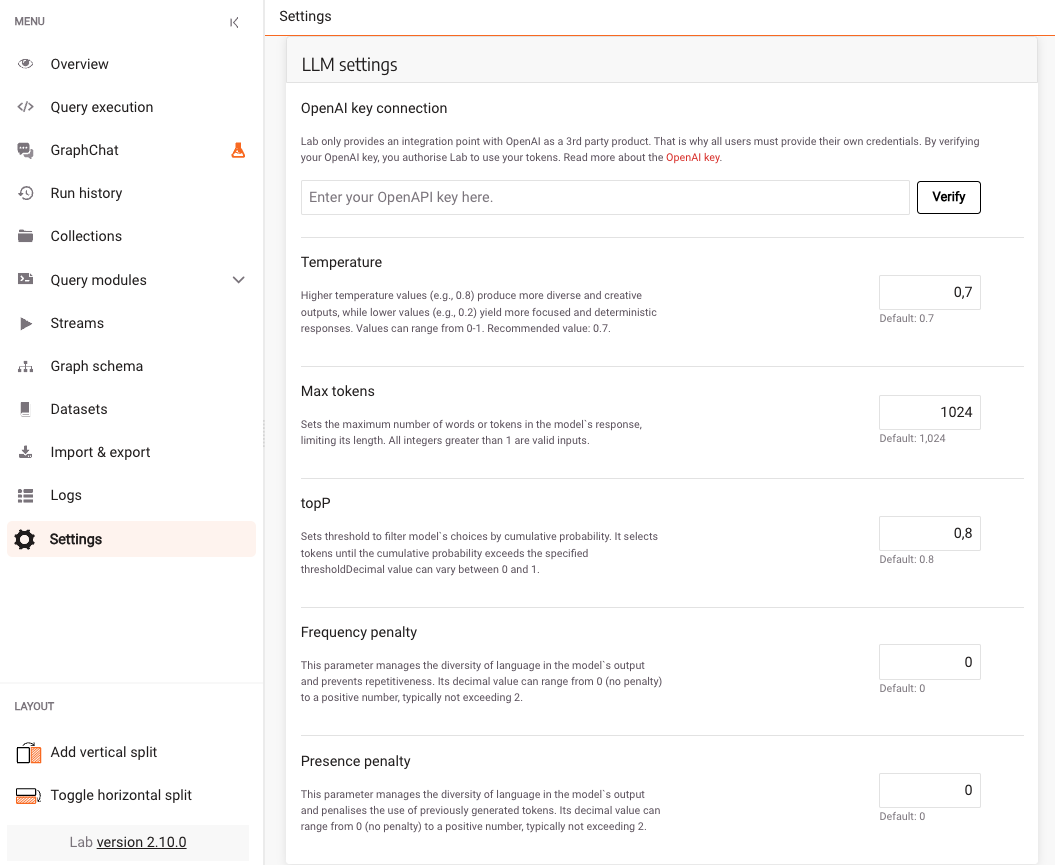
The feature is still experimental, so we allowed users to customize temperature, maxTokens, topP, frequencyPenalty and presencePenalty features. By default, the GPT-4 model is used with the following parameters:
- temperature = 0.7 (Controls the randomness of the output. A higher temperature results in more varied and creative responses, while a lower temperature produces more predictable and conservative text.)
- maxTokens = 1024 (Defines the maximum length of the model's response.)
- topP = 0.8 (Controls the diversity of the generated text by focusing on the most likely next words. A lower value means the model will concentrate on a smaller set of possibilities.)
- frequencyPenalty = 0 (Higher frequencyPenalty reduces the likelihood of the model repeating the same line of text.)
- presencePenalty = 0 (Higher presencePenalty encourages the model to introduce new topics and ideas in its responses.)
The primary goal of the feature is to help users who are not familiar with Cypher to query Memgraph with natural language. Besides that, the intermediate steps are displayed, which help the user to understand how LLM translated natural language into a Cypher query and to see what response Memgraph gave on the generated Cypher query. The provided intermediate steps proved useful when LLM wasn’t sure how to translate the result from the database into natural language.
Have a chat with Memgraph
It all sounds great in theory, but how does it actually work? We added the GraphChat feature in Memgraph Lab to read from or write to Memgraph in natural language. The context provided to the LLM consists of the database schema currently stored in Memgraph. By providing context, LLM can generate better answers, and if you’d like to learn more about how the schema for LLM was created, check out Memgraph Community Call with Brett Brewer, who worked on defining the optimal schema format.
Prerequisites for using GraphChat are an OpenAI API key, the MAGE library and a populated database. Once those three conditions are met, you can start chatting with Memgraph.
The easiest way to have Memgraph running along with MAGE and Memgraph Lab is to run a simple Docker command:
docker run -p 7687:7687 -p 7444:7444 -p 3000:3000 --name memgraph memgraph/memgraph-platform
For other ways of installation, please refer to the documentation.
We imported a preprepared Europe backpacking dataset from Memgraph Lab to populate the database. After that, we can start querying the database.
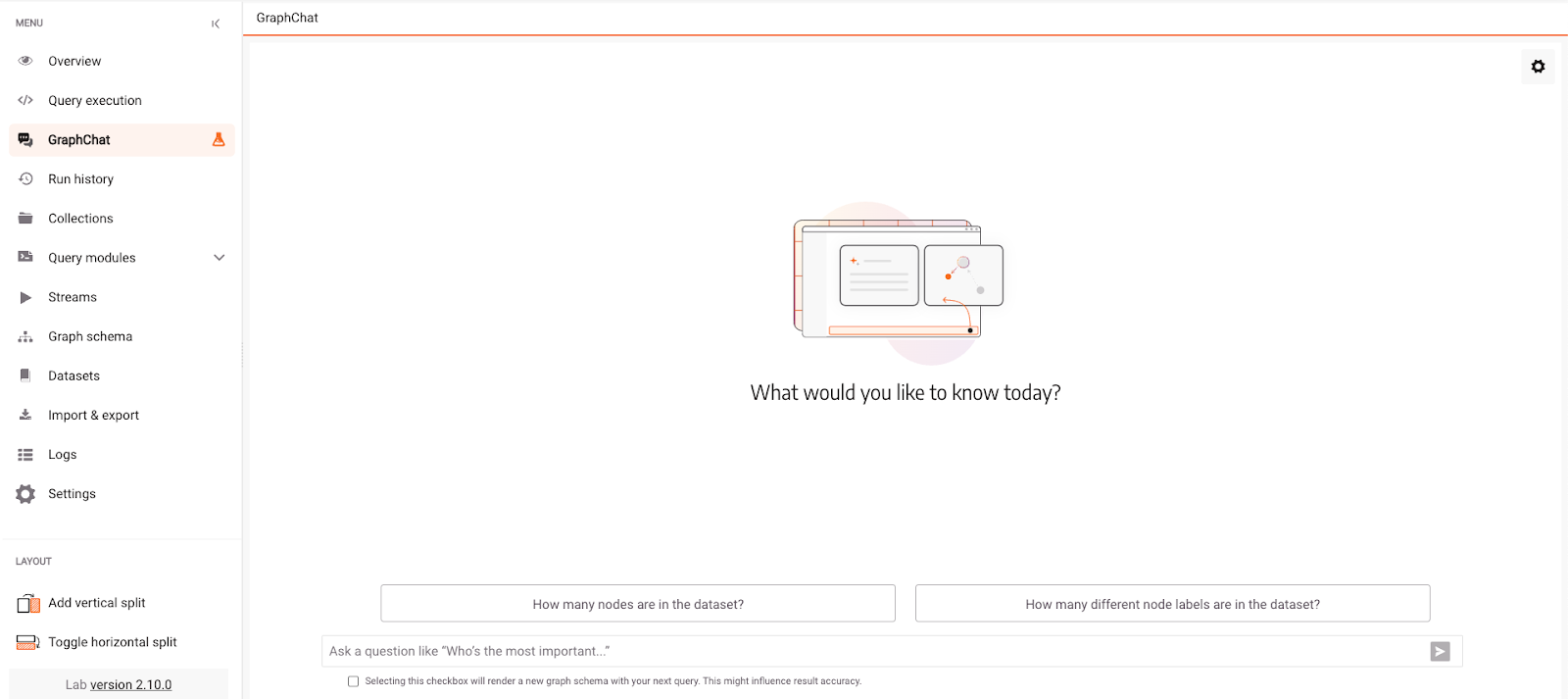
When querying the database, we ask GraphChat to translate the current natural language query to Cypher, which is then automatically run in Memgraph, and the results returned from Memgraph are translated back into natural language and shown as a result. With LangChain, we provided the graph database schema to GPT-4 OpenAI LLM to give it better context when figuring out the correct Cypher query. The schema is generated in the beginning and then cached, so make sure to select a box to render a new graph schema if the data model changes in the meantime. GraphChat still does not have memory, so every query is a question for itself, and it is not aware of the previous questions and answers. Let’s ask some basic questions about the dataset first.
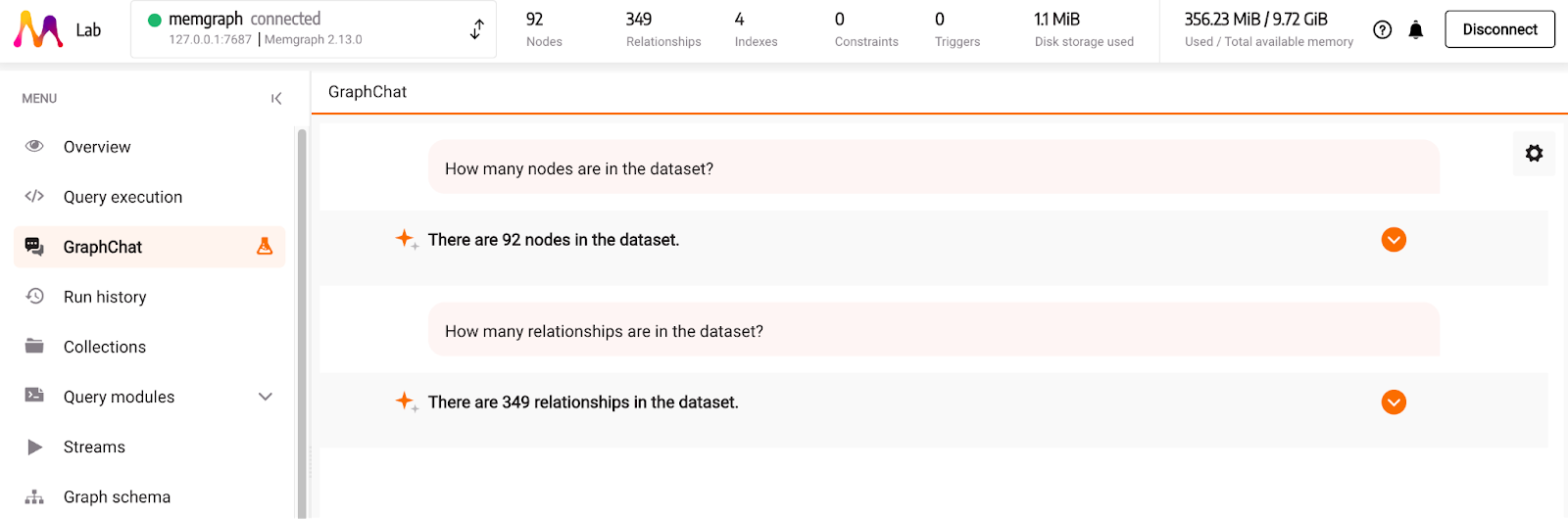
Next, let’s ask a bit more advanced questions to see how it performs. First, we must familiarize ourselves with the dataset to get the most accurate answer. If we head over to the Graph schema tab in Memgraph Lab, we can generate a graph schema and see what the dataset looks like. We can also see available properties by clicking on the nodes and relationships.
One of the countries stored in the dataset is Spain. Based on the schema, it’s interesting to find out which cities are in Spain and which hostels you can visit there. When traveling on a budget, it means a lot to know which one is the cheapest one.

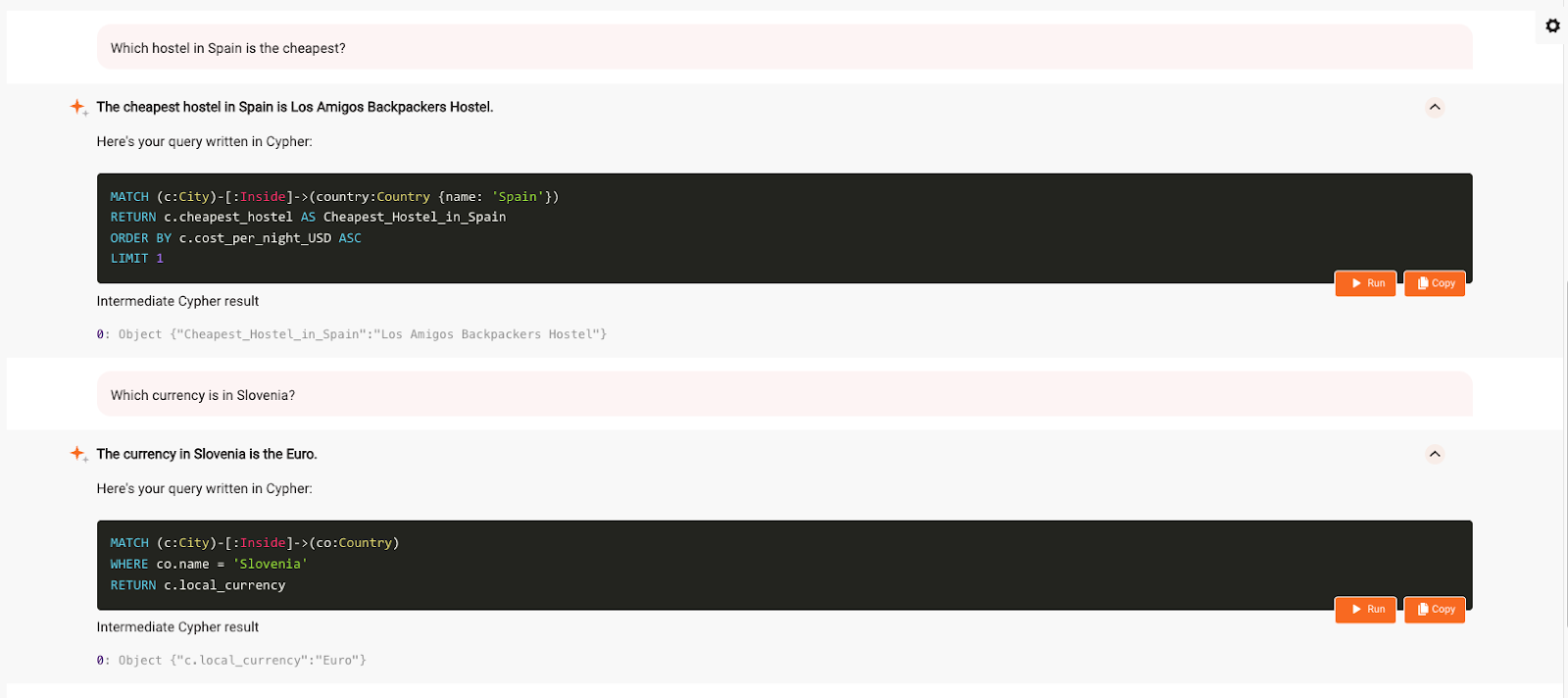
We learned all of that with just English, without worrying about Cypher. The GraphChat provides intermediate steps to determine which Cypher query was run in Memgraph and which results were returned from the database. This is helpful if you’re learning Cypher or don’t get the correct answer and might want to tweak the generated Cypher query. As you can see below, LLM generated a query that finds all cities in Spain, looks for the hostels in them and orders them by the cost per night in the ascending order with limit 1 - giving us only the cheapest hostel.
Each city also has a local_currency property, and we can see how well LLM understands the schema by checking the local currency of the country.
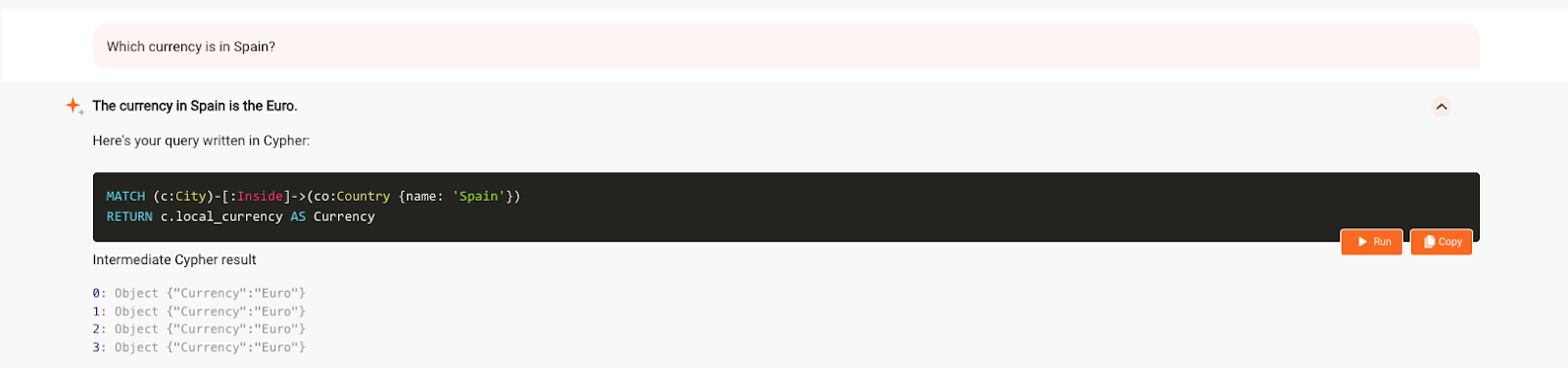
Although the information about the currency is stored as a property of a city node, GraphChat still finds it based on the country input and responses in natural language correctly.
If we decide to travel around Spain, it makes sense to check the total cost of the stay, including accommodation, attractions, meals, drinks and transportation. Let’s see what GraphChat has to say about that.

Besides reading the information from the database, you can also write to the database with GraphChat. Prices are always changing, including increased prices of meals and drinks. Let’s ask GraphChat to update the prices for Barcelona from 11.16$ for drinks to 12$ and from 23.808$ for meals to 25$.
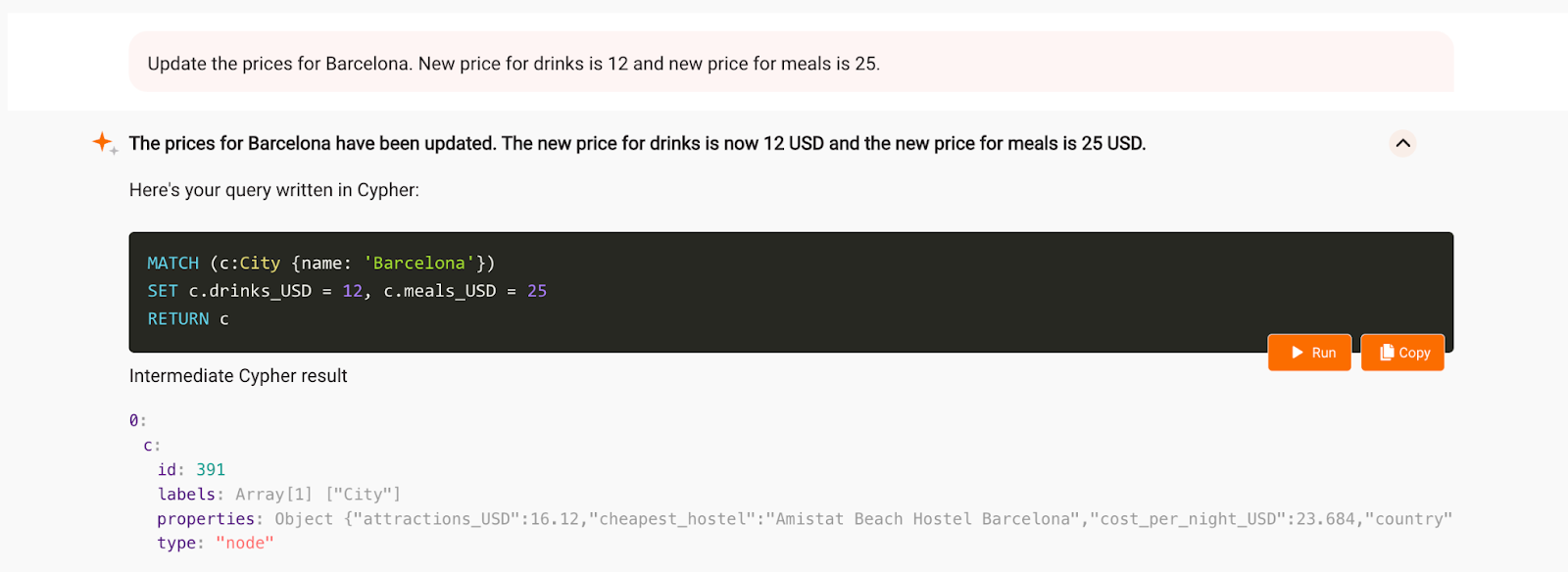
To verify that the prices are updated, you can run a Cypher query in the Query execution tab and check the new values of the properties.
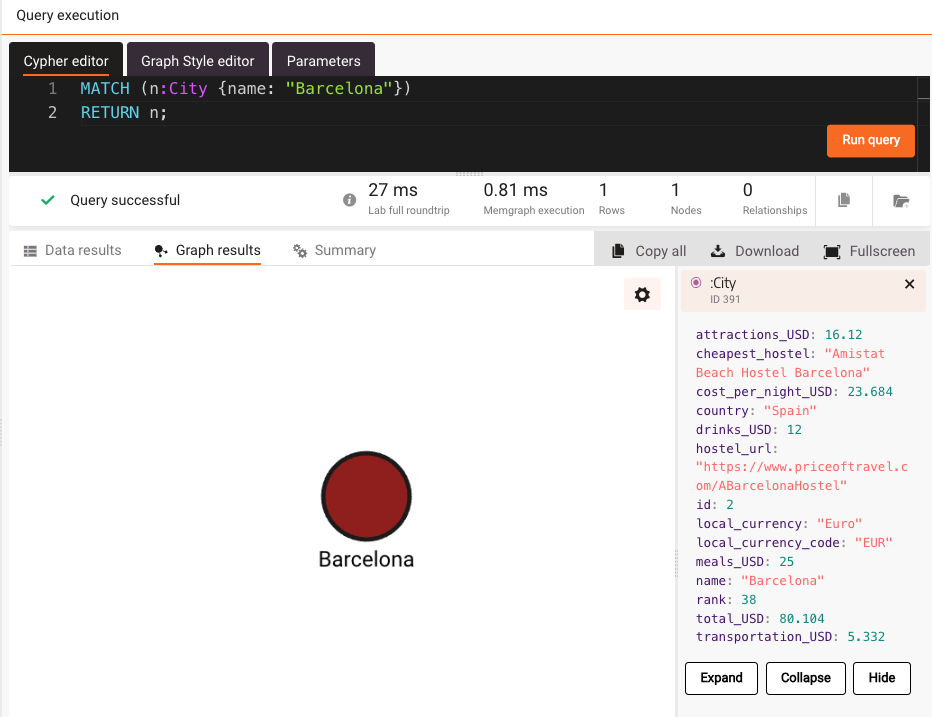
The prices have indeed been updated and we didn’t have to know how to actually do it in Cypher, because GraphChat did it all for us. To tweak the default settings of the model, head over to the settings tab and update the values. It is also possible to update the OpenAI API key there.
Conclusion
By integrating LangChain with Memgraph Lab, we are a bit closer to contributing to LangChain JS so anyone can play with Memgraph and LLMs in their project. Currently, GraphChat is in the experimental phase because we first wanted to do the simple integration to see how it works. The next versions of GraphChat will be more advanced and we’re looking forward to your feedback. If you notice a bug or have a suggestion, please open an issue on the Memgraph repository. We are also hanging out at Memgraph’s Discord server and are eager to hear your opinions on GraphChat.
Next Steps
Interested in enhancing your chatbot technologies? Watch our webinar, Microchip Optimizes LLM Chatbot with RAG and a Knowledge Graph, and read the detailed follow-up blog post, How Microchip Uses Memgraph’s Knowledge Graphs to Optimize LLM Chatbots.