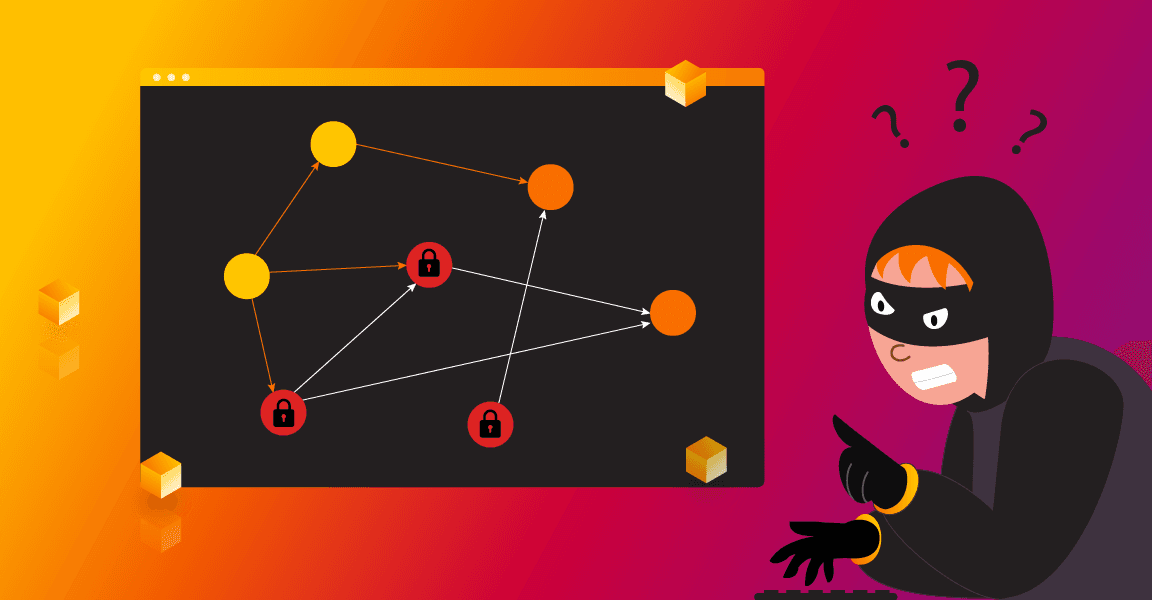
Label-Based Access Control in Memgraph - Securing First Class Graph Citizens
Identity and access management are one of the key features a database needs to have in order to execute in a secure environment. As companies are growing from startups to corporate giants, and the hierarchical structure of roles builds on a yearly basis, the need to secure the confidentiality of information becomes crucial for preventing data leakage.
In this article, you’ll learn why is authorization necessary in databases, how deep you can go with it, and at the end, we’ll tell you about our thorny path of implementing authorization over specific nodes and relationships, our first class graph citizens.
Massive Amount of Data Screams Security
The cardinality of data ingested into databases, warehouses, and other storage engines is growing day by day. Data stems from various sources. It is streamed from message queues like Kafka, it’s being recorded at every checkpoint in the supply chain network, it’s gathered from personal file systems, etc. Data can be unstructured or structured, and have various semantics.
Once raw data is processed and ingested into a database, the company has a massive amount of connected data that is waiting for the data scientists to apply their mean analytical and algorithmical skills to uncover the knowledge. Some data could be strictly confidential because it consists of private client information, and therefore requires additional security provided by the database administrator. In other cases, data can only be manipulated by an accountable senior engineer, and it’s preferred to give them exclusive data manipulation superpowers for additional safety.
The two aforementioned use cases have different approaches to solving. Having different client information separated usually screams multitenancy, while making data operations restricted from certain roles requires some basic privilege and access commands for advanced security.
Types of Authorization in Databases
Let’s just say, there are levels to how deep a database can be authorized. In the simplest scenario, all the data is visible, but to make sure it doesn’t get corrupted, the database administrator forbids the write access to the database. It’s usually the most effective way to prevent an inconsistent state, because developers need to know how they will affect the data by writing into the database manually. This information is enough for debugging, one can see what’s currently happening while inspecting the code, and these are in essence all prerequisites to track the application lifecycle.
Sometimes, database admins can make tables or specific rows inaccessible. It’s not because they’re mean people, it just means that certain people don’t have high-enough clearance to see them (if you recognize yourself in this sentence, don’t worry, you’ll climb the ladder if you push hard enough).
In the graph database space, disabling access to tables or rows would therefore correspond to restricting operations over specific node labels or relationship types. The end result? By tailoring the data labels specifically, multiple views or subgraphs can be constructed which is defined only by user privileges!
Setting the Authorization Goals
When we thought about what we wanted to achieve in Memgraph with more granular access control, we took into account the corporate hierarchical structure. Based on that, we designed an identical level of permissions a user can have in the database.
The basic access permission READ includes only the ability to see a node or a relationship. An increment to that, called UPDATE, would grant the user both read and editing privileges to the same entities. The final privilege, CREATE_DELETE, grants the aforementioned privileges, as well as new ones - to create and delete entities. If the users has none of these permissions, they are granted NOTHING to the entity.
If you are a database administrator, here are a couple of examples for granting permissions:
- for granting the READ permission over all node labels
GRANT READ ON LABELS * TO user- granting READ and EDIT to a relationship
GRANT UPDATE ON EDGE_TYPES :my_edge_type TO user- denying access to a specific node
GRANT NOTHING ON LABELS :label TO userOne point of discussion when a specific company wants to design its authorization policy is should all users start with all labels initially visible, and subsequently be denied access to the nodes (blacklisting), or have the users start with no visibility and grant them labels one by one (whitelisting). When new labels of yet unseen confidential data are imported into the database, whitelisting ensures they are invisible to all the users and therefore secure until the database administrator grants users with clearance access to the data.
You are now familiar with the usage of the label based access control. As easy as it might look, the implementation through the database internals was quite thorny so the rest of this post is going to be much more adventurous, so please sit tight!
The Naive Assumptions of How to Model Authorization
The first approach we took while designing more granular authorization, was looking at the database queries, and what actually comes out of them. Let’s take a look at the basic Cypher command which returns all the data in a graph:
MATCH (n)-[r]->(m) RETURN n, r, m;
If a user has restricted visibility on a node, or a path of the graph, there is a choice to be made - to either make the commands fail (with an error/notice of having insufficient visibility), or just return the triplets of the graph that the user has the permission to see. We preferred the latter choice because if the person querying the database is an attacker, any exception would inform him there is something more valuable in the graph.
That’s a pretty strong argument not to report any errors when a person is denied visibility. Let’s go back to the query. In the simplest scenario, we can wait for the result at the end and just filter out the triplets that the user is not supposed to see. How easy is that? Well, it turns out, it’s not that simple, if we look at the next query
MATCH (n)-[r]->(m) RETURN COUNT(*) AS count;
The result of this query is an integer primitive, which is actually not something we can authorize, but it could give the attacker enough information to guess the size of the graph. We haven’t even touched upon relationships of a graph, making paths, or granting higher privileges, and we are already facing the hard truth of authorization implementations - we have to take a deep dive into the query execution mechanisms inside the database.
Delving into the Operator Tree
In query languages, as well as compiled programming languages, there’s a standard way of processing commands. It all starts with a lexer component, which analyzes every token of the command. Lexer component is usually followed by a syntax analyzer, which catches any invalid commands to the language. The product of the syntax analysis is the AST (Abstract Syntactic Tree), which is a valid language command. Programming languages take different approaches from this point onward, as they build semantics and latter on generate machine commands to execute.
Databases, on the other hand, have nesting operators as a mechanism, where an operator is a concrete action over the input data with possible transformed output as a result. In the database jargon, some of the actions can be: get me a node from the storage, filter it over certain expression, aggregate a group of entities based on a function, delete something, etc. Stacking operators one over another, gives us an operator tree, which is an end-to-end set of instructions of extracting insights from a database. A brief explanation can be found on the picture.
With operators all figured out (there is literature below for curious fellas), we can conclude that an appropriate place to put authorization in the database would be in certain operators, and to be more precise, in those that either retrieve nodes or relationships from the storage, or do manipulations over them.
If you look at the article on profiling, you can actually get the output of the operator tree in Memgraph based on the query you entered.
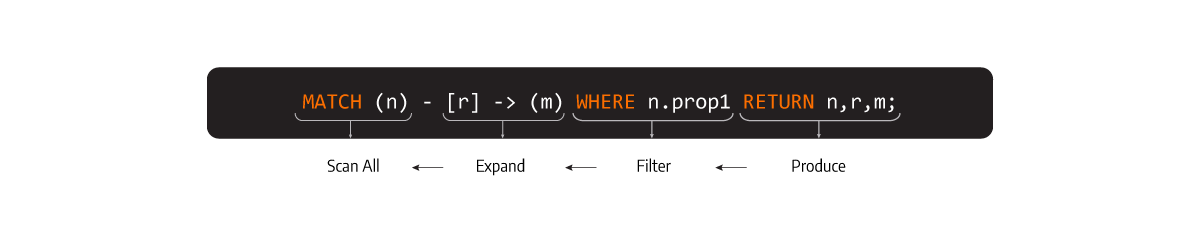
For example, if you typed the following Cypher command:
PROFILE MATCH (n)-[r]->(m) WHERE n.prop = 2 RETURN n, r, m;
You would get the operator tree in this order
ScanAll -> Expand -> Filter -> Produce
ScanAll corresponds to the MATCH clause (finding the nodes in the storage), Expand is the traversal of a node to its closest neighbors, Filter is a predicate for a specific property, and the Produce streams the results to the client.
Performing Actual Authorization
Luckily, that was actually all the knowledge we needed! The next step is identifying a set of operators to add modifications to and apply certain clearance.
In the previous example, we had four operators, four candidates for possible authorization. Out of those four, only ScanAll and Expand would need to be authorized explicitly with a READ clearance, while Filter and Produce can be left out since they only either filter the authorized nodes based on node property or return the actual results to the user.
And that's it! As a final note, we were debating whether to return an exception on UPDATE and CREATE_DLETE clearances and decided that being too silent can also cost us. But, at the same time when an exception should be returned, the users can already see the nodes, so it's fine to notify the users they are unauthorized to make those changes.
What’s next?
You made it to the end, good job! Be sure to check the docs on label based access control. If you need more context, check out it’s predecessor, the how-to-guide for managing user privileges.