
Vector Search Demo: Turning Unstructured Text into Queryable Knowledge
Dealing with vast amounts of unstructured data? Think documents, emails, social media posts, or even surveillance footage. Extracting valuable insights from it can be a cumbersome task. How do you turn this raw information into actionable, queryable knowledge?
In a recent Memgraph Community Call, Josip Mrden, our Head of Solutions, demonstrated how Memgraph's built-in vector search capabilities helps tackle this challenge head-on.
He showcased how to build an interactive app with a simple Q&A interface and even an automatic pub quiz generator from ingested text, highlighting the potential for educational tools and smarter information retrieval apps.
Built with Memgraph graph database, vector search, and a lot of creativity, the app demonstrates how quickly and effectively you can build AI-powered learning tools.
Whether you're a developer, data scientist, educator, or just curious about how graph databases work with modern AI workflows, this session has plenty to offer. If this sounds interesting, you’ll want to dive deeper into the actual demo, learn how it was built, and get inspired to build something yourself. Watch the full session here:
Here’s a breakdown of the key technical takeaways and live demo shared during the session:
Talking Point 1: Why This Project
What started as a weekend side project quickly turned into an impressive demonstration of how you can convert unstructured text into queryable knowledge using Memgraph’s new vector search.
Josip is known for supporting users and customers hands-on. But he also loves pub quizzes. So, one weekend, he combined both passions to build a demo Q&A and pub quiz application.
Tech Stack Used
The tech stack for the demo included:
| Component | Purpose |
|---|---|
| Memgraph 3.2+ | In-memory Graph database |
| uSearch | In-memory vector index library integrated into Memgraph |
| Streamlit | Python framework for building an interactive app UI quickly |
| OpenAI / GPT | Natural Language Querying for Q&A and quiz generation |
| Cursor | AI-powered coding IDE |
| LlamaIndex / LangGraph / MCP | Framework compatibility for GraphRAG pipelines |
Talking Point 2: Why Create This
Here’s why Josip chose to combine vector search with a graph database to create this app:
- To effectively connect unstructured data (like text documents) with your existing structured data (graphs) for better expressivity.
- To solve the problem of searching across large volumes of unstructured knowledge (replacing
Ctrl+F). - To enable fast prototyping using LLMs and graphs.
- To create a fun & interactive learning tool.
Talking Point 3: Building the Demo App – Step-by-Step Guide
Ingestion Step 1: Creating a Vector Index
First, a vector index is created on the nodes that will store the paragraph embeddings. This index is essential for performing efficient similarity searches.
The index is created on nodes with a specific label (representing the category of the ingested data) and targets the vector property.
CREATE VECTOR INDEX {index_name} ON :{category}(vector)
WITH CONFIG {{
"dimension": {dimension},
"capacity": {capacity},
"metric": "cos"
}}
Ingestion Step 2: Creating Paragraph Nodes
Each paragraph from the unstructured text is transformed into a node in the graph. These nodes are assigned labels (both the category label and a general :All label for broader queries).
They also store properties like the original content, a unique ID, page information, index within the document, and the generated vector embedding.
CREATE (p:{category}:All {{
id: $id,
content: $content,
page: $page,
index: $idx,
vector: $vector,
lang_prefix: $lang_prefix
}})
Ingestion Step 3: Linking Paragraphs Together
To maintain the original document structure and enable sequential traversal, relationships are created between consecutive paragraph nodes.
MATCH (p1:{category} {{id: $id1}}), (p2:{category} {{id: $id2}})
CREATE (p1)-[:NEXT]->(p2)
Performing Vector Search for Q&A
Once data is ingested, users can enter natural language questions. For example:
Who founded Rome?
Memgraph then performs a vector search using the question's embedding.
CALL vector_search.search("{index_name}", 20, $query_vector)
YIELD node, similarity
RETURN node.content AS content, similarity
It returns the top 20 most relevant paragraphs. These were sent to the LLM with a strict prompt to generate an answer using only those sources.
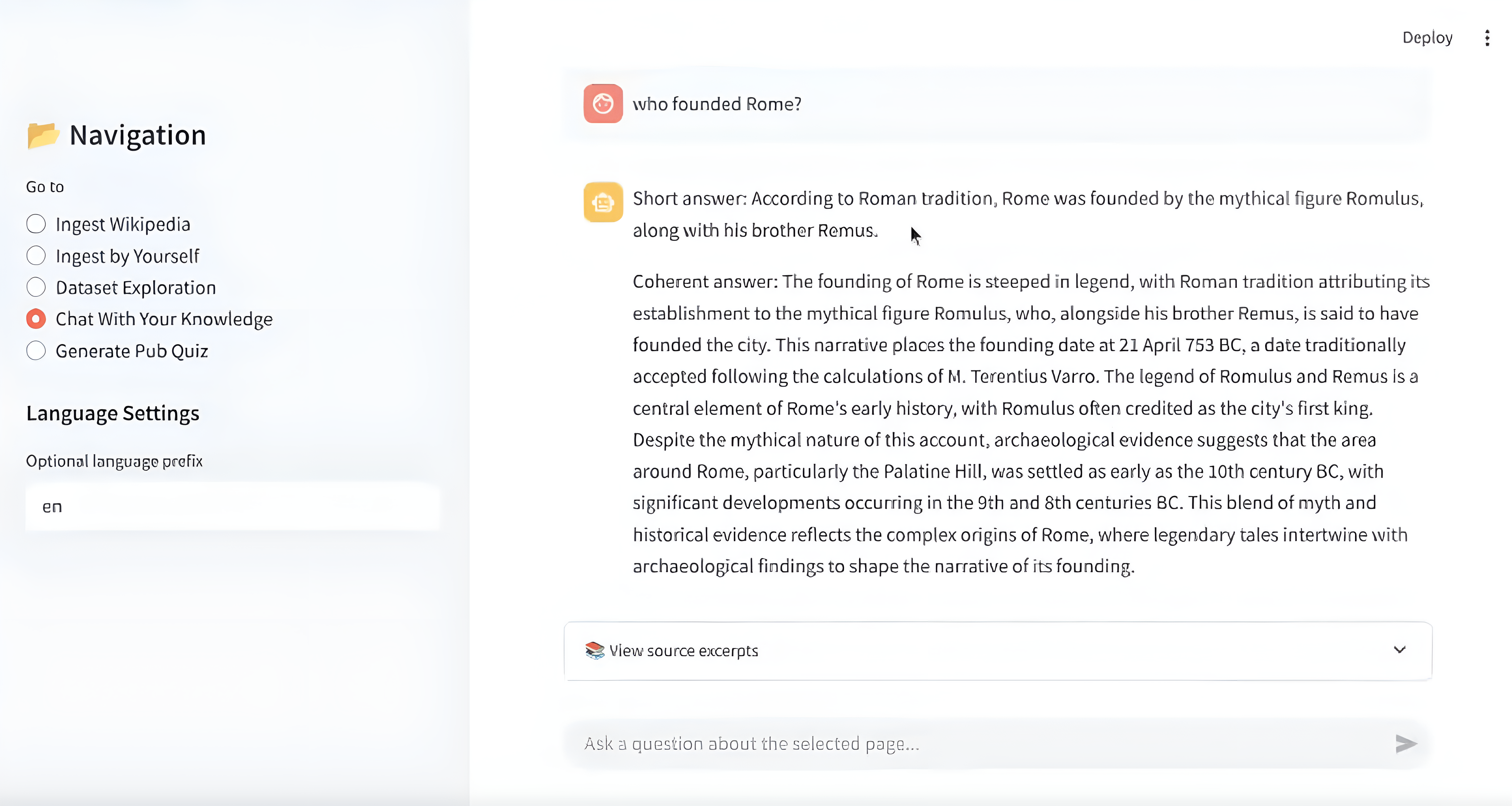
This ensures the model doesn't hallucinate and only uses grounded data.
Auto-Generating Quiz Questions
For generating pub quizzes, the application traverses the graph structure to get a sequence of connected paragraphs.
UNWIND $ids AS id
MATCH path=(p:{category} {{id: id}})-[:NEXT *bfs 0..5]->(next)
WITH project(path) as graph
UNWIND graph.nodes as nodes
RETURN nodes.content AS content
ORDER BY nodes.index ASC
Using a breadth-first search (BFS) from a paragraph node, Memgraph retrieved a chunk of content, which was passed to the LLM to generate:
- Questions
- Difficulty levels
- Correct answers
- Explanations
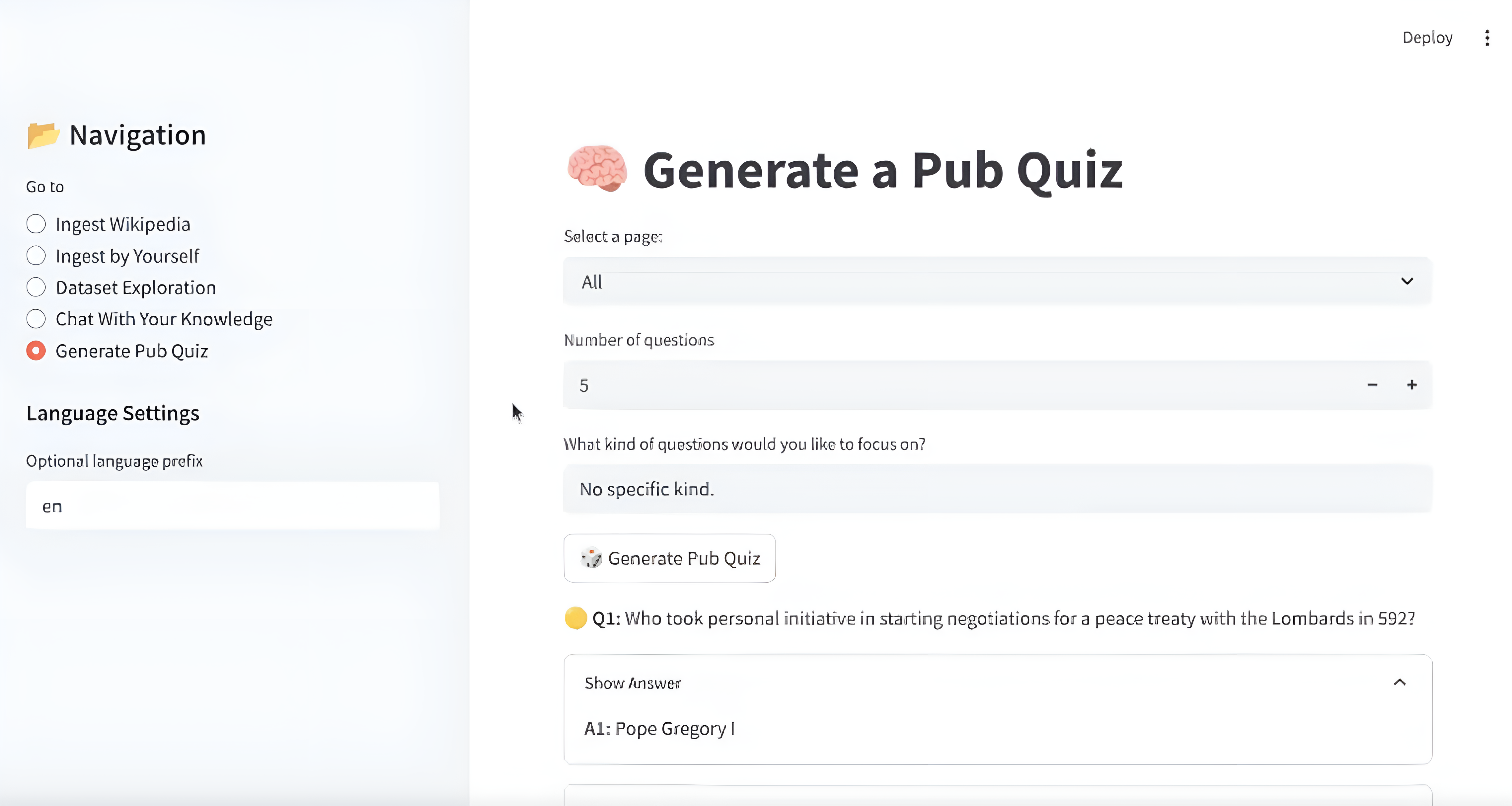
And there you have it, a complete pub-style quiz built from structured Wikipedia data!
Talking Point 4: Why Memgraph for GraphRAG
Memgraph offers several compelling reasons for choosing it as the platform for your GraphRAG applications:
- Ensure higher RAG Accuracy
- Productivity boast
- Hierarchical Composition of Knowledge
- In-memory vector search
- Flexible framework compatibility
- Reduced complexity with unified platform
Talking Point 5: What’s Coming Next
These are future improvements planned in Memgraph’s RAG roadmap:
- Role-based access controls
- Multi-tenancy
- Improved RAG Framework
- Cypher generation improvements
- Semantic validations
- Long-term memory
- Ingestion from multiple data sources
Q&A
Weʼve compiled the questions and answers from the community call Q&A session.
Note that weʼve paraphrased them slightly for brevity. For complete details, watch the entire video.
- Is vector search in Memgraph persistent and production-ready?
- Yes! Since version 3.2, Memgraph’s vector search is fully supported out-of-the-box. No experimental flags needed. Just use
CREATE VECTOR INDEX, and it persists across container restarts and production environments.
- Yes! Since version 3.2, Memgraph’s vector search is fully supported out-of-the-box. No experimental flags needed. Just use
- What's the benefit of using GraphRAG with Memgraph versus a vector DB like ChromaDB?
- The trade-off is having two separate solutions vs. one unified system. Memgraph bundles both graph + vector search. You can still use external vector DBs (e.g., Pinecone, Chroma) with Memgraph for graph-only functions. But Memgraph gives you end-to-end structure + semantics + performance in one place. Especially useful when your data is highly connected (e.g., supply chain, fraud, data lineage).
- How does Memgraph GraphRAG compare to non-graph approaches in performance?
- This use case (Q&A on a single Wikipedia page) can be easily done using non-graph approaches as well. But when you complex proprietary data spanning multiple sources or needing multi-hop logic, graph databases are better suited. Graphs eliminate joins, reduce query complexity, and are ideal for recursive or hierarchical reasoning. That’s where Memgraph excels.
- Can I build similar applications with PDFs, images, or plain text?
- Currently, ingestion is done via Wikipedia API, but the architecture supports expansion to other formats. Future roadmap includes ingestion from PDFs, text files, and even images.
Further Reading
- Docs: Vector Search
- GitHub Repo: USearch
- Docs: Memgraph in GraphRAG Use Cases
- Blog: Showcase Building a Movie Similarity Search Engine with Vector Search in Memgraph
- Blog: Decoding Vector Search: The Secret Sauce Behind Smarter Data Retrieval
- Blog: Simplify Data Retrieval with Memgraph’s Vector Search
- Webinar: Talking to Your Graph Database with LLMs Using GraphChat
- Blog: GraphChat: How to Ask Questions and Talk to the Data in Your Graph DB?