How to Optimize Performance with Memgraph Query Plans
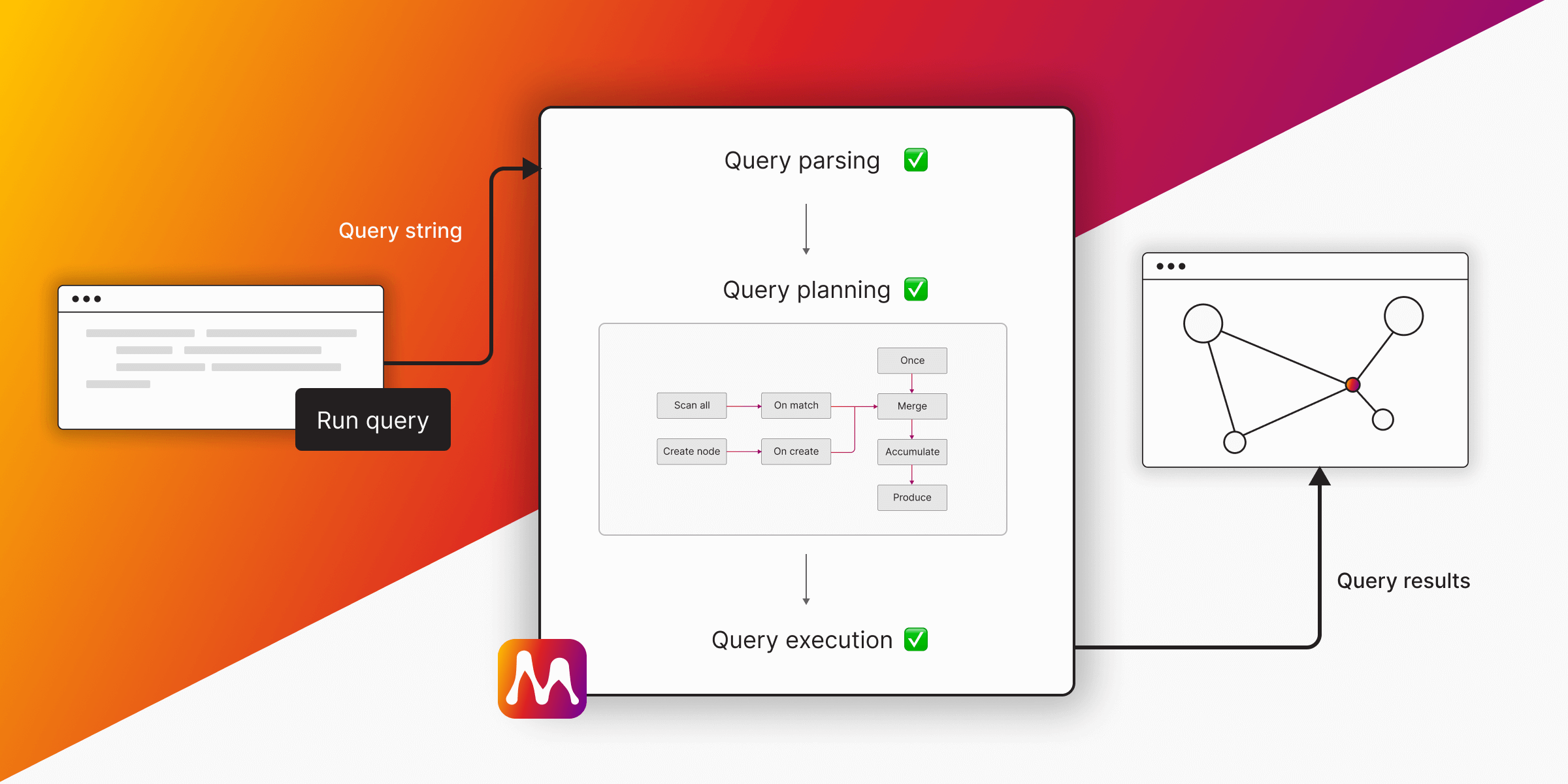
Understanding how the Memgraph query engine processes Cypher queries is important for optimizing query performance. This post explores the stages of query processing, the structure and operators of query plans, and the impact of query plan caching and configuration on performance.
What is Cypher Query?
Cypher is a declarative query language that specifies what data to retrieve without detailing the steps to retrieve it. The Memgraph query engine takes a Cypher query and determines the optimal execution plan.
To achieve optimal execution time, it's crucial to have a well-structured query plan composed of various operators. If a query plan has already been generated for a specific query, caching that plan can significantly speed up execution. Beyond the default query planner behavior, you can tweak configurations to squeeze out the best performance.
Memgraph Query Engine Overview
The Memgraph query engine handles every Cypher query by converting a textual statement into a query plan. This process involves several steps:
- Query Run Initiated - Memgraph receives the query as a raw string.
- Query Parsing - The query parser runs lexical and syntactic analysis.
- Query Planning - The query planner constructs and caches an optimal execution plan.
- Query Execution - The storage engine executes the query plan.
- Query Results Returned - Results are returned to the client.
Query Parsing and Execution
Let's give an example of how the query engine transforms a raw string into an actual result from the database.
Here is the query:
MATCH (n:Node {id:1})
RETURN n;The query is sent to the database, and the first step it goes through is the query parser. The query parser will run the lexical and syntactic analysis of the query. That involves checking statements and query string structures, ensuring they are appropriately written and constructed from the available vocabulary.
Here is an example of a query that would not pass lexical analysis:
MATC (n:Node {id:1})
RETURN n; The parser returns an error because "MATCH" is misspelled:
line 1:1 mismatched input 'MATC' expecting {ADD, ANALYZE, CALL, CHECK, CLEAR,...If the lexical and syntactic analysis passes, the query engine checks for a cached query plan for the same query.
- Found in cache - If a query plan is found, it’s reused for execution, speeding things up.
- Not found in cache - If no plan is cached, the query is stripped of literals, replaced with normalized values for caching, and a new query plan is generated.
Query Planner
Query planner aims to find the optimal plan that defines steps for the most cost-effective query execution. Memgraph query engine can do many optimizations in the background but also make mistakes. Hence, it is essential to get familiar with the structure of a query plan to understand query execution and identify potential performance bottlenecks.
Query Plan Structure
A query plan is a tree-like data structure outlining a series of operations on the database. Each node, known as an operator, performs a specific task. Operators execute iteratively, with data flowing through the pipeline from one operator to the next.
You can get a query plan by prefixing any query with EXPLAIN or PROFILE clauses. This is a basic example:
EXPLAIN MATCH (n)
RETURN n;+----------------+
| QUERY PLAN |
+----------------+
| * Produce {n} |
| * ScanAll (n) |
| * Once |
+----------------+The EXPLAIN clause shows the query plan, listing each operator starting with an asterisk (*) followed by its name. The query executes iteratively, with data flowing from the bottom-most operator (start of the pipeline) to the top-most operator (end of the pipeline).
In the given example, the query plan consists of three operators:
Once- The identity operator, always at the start, does nothing.ScanAll- Iteratively produces all nodes in the graph.Produce- Takes data from another operator and returns it as the query's result set.
Here, ScanAll produces all nodes and passes them to Produce, which then returns the nodes to the user. This forms a simple query data pipeline.
A more complex query plan would look like this:
EXPLAIN MERGE (p:Person {name: 'Angela'})
ON MATCH SET p.found = TRUE
ON CREATE SET p.notFound = TRUE
RETURN p.name, p.notFound, p.found;+------------------------------------------+
| QUERY PLAN |
+------------------------------------------+
| * Produce {p.name, p.notFound, p.found} |
| * Accumulate |
| * Merge |
| |\ On Match |
| | * SetProperty |
| | * Filter (p :Person), {p.name} |
| | * ScanAll (p) |
| | * Once |
| |\ On Create |
| | * SetProperty |
| | * CreateNode |
| | * Once |
| * Once |
+------------------------------------------+For more details, check out our query plan structure on our Memgraph docs.
Query Plan Operators
By combining different operators, the query engine creates various query plans for executing queries and producing results. Each operator performs a specific function. Common operators include:
Accumulate- Accumulates input data.Filter- Filters input based on conditions.ScanAll- Produces all nodes in the database.Produce- Produces results for the query's result set.Once- Initiates the operator chain.
For a full list of possible operators, refer to our documentation. Each operator serves a distinct purpose and should be considered individually. The same query can generate different query plans due to indexing on specific labels and properties.
Example:
EXPLAIN MATCH (n:Transfer {year:1992})
RETURN n;This will yield the following query plan:
+-------------------------------------+
| QUERY PLAN |
+-------------------------------------+
| " * Produce {n}" |
| " * Filter (n :Transfer), {n.year}" |
| " * ScanAll (n)" |
| " * Once" |
+-------------------------------------+Indexing this query will improve performance, as the query will use the index.
CREATE INDEX ON :Transfer(year);
EXPLAIN MATCH (n:Transfer {year:1992}) RETURN n;
Generated query plan:
+-------------------------------------------------------+
| QUERY PLAN |
+-------------------------------------------------------+
| * Produce {n} |
| * ScanAllByLabelPropertyValue (n :Transfer {year}) |
| * Once |
+-------------------------------------------------------+For more information, check out the optimization details in our documentation.
Query Plan Caching
Query plan caching speeds up execution by reusing previously generated plans, eliminating the need for re-planning.
Repeated CREATE queries reuse the same query plan:
CREATE (n:Node {id: 123});
CREATE (n:Node {id: 154});
CREATE (n:Node {id: 322});To validate query plan caching, check the query execution time summary. Look at the time spent on query planning in the results.
//First run of the query
Additional execution time info:
Query COST estimate: 0
Query PARSING time: 0.00170783 sec
Query PLAN EXECUTION time: 9.8768e-05 sec
Query PLANNING time: 0.001479502 sec
//Second run of the query
Additional execution time info:
Query COST estimate: 0
Query PARSING time: 8.0453e-05 sec
Query PLAN EXECUTION time: 7.1126e-05 sec
Query PLANNING time: 7.6255e-05 sec
You'll notice that the planning time is significantly smaller on the second iteration compared to the initial run of the query.
Query Engine Configuration
The behavior of the query plan can be influenced by the database configuration parameters set at startup.
--cartesian-product-enabled=true
This parameter enables or disables the Cartesian product operator. The Cartesian product operator is used to apply the Cartesian product to the input it receives. This means if you match two nodes, the Cartesian product operator will produce all possible combinations of the nodes. This is a costly operation, and it should be used with caution. The default value is set to true.
Here is an example of the query plan that will trigger the query planner to use the Cartesian operator:
MATCH (n), (m)
RETURN n, m;Suppose there are three nodes in the database labeled Person with the property name having values: John, Stan, and Peter. The above query matches all pairs of nodes and returns them. The Cartesian product operator produces all possible combinations of n and m nodes.
Here is the result:
+---------------------------+---------------------------+
| n | m |
+---------------------------+---------------------------+
| (:Person {name: "John"}) | (:Person {name: "John"}) |
| (:Person {name: "John"}) | (:Person {name: "Stan"}) |
| (:Person {name: "John"}) | (:Person {name: "Peter"}) |
| (:Person {name: "Stan"}) | (:Person {name: "John"}) |
| (:Person {name: "Stan"}) | (:Person {name: "Stan"}) |
| (:Person {name: "Stan"}) | (:Person {name: "Peter"}) |
| (:Person {name: "Peter"}) | (:Person {name: "John"}) |
| (:Person {name: "Peter"}) | (:Person {name: "Stan"}) |
| (:Person {name: "Peter"}) | (:Person {name: "Peter"}) |
+---------------------------+---------------------------+Here is the query plan obtained with the EXPLAIN query:
+------------------------+
| QUERY PLAN |
+------------------------+
| " * Produce {n, m}" |
| " * Cartesian {m : n}" |
| " |\\ " |
| " | * ScanAll (n)" |
| " | * Once" |
| " * ScanAll (m)" |
| " * Once" |
+------------------------+Only the left branch from the Cartesian product will be cached. If the left branch produces too many records, the Cartesian product can cause memory overhead. To avoid this, you can set --cartesian-product-enabled to false.
For the rest of the configuration flags, refer to the query plan docs.
Conclusion
Understanding the Memgraph query planner and its operators can significantly improve query performance. By using query plan caching, indexing, and proper configuration, you can optimize the execution of Cypher queries in Memgraph.
For more details and best practices, refer to the Memgraph documentation.