
How to Analyze Commits in a GitHub Social Network in Real-Time?
GitHub provides internet hosting for software development and version control using Git. But you could also say that GitHub is a kind of social network as well. Users can follow other users based on their interests and contributions. And as it usually goes with social networks, there are a lot of insights to uncover, especially if you receive changes in the data as they come. One of the reasons we created Awesome Data Stream, a data streams website, is to make things dynamic and real-time. There, you can find all the details about the GitHub dataset used in this blog post.
Data coming from these streams can be run through Memgraph, which you can set up using the new Memgraph Cloud or by running a local instance of Memgraph DB. The latest version of Memgraph Lab, an application you can use to query and visualize data, has a new feature that guides you through the process of connecting to streams. All the information necessary to connect to a stream of GitHub commits from the NetworkX repository is available on the Awesome Data Stream website. If these tools spark your interest, feel free to browse through the Cloud documentation or check out the guide on how to connect to streams using Memgraph Lab. If you are a visual learner, both of these processes are also described in the video tutorial.
This blog will explore the GitHub streaming dataset by using the PageRank algorithm to find out the most influential user in the network and a community detection algorithm that will assign each node to a community. When the amount of data is constantly rising and the data set is perpetually changing, as it does with streaming data, these algorithms require dynamic implementations that are specifically designed for real-time data analysis.
Checking the setup
Assuming you are successfully running your Memgraph instance, you’ve connected to it with Memgraph Lab or mgconsole, and the database is ingesting the GitHub data stream, run the following Cypher query to be sure everything is connected and running smoothly (in Memgraph Lab, switch to Query Execution):
MATCH (c:Commit)-[r:CREATED_BY]-(u:User)
RETURN c, r, u LIMIT 100;
If everything is set up correctly, you should see 100 commits, and in Lab you can switch between graph results and data results returned by the query.
Detecting influential users on GitHub with PageRank
PageRank is an algorithm used by Google Search to rank web pages in their search engine results, and in this dataset, it will be used to find the most influential user in the GitHub network. The good thing is that PageRank is a part of MAGE, and if you are using Memgraph Cloud or Memgraph Platform, MAGE is already locked and loaded, and you don’t have to read or write a single line of code.
To invoke it, run the following query:
CALL pagerank.get()
YIELD node, rank;
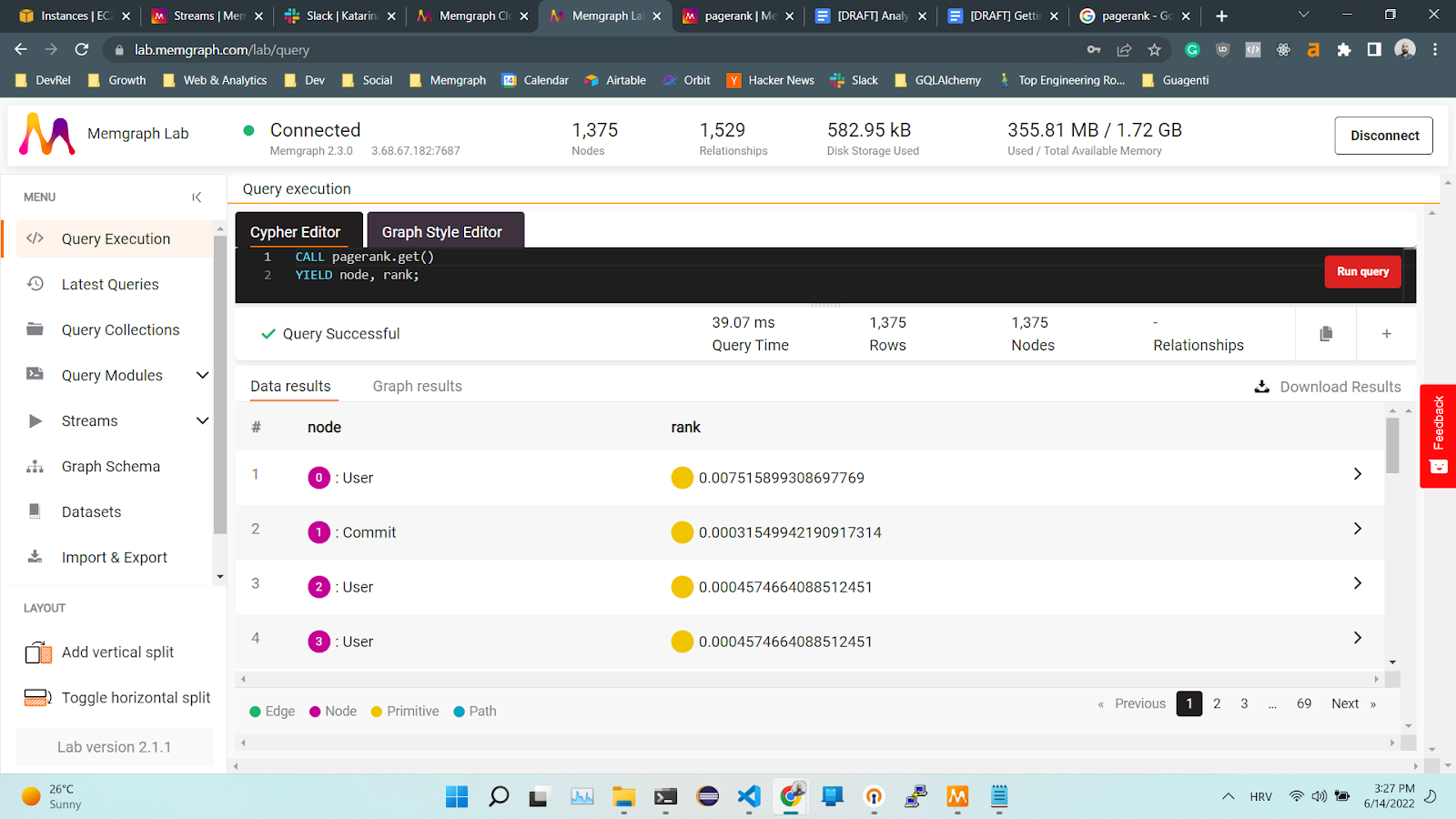
Written like this, the algorithm returns the user with the highest PageRank score, but it also includes Commit nodes to return the results. To find out the influence of users, filter out the commits using the following query:
CALL pagerank.get()
YIELD node, rank
WITH node, rank
WHERE node:User
RETURN node, rank;
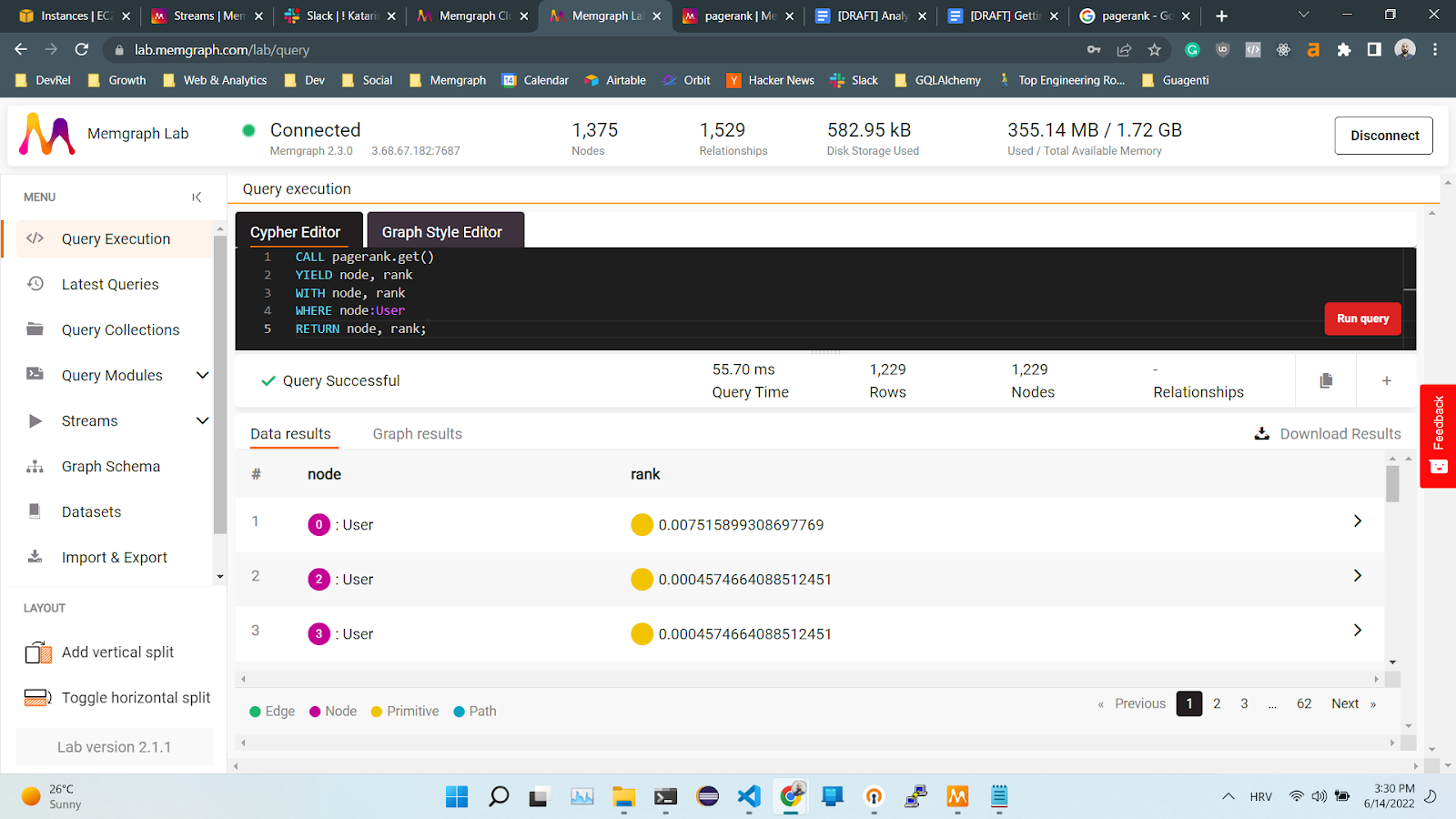
This query looks too good to be true, and you are right. There is a slight issue with this approach. If you want to analyze the data in real-time, which means the moment the new users and commits are added to the network, running the PageRank algorithm will become computationally too expensive. It is possible to create a trigger that would run the algorithm each time a new node is added to the network, but after some time, the graph will become too large for the algorithm to handle it in real-time.
The solution is to use a dynamic version of the PageRank algorithm, which doesn’t recompute the rank for each node, but only for those affected by the network changes. The MAGE graph algorithm library contains an incremental PageRank algorithm as well, in the pagerank_online module.
First, set up the algorithm:
CALL pagerank_online.set(100, 0.2) YIELD *
Now, create a trigger that will execute the algorithm each time a node and/or relationship is created or deleted:
CREATE TRIGGER pagerank_trigger
BEFORE COMMIT
EXECUTE CALL pagerank_online.update(createdVertices, createdEdges, deletedVertices, deletedEdges)
YIELD node, rank
SET node.rank = rank;
Once new data starts coming into the database, you can traverse the graph and find the nodes with the highest rank:
MATCH (n:User)
RETURN n.username
ORDER BY n.rank DESC;
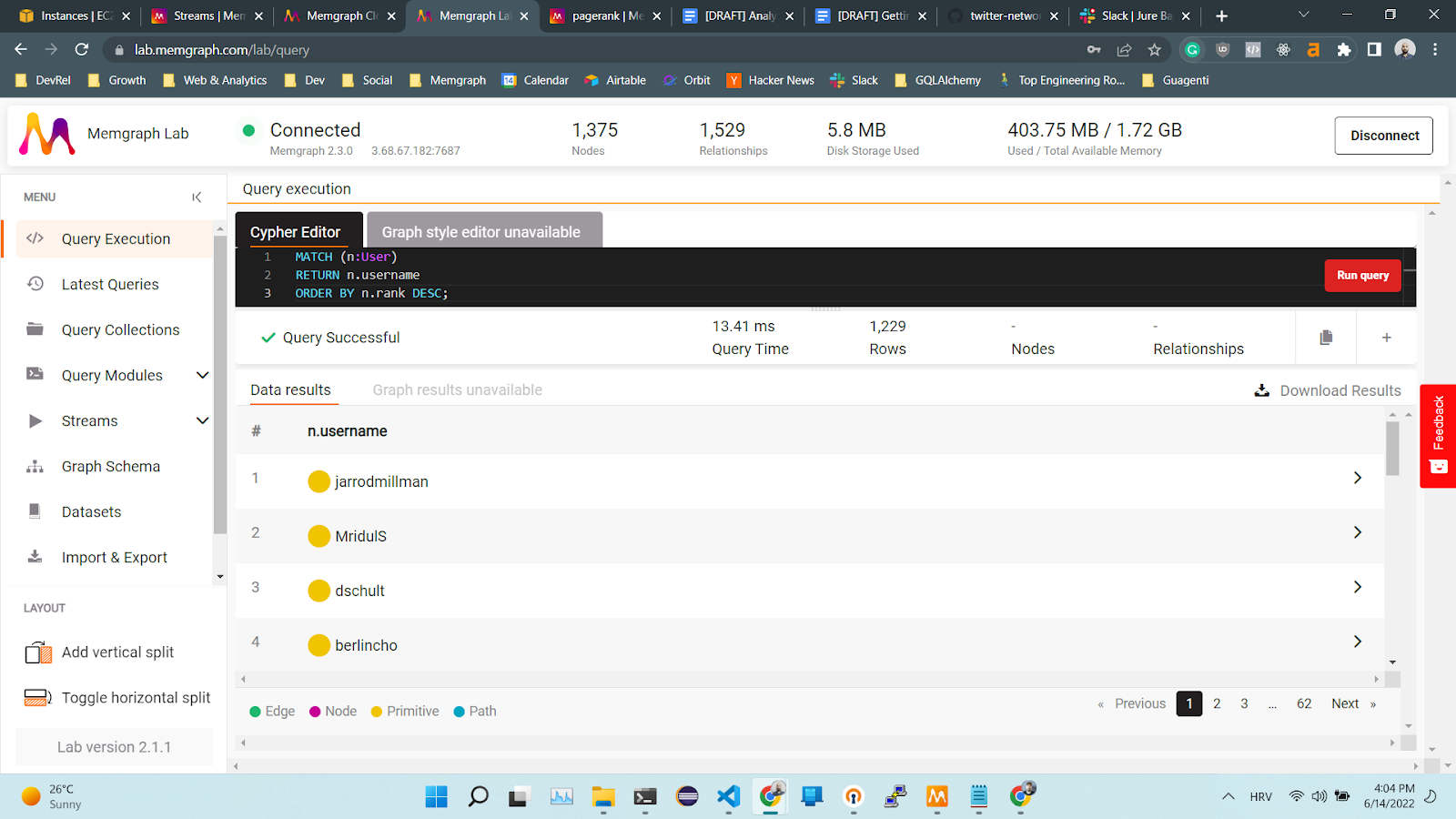
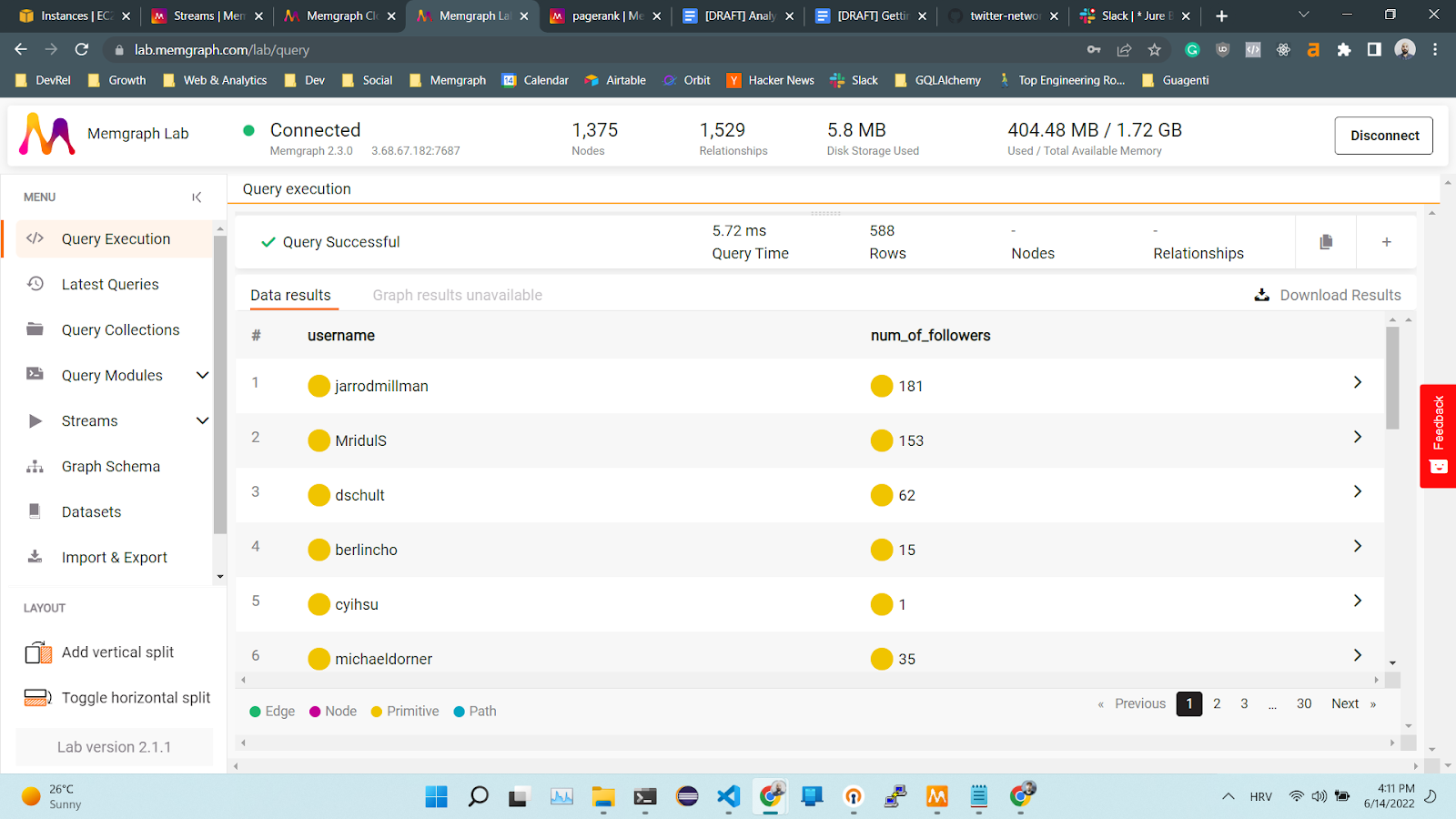
To make sure that the algorithm is behaving as expected, check how many followers these users have:
MATCH (n:User)<-[:FOLLOWS]-(f)
WITH n, count(f) as num_of_followers
RETURN n.username as username, num_of_followers
ORDER BY n.rank DESC;
Detecting communities on GitHub
As people gather in social circles in real life, groups of users gather in communities. Within graphs, nodes in the same communities are more strongly connected (have more relationships) than the nodes in different communities. Therefore, the community detection algorithm assigns each node to a community. But the same issue will occur when using a community detection algorithm on a data stream as when using the PageRank algorithm. Rerunning the algorithm on the whole dataset takes up too much time.
If you need to run it only a few times or in batches, use the following query:
CALL community_detection.get()
YIELD node, community_id
RETURN node, community_id;
But, if you want to set up the dynamic version of the algorithm, you first need to execute the following query:
CALL community_detection_online.set(False, False, 0.7, 4.0, 0.1, 'weight', 1.0, 100, 5) YIELD *;
Now you can create a trigger that will determine to what community a node belongs to and update the node properties by adding that community as a cluster property:
CREATE TRIGGER labelrankt_trigger
BEFORE COMMIT
EXECUTE CALL community_detection_online.update(createdVertices, createdEdges, updatedVertices, updatedEdges, deletedVertices, deletedEdges)
YIELD node, community_id
SET node.cluster=community_id;
Each new node in the network will have a cluster assigned to it.
Conclusion
If you have a Kafka, Pulsar or Redpanda data stream, using Memgraph as a stream processing pipeline for analyzing data with graph algorithms is intuitive and straightforward. Algorithms such as PageRank and community detection can help you gain valuable insights that you can base your strategic decisions on.
If you want to analyze other datasets, feel free to explore Awesome Data Stream further. For example, check out another tutorial on how to get real-time book recommendations based on the Amazon book dataset. If you do run into any issues or you would like to discuss something related to this article, drop us a message on our Discord server.