
How to Query Your Database with ChatGPT: Memgraph Edition
Getting started with graph databases can be scary, especially if you are unfamiliar with the domain and Cypher query language. However, with the help of ChatGPT, a ground-breaking natural language processing (NLP) technology, the learning process can become more intuitive and user-friendly.
This blog post is a simple and fun demonstration of how you can create a graph data model and learn how to use ChatGPT to generate Cypher queries by describing what you want to do in natural language and then copying those queries into Memgraph.
If you are new to graph databases and want to learn how to write queries in Cypher, a structured query language for graphs, this blog post is for you. ChatGPT will teach you the meaning of Cypher queries and how to run them in Memgraph to create, visualize and query your database. And hopefully, you will have some fun along the way! 😀
Generate a graph data model with ChatGPT
The first thing to do is decide what kind of data to store and explore. The most straightforward examples to learn about graphs involve social networks, movies, countries, etc. This example will deal with a specific TV show dataset - Money Heist. To start off, ask ChatGPT whether it knows about that TV show:

The good thing is that Money Heist ended in 2021, and the last update of ChatGPT’s knowledge base happened in September 2021. That makes exploring newer data a bit tricky, but luckily, ChatGPT accepts the facts you provide and considers them as your conversation evolves.
Before data is imported into a graph database, the graph data model for the dataset should be defined. Here is a suggestion from ChatGPT:

The suggestion above seems reasonable but may be too complicated for a simple database. The next thing to do is ask ChatGPT to provide a smaller graph model, including only Character, Episode, and Season nodes, along with APPEARED_IN and CONTAINS relationship.

Great! However, the actual data is needed to create such a dataset in Memgraph. Of course, there is always an option to search for information online and gather the dataset, but ChatGPT should also have that knowledge. Ask ChatGPT about the season count, episode count of every season, and main characters who appeared in those seasons, that is, episodes. It would be smart to fact-check that since the information is not necessarily correct. Still, for this example, accuracy is less important than the process of creating a graph database in Memgraph and letting ChatGPT do that for us.

As mentioned, the information about characters and episodes they appeared in is also crucial for the created graph database model. This is how to ask ChatGPT about that:

The information is incorrect since season 1 has only nine episodes, and there are episode numbers bigger than nine here, but correctness is not necessary in this example. Also, this proves that you should always fact-check anything ChatGPT tells you 😂 Do the same for every season to get all the information required. After all that is done, the data about seasons, episodes, and characters is collected. The next step is to generate Cypher queries to create a dataset in a graph database - Memgraph.
Import the data into Memgraph
Memgraph is an open-source in-memory graph database that supports strongly-consistent ACID transactions and uses the standardized Cypher query language for structuring, manipulating, and exploring data. Please refer to our documentation to learn how to get started with Memgraph. Ideally, install and run the Memgraph platform, which includes the Memgraph database, MAGE (an open-source repository that contains graph algorithms and modules), and the Memgraph Lab (visual user interface). All of the database queries below will be run via Memgraph Lab.
First, create all seasons, which will be represented as nodes with property numbers. Ask ChatGPT how to do that:
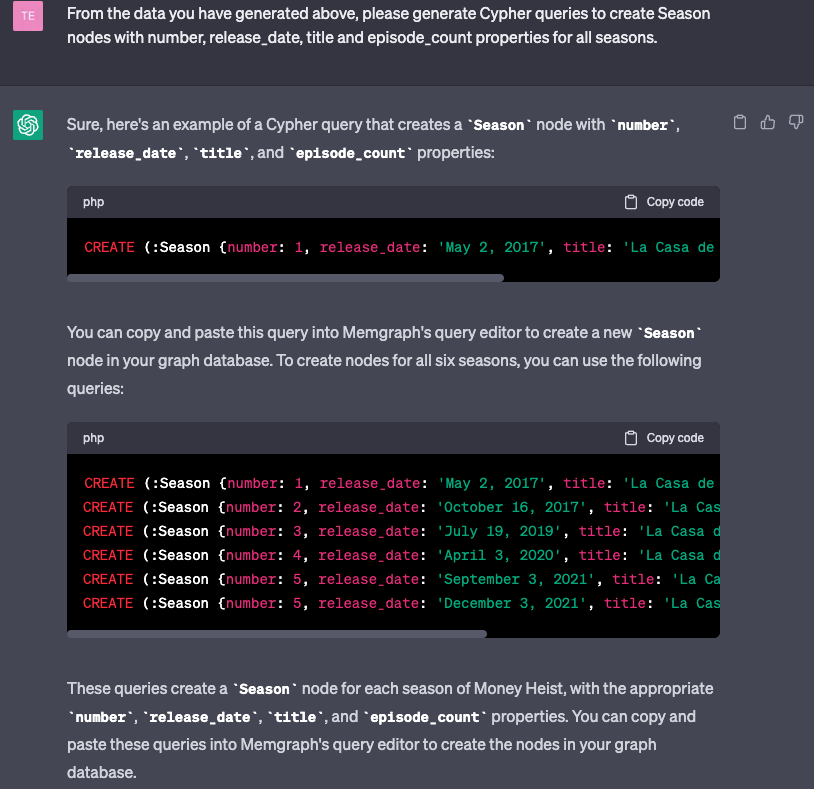
Copy the database queries above, paste them to Memgraph Lab, and ideally, merge the two parts of season 5.
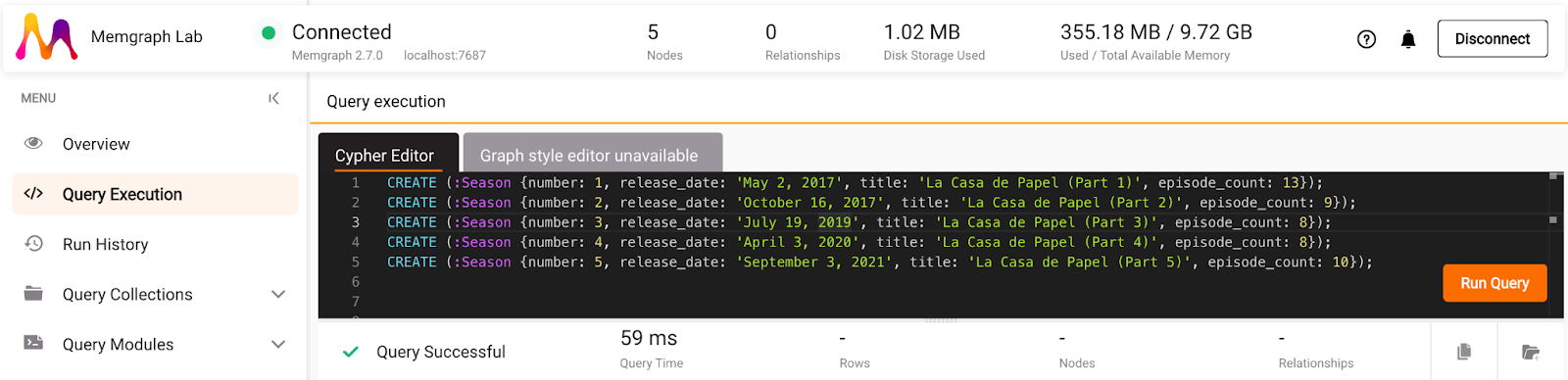
Then ask ChatGPT to generate Cypher queries for the creation of Episode nodes:
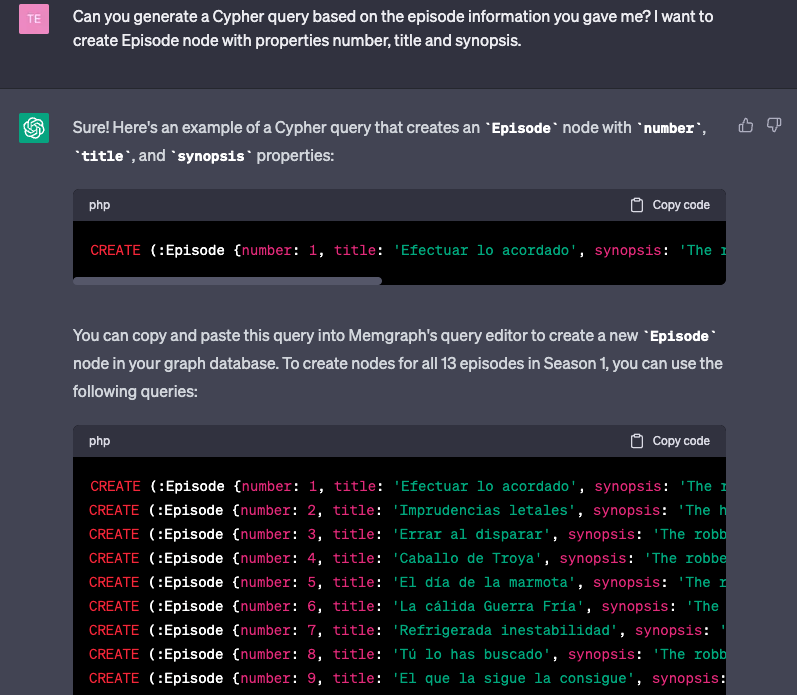
ChatGPT got confused a bit and thought that season 1 has 13 episodes, whereas it's 9 episodes, in reality. Hence, run the given database queries in Memgraph Lab:
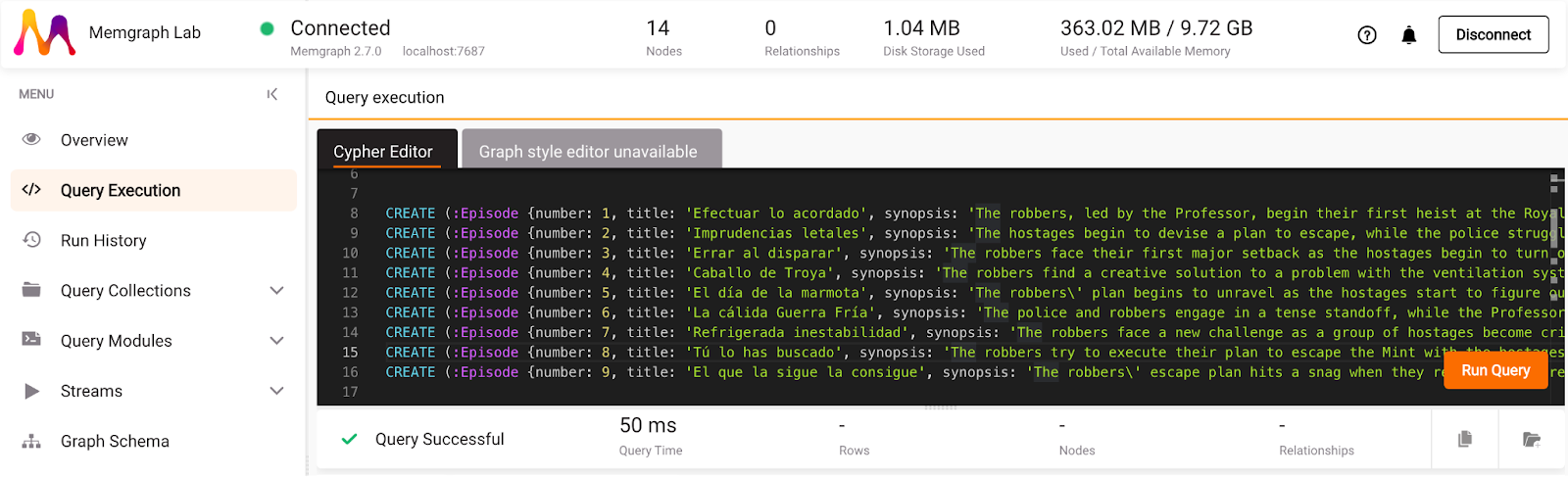
Now, connect the Episode nodes to the Season nodes with the property number of value 1. Since ChatGPT is currently aware of 9 existing episodes, this is the query it provided:
MATCH (s:Season {number: 1}), (e:Episode)
WHERE e.number <= 9
CREATE (s)-[:CONTAINS]->(e);Next, create Character nodes that are connected to Episode nodes with the relationship of type APPEARED_IN. Ask ChatGPT something along the lines: How to create a node Character with the property name and connect it to all of the episodes they appeared in season 1 with the relationship of type APPEARED_IN?
The answer might be incorrect initially, but continue asking additional questions to ChatGPT to provide you with the best answer. In the end, ChatGPT provided these queries to run in Memgraph Lab:
Season 1, with all of its episodes, and the main characters who appeared in those episodes, are inside the databases. There should be a total of 25 nodes and 100 relationships. To see if the graph is correctly modeled, head over to the Graph Schema tab and click on Generate Graph Schema.
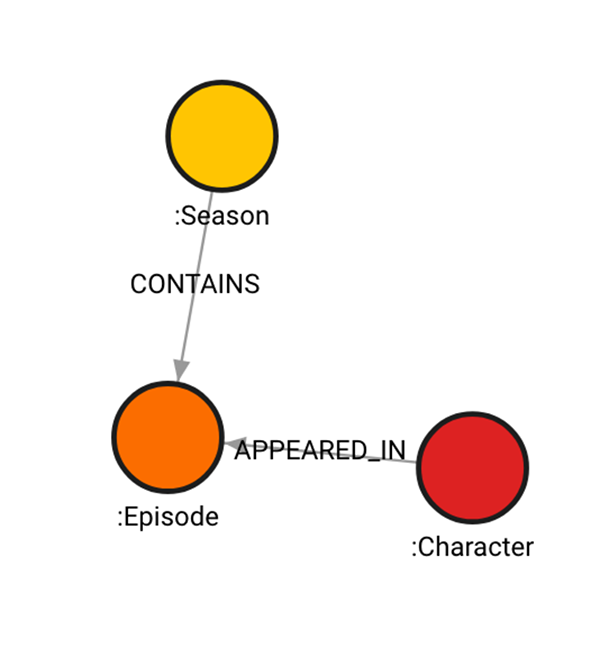
Everything in the database looks the same way ChatGPT described in the beginning. To make querying more interesting, ask ChatGPT to provide similar queries, with different query parameters, for the rest of the seasons. The difference is that it will first have to match a season to attach episodes to it since at least one season already exists in the database. That means that the query to create episodes of season 2, along with the relationship of type CONTAINS connecting them, looks like this:
MATCH (s:Season {number: 2})
MERGE (s)-[:CONTAINS]->(:Episode {number: 1, title: "We're Back", synopsis: "The Professor, while in mourning, attempts to make a daring and dangerous escape."})
MERGE (s)-[:CONTAINS]->(:Episode {number: 2, title: "Aikido", synopsis: "The Professor recruits Martín to put his brother's plan into action and target the Bank of Spain."})
MERGE (s)-[:CONTAINS]->(:Episode {number: 3, title: "48 Meters Underground", synopsis: "Tokyo and Nairobi's efforts go drastically awry. The Professor recalls Berlín from self-imposed exile to oversee the plan."})
MERGE (s)-[:CONTAINS]->(:Episode {number: 4, title: "Boom, Boom, Ciao", synopsis: "The Professor, Benjamin and the others attempt to free Lisbon. Rio is faced with a difficult decision."})
MERGE (s)-[:CONTAINS]->(:Episode {number: 5, title: "The Red Boxes", synopsis: "With Nairobi held hostage, Gandía negotiates with the crew. The Professor desperately seeks a new plan."})
MERGE (s)-[:CONTAINS]->(:Episode {number: 6, title: "Everything Seemed Insignificant", synopsis: "The group reels following the attack on one of their own. The Professor puts his adjusted plan in motion with the help of new recruits and Palermo."})
After everything is imported into Memgraph, there should be 66 nodes and 468 relationships Time for querying!
Query the database with ChatGPT
You can give ChatGPT the following query to generate Cypher queries and explore your data:

That is a great starting point for anyone unsure where to begin with Cypher and for those who don't know what insights can be obtained from the data. Also, for more experienced Cypher users, ChatGPT is excellent for producing ideas on what to query in a database.
Not all of the answers that ChatGPT provided were correct. Here are a few:
1. Find the top 10 most common words in all episode synopses:
MATCH (e:Episode)
WITH reduce(synopsis = "", ep in collect(e) | synopsis + ep.synopsis + " ") as text
UNWIND split(text, " ") as word
WITH toLower(word) as word, count(*) as freq
WHERE word <> "" AND NOT word IN ["a", "an", "the", "of", "in", "to", "for", "on", "and", "with", "at", "from", "by", "is", "was", "were", "that", "this", "these", "those", "it", "its", "they", "them", "we", "us", "he", "him", "she", "her"]
RETURN word, freq
ORDER BY freq DESC
LIMIT 10;
Let’s run it in Memgraph Lab and see the results:
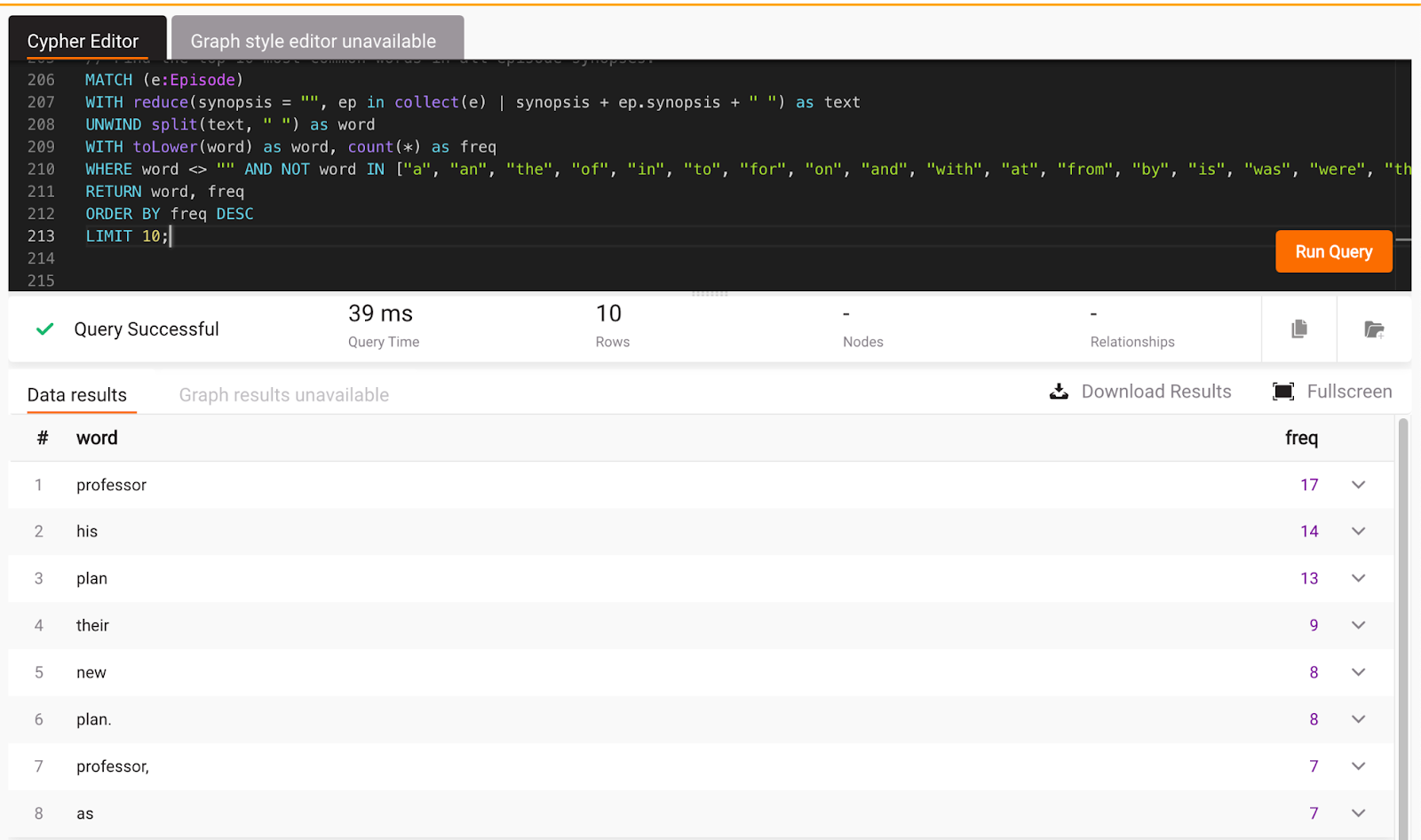
The query works, and the results make sense.
2. Find characters who appeared in the most episodes:
MATCH (c:Character)-[:APPEARED_IN]->(e:Episode)
RETURN c.name, count(*) AS episodeCount
ORDER BY episodeCount DESC
LIMIT 10;
In Memgraph Lab:
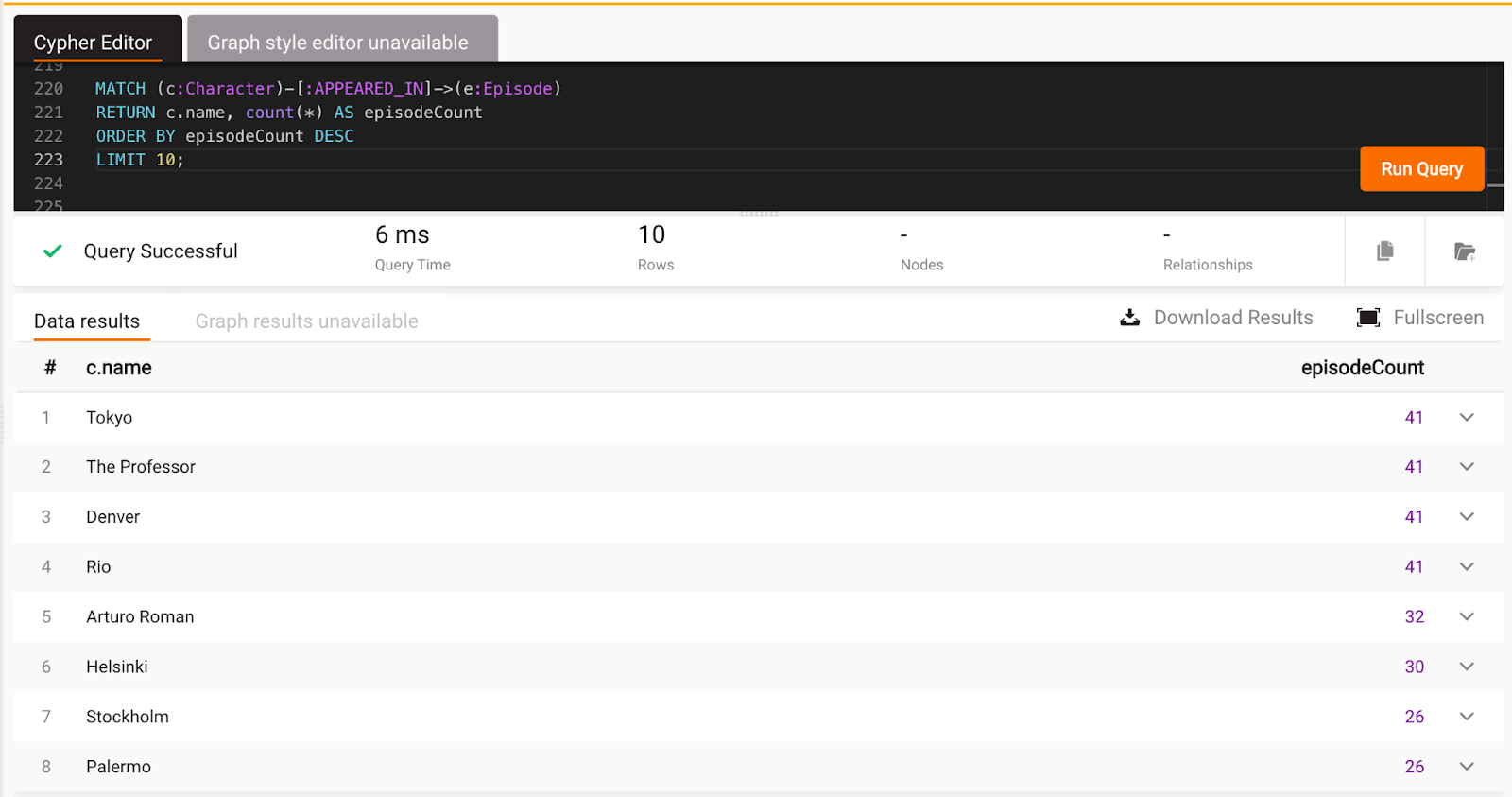
Again, the results are correct, and the query was well written.
3. Find the season with the most episodes:
MATCH (s:Season)-[:CONTAINS]->(e:Episode)
RETURN s.title, count(*) AS episodeCount
ORDER BY episodeCount DESC
LIMIT 1;
In Memgraph Lab:
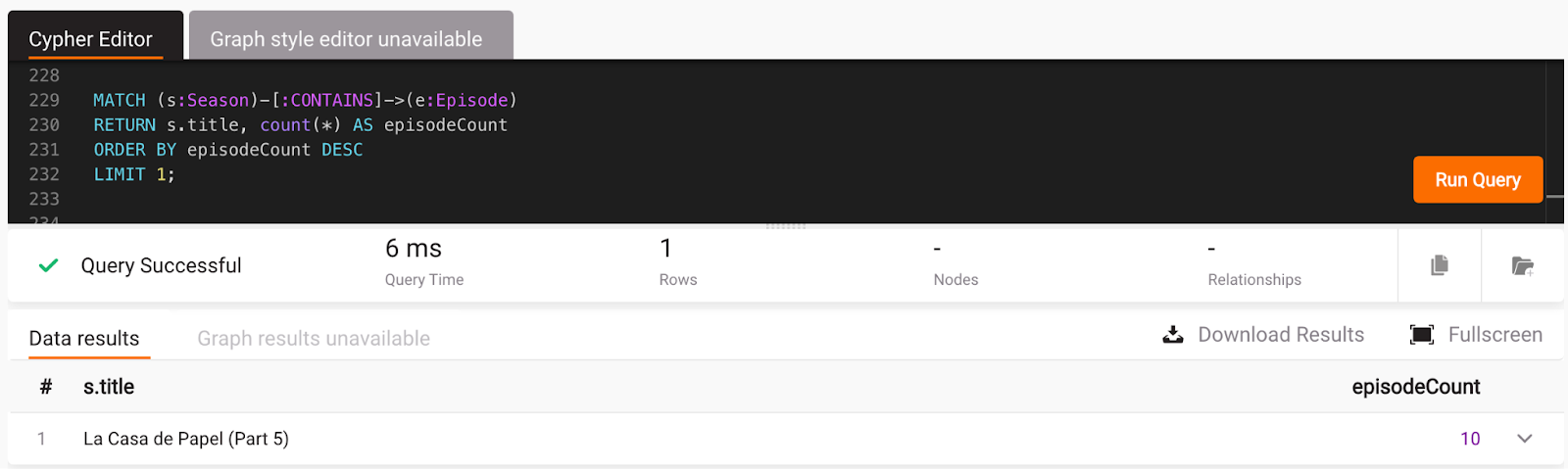
And that's correct since season 5 is the only season with 10 episodes.
4. Find the episodes with the longest synopses:
MATCH (e:Episode)
RETURN e.title, length(e.synopsis) AS synopsisLength
ORDER BY synopsisLength DESC
LIMIT 1;
This one ChatGPT did not get right for Memgraph since Memgraph has the Cypher function size for the string length. Switch that up and run the query In Memgraph Lab:
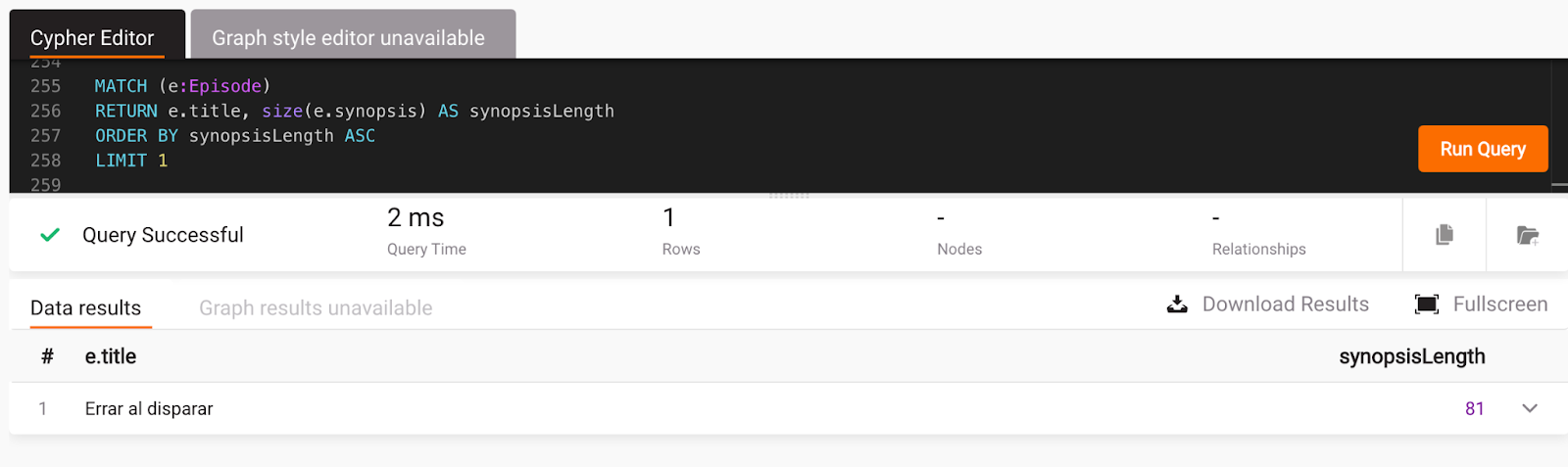
When asked to provide a query that works in Memgraph, ChatGPT generates the following:
MATCH (e:Episode)
WITH e, SIZE(SPLIT(e.synopsis, ' ')) AS wordCount
ORDER BY wordCount DESC
LIMIT 1
RETURN e.title, wordCount;
That one does work in Memgraph but it doesn’t provide the same result since it checks the number of words in synopsis as opposed to the total length of the synopsis string.
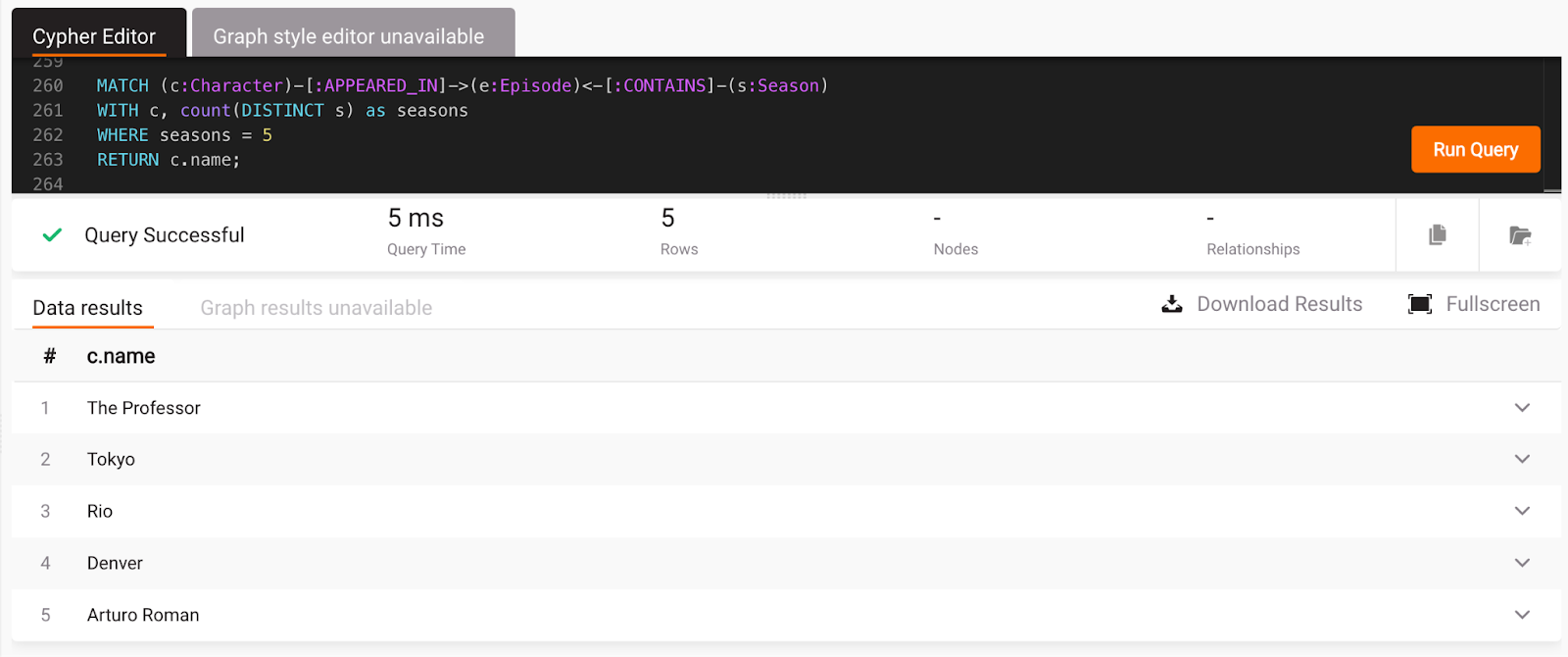
5. Find the characters who appeared in all 5 seasons:
MATCH (c:Character)-[:APPEARED_IN]->(e:Episode)-[:CONTAINS]->(s:Season)
WITH c, count(DISTINCT s) as seasons
WHERE seasons = 5
RETURN c.name;
No results will be obtained by running the above query in Memgraph Lab. That happens because the relationship between Episode and Season nodes needs to be in the correct direction. ChatGPT got confused there. But it’s an easy fix:
ChatGPT can work the other way around too. Check out this example:
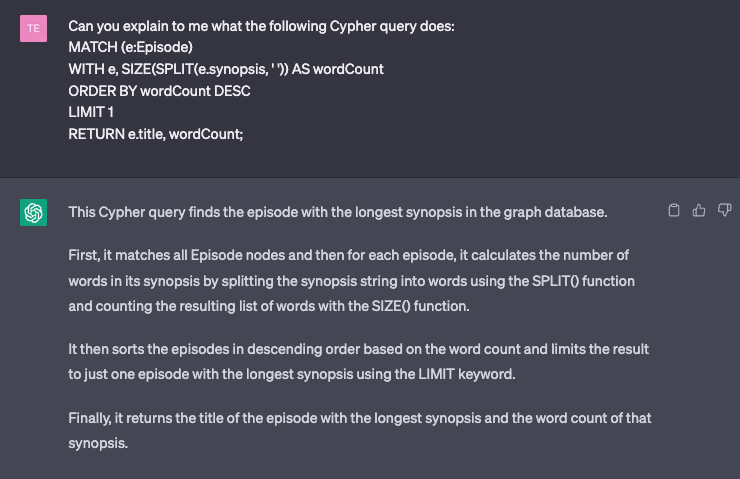
It’s excellent that ChatGPT can do the heavy lifting and figure out the patterns that Cypher has. Although Cypher is a pretty intuitive query language similar to English, it is still helpful to get such an explanation when learning the basics.
Wrap up
Regardless of one's Cypher expertise, ChatGPT proved to be a valuable asset in helping overcome the lack of knowledge in Cypher and Memgraph, allowing to dive deep into the world of Money Heist. Who knew a language model and a graph database could be such a powerful combination?
In addition to graph database modeling and querying, ChatGPT can be used for various applications, from NLP to chatbot development. With its ability to understand and generate human-like language, ChatGPT has the potential to revolutionize how we interact with machines and computers.
But be careful since ChatGPT is not always accurate! It keeps things interesting though since it may sometimes mistake Nairobi for Rio or suggest that the Professor's real name is Mr. Money Heist.
If you want to play with the dataset, here is the cypherl file and the query collection which you can import to Memgraph via Memgraph Lab.