
The Benefits of Using a Graph Database Instead of SQL
Graph databases provide a much faster and more intuitive way to model and query your data compared to traditional relational databases. In a previous article, we discussed the main differences between a graph database and a relational database, their strengths and weaknesses and what database types are best suited for certain kind of use-cases.
Choosing the right tool for the job is critical for speeding up development, ensuring flexibility, and avoiding operational complexity as your application evolves. In this tutorial, you will go through the process of building a simple customer order management application to learn how a graph approach compares to an SQL one in terms of data modeling, querying, and development flexibility. Once you get a handle of graph databases, feel free to check how Memgraph compares to Neo4j, to help you choose the best graph analytics platform for your needs.
Prerequisites
To follow along, you will need to install:
- Memgraph Platform: a graph application platform that includes a database,command-line interface mgconsole, an integrated development environment used to import data, develop, debug and profile database queries and visualize query results Memgraph Lab and MAGE - graph algorithms and modules library.
To install Memgraph Platform and set it up, please follow the Docker Installation instructions on the Installation guide.
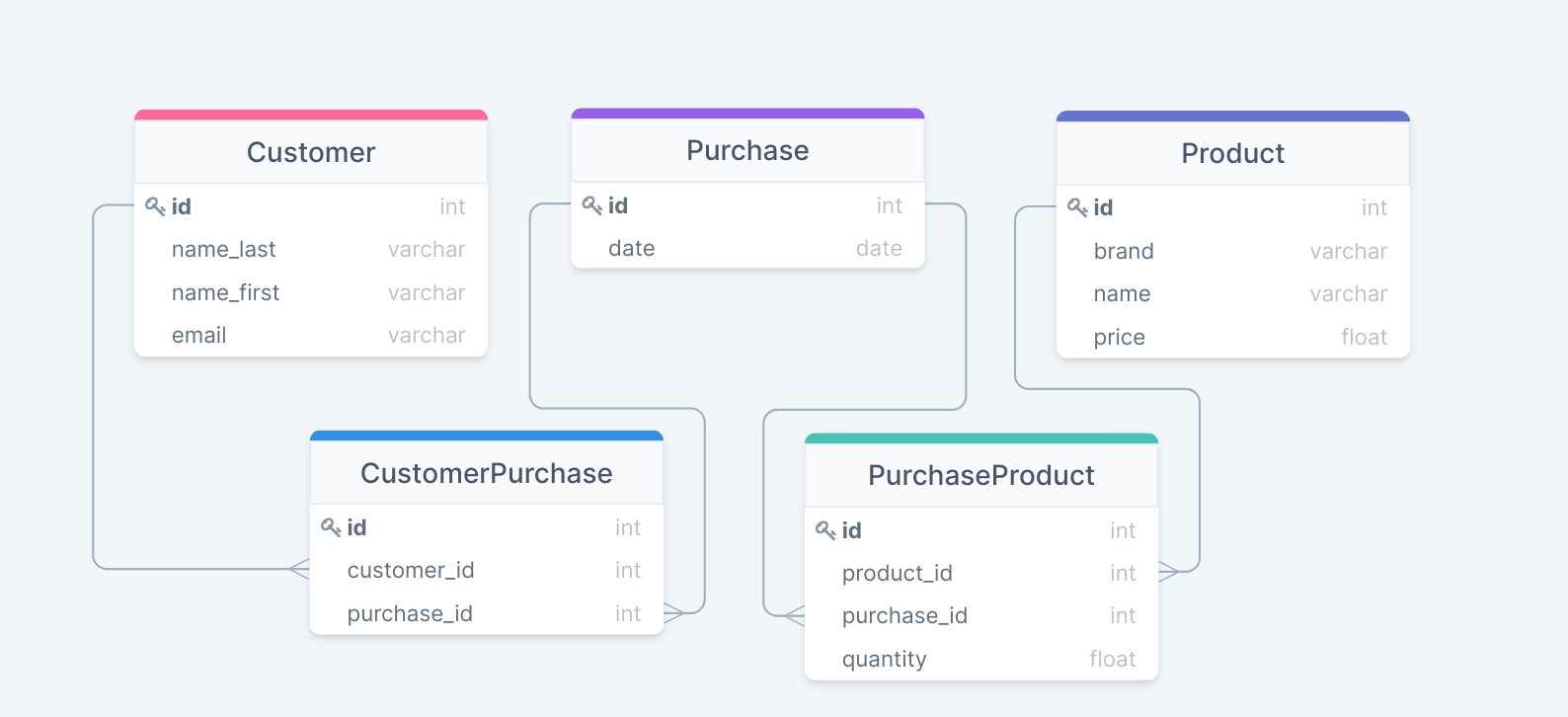
Modeling Data with SQL
To model your customer order management system using an SQL implementation,
you will need three tables: Customer, Purchase and Product.
You should also define a structure for them upfront, which in the case of a more
complex real-world problem would imply a lot of meetings and discussions with
your team to figure out what Customer, Purchase and Product should look
like.
Once that's done, the next step is to connect your tables. Many customers have
many purchases, which means an additional many-to-many table. This is not a
problem and many ORMs will handle it for you. You will need another many-to-many
table for connecting purchases and products. A Purchase containing a Product
can have a quantity. Again, not a problem, you just need to expose your
many-to-many and add a field.
At this point, you have a schema, you deployed it to your database, learned a bit more about your favorite ORM, cursed a few times because it was not 100% intuitive, and are rolling it out. Great!
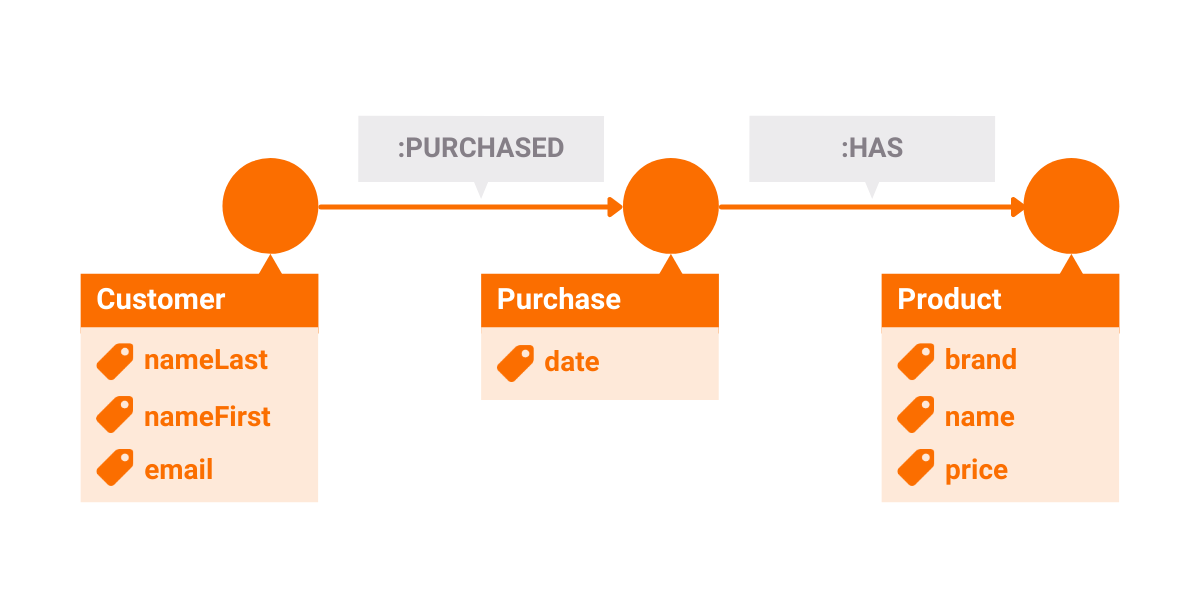
Modeling Data with Graph
Modeling your customer order management system using graphs is much faster. First, property graph databases like Memgraph, don't have a strict schema, so you don't have to define it upfront. You need to differentiate customers, purchases, and products. Those will be nodes (vertices) in our graph with appropriate labels. You will then need to connect them and add properties on those connections, which is pretty straightforward too.
Can you handle many-to-many? Of course, graph databases support fast arbitrary
relationships. Let's make a layout diagram. It's not as explicit as the
relational schema, but it's semantically clearer, and in general more
intuitive.
Let's write a few Cypher queries so you can populate your database. Unlike
SQL, where you actually had to define the database schema beforehand, in graph
databases, the insertion itself defines the structure. We won't explain the
queries in detail, feel free to check out our quick-start on
Cypher. Let's start by creating a
Customer and a Product node:
CREATE (customer:Customer {name: "John Doe", id: 0})
CREATE (product:Product {brand: "Shooz", name: "X3D Ultra Turbo Pro 3.1",
cost: 399.95, id: 0})
RETURN customer.id, product.id;Notice how you haven't added all the properties yet. You don't need to know the whole data structure upfront, you can modify it as the need arises. If you're building some sort of a web API in front of your database, the input queries don't even have to be predefined. Here's how a creation-query generator would look in Python (slightly different Cypher syntax to facilitate the property map generation):
def make_create_query(id, label, properties):
"""
Generates a Cypher query for creating a node with the given
label and properties. Properties map strings (names) to primitive
values (ints, floats, bools, strings).
"""
return "CREATE (node:{1} {{{2}}}) " /
"SET node.id = {0} RETURN id".format(
id, label, ", ".join("{}: {!r}".format(*kv) for kv in properties.items()))Using such a function, you can easily create nodes with properties extracted
from, for example, a HTTP URL. If the structure of your Customer or Product
entities changes, you don't have to modify the DB schema nor the back-end server
(OK, you might want to validate the key-value pairs you get). Zero downtime
redeployment comes down to switching to a new front-end. Pretty cool!
Now let's handle creating orders and connecting customers to products. Assuming
that you have the info on who the Customer is and what their Purchase is
(handled by your app's front end), the Cypher query would look something like
this:
MATCH (customer:Customer {id: 42}),
(p1:Product {id: 123}),
(p2:Product {id: 654}),
(p3:Product {id: 12})
CREATE (customer)-[:PURCHASED]->(purchase:Purchase {id: 0}),
(purchase)-[:HAS {quantity: 3}]->(p1),
(purchase)-[:HAS {quantity: 5}]->(p2),
(purchase)-[:HAS {quantity: 1}]->(p3);It's fairly simple. First you MATCH the known Customer and Products and
then you create a Purchase that is connected to them. Generating a query
dynamically (the number of different products in a purchase varies) also
shouldn't be too hard.
As you can see, the Cypher implementation of your data model is simple and easily extendible. With SQL, there's definitely more work to be done. There are five tables to define with their complete schemata. If you want to avoid writing raw SQL you also need to know and depend on a third-party tool. Personally, I used a few relational ORMs (SQLAlchemy the most), and while they helped it still wasn't exactly enjoyable.
Querying Data with Cypher
Once you start getting some data in, you'll obviously want to get it out. Let's say you want to get all the products a specific customer purchased. This would be unpleasant to write in SQL because it would require five JOINs. A good ORM tool will probably make it substantially smaller and easier to handle. With Cypher it's quite easy:
MATCH (:Customer {id: 42})-[:PURCHASED]->(purchase)-[purchase_product:HAS]->(product)
RETURN purchase.year, purchase_product.quantity, product.id;After all, the Cypher language was designed for easily querying connected data. Extending the query to include arbitrary filters can be done by query generation in your app's backend, similar to creation queries. While not entirely trivial, it's doable. In all fairness, an SQL ORM should probably make it even easier. This is a common and simple requirement, and it can be handled well.
Now let's say you want to find the ten top-spending customers during a given time period (for simplicity let's say during a calendar year). The SQL query would again be cumbersome to write, and an ORM would help. With Cypher it's fast and intuitive:
MATCH (customer:Customer)-[:PURCHASED]->(purchase {year: 2017})-[purchase_product:HAS]->(product)
WITH customer, sum(purchase_product.quantity * product.price) AS yearly_expenditure
ORDER BY yearly_expenditure DESC
RETURN customer, yearly_expenditure LIMIT 10;Voila! You just wrote it and there are absolutely no JOINs.
Refactoring Your Data Model
Database schemata rarely remain unchanged throughout a system's lifetime. Let's say that due to a business expansion the variety of products on offer in your store suddenly greatly increased. You should now store many different product types that have a large number of incompatible attributes (both running shoes and mobile phones are products on offer).
With SQL databases there are several ways of tackling this problem, but none of them are really pleasant. ORMs typically attempt to map OOP class hierarchies to database columns, but the underlying storage limitations make it finicky. And again, the data structures need to be defined upfront, which means a lot of iterative discussing, refactoring, testing, and redeploying. Of course, it all needs to be done with zero downtime. This kind of intervention into a relational database is neither trivial nor fast to execute, even on a toy example. In a real-world scenario it's point-blank avoided (quickly earning the "technical debt" tag).
With a property graph like Memgraph, it's fairly simple. Every node can have an arbitrary number of labels, so a Product can at the same time also be of a specific type. It can even belong to multiple types, it all just comes down to adding a label. Here's how it's done:
MATCH (product:Product) WHERE product.brand in ["Nike", "Adidas"]
SET product:TrainerShoe;With a few queries, you can label products making them easy to differentiate. The queries are likely to be simple enough to execute on a production database, but you should test on a clone first. Since there is no strict schema, the system can naturally evolve along with the business logic.
There are a number of other refactors you might need to introduce into the system as it grows. You might need to relate products to each other, introduce a concept of suborders, as well as introduce new fields. Most of these will be easier to handle in a graph than in a relational database.
Personally, I believe all of them will be easier to handle. A property graph is extremely flexible, both for data structure and connections. Many concepts are much easier to express naturally than in a relational database. In my opinion, when it comes to evolving a system, a property graph beats relational hands down.
Graph Database Performance
Over time the quantity of active data in your system will grow. The scale can vary wildly, and in all but the largest (think Google) scales, you would expect a modern database to deliver good and predictable performance. So, let's test what kind of a scale can Memgraph handle. We are running this on a strong laptop (4 core i7 with 16GB RAM).
Creating a dataset
Here are a few Cypher queries to help you set up a mock dataset. First, you'll need to create some indexes:
CREATE INDEX ON :Customer(id)
CREATE INDEX ON :Product(id)Next, keeping things simple, let's create ten thousand customers with the same name:
UNWIND range(0, 9999) AS ignored
CREATE (:Customer {id: counter('Customer.id', 0), name: "John Doe"})Then, let's create 10 000 products. Let's add random prices so you can play with analytic queries:
UNWIND range(0, 9999) AS ignored
CREATE (:Product {id: counter('Product.id', 0),
name: "Awesome product",
price: rand() * 100})Finally, let's generate 100 000 purchases from random customers to random products. To keep it simple, each purchase contains three products with random quantities:
UNWIND range(0, 99999) AS ignored
WITH tointeger(rand() * 10000) AS c_id,
tointeger(rand() * 10000) AS p1_id,
tointeger(rand() * 10000) AS p2_id,
tointeger(rand() * 10000) AS p3_id
MATCH (customer:Customer {id: c_id}),
(p1:Product {id: p1_id}),
(p2:Product {id: p2_id}),
(p3:Product {id: p3_id})
CREATE (purchase:Purchase {id: counter('Purchase.id', 0),
year: 2000 + tointeger(rand() * 18)}),
(customer)-[:PURCHASED]->(purchase),
(purchase)-[:HAS {quantity: 1 + tointeger(rand() * 5)}]->(p1),
(purchase)-[:HAS {quantity: 1 + tointeger(rand() * 5)}]->(p2),
(purchase)-[:HAS {quantity: 1 + tointeger(rand() * 5)}]->(p3);After a few seconds, your mock dataset is ready for testing. It contains 120 thousand nodes and 400 thousand relationships. Memgraph is using around 350MB of RAM which shouldn't be a problem.
Let's see how the query for finding a customer's purchases performs.
MATCH (:Customer {id: 42})-[:PURCHASED]->(purchase)-[purchase_product:HAS]->(product)
RETURN purchase.year, purchase_product.quantity, product.id;The results (around 30 products) are obtained in around 0.1 milliseconds.
What about that analytical query for getting last year's top 10 spenders?
MATCH (customer:Customer)-[:PURCHASED]->(purchase {year: 2017})-[purchase_product:HAS]->(product)
WITH customer, sum(purchase_product.quantity * product.price) AS yearly_expenditure
ORDER BY yearly_expenditure DESC
RETURN customer, yearly_expenditure LIMIT 10;This one takes around 106 milliseconds. Not too bad for an analytic query executed on a transactional database. It would also be important to measure performance when there are parallel inserts, but that's a task for another time.
Let's also try a ten times bigger scale. That means 100 thousand customers and 100 thousand products. This is already big business. Let's connect them with a million purchases (that's almost a thousand purchases daily, for three years). Generating a new dataset on the given scale takes a bit longer (about a minute). Once set up, Memgraph uses around 2GB of RAM. Getting all the products a customer purchased still takes only a few milliseconds. The analytic query for the top 10 spenders in 2017 takes around 782 milliseconds, which is also reasonable.
Note that all of the queries above execute in a single thread in Memgraph and the test machine was nowhere near at full load. Also, don't forget that the test machine is a personal laptop running other things in the background.
Conclusion: The Infamous Graph Use-case
In this post, you learned how a graph database can help you model, query, and expand your data in a faster and more intuitive way when compared with a traditional SQL approach.
You often come across the question: What is a use-case for graph databases?
Typically, you start thinking about queries spanning a large number of connections (relationships, edges) or finding the shortest path from point A to point B. I believe that to be a very limiting and simplistic mindset.
What if the question was: Do you need a lightweight, fast, scalable, initially flexible, and refactor-friendly solution?
The answer: Who doesn't?
Graph databases are used by almost every industry as well, so find out how you can utilize it in yours, and also how Memgraph compares to Neo4j to find a perfect tool to handle your data.