
Batch Processing vs Stream Processing
In this article, you can learn the difference between stream processing vs batch processing, and get to know the basic use cases for each.
What Is Batch Processing?
Batch processing refers to a method of processing high-volume data in batches or groups simultaneously, sequentially, and continuously, often at the end of a business cycle, e.g., the end of the month for payrolls. Batch processing makes calculations on an initially large dataset, which is then reduced to a smaller set of results.
For example, if your company's data were being processed through batch calculations every day, you would have to wait until your accounting department recorded all transactions before being able to compile reports for each region or each year. This means that it could be days before you can access the final report for your business.
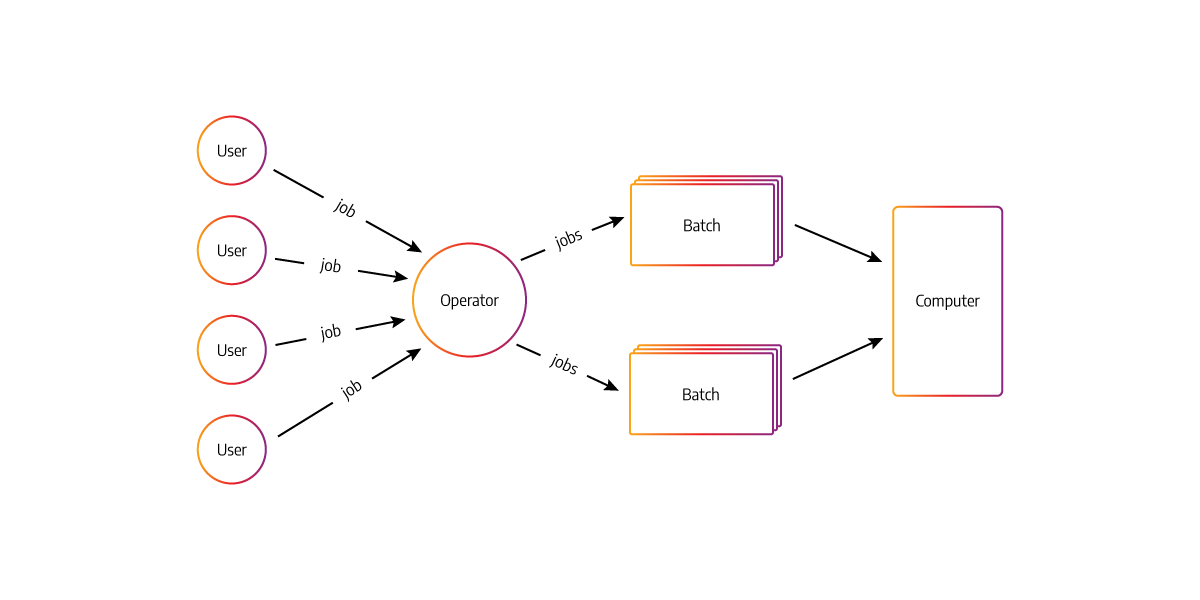
Use cases and examples of batch processing
Below are some common scenarios where batch processing is used:
- Data cleansing
- Data transformation
- Data aggregation (summary, rollups)
- Grouping and selection (group by, distinct, pivot)
One of the most common use cases for batch processing is ETL.
Extract – Transform – Load refers to a process where unstructured data is extracted from external sources and transformed using rules and algorithms before being loaded into a data warehouse or data mart for reporting and analysis. This allows companies to consolidate their data and only include the most useful information in one place.
These processes can take hours or days. So, they are typically done at night as part of the nightly maintenance window.
Batch processing use cases include banking, healthcare, and other sectors where massive quantities of data must be processed. For example, utility companies generate reports at the end of every business day after all credit card transactions have been processed. They collect data on their customers' usage and determine billing by running batch processes.
In a different scenario, a financial data management firm conducts overnight batch processes to provide financial institutions and banks with direct financial reports.
What Is Stream Processing?
Stream processing is the process of analyzing and managing data in real-time – it's the continuous, concurrent, and incremental evaluation of events as they happen. This means that, unlike traditional batch jobs, stream processing doesn't need to wait until all the data has been collected before starting analysis or getting a result - you can start working on it straight away.
One example would be using Apache Kafka (a distributed streaming platform) to monitor web traffic by processing log entries as they come in rather than having to wait until all the logs had finished uploading from each server.
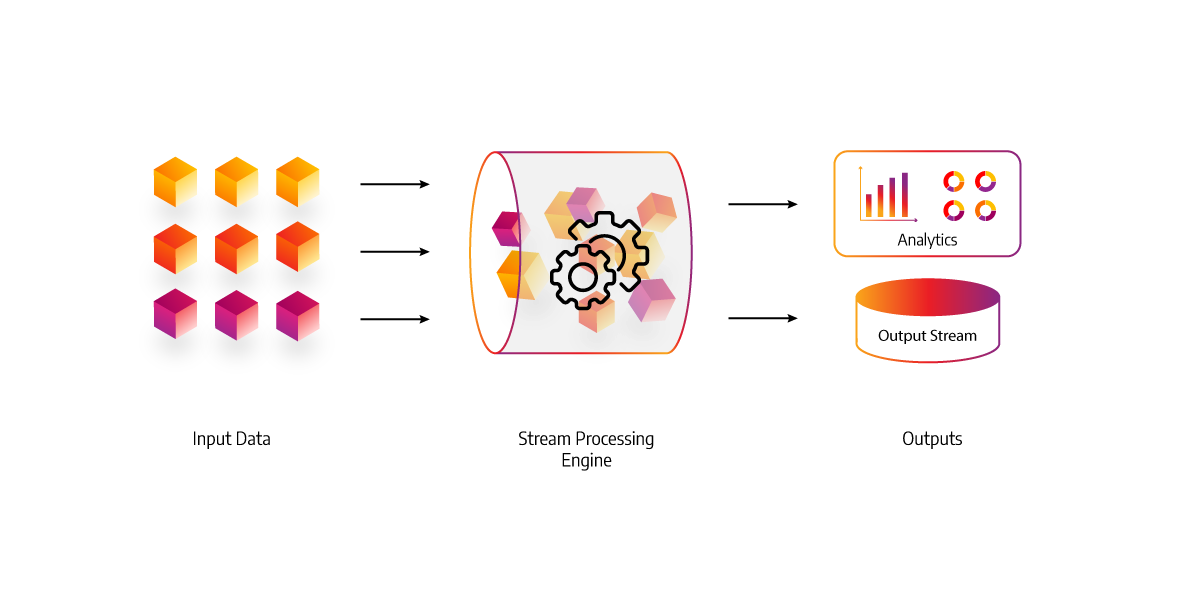
Use cases and examples of stream processing
Some of the most common use cases for stream processing include:
- Real-time anomaly and fraud detection: credit card transactions, click-stream analysis, web server logs
- Real-time data analytics: manufacturing sensors, UPS telemetry, connected cars
- Event stream processing for IoT: point of sale terminals, stock tickers
One of the most common use cases for stream processing is monitoring sensor or device data. For example, a smart connected car can monitor a multitude of information from whether the hood is open to tire pressure and velocity through more advanced features such as adaptively learning driver behavior over time. This allows companies to work out how best they can interact with their customers on a one-to-one basis by suggesting alternative products or services based on what they know about users. It’s essentially big data tailored for the individual user.
As a result, customers receive a better service, and companies learn how users interact with their products and when they tend to do certain things. For example, suppose the car knows that your daily commute is usually 30 minutes. In that case, it will prepare the inside of the vehicle accordingly or even suggest a playlist for you to listen to on your morning drive. This level of personalization increases customer engagement and satisfaction while also allowing companies to learn about their consumers' behavior more effectively, allowing them to make more relevant suggestions going forward.
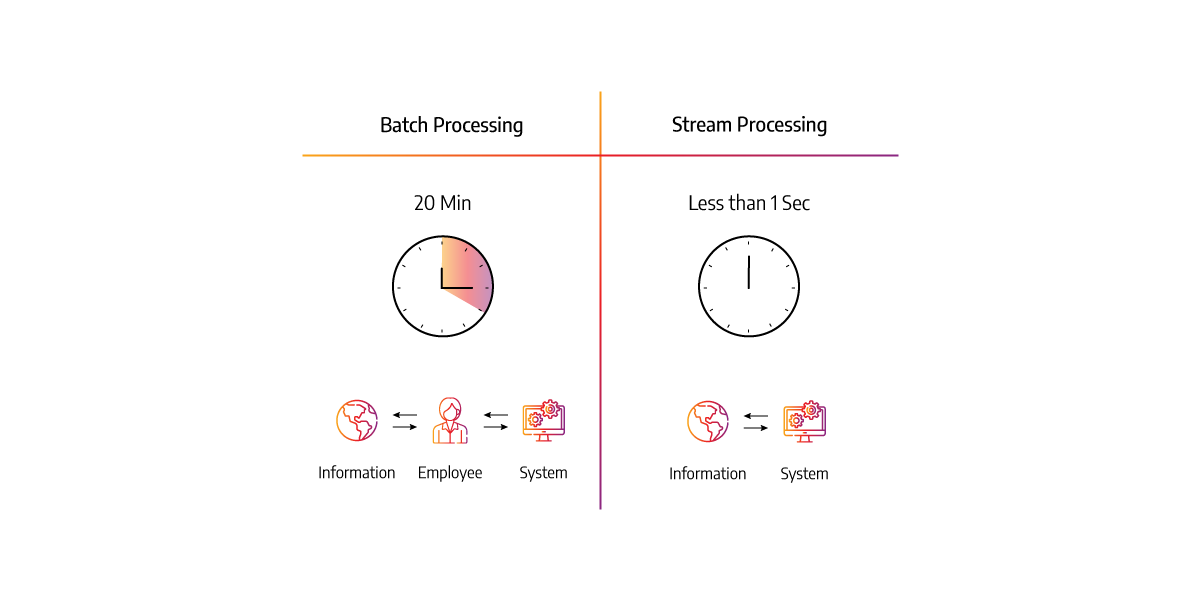
Differences between batch and stream processing
Batch Processing
- Batch processing processes huge data volumes within a specific time after production.
- Batch processing compiles a large volume of data all at once.
- Processing data size if finite and specified.
- Input graph in batch processing is static.
Stream Processing
- Stream processing processes continuous data in real-time as it is produced.
- In-stream processing is done in intervals as soon as data is produced.
- Stream processing data size is unknown and infinite.
- In-stream processing, the input graph is dynamic.
How to turn batch data into streaming data
To transform these types of data, you’ll need to make a few adjustments to your current setup. Instead of sending the data in batches at specific times, you would need to continuously send each data packet as it’s created and available for transport and analysis. Streaming platforms like Kafka, Redpanda and Pulsar could be used as message brokers while other applications are available to perform real-time stream processing. This way, your data would be processed as it’s created, and the analysis information would be available shortly thereafter.
Conclusion
In conclusion, batch processing is safe and secure for data deployment, but it takes time to compile and release the data, so if you want a faster way to obtain data, you can use batch processing. However, when it comes to fast data streaming, you may need to use stream processing which deals with data in real-time.