Why You Should Automate Mapping Data Lineage With Streams
A challenge all data lineage projects face is figuring out the best way to get lineage information in a database and keep it up to date. The specifics vary by the type of data lineage (business vs. technical) and even more by the particularities of your organization’s data landscape. Automating data lineage mapping saves a lot of resources. Besides that, compliance with business standards like BCBS 239 and the GDPR means that companies must be able to make data-driven reports on a largely automated basis.
Even if you brush aside the above, it’s indisputable that graph DBs are the best choice for data lineage, but Memgraph raises the bar by making end-to-end data lineage automation feasible with built-in support for streaming. You can use streaming to build ETL (extract, transform, load) processes that automatically ingest and transform collected data and maintain separation of ETL concerns.
Lineage data collection
There’s a variety of approaches for gathering the information needed for a system’s data lineage. Each of them has its pros and cons, and the ultimate choice depends on your use case.
For example, modern BI/data visualization tools like Tableau and Looker keep track of their data lineages and expose it via APIs. Alternatively, OpenLineage seeks to standardize metadata so that data lineage can easily be pieced together. These solutions provide robust and accurate information, but it’s rare that the entire data landscape is compatible with them. To deal with that, specialized software parses the data transformation code, identifies and extracts lineage information. Finally, manual lineage entry may be time-consuming and painstaking, but the ability to do fixes by hand can be indispensable.
Three reasons to stream lineage data
Regardless of the collection method chosen, the next step in mapping data lineage is to push the metadata to tools that process it before it can be taken by the database.
Streaming platforms send off events (messages with data) to connected services in real time. They are a handy data lineage tool for these reasons:
- Data integration: Real-world organizations have complex data infrastructures with multiple subsystems and you often have to integrate diverse data. With streaming platforms, you can assign each source to a topic (a group of similar events). That way, data consumers can tell each source’s data apart and handle it correctly.
- Real-time operation: Lineage data is often batched (processed in groups), but with streaming it’s possible to process it as soon as it’s created or modified. With a tight feedback loop, you can get data engineering tasks done faster and catch any breakages as the moment they happen.
- Reliability: Streaming platforms offer high reliability, and data lineage solutions that require low latency often depend on the strong durability guarantees these tools provide.
Memgraph: a streaming graph DB
Memgraph is a fast, flexible graph database that supports the Apache Kafka, Redpanda and Apache Pulsar streaming platforms.
Connecting Memgraph to a stream is as simple as following a wizard in the Memgraph Lab IDE. The step-by-step process helps reduce cognitive load and free up attention so that you can focus on configuration and data transformation. Once everything is set up, you can begin ingesting data via transformation modules.
Transformation modules
Transformations are user-defined procedures, written in Python or C++, that tell Memgraph what to do with incoming messages before it can ingest their contents.
When configuring a stream in Memgraph, you specify what transformation procedure is tasked with handling data from it. If you have multiple data sources, you can develop individual procedures for them. Or, multiple streams can share the same procedure if applicable.
Streams + transformations are the right solution for doing data lineage on complex, multi-component data systems as they avoid unnecessary complexity that comes with one-size-fits-all transformations. When each lineage metadata source is assigned its own stream, Memgraph can pick it up and do the right transformation before adding it to the lineage graph.
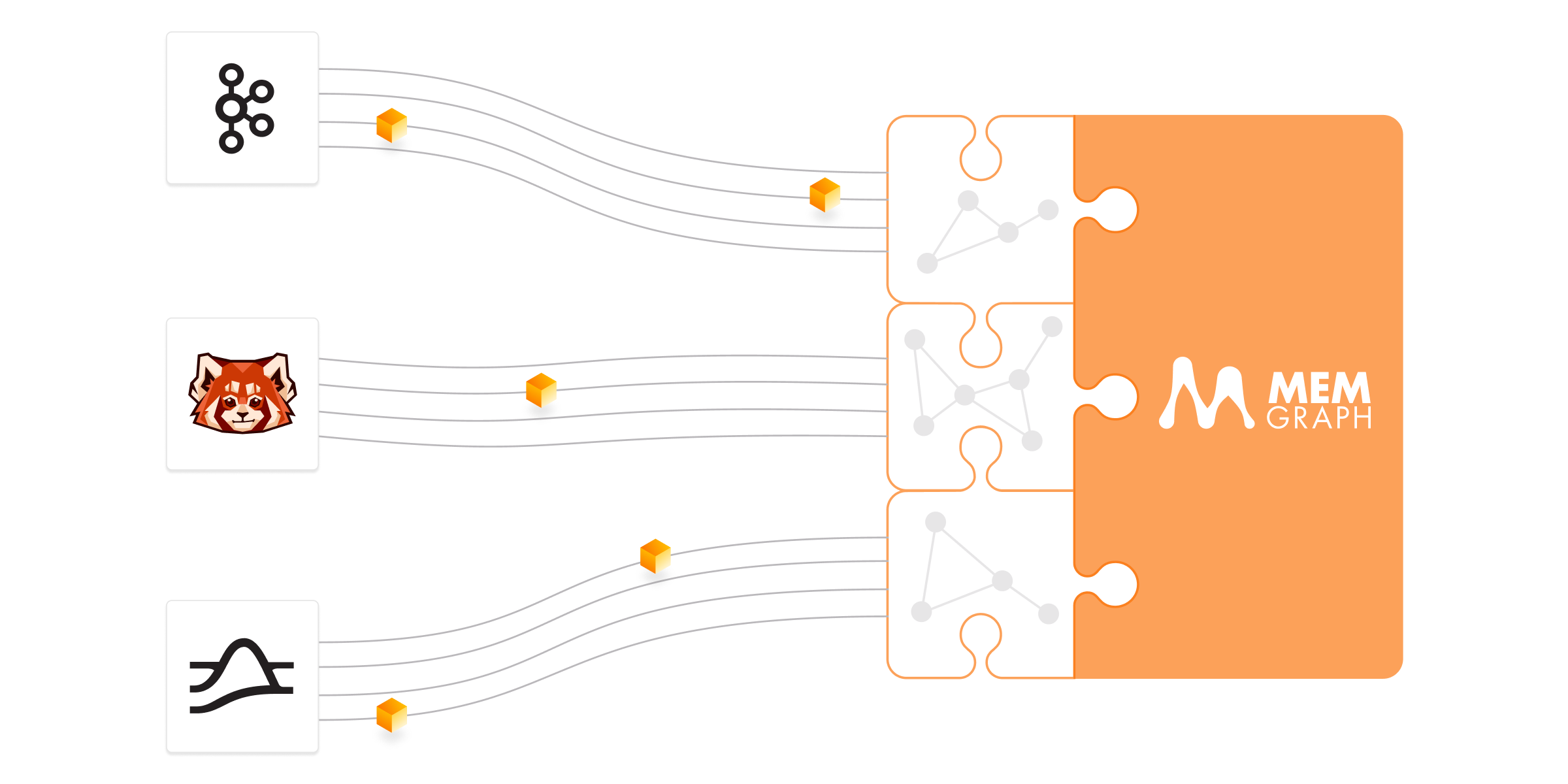
All in all, Memgraph’s streams feature helps simplify data ingestion by organizing component processes. You no longer need to funnel all data to one complex procedure that constitutes a single point of failure.
Summary
“Event streaming is the digital equivalent of the human body’s central nervous system.”
In conjunction with a streaming DB like Memgraph, stream tech makes it easier to clean raw lineage data by passing off different-format data separately. On the database end, Memgraph connects to streams and applies user-defined procedures to lineage data before ingestion. This combination separates extraction and transformation concerns, and lets you build reliable, real-time systems that automate mapping data lineage.
As for other data lineage tasks, Memgraph’s graph data model and analytics help you understand your data so that it can be a trusted asset in the organization.