
Why Are SQL Databases Outdated for the Real-Time Recommendation Engines
Data in recommendation engines grows rapidly and can become very complex. Websites like Amazon have over 197 million users each month, and every few minutes 4000 items get bought. Storing all that data might not be a problem for relational databases but querying and finding useful information for making recommendations could be a slow and painful SQL nightmare.
It is no longer enough to know that a connection between certain users, reviews, and products exists. To have a truly accurate and adaptable recommendation engine, those relationships need to be dissected to extract their significance, influence, and weight. To discover those relationships, let alone analyze them, puts a strain on the relational databases due to a large number of (recursive) JOIN operations. Luckily, graph databases don’t need to bother with identifying connections - entities and their relationships are graph databases’ building blocks.
And if at any point your business model changes in a way it was not foreseen while first being built, graph databases can handle those changes with ease due to their flexibility in modeling data.
Due to the shift of focus to relationships in graph databases, querying them to find useful recommendations becomes easier and faster in comparison to relational databases. Check out how you can finally stop thinking about JOINs, and start thinking about what your customers actually need to buy.
Easy to model data
In relational databases, data is stored by creating multiple tables where each column represents the entity’s attribute including a unique key by which each table can be connected using JOINs with other tables in the database. Sketching a relational data model and the associated tables on a whiteboard presents a bit of a challenge, but anyone familiar with their business requirements can work with a graph data model, even if they are not well-versed in data science.
Graph databases have nodes (vertices) and relationships (edges) between those nodes as two main entities. Information about each node is saved as its properties. So if the data consists of products, users, and reviews - those are all nodes with different labels and properties - the product’s name, brand, dimensions, and price. Users look at those products, put them in a basket, buy them, rate them or return them, and form different types of relationships between themselves and the products.
In order to implement a recommendation system in the retail sector, relational databases require defining a database schema and setting up tables, one table for users, one for products, and one for ratings. Each row in a table has a unique key, that key is stored in another table row as an attribute to show a connection. The schema could look something like this:
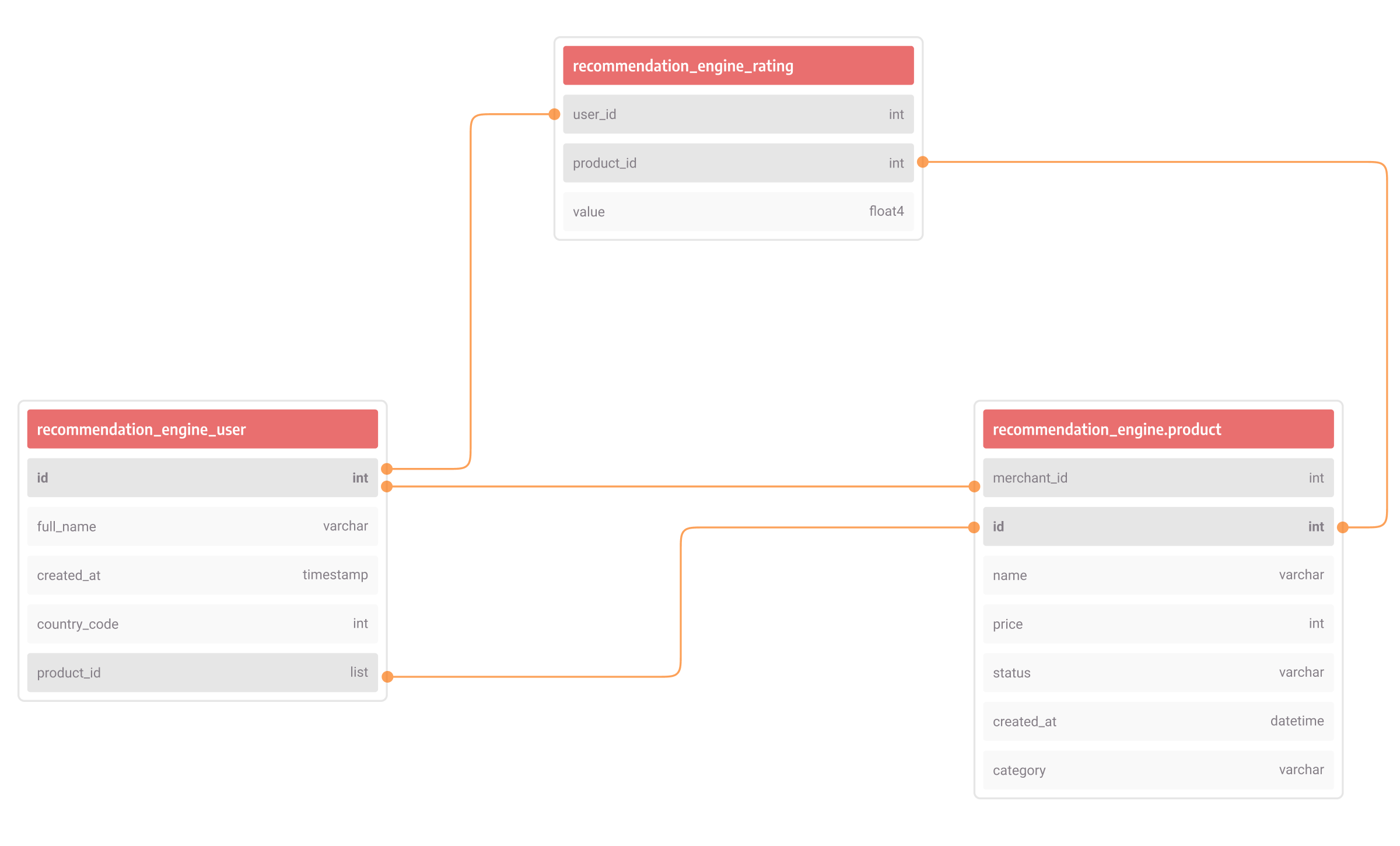
With numerous rows of data and a system with far more tables than this simple example, it is a hard job to understand the nature of the connection between tables. If anything in the model changes, we need to go back to the schema to rearrange the inner working, then update all the tables and processes.
Modeling interactions between nodes in graph databases aligns with the way data is stored and queried to provide optimal results for recommendation engines. Graphs help develop an accurate representation of the business model by offering a means to express connections between entities in a better way than relational databases. And additionally they provide the system with much-needed flexibility.
In most graph databases database schema is not a requirement, so it is much easier to start importing and later update data. Nodes and relationships are created at the same time as the data is stored in the database.
Once a user creates a profile account, a node with the label USER is created along with the properties that define a specific user. Users can create products they sell, and the graph model is updated with a node labeled PRODUCT. USER and PRODUCT nodes are connected with a relationship :SELLING. Users can also buy a product and rate them. In that case, a relationship is formed between the USER node and the PRODUCT node with a type BOUGHT or with relationship type :RATED and the actual rating as its property. The graph schema looks like this:
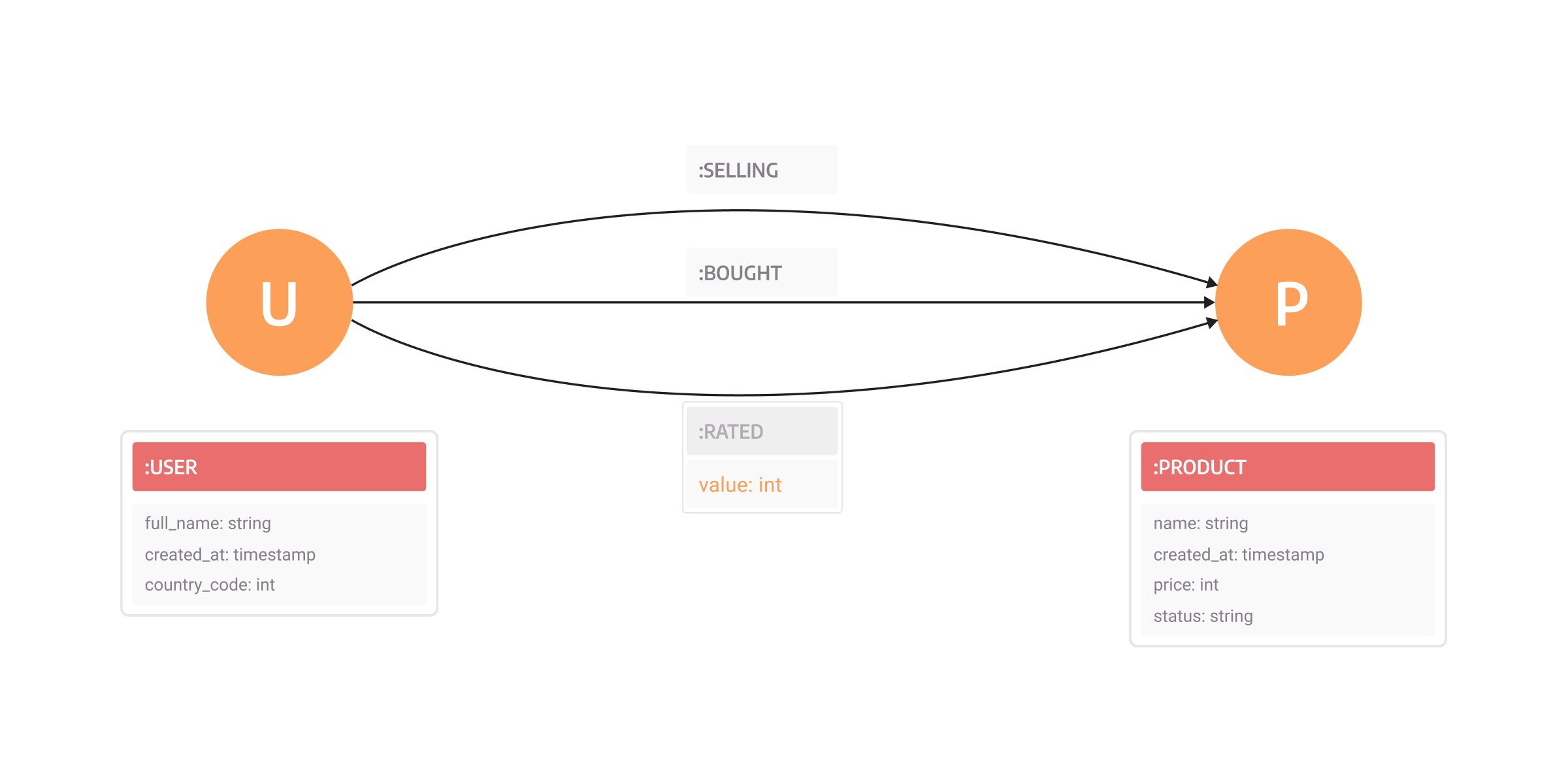
Even at a quick glance, all entities and relationships between them are instantly clear and comprehensible.
The network created with relationships between different nodes is precisely what makes examining and gaining insights into them easier and faster when compared to relational databases.
Recommending a product - SQL queries vs. Cypher queries
Based on the data models in the previous chapter (and it’s important to point out they are much less complex than the models in real-life), let’s try to create a query that would recommend a product to a certain user that didn’t buy that product before. The recommendation will be based on products that they gave the highest rating to, and so did all the other users that reviewed the same products as our target user and gave the highest rating as well. This is also one of the simpler queries recommendation engines can use, because they can dig even deeper with community detection, calculating Pearson correlation coefficient, and machine learning as well.
To write an SQL query, tables need to be connected using complex JOIN operations. The SQL query would look something like this:
select B.* from user User1
join rating Rating1 on User1.user_id = Rating1.id and Rating1.value = 5
join product A on A.id = Rating1.product_id
join rating Rating2 on Rating2.product_id = A.id and Rating2.value = 5
join user User2 on User2.id = Rating2.user_id and User2.id <> User1.id
join rating RatingB on RatingB.user_id = User2.id and RatingB.value =5
join product B on B.id = RatingB.product_id
WHERE User1.id = 1;JOIN operations are prone to error, slow, and computationally expensive. Every JOIN operation has a time complexity of O(M / log(N))* where M is the number of records in one table and *N* is the number of records in the other table, meaning we need to scan all rows from both tables and then try to connect them on a unique key. Relational databases will get slower and slower with more complex queries and analytics that require connecting multiple tables and also as data in the recommendation engine grows.
Each graph database uses its own query language, and in the world of graph databases, the most common language is Cypher. The Cypher query that would achieve the same result looks like this:
MATCH (pA:PRODUCT)<-[r1:Rated {"rating":5}]-(n1:USER)-[r2:Rated {"rating":5}]->(pB:PRODUCT)
MATCH (n2:USER {id:1})-[r3:Rated {"rating":5}]->(pb)
WHERE n1.id != n2.id
RETURN pB;
The process of searching through nodes in a graph is called graph traversal. The complexity of graph traversal is O(K) where K is the number of connections that one node has with others nodes. The high optimization is the result of the index-free adjacency concept, one of the most important concepts to understand when it comes to graphs. When looking for adjacent nodes in a graph, graph databases perform pointer hopping, that is, a direct walk of memory - the fastest way to look at relationships. To enable direct walks of memory, relationships are stored as direct physical RAM addresses. And what’s most important, relationships are created upon creating data, not querying.
Graph databases don’t have to work with any other data structure or indexes to hop from any node to neighboring nodes. When designing a recommendation engine, connections between users and products they bought are explicitly added as fixed physical RAM addresses. What enhances the performance even more is storing related nodes next to each other in memory, thus maximizing the chances that the data is already in the CPUs cache when needed.
The research shows that recommending a product to users that are three connections away is more than 180 times faster with graph databases than it is using relational databases.
Flexibility
Relational databases rely on a predetermined schema created before the database itself. The schema of a relational database shows its true rigid face once something unexpected or unplanned occurs. In the retail business, where recommendation engines play a crucial role, it’s really hard to predict how the market, and therefore platform will evolve and change.
For example, your company sells boats and you built a recommendation engine on top of that data. One day, you want to expand the business and start selling fishing equipment that will complement the boat offers. With relational databases, you need to rethink your relational database at the very foundation because the schema must be followed to the letter. Otherwise, any data that enters the database but doesn’t fit in, will not be stored. So if the schema doesn’t predict that a product has a thickness, a very important attribute of a fishing line, but not a topic often raised during discussions about boats, the schema needs to be redesigned.
If you take an easy way out, and just add all the attributes that could be applied to all the products, some of them would have to be of the NULL value, because fishing equipment cannot be defined by properties such as engine power or boat type, and boats aren’t typically defined by the thickness of anything. First of all, you are wasting memory, but you are also adding more complexity to your code by adding another filter to filter out boats, or additional checks to avoid page breaks caused by NULL attributes.
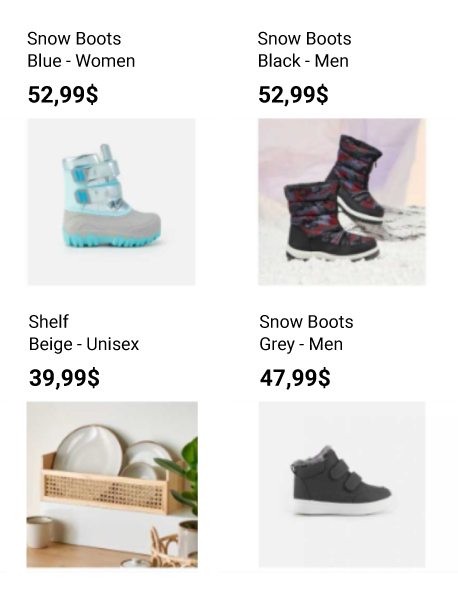
If you choose to ignore the problem and just show all the attributes, the recommendations will look silly and unprofessional. Look at this real-life example, where a shelf is described as being unisex because the retailer is mostly focused on selling clothing items and did not adapt the database to selling household items.
A better solution would be to update the database schema by creating one table for storing boats and another table for storing fishing equipment. But, you also need to add an additional attribute to the User table to store unique keys from fishing equipment alongside unique keys from boats. Without the information about unique keys, you can’t connect the two tables.
If your business continues to grow and expand, you will face this exact problem each time you decide to deal with a new type of product. That means another table and another attribute column for the user. Of course, this is just a dummy example, and you could definitely do a better job improving the database scheme. But, as you can see, there are a lot of technical details and future problems you need to address when you are using relational databases. It all becomes messy quite quickly.
All these time-consuming changes and the possibility of sudden system fallouts because certain scenarios were not covered are minimized by using graph databases.
Graph databases don’t have predefined schema meaning you can create nodes with labels and properties that don’t exist in the database. You can also connect them to existing nodes without breaking anything or doing any changes to the existing data. Isn’t that awesome?
With graph databases, you can enter new changes at any time without risking the integrity of present functionality, as opposed to extensively designing a domain in advance.
Let’s take the same example with a new business requirement of selling and recommending fishing equipment but in a graph database. When your platform decides to start selling fishing equipment, on creating a new PRODUCT node, you will need to add another label, let’s say FISHING_EQUIPMENT with properties that you need to define that product and that's it, you are good to go.
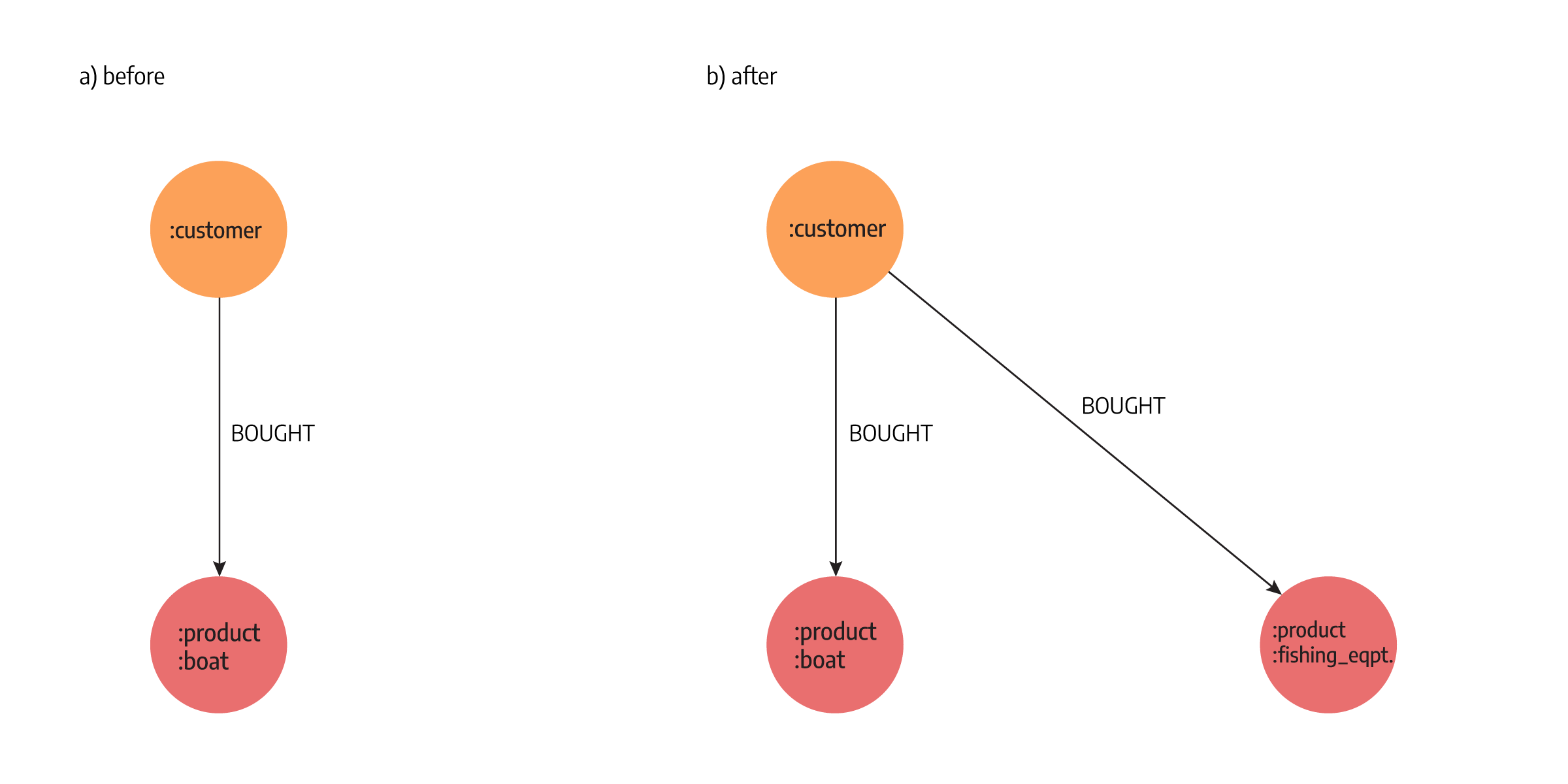
Users on your platform can start buying fishing equipment, and the recommendation engine will include it in its algorithms. When purchases occur, relationships are created between the customer and product without any changes to either the CUSTOMER node or FISHING_EQUPIMENT node.
Conclusion
Trying out new things is never easy, but if you’re not at the forefront of them, your competition probably is. Data used by recommendation engines grows by the second and the market demands truly meaningful recommendations. To get high-value recommendations, they need to be influenced by market trends and any actions the users do on the platform (browse, review, add to basket or wishlist, remove, share, or buy).
The engine also needs to align not only with the shopping habits of the targeted user, and with the habits of shoppers with similar habits as well. The business requirements, due to changes in the market, are not easily predicted making the business model change as well. Graph databases can easily adapt to any necessary modifications. And if your recommendation engine becomes congested with more data than it can handle and complex queries which throttle the prosperity of your company, moving from relational databases to graph databases should be a no-brainer.