How to Extract Entities and Build a Knowledge Graph with Memgraph and SpaCy
Here’s how you can build a knowledge graph by extracting entities from unstructured text and connecting them in Memgraph. In this example, I’ve taken The Catcher in the Rye, pulled out key entities using SpaCy, and used GPT-4 to generate relationships between them. Finally, I’ll show you how I’ve pushed it all into Memgraph as a graph that reflects the book’s themes and characters.
Prerequisites
Before diving in, ensure you have the following:
- Docker: Make sure Docker is running in the background. If you don’t have Docker installed, go to Docker’s official site to download and install it.
- Memgraph Instance: A running instance of Memgraph is required to connect and build your graph. You can set this up using Docker.
Linux / macOS:
curl https://install.memgraph.com | shWindows (PowerShell):
iwr https://windows.memgraph.com | iexHere’s the video tutorial so you can follow along and find the step-by-step guide below + here’s the link to the Jupyter Memgraph Tutorial:
Step 1: Set Up Memgraph with Docker
To get Memgraph up and running, execute one of the following commands in your terminal, depending on your operating system:
These commands will:
- Download a Docker Compose file.
- Set up two containers:
- Memgraph MAGE are built-in analytics and algorithms.
- Memgraph Lab is a visualization and query execution tool.
Once the containers are running, you can access Memgraph Lab:
- Open your browser and navigate to
http://localhost:3000, or - Use the desktop version of Memgraph Lab for a richer experience. In this guide, I’ll construct and visualize the graph using the desktop app.
Step 2: Confirm Memgraph is Running
Check that the Docker services are active and that Memgraph is running. You’ll know it’s working when you can see Memgraph Lab on your browser or desktop app. The interface will allow us to visualize the graph and directly execute queries under the Query Execution tab.
Step 3: Environment Setup
With Memgraph up and running, it's time to set up the environment for extracting entities from unstructured data. I’ve used SpaCy to process the text and OpenAI to construct a JSON representation of nodes and relationships. We’ll also use Neo4j’s driver to connect to Memgraph.
Install Required Libraries and Models
Start by installing the required dependencies:
pip install spacy openai neo4jNext, download the SpaCy English model. SpaCy provides trained pipelines for over 20 languages, and we’ll use the English model:
python -m spacy download en_core_web_smNOTE: You can skip this step if you’ve already installed SpaCy and the model.
Set Up OpenAI API Key
We’ll use the OpenAI API to construct a JSON file containing the nodes and relationships for our knowledge graph. To configure OpenAI:
-
Retrieve your API key from the OpenAI dashboard.
-
Save the API key in your environment variables:
Linux / macOS:
export OPENAI_API_KEY="your_openai_api_key"Windows (Command Prompt):
set OPENAI_API_KEY="your_openai_api_key"
PRO TIP: Keep your API key secure and never share it publicly.
After setting up the API key, we’re ready to extract entities.
Step 4: Prepare the Text Data
Our unstructured data will be a text summary of The Catcher in the Rye. Below is the sample excerpt from the summary, but to get meaningful results and a richer graph, you should provide a more detailed or complete version of the text. Store your chosen summary in a Python variable:
# Sample excerpt for demonstration purposes. Replace with a more detailed summary for a richer graph.
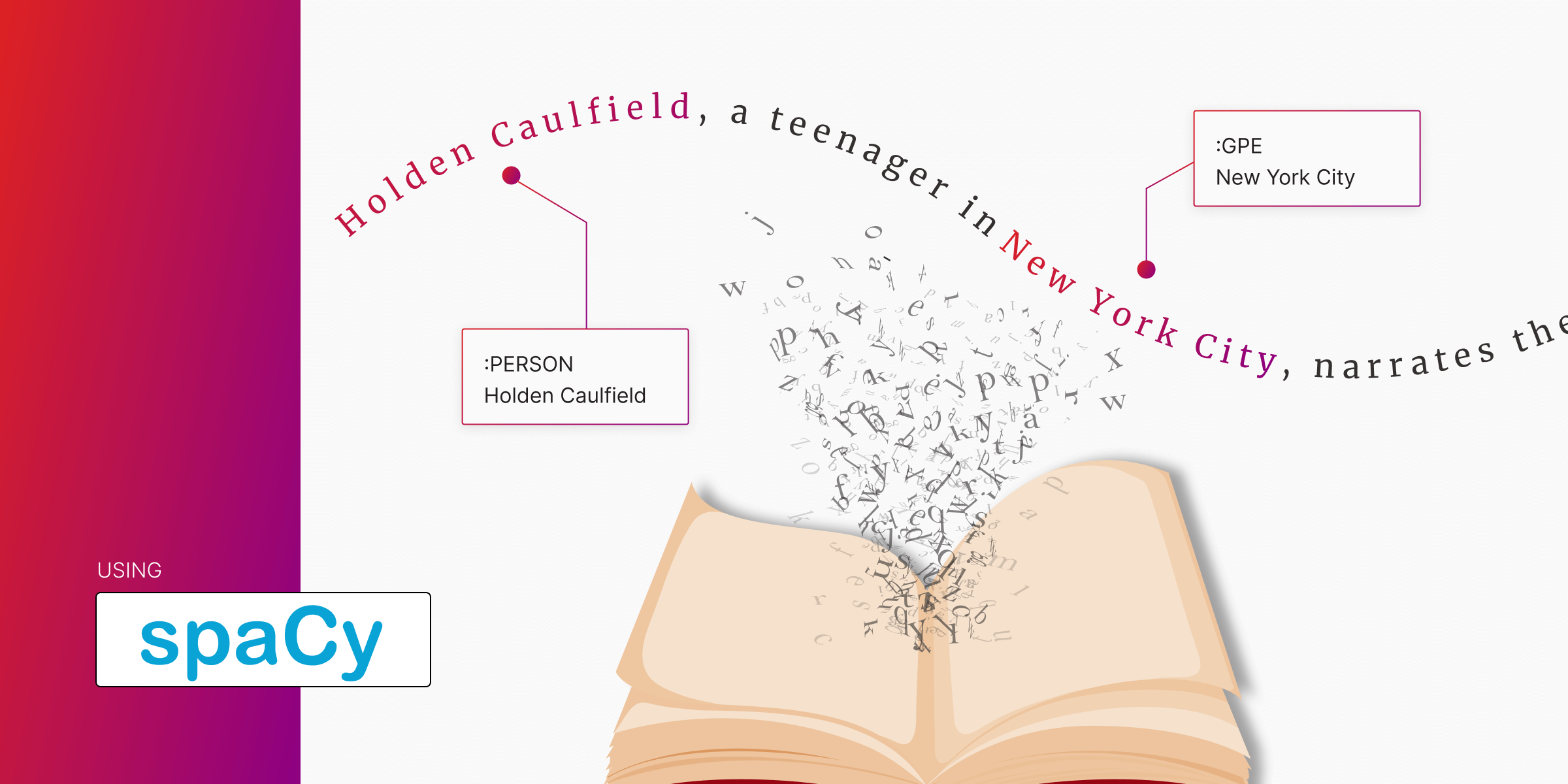
summary = """
Holden Caulfield, a teenager in New York City, narrates the novel. Struggling with depression, he recounts his experiences in school, relationships, and his disdain for 'phonies.'
"""We’ll pass this summary to SpaCy for entity extraction. A longer summary will result in more nodes and relationships in the graph, enhancing its complexity and value.
Step 5: Load the SpaCy Model
Load the SpaCy model and process the text to extract entities:
import spacy
# Load the English SpaCy model
nlp = spacy.load("en_core_web_sm")
# Process the summary text
doc = nlp(summary)SpaCy will tokenize the text into sentences and extract relevant entities for each sentence based on the model’s trained pipelines.
Step 6: Extract Entities and Labels
Using SpaCy, extract the entities and their corresponding labels. Visit Jupyter notebook to see the complete code snippet:
# Pipeline to run entity extraction
def extract_entities(text, verbose=False):
processed_data = []
# Split document into sentences
sentences = split_document_sent(text)
# Extract entities from each sentence
for sent in sentences:
doc = process_text(sent, verbose)
entities = [(ent.text, ent.label_) for ent in doc.ents]
# Store processed data for each sentence
processed_data.append({'text': doc.text, 'entities': entities})Example Output
After processing, SpaCy will generate a JSON-like structure containing sentences stored in the text variable and entities extracted from that sentence.
[
{
"text": "Holden Caulfield, a teenager in New York City, narrates the novel.",
"entities": [("Holden Caulfield", "PERSON"), ("New York City", "GPE")]
},
...
]Step 7: Pass Entities to LLM for Further Processing
The extracted text, entities, and labels will be passed to an LLM (e.g., GPT-4) to construct a JSON representation of nodes and relationships for the graph. Below is an example of the output generated by an LLM.
{
"nodes": [
{"id": 1, "name": "Holden Caulfield", "type": "PERSON"},
{"id": 2, "name": "New York City", "type": "GPE"},
],
"relationships": [
{"source": 1, "target": 2, "relationship": "LOCATED_IN"},
]
}Step 8: Generate Queries for the Knowledge Graph
Now that we have extracted entities and their relationships, it’s time to generate Cypher queries to create the graph in Memgraph.
Create a Function to Generate Cypher Queries
The function below processes the extracted entities and relationships, generating Cypher queries to insert them into the database:
def generate_cypher_queries(nodes, relationships):
queries = []
# Create nodes
for node in nodes:
query = f"CREATE (n:{node['type']} {{id: '{node['id']}', name: '{node['name']}'}})"
queries.append(query)
# Create relationships
for rel in relationships:
query = f"MATCH (a {{id: '{rel['source']}'}}), (b {{id: '{rel['target']}'}}) " \
f"CREATE (a)-[:{rel['relationship']}]->(b)"
queries.append(query)
return queriesExample Output
For the entities and relationships extracted earlier, the generated Cypher queries might look like this:
CREATE (n:PERSON {id: "1", name: "Holden Caulfield"});
CREATE (n:GPE {id: "2", name: "New York City"});
MATCH (a {id: "1"}), (b {id: "2"})
CREATE (a)-[:LOCATED_IN]->(b);This function ensures each node has:
- A label based on the extracted entity type.
- Properties such as
idandname. - Relationships connecting nodes via their
idfields.
Step 9: Execute the Queries in Memgraph
Before inserting data, we need to connect to Memgraph. If you’re starting with a fresh graph, you can delete existing data by running a MATCH (n) DETACH DELETE n query.
from neo4j import GraphDatabase
# Initialize the Neo4j driver for Memgraph
driver = GraphDatabase.driver("bolt://localhost:7687", auth=("", ""))
# Function to execute queries
def execute_queries(driver, queries, delete_existing=False):
with driver.session() as session:
if delete_existing:
session.run("MATCH (n) DETACH DELETE n") # Clear existing data
for query in queries:
session.run(query)
# Execute queries
queries = generate_queries(entities, relationships)
execute_queries(driver, queries, delete_existing=True)Verify Data in Memgraph Lab
After executing the queries:
- Open Memgraph Lab via the desktop app or navigate to
http://localhost:3000in your browser. - Check the node and relationship count to confirm the data was successfully inserted.
Step 10: Visualize the Graph
To visualize the graph, use the following query in Memgraph Lab:
MATCH (n)-[r]->(m)
RETURN n, r, m;This query retrieves all nodes and relationships in the graph. Since we only have a two-sentence example, the graph will probably contain only a few nodes, but it will grow with the larger the text provided.
Explore and Analyze the Graph
At this stage, you can:
- Run additional Cypher queries to analyze the graph.
- Apply algorithms for insights like centrality or community detection.
- Generate the graph schema for further exploration.
Memgraph Academy
If you want to know more about data modeling, check out a few short and easy-to-follow lessons from our subject matter experts. For free. Start with: