
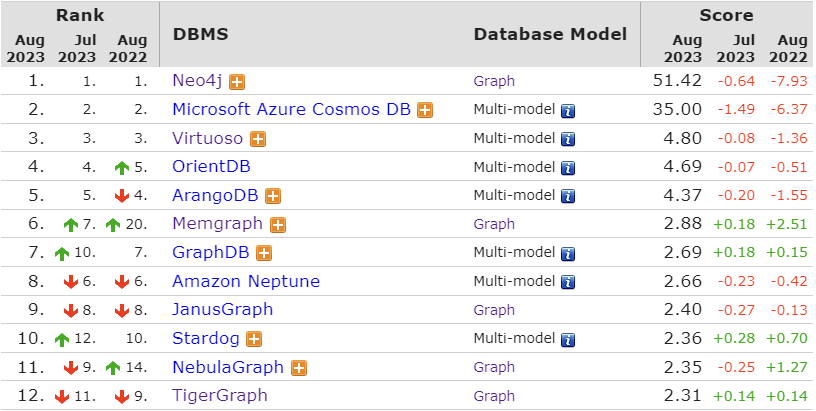
Memgraph vs. TigerGraph
In today's data-driven world, the necessity to process and interpret complex relationships within massive datasets is making organizations continually search for the go-to graph database, leaving the traditional relational database options behind. After the initial DB-Engines consultations, two names commonly arise in conversations: TigerGraph and Memgraph.
Background on both solutions
Founded in 2012 by Dr. Yu Xu, TigerGraph's core objective is to provide a scalable and efficient graph database platform that enables organizations to leverage the power of interconnected data, supporting applications ranging from fraud detection to AI and machine learning.
Memgraph is an in-memory, open-source graph database with roots in the UK and Croatia. Founded by Marko Budiselic and Dominik Tomicevic in 2016, and backed by American investors, Memgraph prioritizes high performance and developer accessibility. With a robust community edition, the platform offers a blend of ease of use and practical functionality, all presented through clear and uncomplicated licensing, making it the backbone of many cybersecurity solutions.
Memgraph vs. TigerGraph differences
Although both TigerGraph and Memgraph have been developed in C++ and aim to provide performant solutions for real-time data analytics, there exist some important differences between the two platforms that set them apart. Let’s check what those are.
Query language
The choice of query language plays a significant role in the overall user experience.
GSQL, TigerGraph's proprietary query language, does offer an expressive, Turing-complete language tailored for graph pattern-matching and analytics functions but might present a steeper learning curve for those new to graphs. It has been specifically designed for TigerGraph, and the skillset may not be easily transferred from or to other graph database platforms.
In contrast, Cypher query language is an open-source, declarative language known for its user-friendly syntax. Cypher's human-readable style has propelled it into a standard for querying graph databases. It has been developed by Neo4j but is utilized by various systems, including Memgraph. Due to its simplicity, and broad community support, it is a preferred choice for many developers who know their applications will need minimum changes if they require a switch to another database vendor.
Data storage
TigerGraph and Memgraph offer distinctive approaches to handling data in their graph databases, each reflecting a unique strategy to balance performance, scalability, and flexibility.
TigerGraph employs a hybrid memory-disk approach, leveraging RAM for storing frequently accessed data and disk storage for large graphs that may exceed available memory. This hybrid model allows TigerGraph to achieve real-time analytics, where active datasets are immediately available, while also scaling to handle massive datasets without being constrained by RAM.
In contrast, Memgraph's architecture has been built natively for in-memory data analysis and storage, focusing on lightning-fast data processing. Being ACID compliant, it ensures consistency and reliability in its core design. However, Memgraph also offers flexibility. An analytical storage mode that bypasses ACID compliance is available, accelerating analytics and data import operations when absolute consistency is not required. Additionally, an on-disk storage option allows users to weigh performance against budget constraints, thus achieving a balance tailored to specific needs.
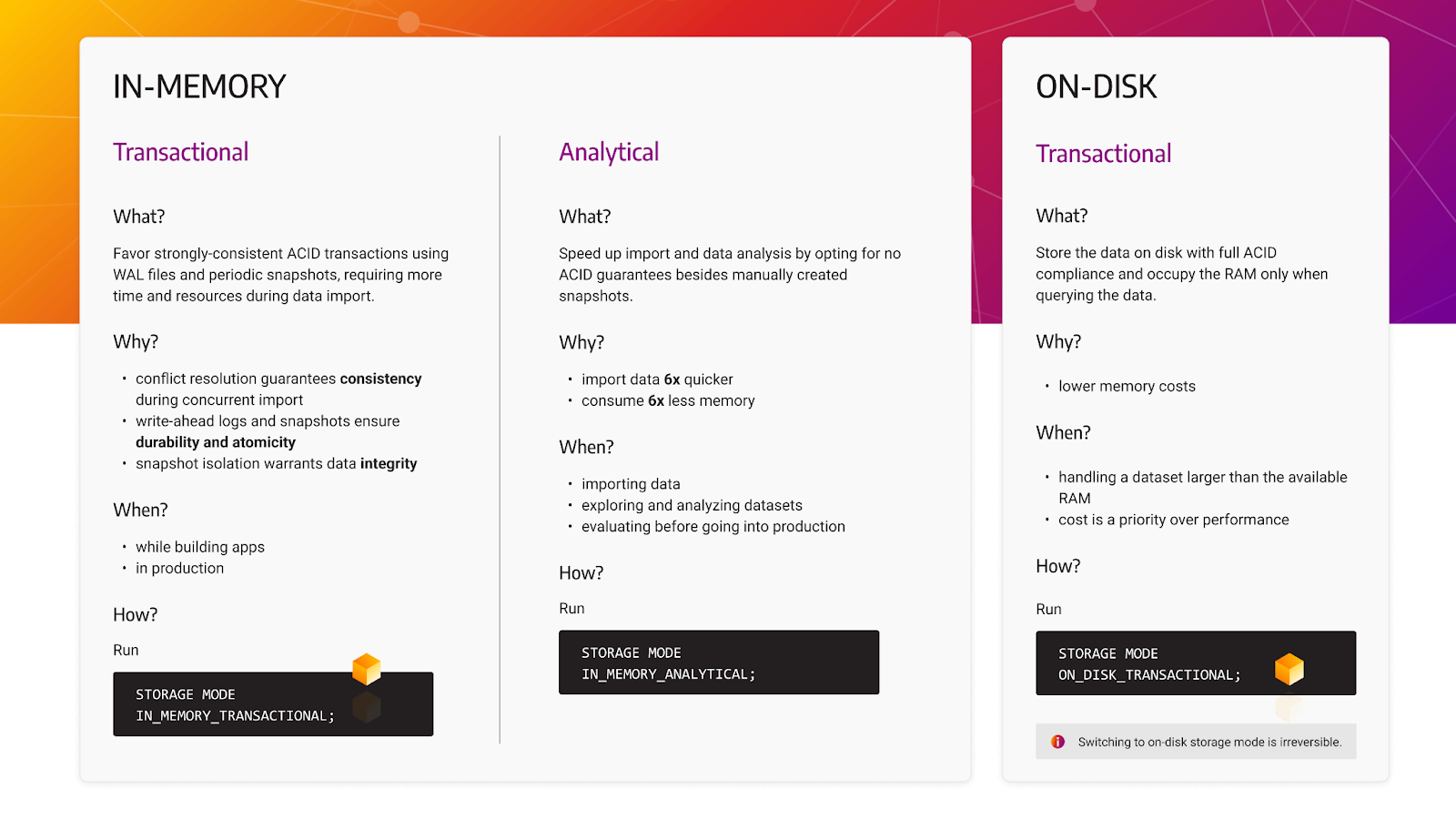
While TigerGraph's hybrid approach offers a comprehensive solution for both speed and scalability, Memgraph's focus on in-memory processing with adaptable options reflects a commitment to performance with versatility to suit various requirements. The distinction between these two models shows the innovation in graph database technology, catering to diverse needs in data management, analysis, and storage.
Data isolation level
TigerGraph employs a read-committed data isolation level, meaning that a transaction can access data which is committed before and during this transaction’s execution. For example, two same READ queries inside one transaction can return different results because between them another transaction was committed.
On the other hand, Memgraph uses snapshot isolation by default, where each query operates on a consistent snapshot of the data at the query's start time, with the option to change the isolation level, but snapshot isolation offers an advantage as it provides a more consistent view of the data, reducing the chance of reading partial or uncommitted changes. This ensures more accurate query results and a smoother transaction experience, making snapshot isolation generally considered a more reliable approach in many scenarios.
Pricing models and support
TigerGraph has a free version that allows users to work with up to 50GB of data, making it suitable for small projects or initial exploration. Memgraph offers something different with its Community Edition, which is not only free but also open-source and packed with features.
For example, both TigerGraph and Memgraph offer high availability features to ensure that data is consistently accessible and resistant to failures, but Memgraph's replication is available even in the Community Edition of the product. This means that the Community Edition is not "crippleware" but a fully functional version that allows users to "kick the tires" on the product and properly test it to ensure it meets requirements before deploying it in a production environment.
By offering this, and a plethora of other features in the Community Edition, Memgraph not only shows a commitment to performance and reliability but also to accessibility, empowering users to explore and validate the capabilities of the software without barriers.
Due to the lack of complicated layers of management that some larger companies might have, in Memgraph you can talk directly to engineers if you have questions or need help. It's a more hands-on, direct way of working that puts you closer to the people who built the product, and it can make working with Memgraph a more pleasant and efficient experience.
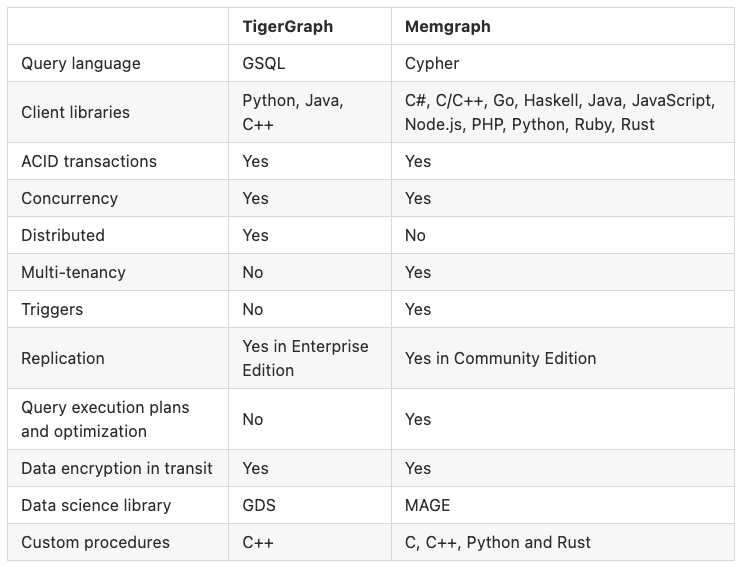
Overview of features
Takeaways on both graph databases
Memgraph and TigerGraph both offer graph database solutions, but Memgraph's native in-memory design sets it apart. Built for speed without losing stability or ACID compliances, Memgraph provides efficient real-time querying and analytics. Although TigerGraph claims to be "The World’s Fastest Graph Analytics Platform for the Enterprise", clients have reported increased performance after switching to Memgraph. If speed, reliability, direct interaction, and support from engineers are key priorities, Memgraph may be the more appealing choice.
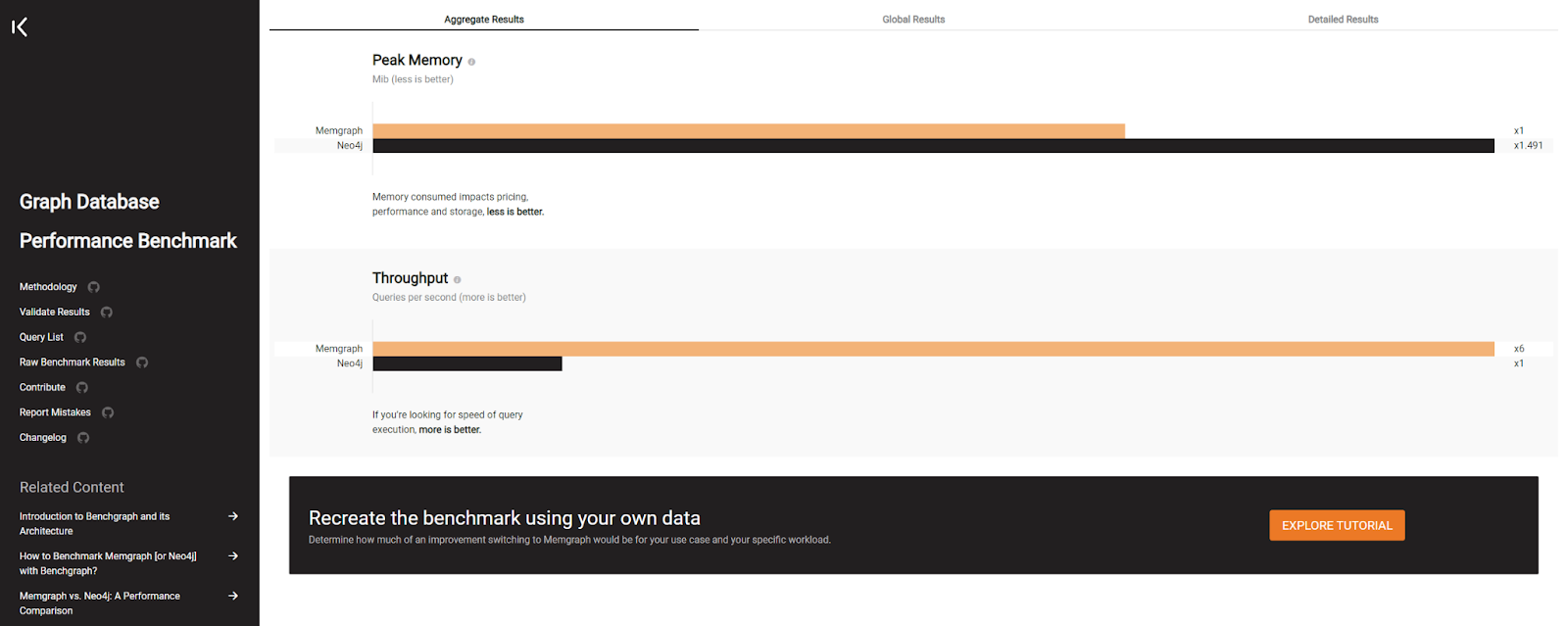
Check the performance of Memgraph on your own dataset using Benchgraph, a graph database performance benchmark, and feel free to contact us about making the switch.