
Who Ranks Better? Memgraph vs NetworkX PageRank
NetworkX is an impressive tool for many Python developers who enjoy researching data networks. An important part of that research are graph algorithms. There are various graph algorithms out there, and they all perform differently, depending on their implementations and the scale of the dataset being analyzed. NetworkX’s pure Python implementation is easy to use for any Python developer. Still, when it comes to the biggest NetworkX challenges, issues with scaling and the need for persistence when working on applications in production, Memgraph saves the day.
Memgraph is an open-source in-memory graph computation platform for static or real-time graph analytics. It holds a set of highly optimized graph algorithms implemented in C++ and also offers the possibility to create custom procedures in Python, C/C++, or Rust. Read how to explore your NetworkX graphs with Memgraph to understand the benefits of using Memgraph compared to NetworkX.
One of the most popular graph algorithms is the PageRank algorithm, used initially by Google Search to rank web pages in their search engine results. There are many implementations of PageRank out there, and NetworkX and Memgraph have theirs. Let’s find out which one is faster on a sample dataset!
The dataset
Both the NetworkX and Memgraph PageRank can and will be run from Memgraph because in Memgraph the Cypher query language can be expanded with Python procedures. In one of the procedures, we will utilize the NetworkX library.
Memgraph’s visual interface, Memgraph Lab, has a collection of datasets that can be used for various graph experimentations and explorations. The dataset chosen for this comparison is the Wikipedia articles dataset made out of 78,181 nodes and 310,227 relationships. The Wikipedia articles dataset can be imported into the database from the Datasets section.
A graph data model of the Wikipedia articles dataset can be generated in the Graph Schema section to understand better how the nodes and relationships interact with each other in the dataset.
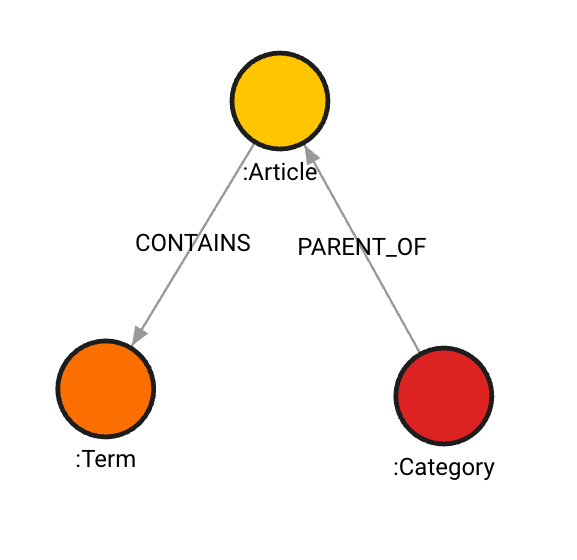
The Wikipedia articles dataset is large enough to obtain significant results to compare Memgraph’s and NetworkX’s PageRank algorithms. Comparison can be made on much larger datasets, but NetworkX eats up memory pretty fast, and those kinds of use cases are where Memgraph would, without a question or need for testing, be a better choice.
Custom query module
Memgraph is integrated with NetworkX, which means it can transform NetworkX graphs into Memgraph graphs, along with the set of NetworkX algorithms and algorithms that utilize the NetworkX library. NetworkX algorithms inside Memgraph are optimized for the best performance and run on Memgraph DiGraph objects.
A custom query module allows us to run the NetworkX PageRank algorithm on the NetworkX DiGraph object instead of running it on the Memgraph DiGraph object for a fairer comparison. A custom query module can be developed in the Query Modules section by creating a new module. Names are given per preference, and we called this the query module measure.
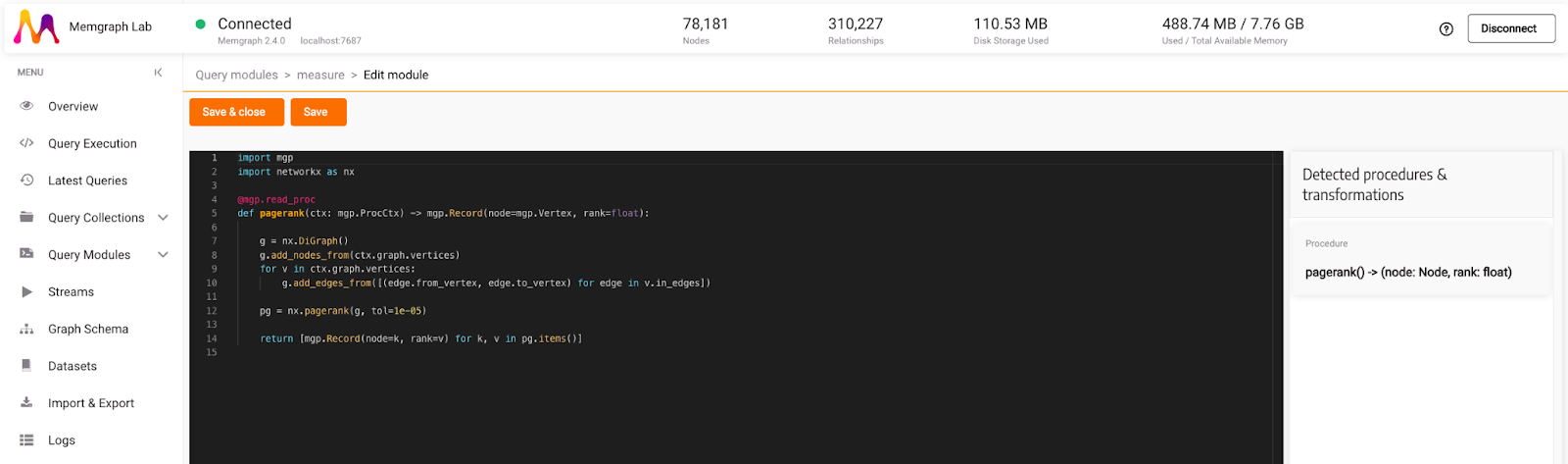
Below is the code for the custom query module used for the comparison:
import mgp
import networkx as nx
@mgp.read_proc
def pagerank(ctx: mgp.ProcCtx) -> mgp.Record(node=mgp.Vertex, rank=float):
g = nx.DiGraph()
g.add_nodes_from(ctx.graph.vertices)
for v in ctx.graph.vertices:
g.add_edges_from([(edge.from_vertex, edge.to_vertex) for edge in v.in_edges])
pg = nx.pagerank(g, tol=1e-05)
return [mgp.Record(node=k, rank=v) for k, v in pg.items()]In the query module, procedure pagerank extracts a graph from the context and creates an instance of NetworkX DiGraph. Then, the NetworkX PageRank algorithm is run on that DiGraph.
Procedures from custom query modules are run from the Query Execution section. The pagerank() procedure from the measure query module is called with the following Cypher query:
CALL measure.pagerank() YIELD node, rank;
If you are interested in developing custom query modules with Memgraph, head to our documentation and learn more about it.
The comparison
In order to get the best comparison, Memgraph’s get() procedure is called from the pagerank module and the custom procedure pagerank() from the measure module. The number of return results is limited to 1 because if the results are filtered or not limited, the unnecessary time would be counted in.
Below are the results for Memgraph’s PageRank on the Wikipedia articles dataset:
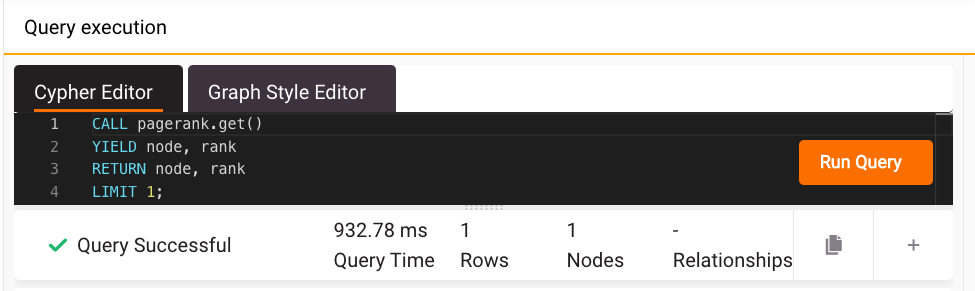
And here are the results of NetworkX’s PageRank on the same dataset:
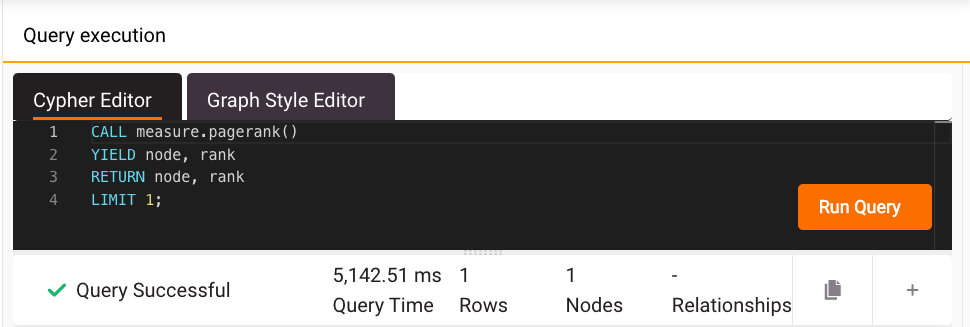
Memgraph is more than 5 times faster than NetworkX in performing the PageRank algorithm on a graph of Wikipedia articles dataset scale (78,181 nodes and 310,227 relationships)!
It’s important to note that Memgraph outperforms NetworkX on a larger scale without question due to its C++ implementation and highly optimized storage memory usage. PageRank is just one example of a graph algorithm that Memgraph offers out of the box. For more, check out the list of available query modules.
Another thing worth mentioning is that Memgraph supports dynamic graph algorithms, which can speed up the graph analysis even more! For example, with dynamic PageRank and a stream of data, Memgraph gives you newly updated results as soon as the graph object is consumed, that is, created in the database. For real-time use cases, such as credit card fraud detection, and that’s where Memgraph shines the best.
Conclusion
Due to its optimized storage memory usage and implementations of graph algorithms in C++, Memgraph handles graph computing on large datasets better than NetworkX, as shown by running PageRank algorithm on a dataset of 78,181 nodes and 310,227 relationships which Memgraph handled 5 times faster than NetworkX. And as the dataset size increases, so does the Memgraph’s speed compared to NetworkX. When deploying the application, the fact that Memgraph is a persistent storage, includes fast graph algorithms and easily connects to external data sources, helps a lot. It's finally time to say farewell to the boilerplate code!
If you want to check more examples and comparisons, head over to the music social network tutorial for betweenness centrality comparison or social network analysis tutorial to learn more about community detection.
For more resources, visit the Memgraph for NetworkX developers website.