
New Memgraph Platform for Another Year of High Performance Graph Analysis
New year is an excellent time to make new decisions, so this year make better decisions by the knowledge you gain from using Memgraph! A new year calls for a new Memgraph Platform - a combination of Memgraph graph database, graph visualization tool Memgraph Lab and graph algorithm library MAGE.
Memgraph v2.5
There are several new features on the Memgraph side.
DISTINCT operator
Most notably, Memgraph can now execute DISTINCT within aggregate functions like count due to popular demand and we like to see our users happy. If you need any help, ask Memgraph by specifying -h runtime flag.
For example, you can count distinct values using the following syntax RETURN COUNT(DISTINCT n.prop).
Initialization before and after server startup
There are some new features to improve security, as well.
Have you ever wondered how to initialize Memgraph before starting the server? With --init-file it's possible to execute any number of Cypher statements before the server is up. The intention of --init-file is to initialize Memgraph with the initial set of users or schema-related rules.
On the other hand, --init-data-file is executed just after the server starts, mainly to import data. Since the server is started before the data import, other users and concurrent clients can query data.
If you only need to initialize the admin user, you can use new MEMGRAPH_USER, MEMGRAPH_PASSWORD and MEMGRAPH_PASSFILE environment variables.
For example, you can set up the admin user with the following Docker command running the Memgraph Platform:
docker run -it -p 7687:7687 -p 7444:7444 -p 3000:3000 -e MEMGRAPH_USER=admin -e MEMGRAPH_PASSWORD=password memgraph/memgraph-platformPerformance benchmarking
A huge addition to the codebase is a new version of mgBench, Memgraph's benchmarking suite, the goal of which is to provide accurate insights on how Memgraph is performing on metrics like latency, throughput and memory usage.
You can check the results on the BenchGraph Platform.
Bug fixes
Last but not least, let's mention some important bug fixes. A bug was fixed that would cause the Go Bolt client to get stuck on a query if there was no RETURN clause because the query results were not exhausted. On the imperative code side, the Python query modules reload was significantly improved in the case when the underlying dependencies were changed. In the C++ query module API, various bugs and memory issues were fixed.
For the full list of changes, please take a look at the Memgraph changelog.
Memgraph Lab v2.4
The most significant feature developed in the new Memgraph Lab is full transaction support. It is now possible to execute multiple queries from a single transaction wrapped in BEGIN and COMMIT (or ROLLBACK if the transaction should be aborted) commands.
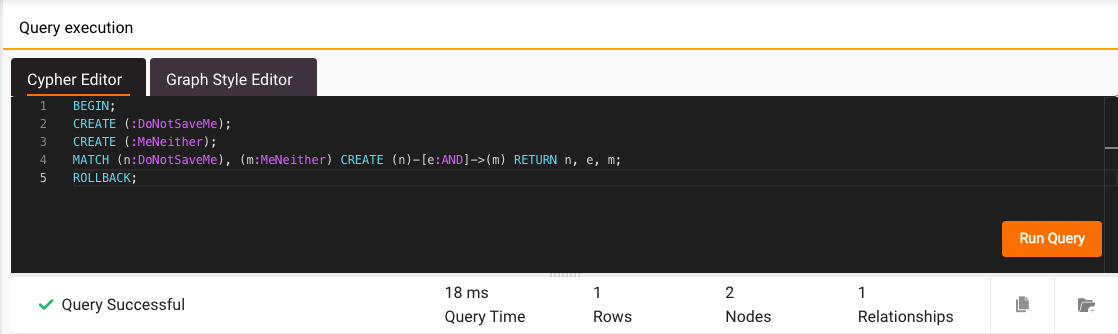
In Memgraph v2.4 graph projection feature was added, but there was no proper support for the projected graph visualization because the projection result is returned as a list of nodes and edges. That’s improved now, because Lab automatically knows how to detect, unpack and visualize the projected graph.
As always, each Memgraph release brings some new Cypher clauses or functions to the engine. Memgraph Lab follows with the code suggestion support so that it’s easier to write queries.
The whole list of new code suggestion capabilities is available in the Memgraph Lab changelog.
Memgraph MAGE 1.4
The new version of Memgraph’s open-source graph algorithm library MAGE focused on machine learning. The new machine learning capabilities enable support in various use cases:
- Fraud detection using node classification based on PyTorch Geometry.
- Building a better recommendation engine for telecom providers using link prediction with DGL.
- Identifying social network communities with k-means clustering.
MAGE 1.4 also offers support for algorithms from the igraph library. Also, you no longer have to worry about memory allocations and custom interfaces, because the new C++ API enables easier implementation of custom algorithms. Check out the MAGE changelog for more information.
Download or sign-up
All of these features are available as Memgraph Platform you can download and install on-prem, or sign up for Memgraph Cloud with a 2-week free trial period.
As Memgraph versions have been bumped more often recently, it makes more sense to introduce unified versions across all Memgraph products to track compatibility. The tradeoff is on the release side because all the releases have to be synced, but since we overall increased the frequency of releases, the release sync overhead should be minimal. Tell us what you think about this unification, and do you use Memgraph products separately or download the Memgraph Platform for smooth sailing at our Discord server! We’ll be happy to hear from you!