Get a Feature-Rich Open-Source Community Edition Graph Database Ready for Production
In recent years, open-source projects have surged in popularity, offering solutions for many business challenges. The graph database field, though relatively new, has embraced this trend, with most projects starting as open-source, giving users free access to cutting-edge technology.
However, building a robust graph database requires significant resources. To sustain development, many companies offer both a free community version and a paid enterprise version, with the latter including advanced features like enhanced security and scalability.
When choosing a graph database, it's crucial to determine which features are essential for your use case and whether they are available in the free version or only in the enterprise edition. This blog post will focus on comparing Memgraph and Neo4j, two compatible graph databases that use the Bolt protocol and Cypher for queries, making it easy to switch between them. Both offer community and enterprise editions, and we'll explore how they stack up against each other.
Read more:
- Memgraph vs. Neo4j: Benchmark Performance Comparison
- Memgraph Key Advantages over Neo4j
- Memgraph Benchmark Results
- Memgraph Is Enterprise-Ready
Production-Ready Database
To call a database production ready, it needs to have several core features. The first and most important feature is ACID transactions, where ACID stands for atomicity, consistency, isolation, and durability. ACID transactions ensure that your database is executing queries properly. This means that your graph data won’t be compromised by incomplete transactions and left in a corrupted state. To avoid getting into extreme engineering details about each ACID property, this means your database has basic engineering prerequisites to be called a database.
The other basic feature or prerequisite is persistence. It ensures that your database is saving data and its current state to permanent memory storage, which means that losing power on your database server won’t lose any data. These two properties are not the only important ones, but each production-ready database needs to have them.
Obviously, both Memgraph and Neo4j support ACID transactions. Neo4j being an on-disk database, is, by design, a persistent database. Memgraph is an in-memory graph database, so it does periodic snapshots that are stored in permanent memory, which enables persistence.
After the database is capable of doing ACID transactions and being persistent, other features are highly dependent on the specific use case that you need, and those features will define if you need an enterprise or community version of the database for production. For a production environment, you should probably deploy an enterprise version of the database, right? Well, not really. It depends on what database features are included in the community versions.
Memgraph and Neo4j Community Editions Compared
Both Memgraph and Neo4j are open-source vendors that provide a lot of value to graph communities. Building great products and making them available to the community comes at the cost of operating expenses. That is why both vendors provide enterprise editions of their graph database. Enterprise editions usually contain most of the features that are needed for more scalable and demanding use cases. Both Memgraph and Neo4j come with their own set of enterprise features, which mainly focus on security, such as LDAP integration, activity auditing, role-based authorization etc.
Obviously, using a community version of the database is cheaper for you. This can be crucial for small companies and startups that need a performant graph database but don’t have bucks for the enterprise edition. Below are several features that differentiate Memgraph and Neo4j community editions. Some of them might be very important for your use case, and some of them less important, but they are all very universal to any graph solution.
High Availability
Running any software these days needs to provide some agreed-upon and universal availability claims, such as 99.99% uptime per year. These constraints and values can differ from project to project, but deploying any database in production without the supported features for high availability is not recommended for critical infrastructure projects.
There are several different ways to achieve high availability, one of them being replication. Implementations of replication can be done in several different ways, but concepts and benefits are similar. Some of the benefits that come with replication are the following:
- high availability,
- server load balancing,
- data reliability,
- disaster recovery,
- lower query latency.
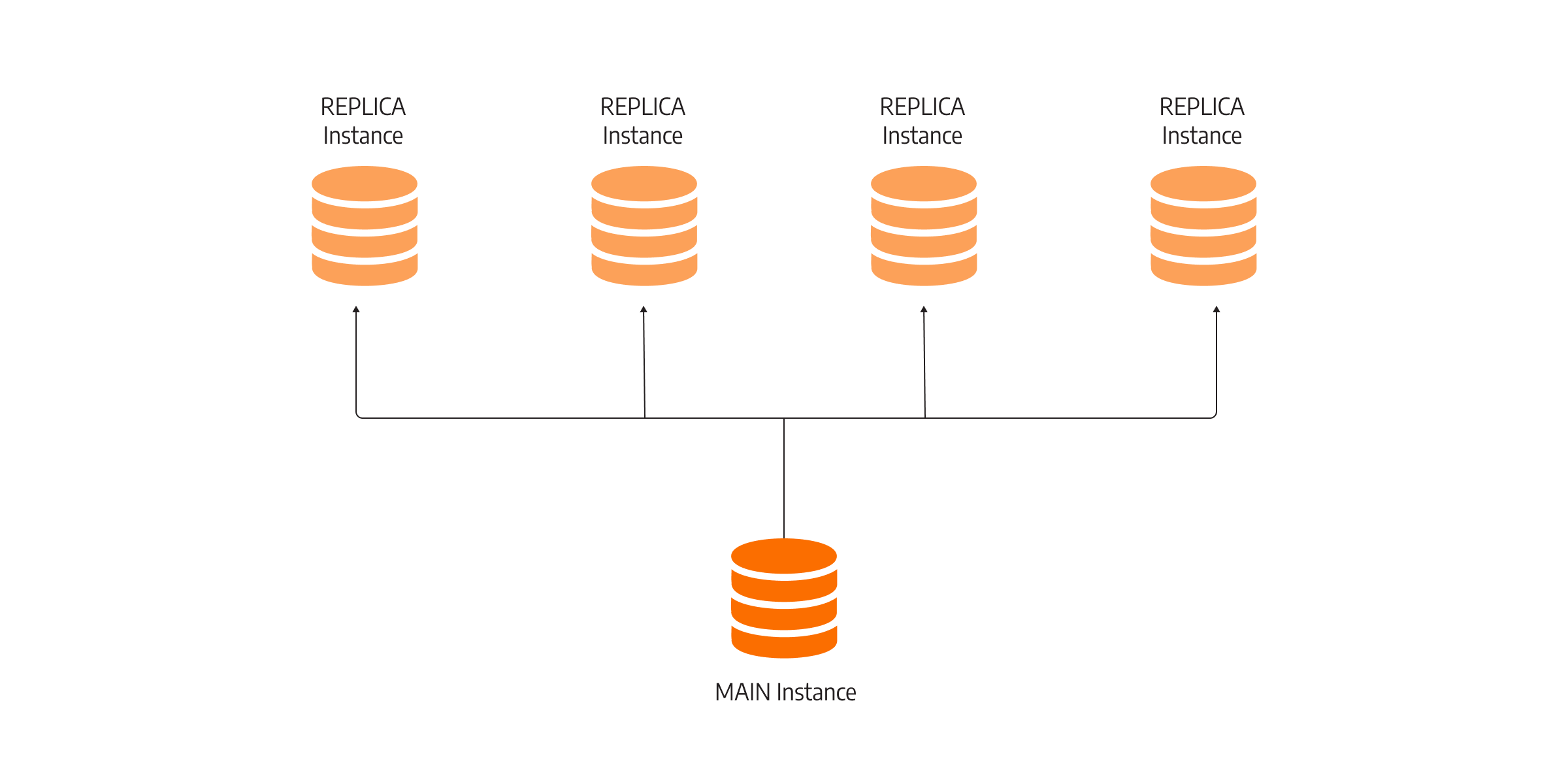
Database replication is the process in which the main database instance sends changes or updates to the database replicas. In usual configurations, each database instance is located on a different server. If, for any reason, the main database instance fails, another secondary backup server with a replica of the database will take care of the upcoming requests. There can be multiple replicas of the main instance, depending on the implementation and redundancy requirements. This also means that if multiple servers have a hardware failure, you will not lose your data.
Replication can be a bit of a complex topic that is out of the scope of this blog post. But the important thing is that running replication and syncing data between different servers leads to many benefits, one of them being high availability, that will ensure that your services are always up and running. This is especially important for critical infrastructure applications.
This brings the discussion back to Memgraph and Neo4j community editions. Neo4j community edition does not support replication of the database. This feature and other features regarding multiple database instances are part of clustering features under the enterprise edition of Neo4j. If your data in a community edition is stored on a single instance of Neo4j, it is vulnerable to any type of server failure. Memgraph does support replication, and in the community edition, you can run replication on a cluster of Memgraph instances.
Read more:
Performance
One of the most important aspects of running any database system is performance. It affects every graph project and application built on top of the database. You want your graph database to be performant as possible so you can build fast and reliable applications on top of it. Graph databases thrive on complex analytical workloads, so if you are building real-time streaming applications, performance is a must from the get-go.
Memgraph community edition is quite performant as it can run up to 120 times than the Neo4j community edition. The key here is that Memgraph’s performance doesn’t differ between community and enterprise editions. If you run a small business and want a performant graph database out of the box, Memgraph’s community edition offers it for free.
On the other hand, the situation with the Neo4j community edition is a bit more complex. As mentioned on their official website, the enterprise edition benefits from the faster Cypher, which should run queries from 50% to 100% faster on the enterprise edition. This means faster queries are not supported on the community edition of the database.
Even though it’s an on-disk graph database, Neo4j is able to cache a lot of graph data to RAM. It does so to improve performance and avoid costly disk access. In order to benefit from that performance, you need to per-warm the database cache by executing various different queries and just giving it time. Without this pre-warm procedure, Neo4j will perform quite poorly.
Once Neo4j is warmed, it should not be turned off or restarted since that will empty the cache. There is an automatic warm-up feature and automatic re-heat after a restart, but they are limited to the enterprise edition. In the community edition, you will need to crank it up manually to get some performance boost.
Also, some Neo4j community versions have 4 CPU core limits, but it is unclear from the documentation which components are affected by these limitations. All in all, the Neo4j Community Edition restricts performance, while Memgraph offers full performance for both editions of the database.
Data Science on Graphs
Since community editions are oriented towards small and medium-sized companies with humble R&D budgets, it’s useful to know that both Memgraph and Neo4j have a library of supported algorithms. Neo4j’s Graph Data Science library (GDS) and Memgraph Advanced Graph Extensions (MAGE).
Both libraries are open-source and contain various graph algorithms such as PageRank, community detection algorithms, etc. These out-of-the-box solutions save users time in developing common algorithms. They are usually hard to understand and write.
But, there are some differences regarding supported algorithms and how they are implemented. In the Neo4j community edition of GDS, you can execute algorithms on just 4 CPU cores. Enterprise edition lifts the CPU limit. On top of that, Neo4j GDS with enterprise license benefits from optimized graph implementations, which are not present in the community edition. With Memgraph MAGE, there are no CPU restrictions, and all algorithms perform in their optimized, native form without restrictions.
Property Constraints
One of the features you will probably need is property constraints when creating nodes and relationships. This feature ensures the presence of a property. Having a node representing a person but without a name or last name properties doesn’t make much sense. In the community edition of Neo4j, you cannot create a property constraint on a node or relationship, it’s an enterprise feature. Memgraph’s community edition does not have that or similar Cypher restrictions.
Memgraph and Neo4j have some cool and useful features in the community version. Not all features are present in both cases, so you should check your own set of requirements for the project. Mentioned features above are just some of the general features that could be universally important to any graph project.
Cost of Ownership
Both databases are open-source community editions and are available to the public for free, so there is no direct cost to using them. But, what you need to pay for is hosting the databases in production. If you host a database on public VMs, the hosting cost will correlate with CPU time, memory, network, and storage usage.
The bar chart below shows Memgraph and Neo4j memory usage during the execution of 4 different types of workloads:
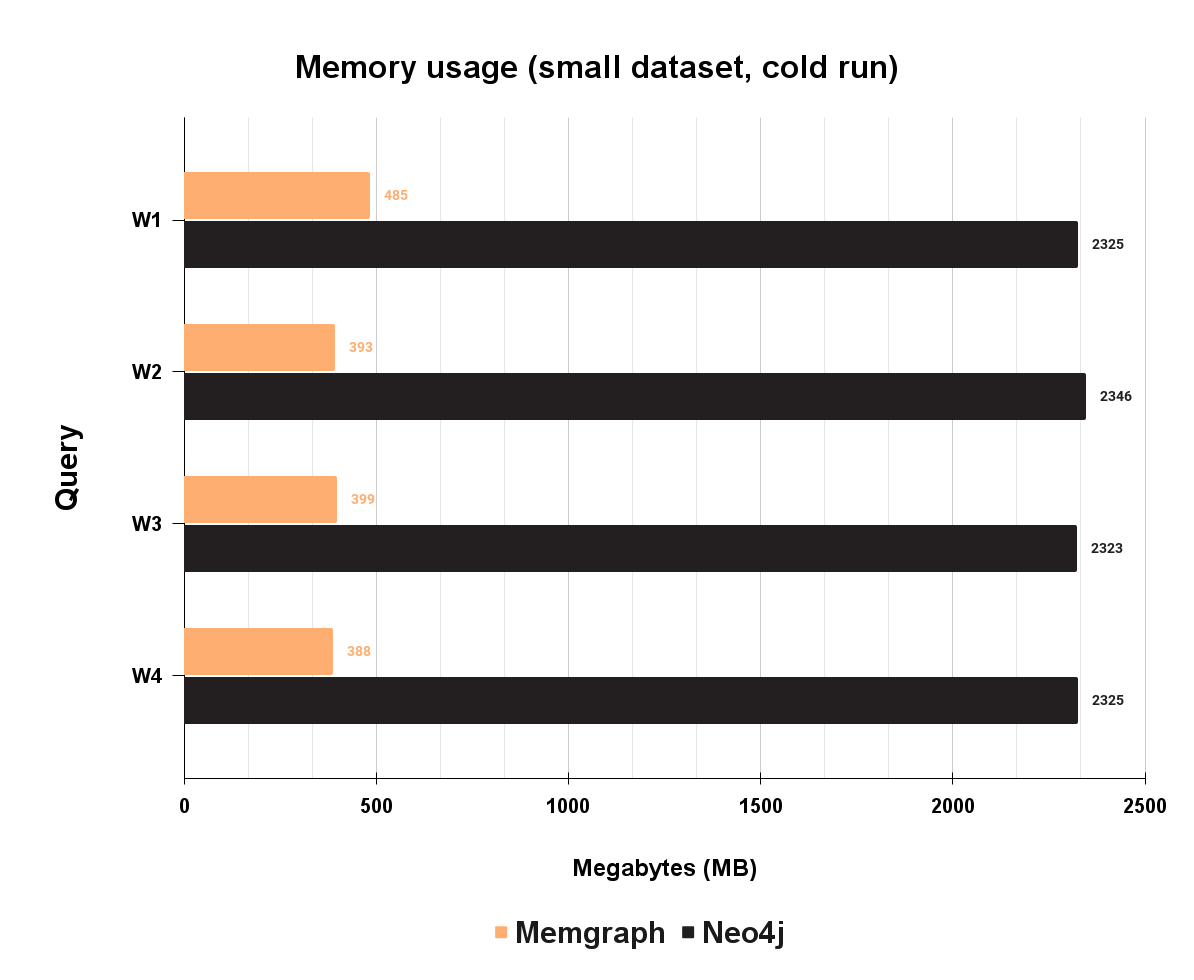
Even though Memgraph is a high-performant in-memory database, in some scenarios, Neo4j will actually consume more memory. At these four mixed workloads, Neo4j is paying the price for being based on JVM, which can have a lot of memory overhead. As seen on the chart, Neo4j uses up to 2.2GB of memory, while Memgraph uses around 400MB for the identical task. Neo4j will allocate quite large amounts of memory and use it only partially for caching, which leads to buying more expensive cloud virtual machines and making hosting more expensive.
Memory usage costs are highly correlated with replication. The downside of replication is the hosting costs of running multiple database replica instances. The hosting cost of every replica instance is identical to the costs of hosting the main instance, as they all require the same resources. As you can see, in some situations, a single instance of Neo4j can have a higher hosting cost than Memgraph, therefor running multiple instances in replication will lead to much higher costs overall. This, of course, depends on several factors, how big the dataset is, how restrictive you are about RAM usage, what AWS instance is being used, etc.
Conclusion
Having multiple choices for an open-source graph database is great for developers. When choosing which graph database to use, it comes down to supported features. As you can see, Memgraph community edition has stellar performance, supports replication to achieve high availability, and allows property constraints. Neo4j, on the other hand, is a bit more restrictive with the community edition and is less performant, but it is a company that paved the way for graph databases with a rich legacy which can sometimes be a two-sided coin.
When the time comes to make a choice, keep in mind that available features are not the only important thing. You should also consider the cost of ownership, supported visualization tools, stellar documentation, customer support, supported languages, easy-to-use APIs, etc. Memgraph as a company was started because we couldn’t find a database that would address all these issues in a satisfactory way, starting from performance to other important features, which is why these are the issues we address with extra attention.
Further Reading
- Neo4j vs Memgraph - How to Choose a Graph Database?
- Memgraph or Neo4j: Analyzing Write Speed Performance
- 3 Signs It’s Time to Switch from Neo4j to Memgraph
- Memgraph vs. Neo4j: Benchmark Performance Comparison
- Memgraph Key Advantages over Neo4j
- Memgraph as a Graph Analytics Engine
- ArangoDB vs. Memgraph