
Fine-Tuning LLMs vs. RAG: How to Solve LLM Limitations
Large Language Models (LLMs) like ChatGPT are incredible tools, but they’re far from perfect. They stumble when asked to handle your proprietary enterprise knowledge, largely because they weren’t trained on your data. This creates a dilemma: How do you make LLMs smarter and more relevant to your needs?
The two most popular solutions are Fine-Tuning and Retrieval-Augmented Generation (RAG). Let’s break down how they work, their pros and cons, and which one is right for you.
The Problem: Why LLMs Fall Short
LLMs have two big issues when it comes to enterprise use cases:
- They don’t know your data. LLMs are trained on public datasets, so they lack context about your specific domain.
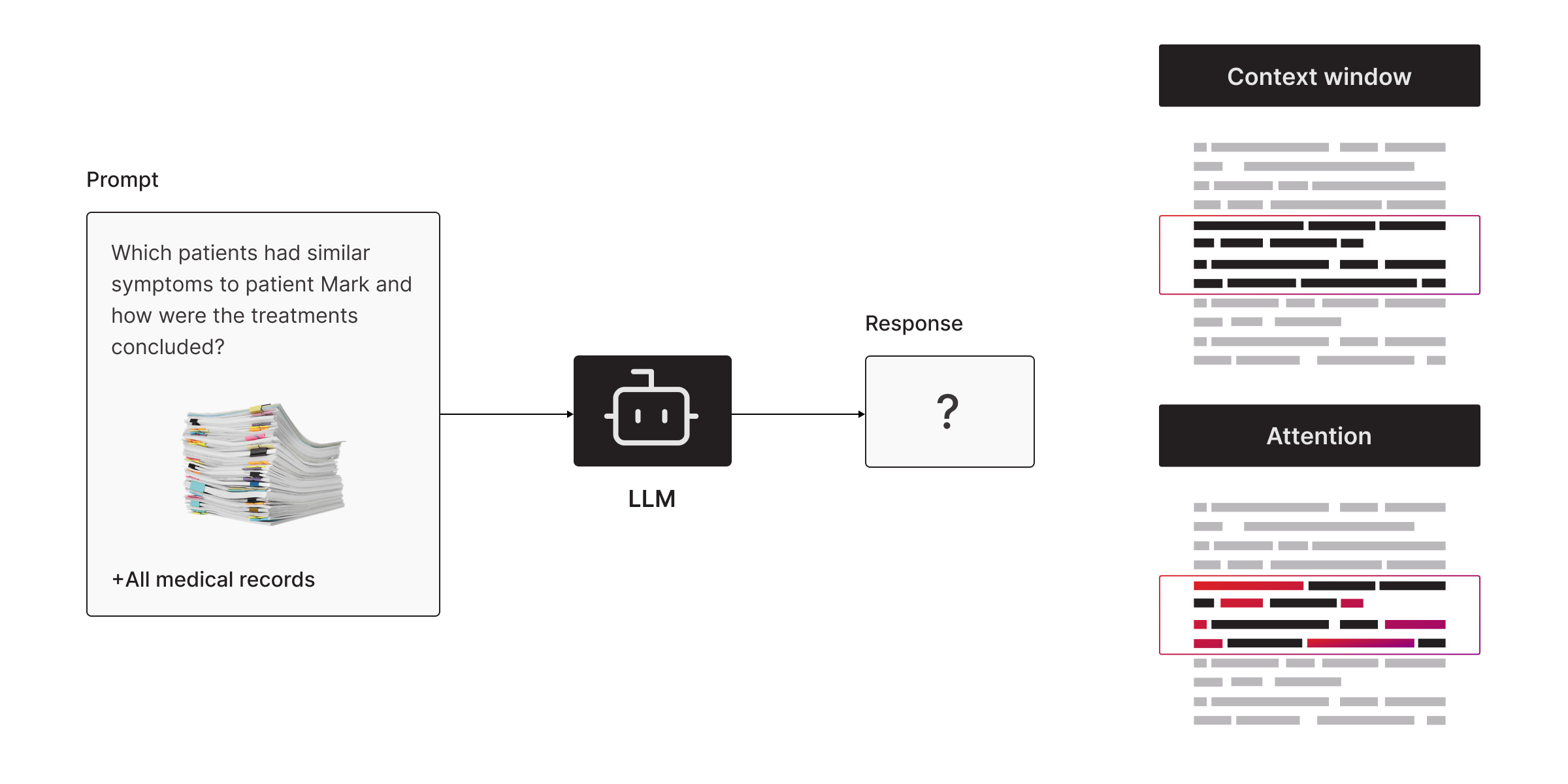
- Context limitations. Even if you feed them your data, their context window is finite—meaning they can only "see" a limited amount of text at a time.
You need a way to overcome these barriers to make LLMs useful for your enterprise.
Option #1: Fine-Tuning
Fine-tuning involves training the LLM further using your proprietary data. It essentially “teaches” the model to understand your specific domain better.
How It Works
- Take an existing LLM (like GPT-4).
- Feed it your domain-specific data (e.g., medical records, customer support logs).
- Update the model’s parameters so it “learns” to generate more accurate, relevant responses for your use case.
Watch Coding with Buda: How to fine-tune an LLM? Getting started
Pros of Fine-Tuning
Fine-tunning LLMs provides highly customized responses by making the model intimately familiar with your specific data. This customization allows the model to deliver tailored and precise outputs.
Additionally, fine-tuning leads to improved performance for repeated tasks, especially when queries follow a predictable pattern, as the model is optimized for those specific use cases. Finally, fine-tuned models can operate offline, eliminating the need for real-time access to your data once the training process is complete.
Cons of Fine-Tuning
It comes with several drawbacks that can make it challenging to implement effectively. It is expensive and resource-intensive, requiring powerful GPUs, significant memory, and considerable time for training.
Moreover, it is hard to maintain in dynamic environments where data updates frequently, as retraining the model regularly can become a logistical burden. Fine-tuning also requires deep expertise, demanding a team skilled in neural networks, hyperparameter tuning, and model architecture. The thing is, fine-tuned models have static knowledge, meaning they only know what they were trained on, and any new information must be manually incorporated through retraining.
Option #2: Retrieval-Augmented Generation (RAG)
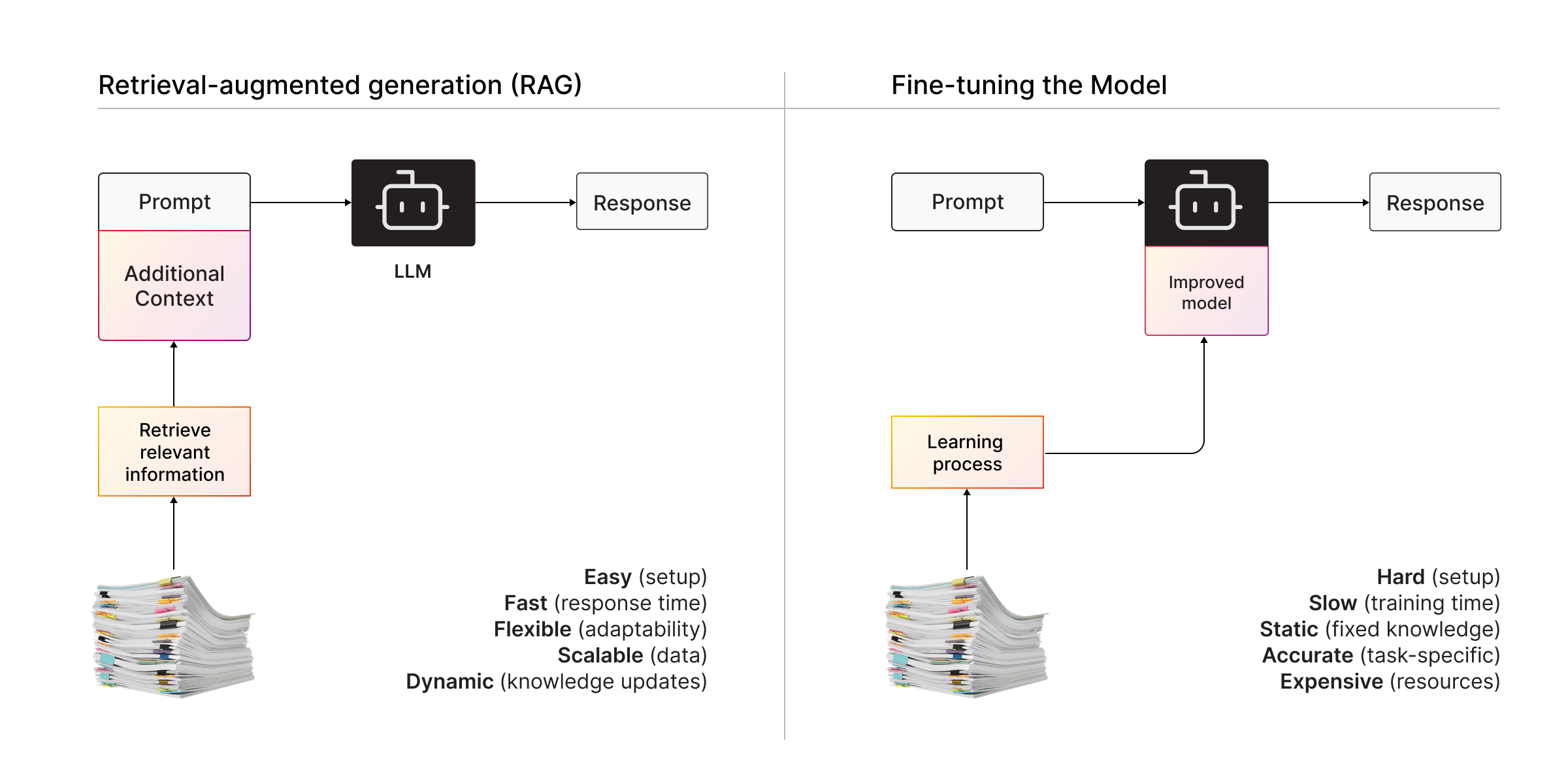
RAG takes a different approach. Instead of teaching the LLM everything, it gives the model a “cheat sheet” of relevant data to answer a specific query.
How It Works
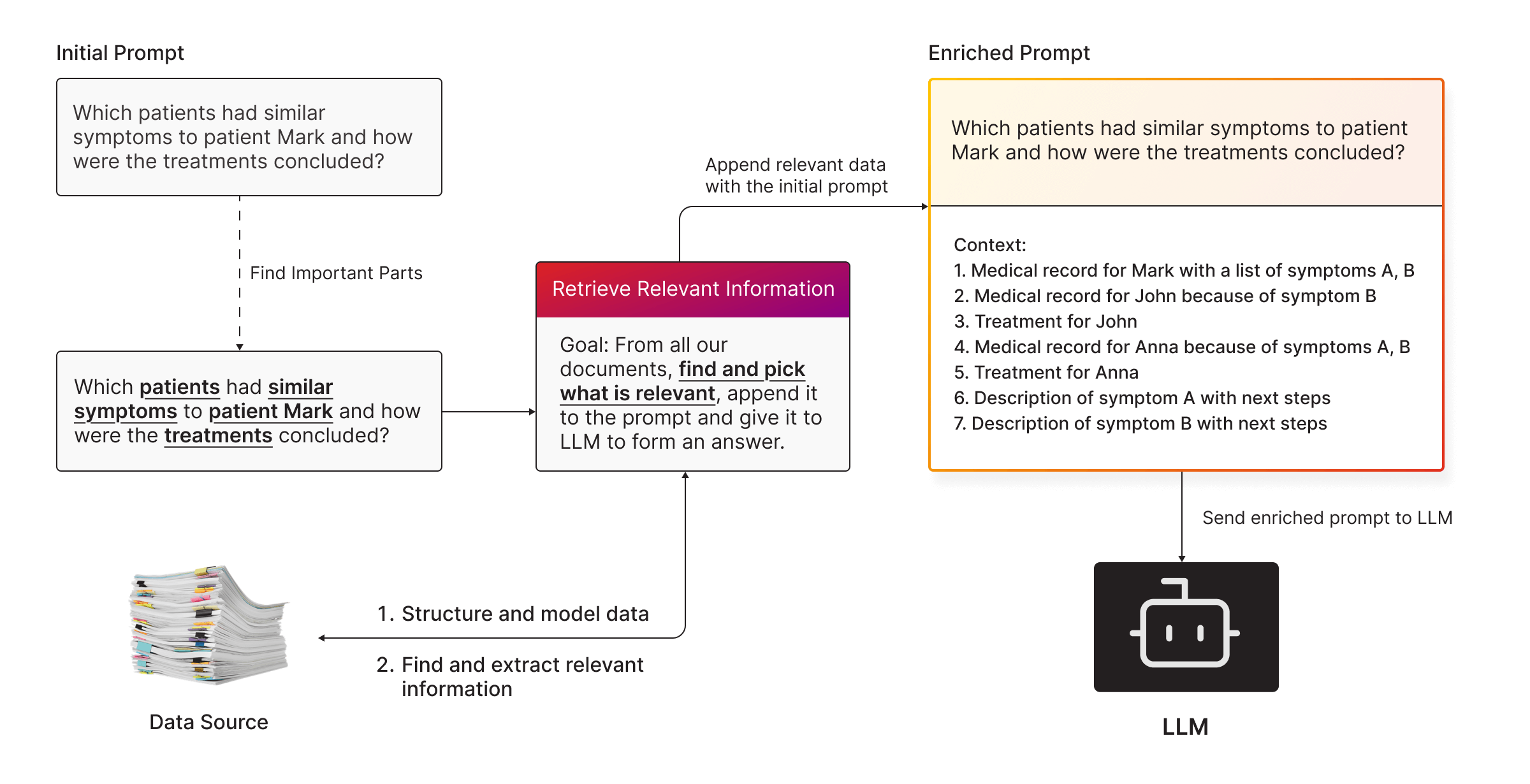
- Store Your Data: Use a graph database, vector database, or other structured data storage.
- Search for Relevance: When you ask a question, a retrieval system searches your data for the most relevant pieces of information.
- Enrich the Prompt: The retrieved data is appended to the query, giving the LLM the extra context it needs to generate a precise answer.
Pros of RAG
Its dynamic updates ensure that your data remains separate from the model, keeping information current without requiring retraining. RAG is also scalable, as it is lightweight and adaptable to growing data needs. The approach features a fast setup, making it quicker to implement compared to fine-tuning. Additionally, RAG is highly flexible, allowing you to use it with any data source or LLM, making it a versatile solution for various applications.
Cons of RAG
RAG has some limitations that can impact its effectiveness. It is dependent on data quality, meaning poorly structured data will lead to suboptimal performance. Context window limitations still apply, as the LLM can only process as much data as its token limit allows. Additionally, RAG requires integration work, as setting up and connecting retrieval systems to your LLM involves extra effort and technical expertise.
Fine-Tuning vs. RAG
| Feature | Fine-Tuning | RAG |
|---|---|---|
| Cost | High: Requires GPUs and training time. | Low: Minimal hardware requirements. |
| Setup Time | Long: Training takes weeks or months. | Short: RAG can be implemented quickly. |
| Maintenance | High: Frequent retraining required. | Low: Automatically updates with new data. |
| Flexibility | Low: Fixed to the trained model. | High: Can adapt to any LLM or dataset. |
| Use Cases | Repeated, predictable queries. | Dynamic, real-time information needs. |
When to Choose Fine-Tuning
Fine-tuning is ideal when:
- You have a static dataset that rarely changes.
- Your queries are consistent and repetitive (e.g., generating customer support responses).
- You have the budget and expertise to train and maintain the model.
For example, a chatbot trained on legal documents to provide highly specific advice based on a fixed set of laws.
When to Choose RAG
RAG is the better choice when:
- Your data updates frequently, and real-time relevance is critical.
- You need a fast, cost-effective solution without retraining the model.
- Your use cases are dynamic and vary in complexity.
For example, a healthcare system that retrieves patient data and treatment histories to answer doctors’ queries on the fly.
Read more: Using Memgraph for Knowledge-Driven AutoML in Alzheimer’s Research at Cedars-Sinai
The Best of Both Worlds
For some scenarios, combining fine-tuning and RAG offers the best results. For example, fine-tune the model to understand your domain’s terminology and basic concepts, then use RAG to provide real-time updates and context.
TL;DR
- Fine-tuning. Customizes the LLM by training it on your data. Best for static, repetitive tasks but expensive and hard to maintain.
- RAG. Augments the LLM with relevant, real-time data. Easier, more scalable, and ideal for dynamic use cases.
- Choose wisely. Pick the approach that fits your use case, budget, and technical expertise. Or combine them for maximum flexibility. If you need help, our Developer Experience team is here, reach out.
The takeaway? LLMs don’t have to work alone. Whether through fine-tuning, RAG, or both, you can supercharge their capabilities to meet your enterprise needs.