
Identify Patterns and Anomalies With Community Detection Graph Algorithm
Identifying communities in a network gains insights into its underlying structure - how the information flows and how entities are connected. It can also help identify important nodes or anomalies in the data that might be worth investigating further.
Community detection is nothing more than grouping entities based on how similar they are to each other. Although humans are great at identifying communities and patterns among a few components, when faced with a complex structure of large interconnected networks, that particular skill quickly takes a downward turn.
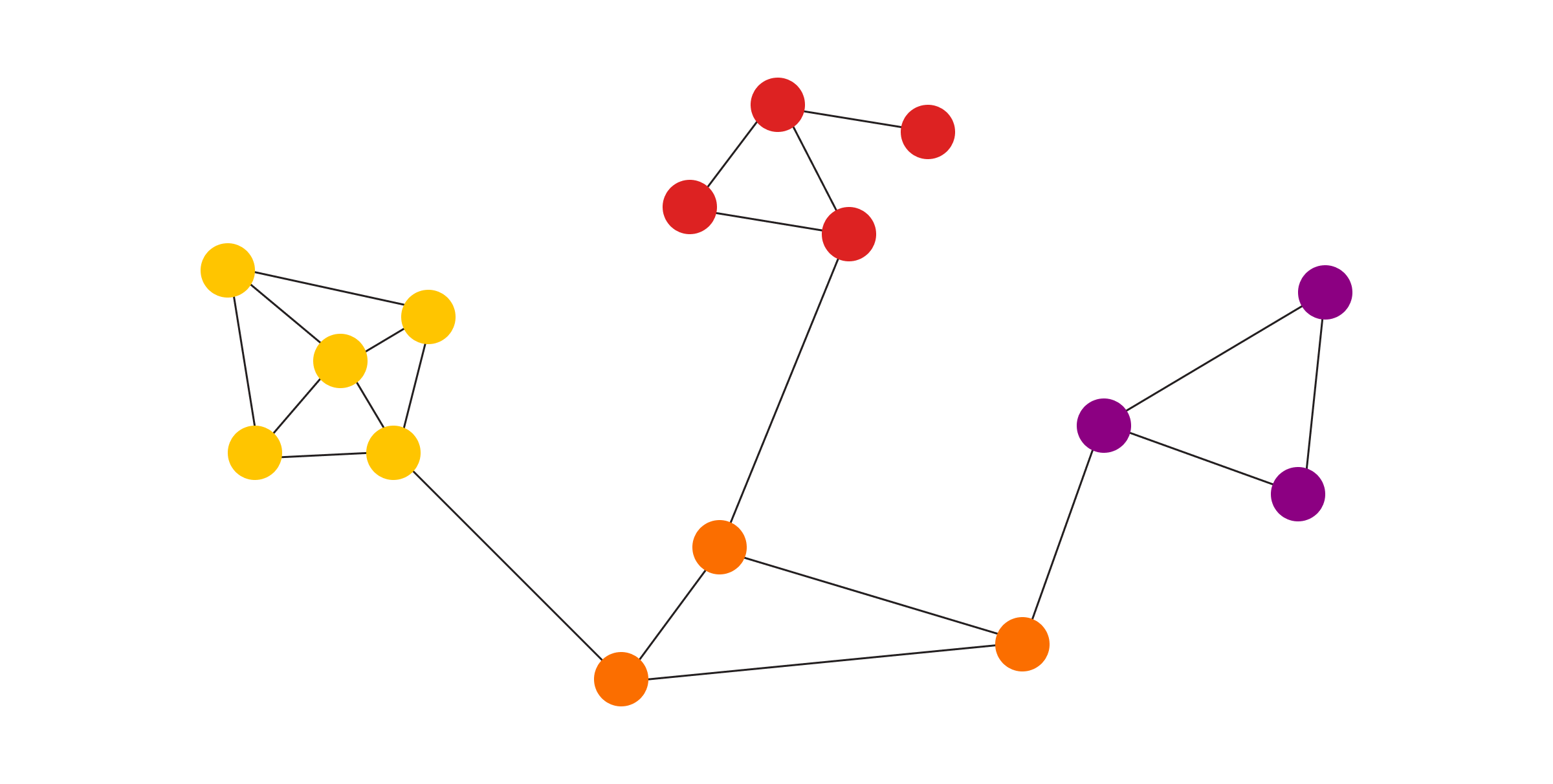
Visually identifying groups of densly connected nodes is relatively straightforward, but the same task is not easy to accomplish programmatically. That is probably a reason why there are so many community detection algorithms out there. Here is just a few of them:
Louvain method
The algorithm first finds small communities and optimizies modularity locally on all nodes. Modularity measures the relative density of edges inside communities with respect to edges outside communities. Once the modularity is optimized, the algorithm groups each small community into one node and repeats the process.This method is exceptionally fast and performes well on large graphs.
Girvan-Newman algorithm
The algorithm is based on the concept of betweenness centrality, which measures the number of shortest paths between pairs of nodes that pass through a given relationships. The algorithm iteratively removes relationships with high betweenness until communities are formed. According to M. Girvan and M. E. J. Newman, who developed this algorithm, groups of nodes in a network are tightly connected within communities and loosely connected between communities.
Infomap
This algorithm is based on the idea that information flow through a network can be used to detect communities. It assigns nodes to communities based on the likelihood of ending up in the same random walk.
Spectral clustering
The algorithm uses the eigenvectors of the graph Laplacian matrix to detect communities. It maps the nodes to a lower-dimensional space and clusters them based on their proximity in this space. Spectral clustering has been shown to perform well on large, sparse networks.
But how does grouping nodes into communities actually help solve real-world problems?
Community detection use cases
Even though community detection sounds natural in a surrounding like social networks, it’s actually very useful in almost any knowledge graph or system represented as a network.
Recommendation Engines
Community detection algorithms can be useful in solving the "cold start" problem in recommendation engines. The cold start problem occurs when a new user joins the system or a new item is added to the system, and there is not enough data available to make personalized recommendations.

One approach to solving the cold start problem is to use community detection algorithms to identify groups of similar users or items based on their properties or interactions. For example, community detection can identify groups of users who share similar interests or purchasing habits or groups of items that are frequently purchased together. Placing the new user or item in of these communities based on very limited data can help provide at least somewhat personalized recommendations.
In addition to addressing the cold start problem, community detection algorithms can also be used to identify influential users or items within a community. Frequently purchased items or items liked by influential users are recommended to a wider audience to increase their visibility and popularity.
Data Lineage
In a complex data environment, it can be difficult to understand the relationships between different data sets and how they are used across different systems and processes. By getting a better overview of the flow od data through the system and processes, you can track the origin and transformation of data, as well as identify potential sources of errors or data quality issues.
For example, if a large database of sales information contains many different data elements, such as product ID, customer ID, sales date, and sales amount, it can be used to generate reports and make decisions about which products to stock and which customers to target.
If, over time, reports become less accurate, perhaps sales dates are missing or incorrect, community detection algorithm can identify groups of data elements that are closely related and exhibit similar behavior or usage pattern. Product ID, sales date, and sales amount are typically used together to track sales by product. Further analysis of this community might reveal that the errors are caused by a software bug that is affecting the data entry process or by a particular sales representative who is manipulating the data to inflate their performance.
Community detection algorithms can also help identify data elements that are similar or have overlapping properties making them redundant. Eliminating unnecessary elements can decrease the risk of errors or inconsistencies, improve data quality and reduce the complexity of the data environment.
Fraud Detection
Fraudsters often operate in groups, collaborating with each other to perpetrate fraudulent activity. Community detection algorithms can identify clusters of individuals or entities that are involved in similar types of fraudulent behavior based on attributes such as location, transaction history, or behavior patterns.
Once these communities are identified, features that capture the relationships between different entities or transactions within the community can be used to train machine learning models to detect anomalous behavior or patterns indicative of fraud.
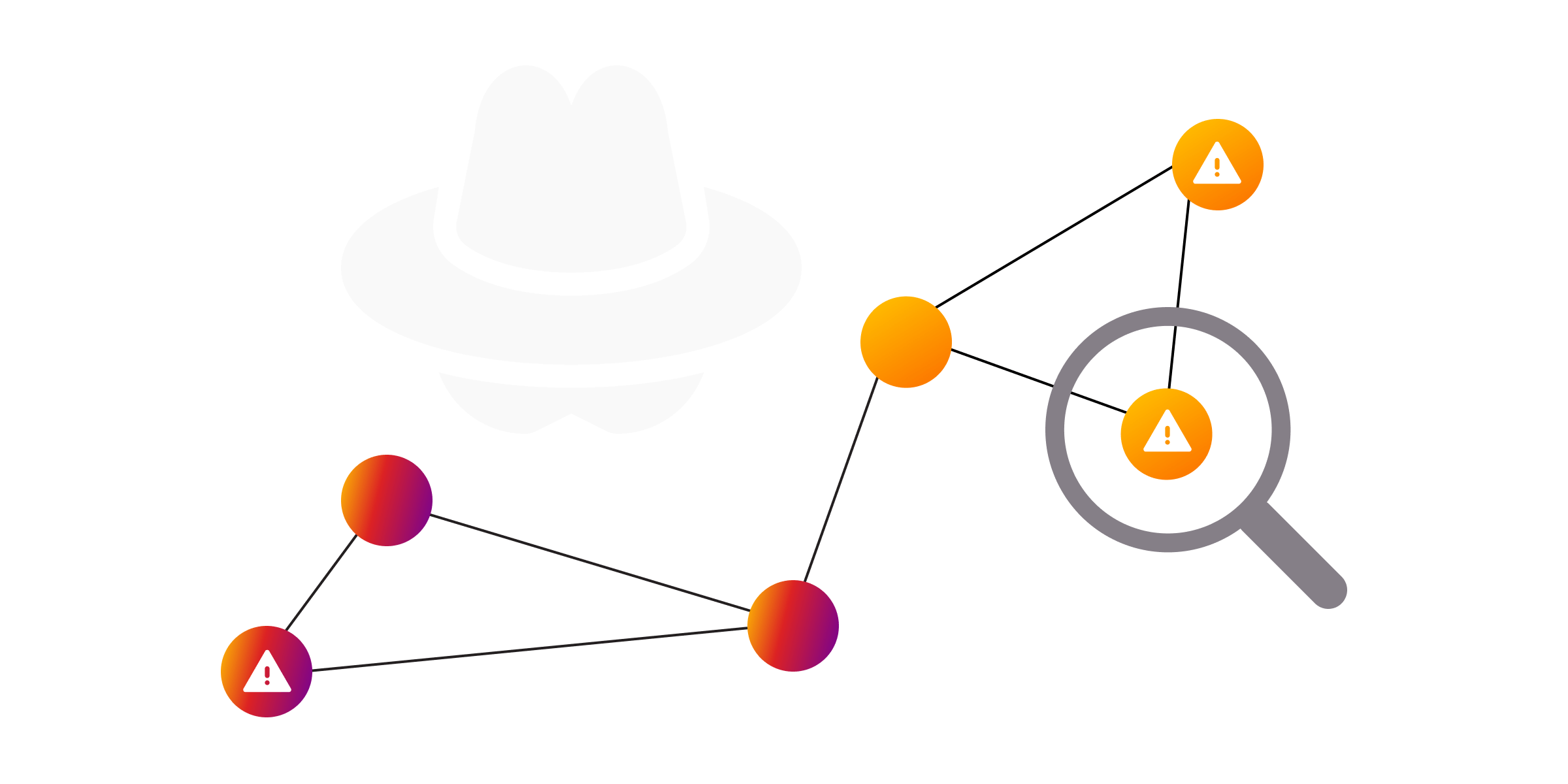
Community detection algorithms can also be used to identify new or emerging fraud schemes that were previously unknown. By analyzing the communities in a fraud detection system, we can identify patterns or relationships that may indicate a new type of fraud or scam. This information can be used to improve the fraud detection system further and to prevent future incidents.
Identity and Access Management
In a complex system, it can be difficult to identify the relationships between different users, roles, and permissions. Community detection algorithms can help identify groups of users or entities that have similar access patterns or permissions based on attributes such as role, department, or job function.
Identifying these communities leads to a better understanding of access patterns and behaviors of different users and entities and identify potential risks or anomalies when users start exhibiting unusual access patterns or behaviors.
Community detection algorithms can also be used to improve the efficiency and effectiveness of access management systems. By identifying groups of users or entities with similar access patterns, a more efficient access management processes can be created. For example, role-based access controls can be introduced based on the access patterns and behaviors of different communities.
Network Optimization
By identifying communities, the network can be optimized by allocationg more resource to the communities with the highest demand based on the usage patterns. Routing algorithms can be optimize to prioritize communities with high levels of connectivity, and the network as a whole can be simplified by removing redundant nodes or relationships, thus improving its performance.
In energy management systems identifying groups of energy-consuming devices or entities that exhibit similar energy consumption patterns can help optimize load balancing, detect anomalies, predict maintenance requirements, and implement energy-saving measures.
Cyber security
By identifying communities with similar behavior patterns, community detection algorithms can be used to detect potential threats such as malware, botnets, or unauthorized access attempts. For example, a community of devices that suddenly exhibit unusual behavior might be indicative of a malware attack.
It can also be used to detect intrusions by identifying communities of users or entities that are not authorized to access a particular system or network and by monitoring their behavior patterns, detect unauthorized access attempts and take appropriate action.
Community detection algorithms can help optimize network segmentation by identifying clusters of devices or entities with similar security requirements allowing the implementation of more granular security measures and reducing the risk of lateral movement by attackers.
Implementation in Memgraph
Memgraph implemented community detection by the Louvain method using the Grappolo parallel implementation.
The algorithm is implemented in C++ and suitable for large-scale graphs as it runs in O(nlogn) time on a graph with n nodes and performant enough for real-time scenarios. Further performance gains are obtained by parallelization using a distance-1 graph coloring heuristic and a graph coarsening algorithm that aims to preserve communities.
The graph needs to be undirected, and the algorithm can take relationships' weight into account.
Default arguments are as follows:
weight: str (default=null)➡ Specifies the default relationship weight. If not set, the algorithm uses the weight relationship attribute if it’s present. Otherwise it treats the graph as unweighted.coloring: bool (default=False)➡ IfTrue, use the graph coloring heuristic for effective parallelization.min_graph_shrink: int (default=100000)➡ The graph coarsening optimization stops upon shrinking the graph to this many nodes.community_alg_threshold: double (default=.000001)➡ Controls how long the algorithm iterates. When the gain in modularity goes below the threshold, iteration is over. Valid values are between 0 and 1 (exclusive).coloring_alg_threshold: double (default=0.01)➡ If coloring is enabled, controls how long the algorithm iterates. When the gain in modularity goes below this threshold, a final iteration is performed using thecommunity_alg_thresholdvalue. Valid values are between 0 and 1 (exclusive). Value of this parameter should be higher than thecommunity_alg_threshold.
To call community detection in Memgraph, use the following query:
CALL community_detection.get()
YIELD node, community_id;You can try it out on Playground, in the Sandbox of the Marvel Cinematic Universe dataset. Check to which communities the nodes belong:
CALL community_detection.get()
YIELD node, community_id
RETURN node, community_id LIMIT 500;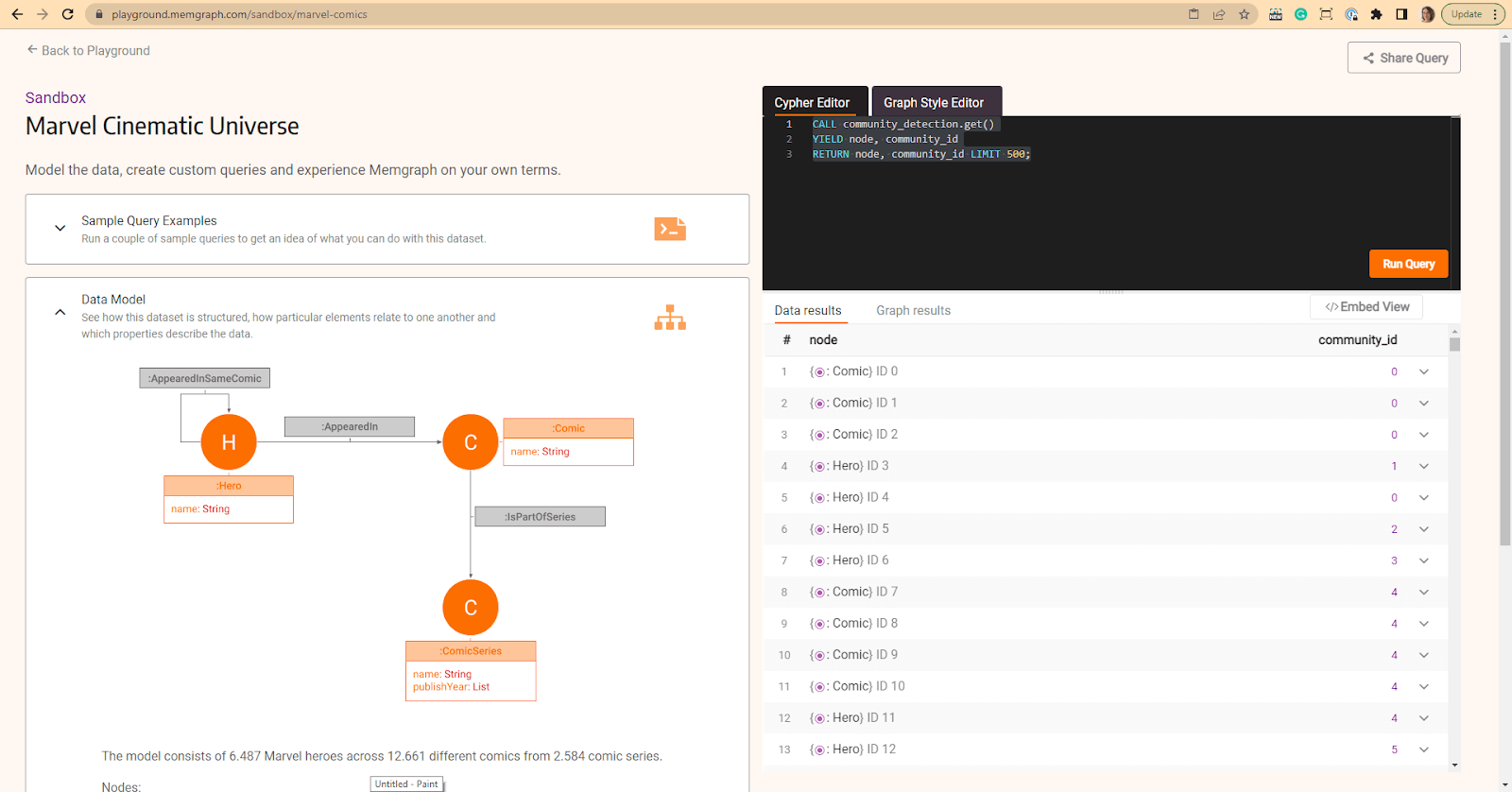
To get a visual representation of communities, you will need to switch to Memgraph’s visual interface or Cloud instance, load the Marvel dataset and assign each node a community ID:
CALL community_detection.get()
YIELD node, community_id
SET node.community = community_id
return node, community_id;
Then define the node colors based on community_id property:
@NodeStyle Equals(Property(node, "community"),0) {
color: blue
}
@NodeStyle Equals(Property(node, "community"),1) {
color: green
}
@NodeStyle Equals(Property(node, "community"),2) {
color: red
}
Calling all the paths with nodes belonging to the same three communities will produces a colorful result, as shown below:
MATCH p=(n1)-[]-(n2)
WHERE n1.community < 3 AND n2.community < 3
RETURN p LIMIT 1000;

As with all the other algorithms in the MAGE open-source library, you can run community detection only on a specific group of nodes with the project() function. Save the sub-graph in a variable, then provide it as a first argument of the algorithm:
MATCH p=(n:SpecificLabel)
WITH project(p) AS subgraph
CALL community_detection.get(subgraph)
YIELD node, rank
RETURN node, rank;If your application is highly time-sensitive and nodes and relationships are arriving in a short period of time, use the dynamic community detection, which allows the preservation of the previously processed state. When entities are updated or new ones arrive in the graph, instead of restarting the algorithm over the whole graph, only the neighborhood objects of that arriving entity are processed at a constant time.
Conclusion
In conclusion, community detection algorithms can be used to gain insights into the underlying structure of a network, identify patterns or anomalies, and solve various real-world problems. With its various applications, community detection algorithms are becoming increasingly popular and widely used, and can be implemented efficiently in graph databases such as Memgraph to improve performance and scalability further. For more examples of using community detection, check Memgraph’s blog posts on the same topic, or explore more graph algorithms.
If you ever have any doubts about whether you are using community detection correctly or you need help with implementing it into your use case, a welcoming community at Memgraph’s Discord server will be more than happy to help you integrate graphs and algorithms into your system.