
How to Upgrade an Antiquated Identity and Access Management System
Identity and Access Management (IAM) includes technologies and processes that enable organizations to provide users with appropriate access to systems, apps, and data. In other words, it defines who gets access to what, for what reason, and at what time. The definition of identity and the individual structure of each organization defines the access management and, therefore, the company’s IAM.
The problem with traditional IAM systems and why they are failing is because they are mainly still using CSV files to extract data from the HR systems. And although they are great for regular tabular data, grocery shopping lists, spending lists, and so on, analyzing patterns, access rights exploration, and dynamical checking for vulnerabilities is impossible with CSV files, as the files need to be analyzed in their entirety to gain the correct information.
Problems that unravel by using CSV files and relational databases as IAM systems come down to security issues, which are almost impossible to identify and track, and painful analysis of all the data in the relational database to discover vulnerabilities.
Solutions like IAM systems should serve to help organizations, not additionally complicate processes. And when the IAM data is modeled as a graph and built on top of a graph database platform such as Memgraph, vulnerability analysis comes out of the box, making any additional analysis and decision-making drastically easier and more performant.
The first important step towards a healthier relationship between an organization and its IAM system is to move IAM systems from old, tabular solutions to new graph solutions. Graph databases are full of benefits for IAM systems. Once a decision is made, it’s time to import data into a database. Memgraph comes with a handful of solutions, such as CSV import tools for the direct import of CSV files, Python libraries such as GQLAlchemy for more complicated imports when CSV files are interconnected and dependent on each other, and SQL migration tools.
How to transform data to Memgraph using LOAD CSV clause
Memgraph can help when it comes to transforming old CSV files data into a graph. LOAD CSV clause is one of the upgrades to the Cypher query language our team brought to Memgraph, making the transition efficient and straightforward.
If you aren’t familiar with Cypher query language, it has connection points with Structured Query Language (SQL) used with relational databases. Cypher is built on SQL's basic concepts and clauses but with added graph-specific functionality, making it simple to work with a rich graph model without being overly verbose. Memgraph uses Cypher query language to communicate with the database, import new data, create nodes and relationships, and query data. You can learn Cypher in only 10 days with our course.
The LOAD CSV clause supports transforming tabular data from the old IAM system to Memgraph using CSV files. All you need is a few Cypher lines. The clause reads row by row from a CSV file, binds the contents of the parsed row to the specified variables, and populates the Memgraph if it is empty or appends new data.
This means when importing data from CSV files to Memgraph, you can create initial relationships between, i.e., the user and files one has access rights to. Afterward, you can run additional queries to immediately check for any vulnerabilities in Identity and Access Management system now modeled with a graph, or you can create additional relationships missing in the current system. This is possible through pattern matching in Memgraph.
There are specifications you should be aware of when considering the CSV import clause, i.e., whether the CSV file has a header or not, what is CSV quote character (default is “), and so on. To check additional rules, jump to our documentation page for the LOAD CSV Cypher clause.
In the following example, you will see how importing data is easy and solves the problem of having multiple sources of truth regarding users' access rights.
Let’s say we model access rights by department and then model additional rights by additional CSV files.
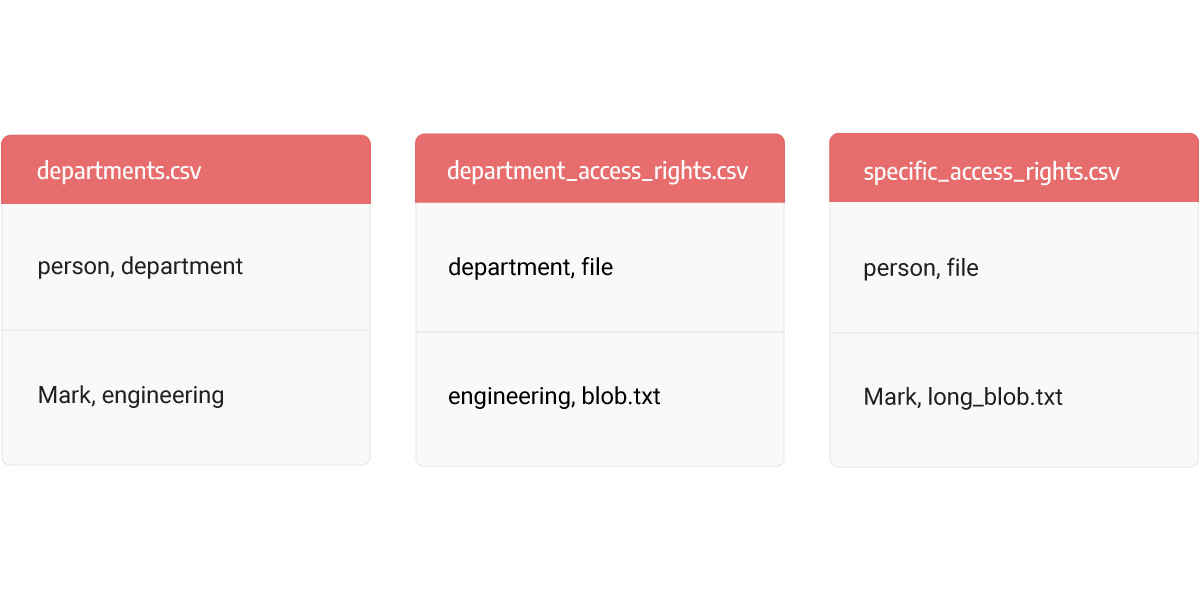
Now you can import data. The following 3 queries are pretty similar, the difference is only in the Node label and Relationship type. Using LOAD CSV from /path-to/file.csv Memgraph loads CSV file. The WITH HEADER part of the query suggests to Memgraph that there is a header in CSV files and that the following rows in CSV file Memgraph will be read and stored in a Map object, where the key is the column name from the header, and the value is the string from the row. To understand more, jump to our LOAD CSV documentation page. After reading from the CSV file, the next part defines the clause using data from each row to create a node with appropriate label names and a relationship between created nodes.
LOAD CSV FROM "/path-to/departments.csv" WITH HEADER AS row
MERGE (p:Person {name: row.person}) MERGE (d:Department
{name: row.department}) CREATE (p)-[:BELONGS_TO]->(d)LOAD CSV FROM "/path-to/department_access_rights.csv" WITH HEADER AS row
MERGE (d:Department {name: row.department}) MERGE (f:File {name:
row.file}) CREATE (d)-[:HAS_ACCESS_TO]->(f);
LOAD CSV FROM "/home/antonio/Downloads/specific_access_rights.csv" WITH
HEADER AS row
MERGE (p:Person {name: row.person}) MERGE (f:File {name: row.file})
CREATE (p)-[:HAS_ACCESS_TO]->(f)
The queries result with the following graph:
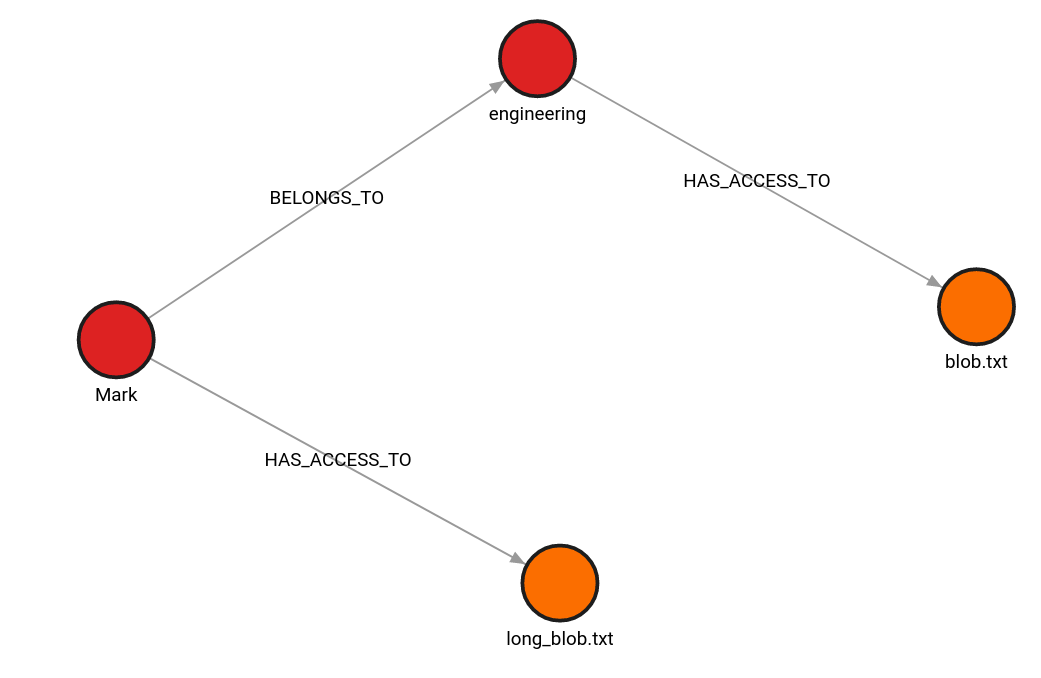
With the following command, you can now explore the access rights of a person or department with a graph database as a single source of truth. Even if you are unfamiliar with Cypher syntax, you will probably understand what the query will do.
The MATCH clause tries to find a pattern where the Person node with the name “Mark” and the File node with the name “blob.txt” are connected within 2 hops with relationships of type BELONGS_TO or HAS_ACCESS_TO.
In summary, the query checks if Mark BELONGS_TO a certain team which HAS_ACCESS_TO a file or whether there is a direct relationship between Person and File with HAS_ACCESS_TO type.
MATCH path=(p:Person {name:"Mark"})-[:BELONGS_TO|:HAS_ACCESS_TO *..2
]->(f:File {name:"blob.txt"})
RETURN *;
What makes GQLAlchemy great when importing data to Memgraph
CSV files containing an exported IAM system can be dependent on each other, which means it’s impossible to import one CSV file without the other. In terms of relational databases, there are many-to-many relationships and foreign keys between different files. When it comes to the flexibility of designing a shema on how to import data consisting of multiple CSV files dependent on each other, GQLAlchemy is Memgraph’s most valuable importer. It is not just an importer but a complete Python library that serves as an Object Graph Mapper (OGM), a link between Graph database objects and Python objects.
GQLAlchemy, as OGM, provides a developer-friendly workflow that allows object-oriented notation writing to communicate to a graph database. This means that you can write object-oriented code instead of writing Cypher queries, and the GQLAlchemy translates that code into Cypher queries.
GQLAlchemy comes in very handy when importing data interconnected within several CSV files because you can write a configuration file to define relationships between different files as stated in the relational databases. Such relationships include many_to_one relationships and many_to_many relationships. Jump to documentation to understand more about mappings with the GQLAlchemy configuration file.
What are some other possibilities?
If you are working with CSV files, but neither the CSV LOAD clause nor GQLAlchemy work for you, then designing how data will be imported by creating your own queries might be the way to go. CYPHERL format in Memgraph supports exactly that. On the other hand, if you are working with relational databases, data migration with an SQL migration tool is worth checking out.
CYPHERL files
Memgraph also allows importing data directly in Cypher lines form - CYPHERL format giving you complete control over data import. You can import all the CSV files in the programming language of your choice, remove redundant data and create queries from the data you want to import into Memgraph. You can create indexes for the node property you want and speed up IAM data import, as there could be millions of nodes in the dataset. You can also create multiple relationships in one query or cherrypick which data to import, as you only need a fraction of it. To understand more about the CYPHERL format, jump to our documentation page. With importing from CYPHERL, possibilities are endless, and it’s completely up to you to import what you want to Memgraph from CSV files.
SQL migrate
If none of the mentioned possibilities is an option because the current IAM system is stored in an SQL database, Memgraph has a solution. We have implemented a tool to help you migrate data to Memgraph. The process of migrating data to a graph database can be part of the testing experience if you want to audit your current Identity and Access Management system by pushing data into Memgraph. To use the power of graphs as part of your IAM solution, jump to migration from MySQL or PostgreSQL.
Next steps
Once you have modeled and imported data as a graph in Memgraph, you have broad possibilities of what you can do with the data. Visualizing graphs in an interface such as Memgraph Lab can come in handy to analyze situations top-down. This way you can check for apparent vulnerabilities by considering relationships between various teams, resources, etc. Afterward, you can let Memgraph detect patterns bottom-up such as non-secure or recursive relationships, and resolve them in your Active Directory - your current IAM system.
Conclusion
This blog post shared how Memgraph is ready to power your Identity and Management solutions by making the first necessary step: data importing. We mentioned 3 tools and one format helpful for data importing.
Once your data is in Memgraph, you can start further exploration and vulnerability detection. From pattern matching, data exploration, visualization, to dynamic vulnerability checking, and everything else necessary to keep a healthy and secure IAM system.
To understand the problems traditional IAM systems are struggling with find out what problems are IAM system struggling with and what benefits can graph databases bring to the table.