
How Memgraph Uses Skip Lists for Fast Indexes and Unique Constraints
With database systems, it is fairly common and expected that a mature database will have indexes and constraint implementations. These are crucial for ensuring the speed of retrieval and data consistency in the database.
The general concepts of the indexes and constraints are quite similar across different database systems, but the specific details on implementation, benefits, and disadvantages are fairly specific to each database system.
This post will walk you through Memgraph’s approach to indexes and constraints, highlighting how skip lists power both these mechanisms and the pros and cons of this design choice.
What Is a Skip List?
A skip list is a clever, probabilistic data structure designed for fast search, insertion, and deletion—similar to a B-tree but without the strict balancing rules. Instead, it uses multiple layers of linked lists to achieve efficiency.
At its core, the skip list is a sorted linked list at the bottom layer. Additional layers sit on top, skipping over chunks of elements from the layer below. This "skipping" drastically reduces the number of nodes you need to traverse for most operations.
Each element is assigned a random "level." The higher the level, the fewer layers that element appears in. This randomness creates a logarithmic distribution on average, allowing searches to operate in O(log n) time complexity, comparable to binary search trees but with simpler implementation.
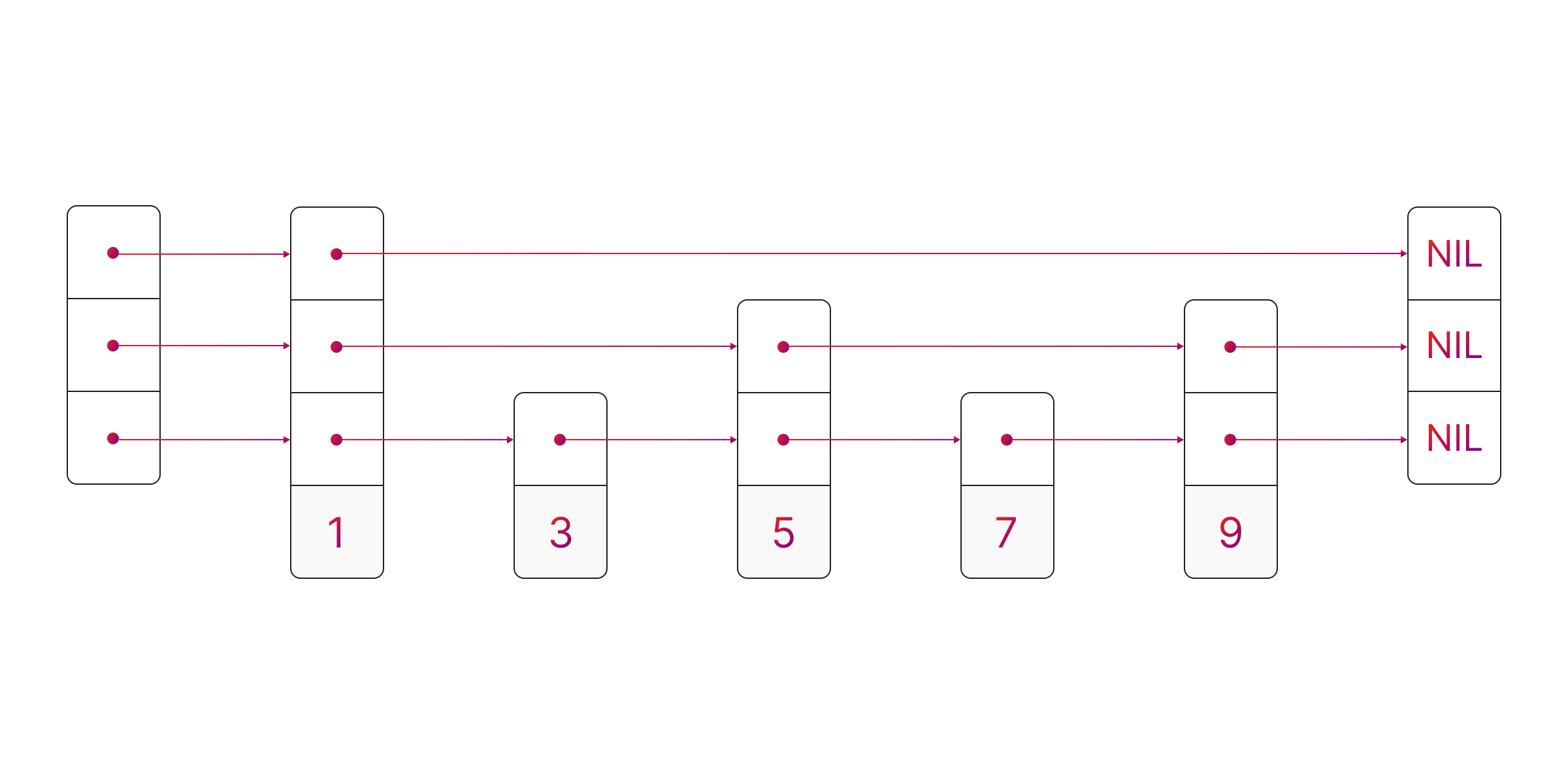
When searching for a value (e.g., 7) in a skip list, the process starts at the topmost layer. You move forward through the nodes until you overshoot the target, then drop down to the next layer. This pattern of moving horizontally and then vertically repeats until you reach the bottom layer, where the target is either found or confirmed to be missing.
This layered design ensures that fewer nodes are visited at each level, making the search operation efficient. On average, the time complexity is O(log n), comparable to binary search trees but achieved through a simpler, probabilistic structure.
Why Does Memgraph Need Indexes?
Indexes play a vital role in any database. While a database can operate without them, the performance would be subpar for large datasets due to the time needed to scan through data. In Memgraph, using indexes becomes essential as the dataset grows.
Step 1: Setting up a large dataset
First, let’s create 10 million nodes in Memgraph:
UNWIND range(1, 10000000) AS id
CREATE (:Node {id: id});This command generates a dataset with 10 million nodes, each assigned a unique id property.
Step 2: Running a query without an index
Now, try querying for a specific node:
PROFILE MATCH (n:Node {id:1}) RETURN n;In the query above, we’re looking for a node with id: 1. Since there’s no index on the id property, Memgraph has to scan each node sequentially. Here’s the performance profile output:
memgraph> PROFILE MATCH (n:Node {id: 1}) RETURN n;
+------------------------------+------------------------------+------------------------------+------------------------------+
| OPERATOR | ACTUAL HITS | RELATIVE TIME | ABSOLUTE TIME |
+------------------------------+------------------------------+------------------------------+------------------------------+
| "* Produce {n}" | 2 | " 0.000404 %" | " 0.009117 ms" |
| "* Filter (n :Node), {n.id}" | 2 | " 84.206315 %" | " 1898.614339 ms" |
| "* ScanAll (n)" | 10000001 | " 15.793277 %" | " 356.093754 ms" |
| "* Once" | 2 | " 0.000003 %" | " 0.000070 ms" |
+------------------------------+------------------------------+------------------------------+------------------------------+
4 rows in set (round trip in 2.255 sec)
INFO: Sequential scan will be used on symbol `n` although there is a filter on labels :Node and properties id. Consider creating a label-property index.
It took over 2 seconds to retrieve this single node because the ScanAll operator had to examine every node in the graph. In Memgraph, nodes are stored in a skip list, a dynamic data structure that organizes nodes by their internal IDs. However, without an index on the id property, Memgraph has no choice but to perform a full scan, checking each node individually.
Step 3: Creating an index for faster access
To resolve this issue, let’s create an index on the id property:
CREATE INDEX ON :Node(id);Now that we have an index, re-run the query to see how performance improves:
memgraph> PROFILE MATCH (n:Node {id: 1}) RETURN n;
+--------------------------------------+--------------------------------------+--------------------------------------+--------------------------------------+
| OPERATOR | ACTUAL HITS | RELATIVE TIME | ABSOLUTE TIME |
+--------------------------------------+--------------------------------------+--------------------------------------+--------------------------------------+
| "* Produce {n}" | 2 | " 27.726533 %" | " 0.006084 ms" |
| "* ScanAllByLabelPropertyValue (n... | 2 | " 71.676614 %" | " 0.015727 ms" |
| "* Once" | 2 | " 0.596853 %" | " 0.000131 ms" |
+--------------------------------------+--------------------------------------+--------------------------------------+--------------------------------------+
3 rows in set (round trip in 0.001 sec)
With the index in place, Memgraph now uses the ScanAllByLabelPropertyValue operator, which directly accesses the id property without scanning every node. This drastically reduces query time to around 0.001 seconds.
- Read more - Skip List (Memgraph docs)
How Memgraph Handles Index Creation
When you create an index, Memgraph generates a new skip list for that specific property. Here’s what’s happening internally:
std::map<std::pair<LabelId, PropertyId>, utils::SkipList<Entry>> index_;This SkipList<Entry> represents the newly created skip list for the indexed property, enabling efficient searches, additions, updates, and deletions based on the id property with O(log n) time complexity.
- Read more - Label-property implementation (Memgraph GitHub)
- Read more - SkipList
index (Memgraph GitHub)
Performance Trade-Offs of Indexing
While indexing speeds up read operations, it also introduces some trade-offs:
- Memory overhead. Each skip list occupies additional memory. For instance, with 21,723 nodes, each
SkipListNode<LabelIndex::Entry>takes 24 bytes, and each pointer takes 16 bytes. The memory overhead can be calculated as follows:
NumberOfVertices × (SkipListNode<LabelIndex::Entry> + next_pointers).Example:
21,723 x (24B + 16B) = 21,723 x 40B =868,920
- Write operation impact. Each time data is modified, Memgraph must update multiple skip lists, which can slightly slow down write, update, and delete operations.
By carefully choosing which properties to index, you can maximize query performance while minimizing memory usage and write overhead.
- Read more - Storage Memory Usage (Memgraph docs)
The Impact of Uniqueness Constraints on Performance
Uniqueness constraints are essential for maintaining data integrity in any database, ensuring no duplicate values exist for specified properties over time. In Memgraph, uniqueness constraints closely resemble indexes in their implementation and are also built on skip lists to support efficient operations on nodes and properties.
How Uniqueness Constraints Work in Memgraph
Consider the following example:
CREATE (:Node {id: -1})When you add a node with an id property, Memgraph needs to verify that no other node already has this id. Without a uniqueness constraint, Memgraph would have to sequentially search the skip list to check for duplicates. In a large dataset, this process could take a significant amount of time, potentially several seconds.
To streamline this, Memgraph lets you define a uniqueness constraint:
CREATE CONSTRAINT ON (n:Node) ASSERT n.id IS UNIQUE;When you run this command, Memgraph creates a dedicated skip list for the constrained property (id in this case). This skip list allows Memgraph to efficiently verify uniqueness without scanning the entire list, as it can now access the property directly.
Performance Considerations with Uniqueness Constraints
While uniqueness constraints speed up searches, they come with some trade-offs:
- Memory consumption. Similar to indexes, each uniqueness constraint requires its own skip list, consuming additional memory for pointers and entries.
- Overhead on write operations. Each time data is written, updated, or deleted, Memgraph must update all relevant skip lists. This adds a small performance cost to write operations, particularly when multiple constraints are in place.
Conclusion: Balancing Speed and Resources
Memgraph’s skip-list-based indexing and constraints provide O(log n) performance for both searches and uniqueness checks. This structure allows for efficient data retrieval and integrity maintenance, though it does come with trade-offs in memory usage and write operation speed.
When implementing indexes and constraints, consider your application’s performance and storage needs carefully to maintain the right balance between retrieval speed and resource efficiency.