Types of NoSQL Databases: Deep Dive
NoSQL databases have gained significant popularity in recent years due to their ability to handle large volumes of unstructured and semi-structured data. Unlike traditional relational databases, NoSQL databases offer flexibility and scalability, making them ideal for modern applications that require high performance and rapid development. In this article, we will explore the various types of NoSQL databases while unraveling their key characteristics and use cases.
What is a NoSQL database?
A NoSQL database, or "Not Only SQL," is a type of database that provides a flexible and scalable approach to storing and managing large volumes of unstructured and semi-structured data. Contrary to classical relational database management systems, a NoSQL database does not rely on a fixed schema, allowing for dynamic and agile data modeling.
SQL/relational databases vs NoSQL databases
SQL and NoSQL databases represent two distinct approaches to data storage and management, each with its own set of strengths and trade-offs. An SQL, or a relational database, has been the conventional choice for structured data storage, while NoSQL databases have come to light for their ability to handle large volumes of unstructured and semi-structured data.
SQL databases enforce a rigid schema, ensuring data integrity through predefined tables, columns, and relationships. They excel in complex queries, transactional consistency, and data integrity enforcement. They also offer powerful ACID (Atomicity, Consistency, Isolation, Durability) properties, making them suitable for applications with stringent data integrity requirements, such as financial systems or inventory management.
On the other hand, NoSQL databases provide a flexible schema-less approach, allowing for agile development and accommodating evolving data structures. They offer horizontal scalability, distributed architectures, and high-performance read-and-write operations. In addition, NoSQL databases shine in handling unstructured data, providing fast data retrieval, and easily scaling to meet the demands of modern applications.
Key characteristics of NoSQL databases
Before diving into the different types of NoSQL databases, let's take a look at the key characteristics that distinguish them from relational databases :
Schemaless
NoSQL databases are schemaless, which means they don't require a predefined schema for data storage. How do you benefit from it? This flexibility allows for easy adaptation to evolving data structures and eliminates the need for expensive database migrations.
Scalability
Our so-familiar horizontal scalability is another feature of NoSQL databases, enabling them to distribute data across multiple servers or clusters effortlessly. The distributed architecture makes it easier to handle massive amounts of data and high traffic loads.
Top-level performance
As a rule of thumb, NoSQL databases are designed to provide fast read-and-write operations, which makes them suitable for use cases that require real-time data processing and low-latency responses.
Flexible data models
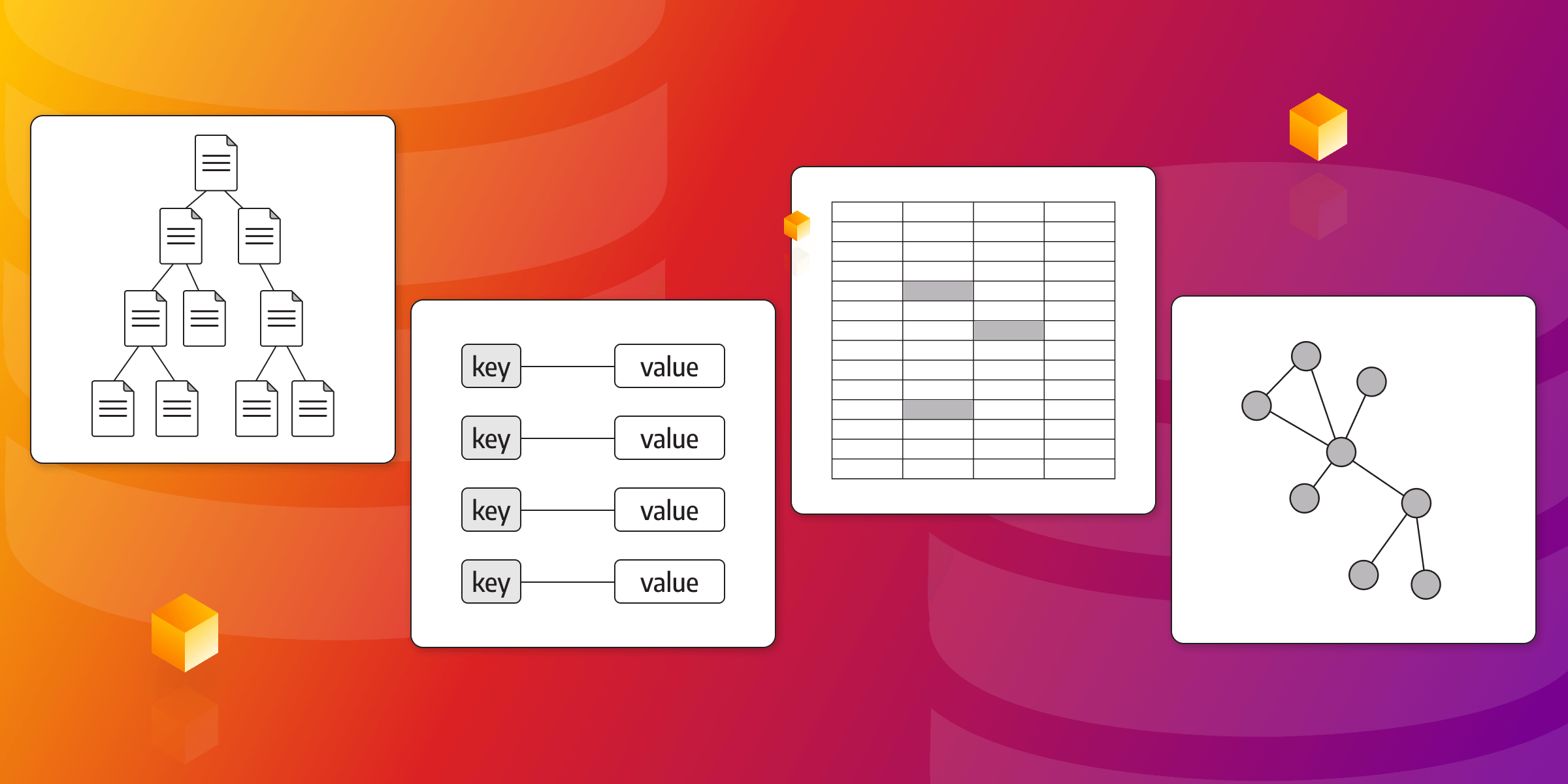
Another characteristic typical for NoSQL databases is that they also offer a variety of data models — also look up types of NoSQL databases — such as key-value, document, columnar, wide-column, and graph databases, providing developers with the flexibility to choose the most suitable one for their specific project needs. This gives them a major advantage when compared with the fixed schemas of relational databases.
NoSQL database categories
Now, speaking of data models, NoSQL databases can be broadly classified into several categories. Let's explore each of them in more detail:
Key-Value databases: Flexible and fast data retrieval
Key-value databases are a type of NoSQL database that stores data as a key-value pair collection. They offer a simple and efficient way to store and retrieve the same data, making them ideal for use cases that require fast data access. Key-value databases excel in scenarios where the primary operation is retrieving data based on a unique key.

One of the benefits key-value databases provide is their flexibility. They don't enforce any specific schema, allowing developers to store values of any data type associated with a key. Similar flexibility makes key-value databases well-suited for caching, session management, and storing user preferences.
Key-Value Database examples
Popular key-value stores include Redis, Amazon DynamoDB, and Microsoft Azure Cosmos DB (all of them also multi-model). Redis, in particular, has gained popularity due to its in-memory caching capabilities, high performance, and support for advanced data structures like lists, sets, and sorted sets.
Document databases: Agile and versatile data management
A document database, also known as a document store, is designed to store and manage semi-structured or unstructured data, storing it in a self-describing format such as JSON or XML. That, in turn, allows for flexible and agile data modeling. In document databases, data is organized into collections or buckets, and each document can have its own structure.

Document databases provide powerful querying capabilities, making it easier to retrieve and manipulate data within the documents. They also offer features like automatic sharding and replication for high availability and scalability. Document databases are particularly well-suited for content management systems, blogging platforms, and applications dealing with complex and altering data structures.
Document database examples
MongoDB, one of the most popular document databases, offers a rich set of features, including flexible querying, automatic scaling, and seamless integration with programming languages. Couchbase and Firebase Realtime Database are also widely used document databases worth looking into.
Columnar databases: efficient analytics and large-scale data processing
Columnar or column-oriented databases are optimized for storing and processing large volumes of data. As the name suggests, instead of storing data elements in rows, columnar databases organize data in columns. This columnar arrangement allows for efficient compression and faster query performance when working with specific attributes.
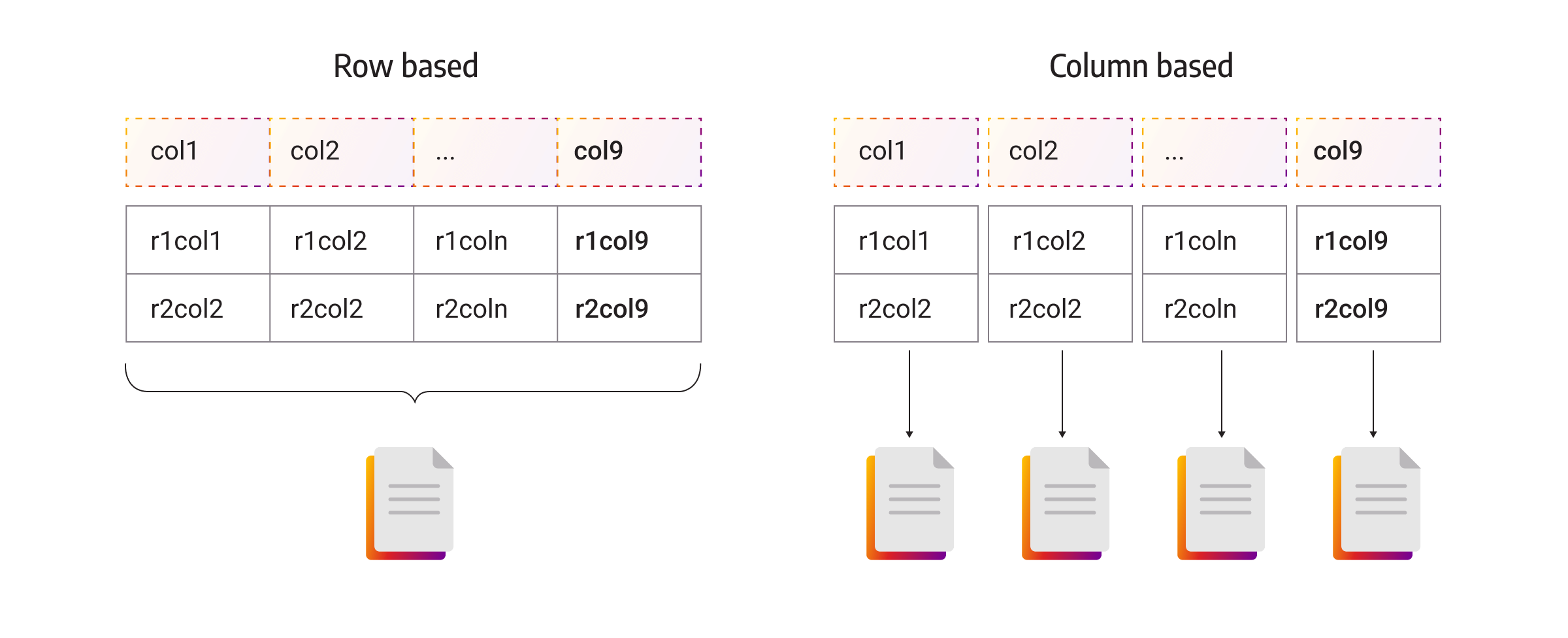
A column-oriented database is used in data warehousing, business intelligence, and analytical applications where the focus is on complex queries that involve aggregations, filtering, and searching across large datasets. Columnar databases provide excellent read performance and enable rapid data analysis.
Columnar database examples
Apache Cassandra and Apache Kudu are examples of popular columnar databases that offer horizontal scalability, fault tolerance, and distributed processing capabilities — all good for big data environments.
Wide-Column stores: scalable and high-performance data storage
Wide-column stores, also known as wide-column databases, combine the characteristics of both columnar and key-value databases.
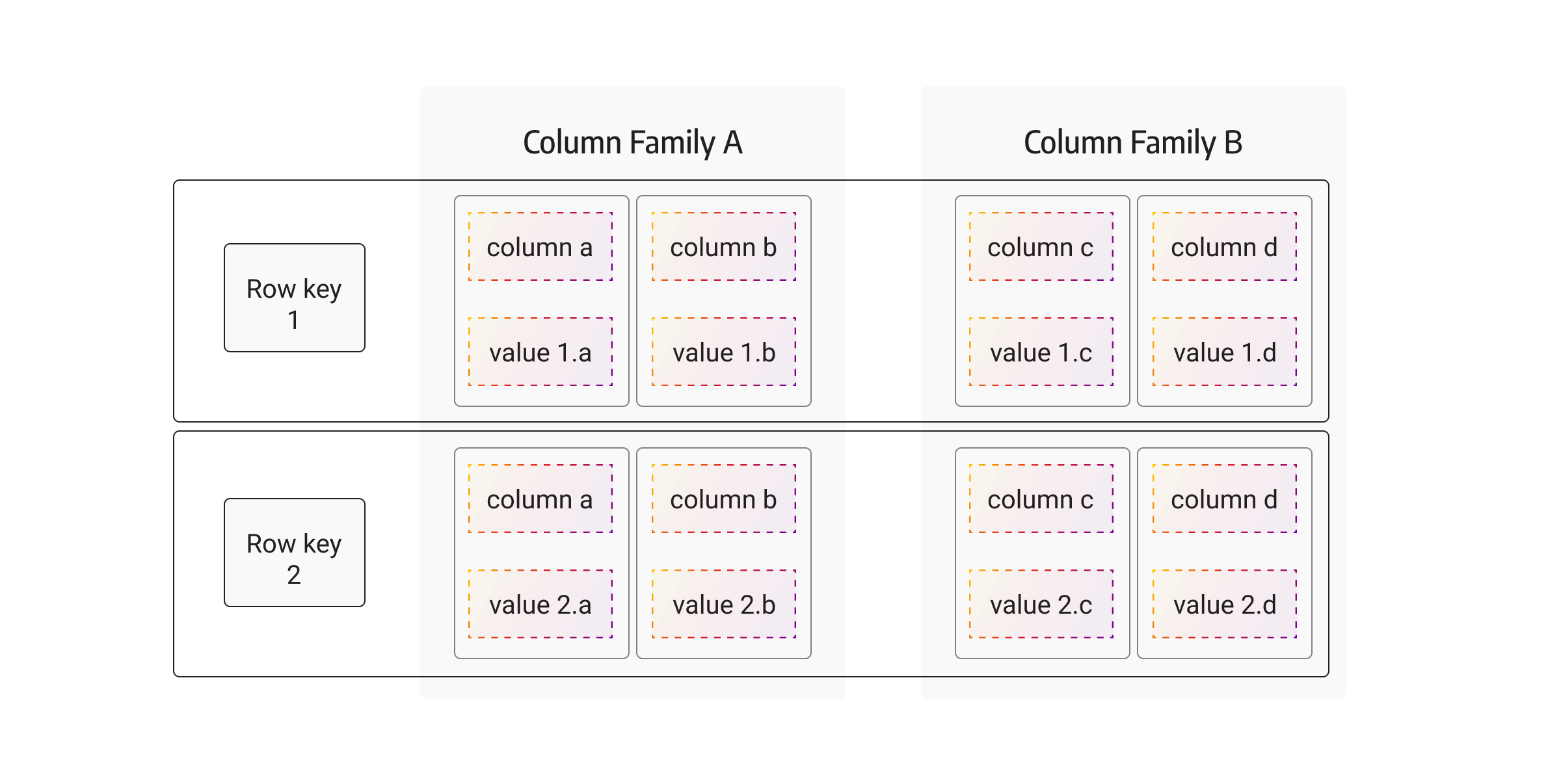
Wide-column stores store data in column families, where each column family can contain multiple columns and hold a large number of rows. This structure allows for efficient data retrieval and enables flexible schema design. Wide-column stores are known for their ability to handle massive workloads and provide low-latency read-and-write operations.
Wide-Column store examples
Apache HBase, Apache Cassandra, and ScyllaDB are good examples of wide-column stores. Apache HBase is built on top of the Hadoop ecosystem and provides consistent, real-time access to large datasets. Apache Cassandra, on the other hand, offers high availability, fault tolerance, and linear scalability.
Graph databases: Exploring relationships in connected data
Graph databases have emerged as a powerful technology for managing and querying interconnected data, making them ideal for applications that rely heavily on relationships. Unlike other types of NoSQL databases, a graph database focuses on representing data as nodes, edges, and properties, allowing for efficient traversal and exploration of relationships.
One of the assets offered by graph databases is their ability to handle complex queries involving relationships. They excel at finding patterns, identifying connections, and performing graph-based operations such as pathfinding, recommendation systems, and social network analysis. Furthermore, graph databases enable the expression of complex relationships and hierarchies, enabling developers to model their data more accurately.
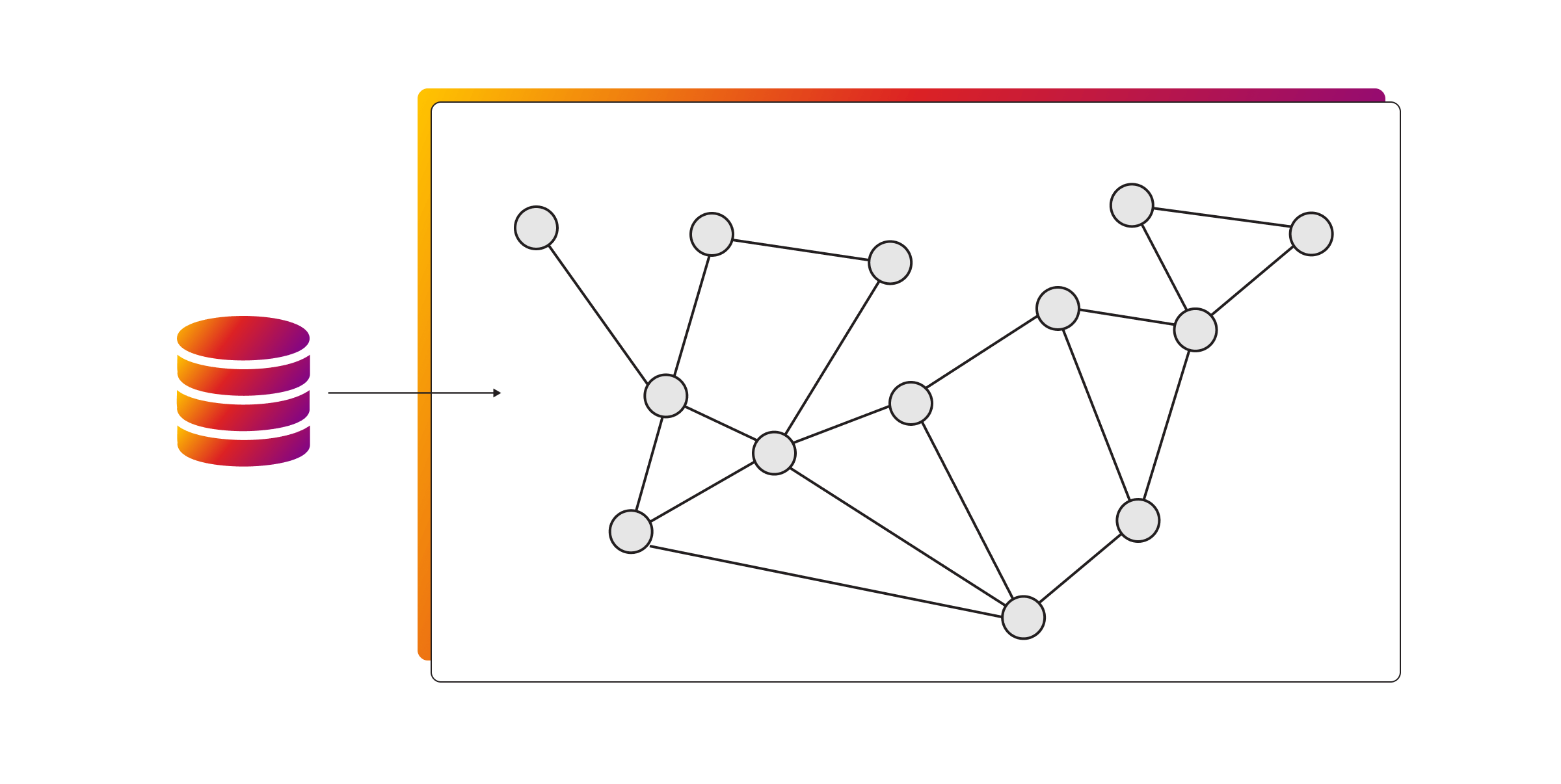
Of course, graph databases find applications in various domains. Social networks leverage them to map connections between users, recommend friends, and identify communities. E-commerce platforms can utilize graph databases to provide personalized recommendations based on user preferences and purchase histories. Whereas knowledge graphs built with graph databases help in organizing and retrieving vast amounts of information efficiently.
The power of graph databases lies in their ability to uncover hidden insights and discover meaningful connections in the data. By leveraging the inherent graph structure, developers can gain a deeper understanding of the relationships between entities and unlock new opportunities for analysis and innovation.
Graph database examples
Memgraph and Neo4j are the leading advocates in graph data space. Although Neo4j has a lengthier history, Memgraph has the advantage of being implemented in C++, making it a highly optimized and efficient in-memory graph storage. In comparison, Neo4j utilizes a conventional on-disk storage approach. To compare their performance, check out the performance benchmarks, or feel free to also recreate and evaluate them using your own data.
Amazon Neptune and Apache Giraph are other notable graph databases that offer scalability and seamless integration with existing data systems.
What to consider when choosing a database?
Way to if you have come this far! Choosing a database can either make or break your project. Thus, be mindful of the following factors before making a decision:
Data model requirements
Understand the structure and nature of your data. Consider whether a key-value, document, columnar, wide-column, or graph data model aligns better with your application's data requirements. Selecting the right data model will ensure efficient storage, retrieval, and manipulation of your data.
Scalability
Determine the scalability needs of your application. Will your data and user base grow over time? To what extent? Consider a database that offers horizontal scalability, allowing you to distribute data across multiple servers or clusters with ease.
Performance demands
Assess the performance requirements of your application. Are you dealing with real-time data processing or high-volume transactional operations? Look for a database that provides fast read-and-write operations, low latency, and robust indexing mechanisms.
Query patterns
Analyze the types of queries your application will frequently perform. Different databases excel in different query patterns. Some prioritize read-heavy workloads, while others handle complex analytical queries more efficiently. Choose a database that aligns with your predominant query patterns to optimize performance.
Consistency and durability
Consider the level of consistency and durability your application requires. Some databases prioritize strong consistency, ensuring that all nodes in the system have the same view of data, while others may offer eventual consistency or trade-offs to achieve high availability. An insider tip: evaluate the data durability guarantees provided by the database to ensure data integrity.
Ecosystem and tooling
Examine the available ecosystem and tooling around the database. Look for a vibrant community, comprehensive documentation, and robust support to facilitate the development, troubleshooting, and maintenance of your application.
Cost and licensing
Take into account the financial implications and licensing requirements associated with the database. Evaluate factors such as upfront costs, operational expenses, and any limitations or restrictions imposed by the licensing terms.
By carefully considering these factors and matching them with your application's specific needs, you can make an informed decision when selecting a database. Keep in mind that there is no one-size-fits-all solution, and the right database choice will depend on the unique requirements and constraints of your project.
Wrap up
NoSQL databases offer a flexible and scalable alternative to traditional relational databases. So far, we have explored the key characteristics of NoSQL databases, including their schemaless nature, scalability, high performance, and support for various data models. We delved into different categories, including key-value, wide-column, graph, document, and column-based NoSQL databases, each catering to a specific use case. We've also learned vital factors to consider when choosing a NoSQL database. By carefully evaluating these factors, you can select the most suitable NoSQL database that aligns with your application's needs and harnesses the full potential of data-driven systems.
With the ever-increasing demand for handling massive amounts of unstructured data, NoSQL databases continue to play a pivotal role in shaping the future of database technology. So, don't miss out! Take a sneak peek into more opportunities. 😉