
Memgraph 1.2 Release - Implementing The Bolt Protocol v4
Introduction
Today, we’re proud to announce the release of Memgraph 1.2, which significantly improves Memgraph’s compatibility with the broader graph ecosystem. This makes it easier for developers and data scientists to work with Memgraph using their favourite tools.
One of the biggest changes in this release, is the addition of Bolt v4 and v4.1 support.
In this post, we will explore what exactly is the Bolt protocol, what it brings to the table, and how we implemented it into Memgraph.
The Bolt Protocol
If you're thinking about using Memgraph in your application, one of the requirements is the possibility of querying Memgraph directly from your application with as little effort as possible. You can achieve that by writing drivers for the Memgraph server in the language you want to support. Drivers are special libraries that follow predefined rules, aka a protocol, to communicate between your application and a server.
Instead of defining its own rules, Memgraph decided to use Neo4j's protocol called Bolt. There are 3 important reasons for this decision:
- Defining a protocol is not easy
- Neo4j also uses Cypher (that doesn't mean that the Bolt protocol can't be used for other query languages!)
- By supporting Neo4j's protocol we automatically become compatible with their drivers
The drivers that Neo4j currently maintains are:
In other words, by making our server compatible with the Bolt protocol, you can use Memgraph in any of the languages and frameworks listed above just by using Neo4j's libraries.
Bolt Protocol Rule Examples
First, we need to know how to exchange messages. Bolt exchanges its messages using a request-response pattern between the client and the server. Each request message can be followed by zero or record messages which are then followed by one summary message. The different possibilities for record messages depends on the type of the request message.
NOTE
A record message is a type of message which contains records, aka result rows.
Also, we need to know how to serialize our data. Bolt uses its own PackStream which provides specification for serializing a bunch of different types of data. It is fully compatible with the types supported by Cypher. We won't go into details but every type is defined with its marker, its size and its data.
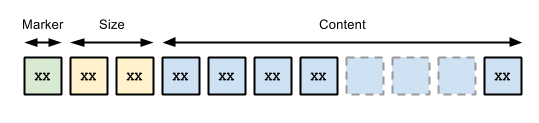
Source: https://7687.org/packstream/packstream-specification-1.html
One of those types is a structure. The size of the structure defines how many fields it contains and the fields can be of any other type. But we're missing an important information. How do we know what the structure represents? Structures carry additional data, its tag byte. This tag tells us what does the structure represent. We're now half way through to understanding how to define request and response messages.
We can't expect that our data will always be small enough to send it all at
once. To solve this problem, Bolt defines how the message is chunked. Each chunk
is starts with two-byte header that tells us the size of chunk data in bytes
followed by the chunk data itself. Now, we have another problem. How do we know
if we received the last chunk of message? We just add a marker! In our case we
append to the end of the last chunk 00 00.
Now, we have everything we need to define our messages. We can define each type of request/response message as a unique structure, having a unique set of fields. We can send the defined structure using the chunking method defined before. We're set! We can serialize and deserialize messages now!
Bolt Protocol Specifications
A good protocol specification should contain as much information as possible. Without enough information, we can only guess how our server or client should behave in some situations, causing a lot of headache for every developer that tries to implement that protocol.
So, as a good protocol, Bolt defines how to parse different types of request message and send the correct response message. It defines how each request message looks and what to send as a response message in each possible situation. Also, it defines the state of server after each request message and its outcome.
If want to delve deeper into the Bolt Protocol specifications, you can find everything here.
NOTE
Implementing rules is not hard, but to do it efficiently requires a lot of careful planning and having a good understanding of how the protocol works.
Evolution of the Bolt Protocol
As with any software, protocols are susceptible to change. Bolt defines it's version using major and minor versions. At the start of each connection, the client needs to do a handshake with the server.
The handshake is really simple and consists of only two steps:
- client sends at most 4 versions it supports, sorted by priority
- server responds with the first version in the list it supports
But doesn't Memgraph support Bolt protocol?
Yes, Memgraph does support the Bolt protocol. But up until now, it only supported Bolt v1, while the current version is 4.1. By looking at the handshake process we can conclude that the client can support at most four versions. The logical thinking is that the client will always support the latest 4 versions. At the time of writing this, the latest version is v4.1, which pushed v1 out of the support list, making us, and everyone else that wanted to try Memgraph using Neo4j’s drivers, very sad.
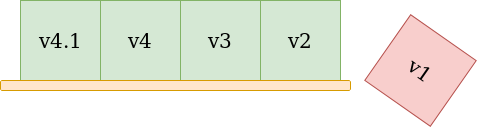
NOTE
It's important to emphasize that after version 1.0, newer versions weren't documented, which made keeping up with the newer versions really hard. But, after v4.1, Neo4j decided to document every version nicely making our lives much easier. Thanks Neo4j!
The Road to Bolt v4.(1)
Since Memgraph was only compatible with the first version of the Bolt protocol, we had three major and one minor version change to catch up with.Most of it was just some basic additions to the already existing messages, but there were also some bigger changes. For example, we made the decision to preserve support for Bolt v1. This has been very challenging as one of the hardest things in programming is making bigger changes to an existing code while not breaking the old behaviour.
Supporting multiple versions
Handling a code that behaves differently for each version can be hard. After we decide on a version for a specific connection, we need to be careful which messages are allowed for that version, which response should each message produce, what parameters are allowed, and many more things. And to do that while reusing as much of code as possible, with the addition of keeping the readability can be a challenge. The only real advice I can give you here is write as many tests that will cover as much as possible because a smallest detail can make your server misbehave while implementing a support for a protocol.
Making transaction handling easier and more powerful
In Bolt v3, new request messages for handling transactions were added. Those messages
are for starting an explicit transaction and ending the transaction by
committing or rollbacking the changes.
Because we already had support for transactions and you could already do
the same thing by running queries consisting of BEGIN, COMMIT and ROLLBACK
commands, the only thing we had to do was add functions that directly run those
queries when the corresponding request was received.
Getting some results from here and some from there
The biggest change to the Bolt protocol was the change to the PULL and
DISCARD message.
Before we delve deeper, let's explain those messages.
When you want to run a query on a server using Bolt messages, first you need to
send a RUN message that contains the query we want to execute. To get the results
of the query we send a PULL message, and if we want to discard the results,
we simply send the DISCARD message. The natural way of handling this is preparing
the query when we receive the RUN message and executing it when we receive the
PULL message. Additionally, to avoid wasting memory, we don't keep the result, we
just forward it to the encoder and send it directly to the client.
In Bolt v1, there were PULL_ALL and DISCARD_ALL messages. As their name suggests,
the only options you had was all or nothing. Taking this into account, we developed
a solution that would simply stream all the results to the client after it receives
PULL_ALL message. But, since v4.0, things got a little more complicated.
The PULL_ALL message was renamed to PULL. Additionally, the PULL message can come with some extra parameters.
n parameter
You can now pull an arbitrary number of results. This small change implies a lot of
changes to the existing code. The easiest solution would be to execute the query on the
first pull and save all of the results in memory. After that, for each pull, we just
send next n results. Even though it's the easiest solution to implement, it's too
inefficient memory-wise. Taking this into account, we have a hard requirement of
keeping the old, lazy behaviour while not keeping any of the results in memory.
There are different types of queries and each query demands a different approach to
achieve this behaviour. Queries with a constant size of the result, like profiling and
explain queries, can have a simple vector of results from which the results are
lazily pulled. For most of the queries that have variable size of the result, we
prepare all the necessary resources for the execution and ask for the next result only
when it's needed after which the results are streamed instantly to the client.
The resources are cleaned after the PULL request that returned the
last result. This is possible because of Memgraph's lazy way of handling the execution.
The query that was surprisingly the hardest to implement lazily was the DUMP query.
By itself, it's really simple to implement this query. You analyse different parts of
your database and, as a result, send a query that defines that part. For example, we
iterate each vertex in our database, and we send back a query for creating that vertex.
As we said before, creating vertices is only part of the DUMP query result. We need to
do the same thing for many different parts, like defining indexes and constraints, and
with the new Bolt protocol we need to do everything lazily. That means that the execution
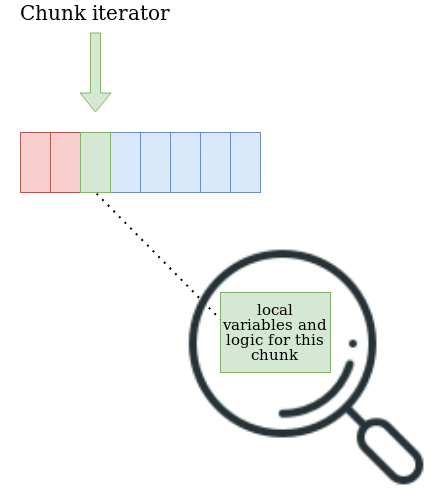
of DUMP query can stop in any part, at any time. A solution we ended up going with was
defining each part as a self-contained chunk. Each chunk needs to keep track of its status
to continue from where it left off and to know when it finished. We also need to define
an object that will iterate those chunks, continuing to the next chunk only when the
the previous was finished. This way we don't need to think about other chunks while defining
each chunk. We can easily add a new chunk by implementing a specific interface, and the most
the important thing is, no results are kept in memory.
qid parameter
While in explicit transaction, each RUN message returns a qid which uniquely defines
that execution. Using that qid, we can pull from each unfinished execution inside the
explicit transaction at any time. Along the small API changes of returning the qid, we
need to keep information about every unfinished execution. There were of course some memory
problems here and there, but the most important thing while designing the solution for this
is how will you find an execution that is represented by that qid. We decided to use the
qid as the index of each execution inside the list of executions. The only thing you need
to be careful of is deleting finished queries so your qids and indices don't go out of
sync.
All of the things above apply to the DISCARD_ALL message which was renamed to DISCARD.
Handling the DISCARD message
In previous versions of Memgraph, a DISCARD_ALL message didn't produce the correct behaviour.
While we were implementing the protocol the only information we had was that the DISCARD_ALL
message discards all of the results. We concluded that this means that we can safely ignore the prepared execution. As we figured that out much later, with the help from one of our community members, this message should have executed the query and simply discarded all the results, i.e. the results should not have been streamed. This mistake was noticeable by executing a query with a side effect and sending a DISCARD_ALL message. We fixed this in our newest version of server but it's a great example of how protocols should always be defined in as much detail as possible.
Keeping up with the future Bolt protocol versions
We plan to keep up as much as possible with the newest versions of the Bolt protocol. The pool of 4 versions gives us some leeway but it's still our job to keep up with the newest versions of Neo4j drivers so you can query Memgraph from many different languages.
Memgraph Drivers
Although Memgraph supports Neo4j drivers, we are also developing our own drivers using the Bolt protocol to deliver better performance and developer experience. So far, we have implemented the following drivers:
Conclusion
In this blog post we explored what it means to support a Neo4j driver and why it isn't always trivial to keep up with the newest versions.
Now that Memgraph supports the newest version of the Bolt protocol we encourage you to try it out and let us know what you think.
You can download the latest Memgraph on our download page.
If you can't come up with an example to try out Memgraph, no worries, we put together examples for each supported driver in our How to Query Memgraph Programmatically?.
Also, bugs and mistakes are always possible so feel free to report any strange behaviour on our Discord server.