Memgraph Storage Modes Explained
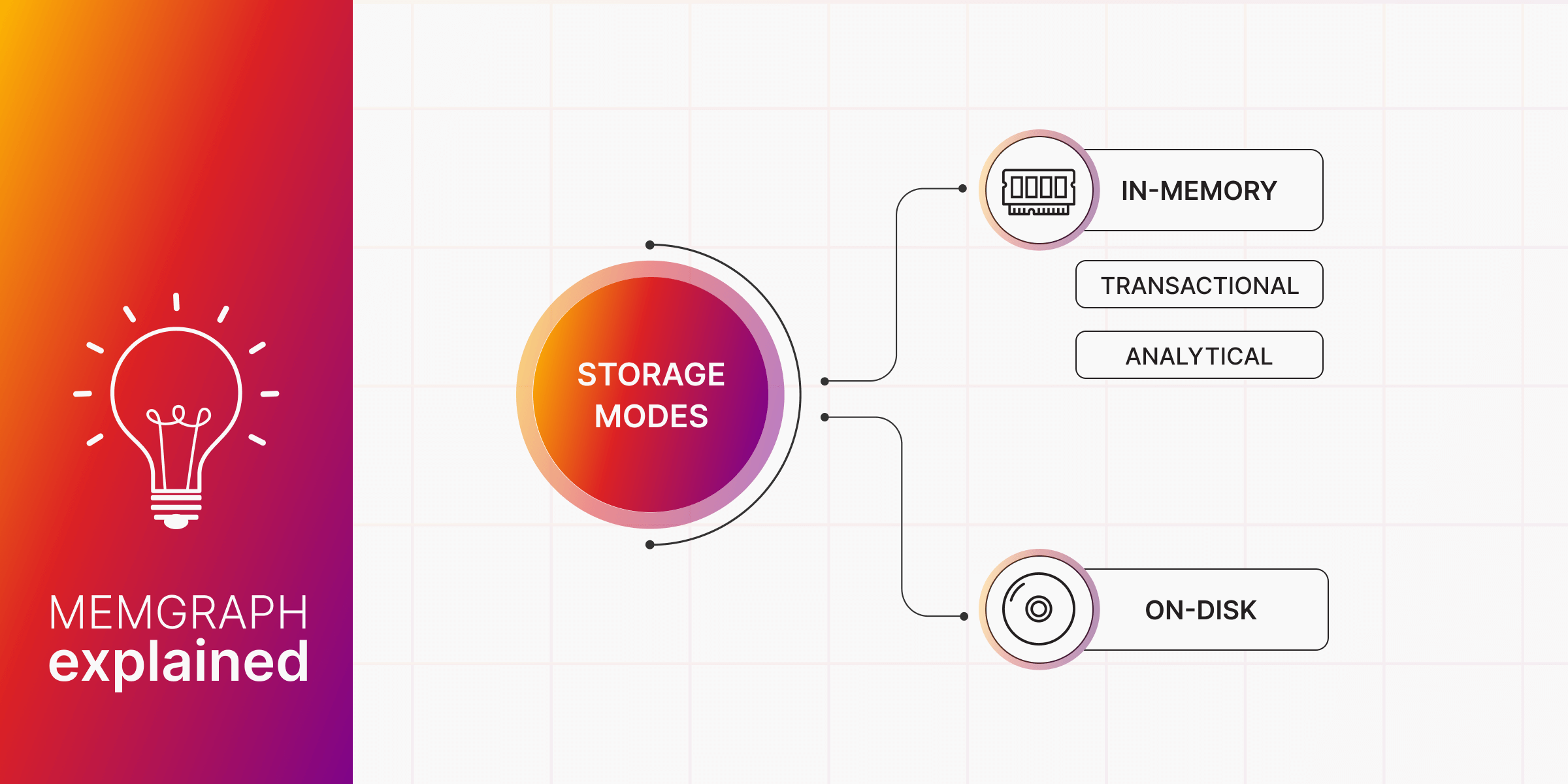
Memgraph is an in-memory graph database that ensures data persistence through ACID compliance by default. While it uses snapshots and write-ahead logs (WAL) for data recovery, in some cases, such additional files and insurance are not necessary. Other databases and analytics tools offer snapshots or WAL, but Memgraph offers both with different storage modes.
Before you start using them, here's a helpful guide on Memgraph storage modes so you can understand when to use them and why.
ACID Compliance in In-Memory Transactional Storage Mode
Previously, Memgraph only had one storage mode—in-memory transactional. The idea was to achieve excellent performance with the in-memory storage but still be ACID compliant.
Under the hood, a Delta object is the primary tool with which Memgraph provides atomicity, consistency, isolation and durability. These objects, inspired by the research presented in the Fast Serializable Multiversion Concurrency Control for Main-Memory Database Systems paper, record all transaction modifications to nodes or relationships. This mechanism ensures that periodic snapshots and write-ahead logs (WAL) are accurately maintained on disk for durability purposes. By default, Memgraph retains the three most recent snapshots and WAL files in the /var/lib/memgraph directory, facilitating efficient backup and recovery processes.
Another transaction property is isolation. It determines how transaction integrity is visible to other users and systems. Isolation can have different levels. For example, a lower isolation level allows many users to access the same data simultaneously but increases the number of concurrency effects (such as dirty reads or lost updates). A higher isolation level secures data consistency but requires more system resources, increasing the chances that one transaction will block another.
Memgraph defaults to the SNAPSHOT_ISOLATION level. It guarantees that all transaction reads observe a consistent database snapshot. This level also mandates that concurrent transactions can’t successfully commit if they are updating the same graph object, and such execution leads to conflicting transactions error.
You should either avoid such errors or retry the transaction for which its execution raised such an error. Still, it is essential to understand that those errors are expected to occur with concurrent transactions to ensure the ACID properties of the database transactions.
Because of strongly consistent ACID transactions in the in-memory transactional mode, you don’t have to worry about consistency even if you have mixed read and write transactions. Still, if you’re dealing with large-scale data import, you might notice memory overhead because Delta objects are quickly accumulated.
To avoid such issues and experience fast import without wasting valuable memory resources, Memgraph introduced the in-memory analytical storage mode.
Fast Writes Without Memory Overhead: In-Memory Analytical Storage Mode
In the in-memory analytical storage mode, Delta objects are disabled to achieve better performance without memory overhead. Which is significantly noticeable during data import. Besides that, no isolation levels are defined in the in-memory analytical storage mode.
Before diving into the details of this storage mode, let’s first explain the motivation behind disabling Delta objects. A while ago, we noticed a common challenge among our users: data import complexities. Since data import is one of the first steps when using a database, we knew we had to make improvements.
During data import, graph objects are frequently created and updated, which causes a fast accumulation of Delta objects. These objects, while crucial for maintaining ACID properties, also consume considerable memory resources. This is particularly noticeable when new relationships are formed, creating Deltas for both the starting and ending nodes. Although Deltas make it possible to undo such changes, they significantly slow down subsequent node updates, as every Delta must be processed before any new modification.
After detecting Delta objects as the main culprit for slow import, we were curious to know what would happen if we disabled them.
Here is the impact of removing Delta objects:
-
Multiple transactions can modify the same object and create relationships on the same node concurrently (there are no concurrent transactions errors anymore)
-
It leads to improved performance write-heavy workloads
-
The trade-offs include a lack of ACID guarantees; though it’s possible to manually create snapshots for durability.
-
Replication is disabled, as Deltas are essential for this process.
Everyone loves to hear about the positive impact on speed and performance, but let’s explain what not having ACID guarantees means.
-
Deltas being disabled lead to no WALs being created, meaning that if a write transaction fails for any reason, the changes can’t be rolled back -> no Atomicity guarantees
-
Transactions may fail and leave the database in an inconsistent state -> no Consistency guarantees
-
No isolation level, meaning if you have a long-running write transaction, other transactions can see the changes of ongoing transactions even if changes are not committed -> no Isolation guarantees
-
Snapshots and WALs are not created -> No Durability guarantees
When you understand what we’ve just covered and review the implications, you can get the most out of this storage mode and achieve the best performance with low memory cost.
Managing Large Datasets: Introducing On-Disk Transactional Storage Mode
What to do when the dataset is larger than the available RAM?
Ideally, if your data is larger than the available RAM, you would have a part of it stored on disk and the part used for the analysis in memory. Memgraph offers a third storage mode that does precisely that - on-disk transactional storage mode.
Let's go over how Memgraph's on-disk transactional storage mode differs from in-memory approaches. We'll get into the implementation and distinctive benefits it brings to the table.
Memgraph utilizes RocksDB as background storage to serialize nodes and relationships into a key-value format to achieve the on-disk transactional storage mode. This storage mode supports only the snapshot isolation level because it simplifies the query's execution flow since no data is transferred to the disk until the transaction is committed.
The durability is achieved with the help of RocksDB, which keeps its own WAL files. The imported data is on disk, while the main memory contains two caches—one for executing operations on the main RocksDB instance and the other for operations that require indexes. In both cases, Memgraph's custom SkipList cache is used, which allows a multithreaded read-write access pattern.
Concurrent transactions are handled differently in the on-disk storage mode than in the in-memory transactional storage mode. In the on-disk storage mode, the cache is used per transaction, so there is no need to question a certain object's validity, meaning the optimistic approach for conflict resolution between transactions is used.
In the on-disk storage mode, Deltas are still used to support Cypher's semantic of the write queries, but they are cleared after each transaction. That happens because the conflict is checked at the transaction’s commit time with RocksDB’s transaction support, which can optimize memory usage during execution. The design of the on-disk storage also simplifies the garbage collection process since all the data is on disk.
Before using on-disk storage mode, it is important to know the implications. Although keeping the hardware costs to a minimum sounds perfect, this storage mode is still experimental because it does not offer the same performance as the in-memory transactional storage mode. If you try out on-disk transactional mode, keep in mind that while executing queries, all the graph objects used in the transactions still need to be able to fit in the RAM, or Memgraph will throw an exception.
Choosing the Right Storage Mode for Your Needs
Which storage mode to use?
Deciding between Memgraph’s storage modes depends on your specific needs and the size of your data:
-
In-memory transactional storage mode - Stick with this default mode if its performance meets your current needs. It’s fast and reliable, providing ACID guarantees for your transactions.
-
In-memory analytical storage mode - Use this mode if ACID guarantees are not a priority and you’re looking to maximize performance and efficiency in memory usage. It’s ideal for analytical workloads where speed is of the essence.
-
On-disk transactional storage mode - If your dataset exceeds your available memory, this mode offers a practical solution. It allows you to work with a subset of your data stored on disk, balancing between performance and capacity. However, be mindful of its experimental nature and the potential tradeoffs in performance compared to in-memory modes.
Conclusion
Before making a switch, it’s important to understand the consequences of each storage mode on your workflows. Each has its benefits and limitations, affecting performance, data integrity, and how you manage your dataset.
Need help? If you are unsure which mode is best for you or if you have any questions, our DX team is here to help. Feel free to schedule an office hour call for personalized guidance. Additionally, our problem-solving Discord community is a great resource for advice, tips, and discussions with fellow users and our team.