
Recommendation Engines Faster Than Ever With Memgraph
Building a recommendation engine is never an easy task because, besides considering the quality of the actual recommendations, an important factor is the speed at which the recommendations are given to the customers. Users won't stand around and wait for the recommendation engine to slowly query the database in search of a perfect match, they are expecting results immediately. In recommendation engines, interactions such as users buying or rating some product happen at least every second, and all of the connections are stored in the database.
Recommendation engines recommend based on previous user activities and activities of other users with similar shopping habits as the targeted user, as well as general trends, noticed in the shopping habits of all clients. That’s a lot of dots to connect and gives relational database engineers hives just by thinking of running those kinds of queries. When it comes to highly interconnected data upon which recommendation engines are built, graph databases proved superior over traditional databases.
The pursuit of a graph database that can meet your performance demands has come to an end because Memgraph, as an in-memory graph solution written in C++, can meet any recommendation engine challenges and spit out instant recommendations that will improve the quality of customer care, attract customers and increase profits. Read on to find out how being in-memory and written in C++ makes Memgraph faster than other graph databases and how that makes the world of recommendation engines a better place.
What makes Memgraph so fast?
Platforms that use recommendation engines are never sleeping, data is constantly growing, users are reviewing and buying different products. All that data needs to be stored and analyzed to give fast recommendations by optimizing memory footprint and recommendation response time.
There are a lot of factors that contribute to Memgraph’s speed, but two features are the most important: efficient C++ codebase and in-memory data storage help provide instant recommendations and provide fast data access for your development team for data manipulation, visualization, clustering, ingestion, grouping and much more.
C++ codebase
Even though we all know that the power of C++ is unquestionable, Memgraph chose it because of its manual memory management and execution speed.
Manual memory management prevents memory wastage and ensures efficient allocation. Some languages, such as Java, use automatic memory management called Garbage Collector. On the upside, it decides what memory to free or allocate but also consumes a lot of resources, leading to a decrease in memory management performance and execution time. With C++, developers decide when to initialize and when to free memory which leads to better memory consumption because resources are only used when needed and immediately destroyed once they are not.
This is exceptionally useful for recommendation engines because the amount of that can get colossal, and the system needs to be designed to use the resources sparingly. Manual memory management helps developers to avoid running out of storage when recording all the activities users do in the system, which are crucial for calculating recommendations. With memory shortages, companies risk their recommendation engines becoming overloaded, which could lead to the unresponsiveness of the database server. An unresponsive recommendation engine means that recommendations are not provided at all or with a delay, resulting in fewer sales.
Another benefit of programs written in C++ is that they are compiled directly into machine code and run commands immediately, improving execution speed compared to programs written in Java or Python, which need to be interpreted during run-time.
What this means for recommendation engines is that running a recommendation algorithm such as PageRank to find queries with the best ratings over the same period of time can be up to 10x faster just by using a graph database written in C++ rather than a Java graph database. And the difference is even more substantial as data size increases.
Just because it’s written in C++ doesn’t mean every program utilizing Memgraph should be in C++. So don’t worry if you don’t code in C++ yourself, your recommendation engine can access Memgraph from many different languages.
In-memory data storage
Databases used by recommendation engines are constantly evolving, meaning users are creating new objects for products they are selling, and customers are browsing, creating wishlists, buying products and leaving reviews. At the same time, recommendation engines are querying the database to make different recommendations for individual users visiting the site.
Each time an on-disk database needs to do a mixed workload of operations (create, update, delete, read or analyze data), it needs to access the data saved on the disk. Accessing the disk is one of the slowest operations a computer can do. It is up to 100 000 times slower than accessing RAM.
There are certain methods that can accelerate on-disk databases, such as using cache, but the numbers add up when you consider all the recalculations done by the recommendation algorithms, let alone adding new products, reviews and customers.
In today's fast-paced world, where users want everything immediately, being an in-memory database makes a lot of sense. In-memory database prioritizes main memory rather than more conventional storage devices like hard disks and SSDs. In-memory databases keep the crucial data in a non-relational and compressed format in hot storage (VRAM) for frequent access and use cold storage (disk) to achieve persistency and backup. This concept of using hot and cold storage is referred to as data tiering.
The difference between in-memory and on-disk storage can be seen in the picture below:
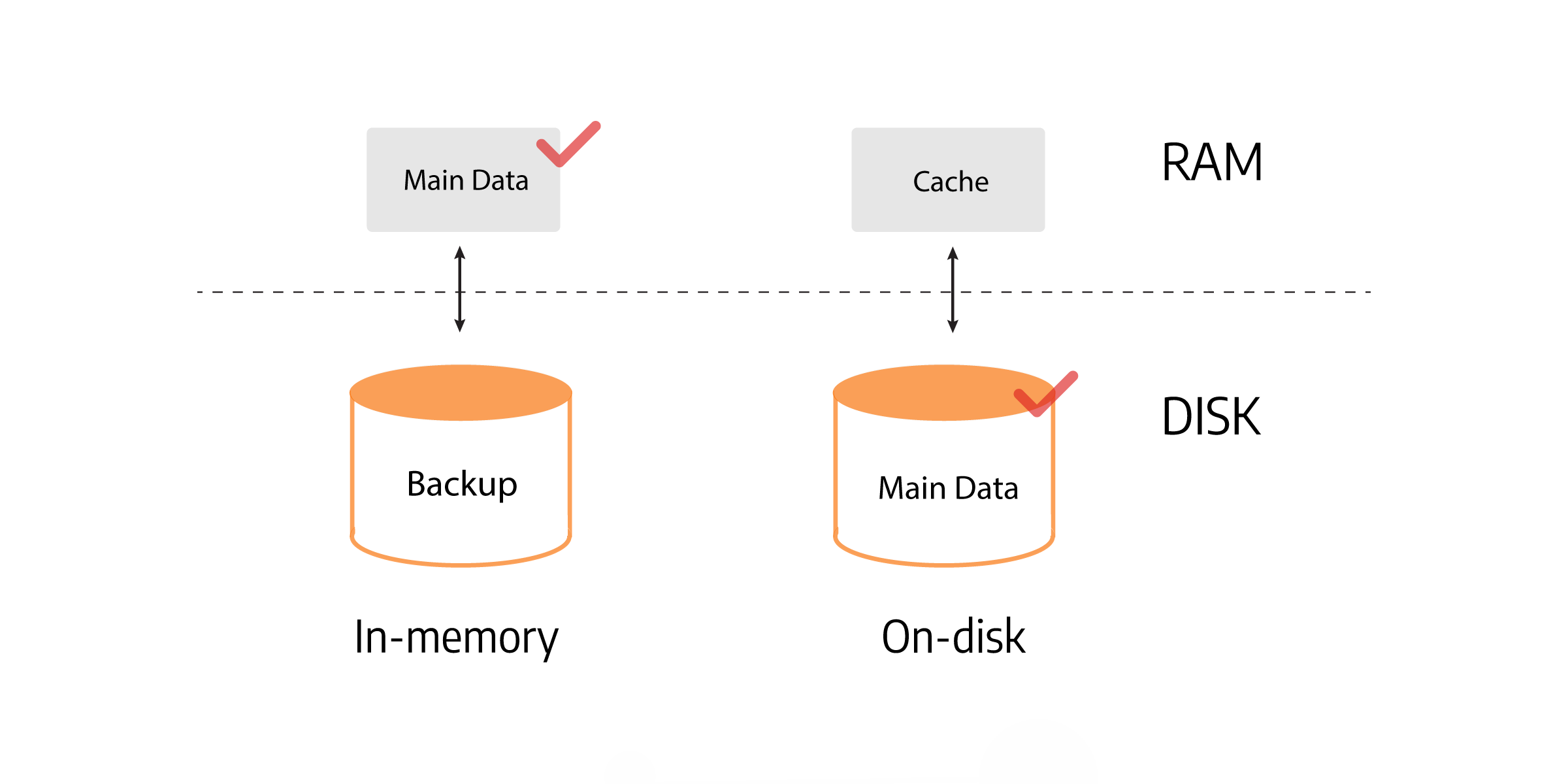
But being in-memory, doesn’t mean the data isn’t persistent. Memgraph continuously backs up data from the volatile random access memory (VRAM) to disk using transaction logs and periodic snapshots. On restart, it uses the snapshot and log files to recover its state to what it was before shutting down. It also means you can sleep soundly, knowing that data will not be lost if a server goes down or the system crashes because of a power outage.
Another advantage of an in-memory database is a smaller digital footprint. On-disk databases are difficult to manage because of too much redundant and unnecessary data. Every time a query is updated in an on-disk database, the data in each row doubles - one copy on disk, one copy in cache. With in-memory databases, the real-time data is updated as a whole whenever an update arrives.
In on-disk databases, when an object is being deleted, there is a risk of inconsistency between data that is alive both in the database and in the cache. For example, if a seller decides to remove some product they were selling, the product needs to be removed from the disk first, then from the cache. Hanging on to that data in the cache consumes valuable resources. With in-memory databases, there is only one delete action in the VRAM.
Data in recommendation engines are constantly created, deleted, updated and read. It is no wonder recommendations engines require a lot of memory resources, but Memgraph, as an in-memory database, allows you better memory management and speeds up getting those recommendations.
Real-Time analytics with Memgraph
Let’s say your data science team changed your recommendation algorithm thinking it would increase sales of a product in a specific category, and a completely opposite thing happens. Your business will start suffering, and nobody will notice until a developer extract data into a CSV, JSON, or some other file format and forwards it to the data science team. Upon analyzing the files, they will finally realize what is happening and where did wrong. Preventing these kinds of problems is very easy with real-time analytics.
Data in recommendation engines is event-driven. Data is created whenever a user interacts with the recommendation engine platform, for example, by buying or rating a product. Real-time analytics enables turning new data into valuable insights instantly. Also, it offers low response times and can deal with large amounts of data with high velocity. As a result, it can answer queries within seconds, making it possible for your data science team to understand correlations, automate processes, make predictions, and correct errors immediately.
Ingesting data from the recommendation engine into a database in real time is possible by using stream processing. As opposed to batch processing, with stream processing, the recommendation engine developers can see the behavior of the users, recalculate their recommendation algorithms and see the impact as soon as it acquires new data.
Memgraph supports getting data from many different stream sources like Kafka, Pulsar and RedPanda. The great thing about Memgraph for real-time analytics is that you can use Memgraph Lab and Orb for visualizing your data and extracting useful information, for example, which products from different categories your customers are buying.
CONCLUSION
In today’s fast-paced world, recommendation engines need to keep up. The first step is switching from relational databases to graph databases, and there is no better graph database to help you fulfill all the recommendation engine demands than Memgraph. If you want to start building a recommendation engine with Memgraph check out these articles about Spotify Recommendation and Amazon Recommendations.