Memgraph as a Graph Analytics Engine
This blog post discusses Memgraph as a graph analytics engine, highlighting its capabilities for managing graph data. Specifically, we concentrate on the in-memory analytical mode, a feature designed for speed and efficiency.
Unlike the ACID-compliant in-memory transactional mode, which ensures data integrity and consistency, the in-memory analytical mode is optimized for rapid, concurrent data imports without the burden of memory overhead. Our blog post will primarily focus on this analytical mode, showcasing how it supports high-performance data processing tasks.
Memgraph Storage Modes
Memgraph’s architecture has been built natively for in-memory data analysis and storage. Now, being ACID-compliant, it ensures consistency and reliability in its core design. However, Memgraph also offers flexibility with three storage modes:
- in-memory transactional
- in-memory analytical
- on-disk transactional.
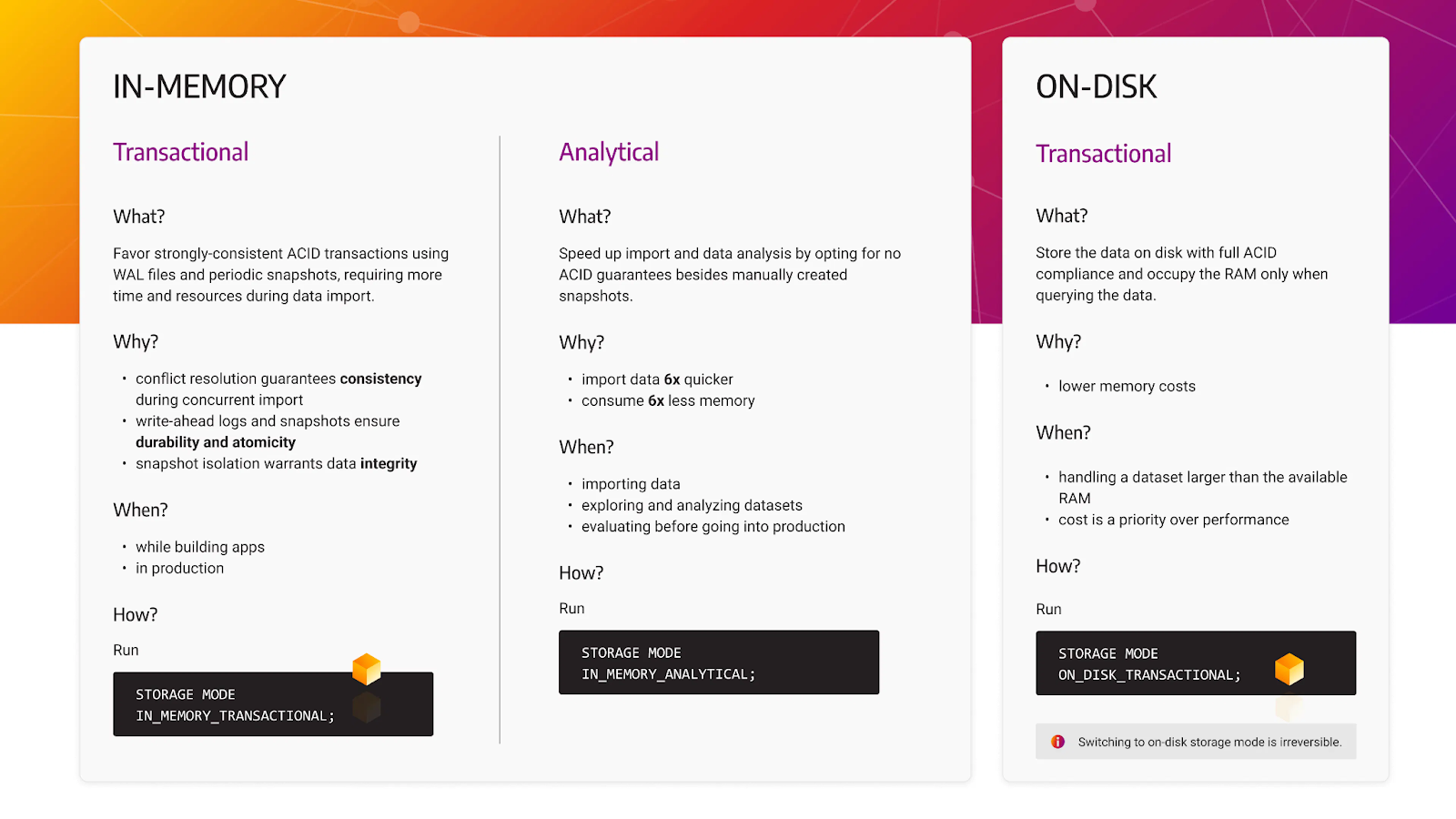
In-memory transactional storage mode is designed to prioritize data integrity and transactional safety. It adheres to ACID principles—atomicity, consistency, isolation, and durability.
On the other hand, in-memory analytical storage mode is optimized for analytical operations and speed, favoring performance over transactional safety. This mode allows for faster data processing by eliminating the overhead associated with tracking every change.
We’ve already covered a lot of details on why in-memory analytical mode was introduced and how it works under the hood, so be sure to check it out.
Optimizing Data Import with In-Memory Analytical Storage Mode
The in-memory analytical storage mode has significant advantages, particularly for handling large-scale data imports efficiently. As previously mentioned, this mode is designed to alleviate specific challenges you can encounter in the in-memory transactional mode. For example, during heavy concurrent data operations. Let’s discuss.
In the in-memory transactional storage mode, each node and relationship in the graph database is linked to a Delta object. These Delta objects are responsible for tracking all changes made during transactions. Such a setup ensures transactional integrity but at a certain cost:
-
Memory overhead - Each graph object’s link to a Delta object increases the total memory usage, as Delta objects themselves occupy additional memory.
-
Conflicting transactions - Delta objects track changes across concurrent transactions. However, this can lead to conflicts when multiple transactions simultaneously modify the same graph object. For example, adding a property to the same node. These conflicts can result in errors, requiring you to retry and slowing down your data import process.
We’ve developed the in-memory analytical storage mode to address these issues and streamline the data import process.
How?
-
Disabling Delta objects → By not using Delta objects, the analytical mode eliminates the root cause of conflicting transactions errors and reduces memory overhead.
-
Efficient concurrent data imports → If you don’t have Delta objects, you get faster and more efficient data imports, even with numerous concurrent operations. This is particularly beneficial when following data import best practices, such as those outlined for LOAD CSV and Cypher queries, where the strict ACID properties are not a prerequisite.
-
Use recommendations → After completing the data import, you might want to switch back to the in-memory transactional mode for operations that require write access and depend on ACID properties for consistency. For read-only queries, continuing with the analytical mode is an option, provided you are aware of its limitations and operational characteristics. Check out the implications for storage mode usage.
Accelerating Data Integration with In-Memory Analytical Storage
Everything we've just outlined makes sense in theory. But! Let's go over how it works in real life with our client, Sayari. This company provides access to a vast public records database and financial intelligence. We’ll use Sayari as an example to highlight how switching to an analytical storage mode can revolutionize data management and processing.
Sayari’s platform is designed to map out the connections between various entities by continuously aggregating a wide range of data. The process involves frequent updates and expansions of their database to include new relationships and records. Previously, Sayari started with a relational database, then moved towards a graph database. However, they ran into challenges such as:
-
Delayed graph updates, which took several days to process,
-
Performance bottlenecks with the inability to handle large-scale concurrent data imports efficiently.
When Sayari transitioned to Memgraph’s in-memory analytical mode, here’s what changed:
-
Efficient data import by being able to import vast amounts of data without the burdensome memory overheads. This change significantly accelerated the update process.
-
Preserved functionality despite the shift in data management strategy. Sayari uses Cypher queries to analyze their newly updated graph database, benefiting from both the language’s expressiveness for data retrieval and Memgraph’s fast handling of imports and queries.
The implementation of this mode enabled Sayari to rebuild a graph database containing 1.4 billion nodes every two weeks from scratch! Moreover, they maintained a high-performance level, executing over 16,000 queries while ensuring that more than 99.8% of these queries were processed in under 10 seconds.
Here’s the customer story in more detail to learn how Sayari utilizes Memgraph for network risk analysis.
Which storage mode to use?
Deciding on the best storage mode for your specific needs can be challenging, as there is no universal solution that fits all scenarios. Our experience has shown us that each project is unique, with its own requirements and best practices. To navigate this, we encourage you to reach out to us.
Join Our Discord Community
Join us on Discord and share your use case with our Discord community, we’d love to chat.
Schedule Office Hours for a Direct Conversation
If you prefer a more direct interaction or need detailed guidance, schedule a call with us in the DX team! We’ll work together to identify the storage mode that aligns best with your technical requirements.
We're committed to supporting your journey and are excited to learn about your project. Whether through our community discussions or a one-on-one call, we're here to help you make an informed decision that propels your project forward.