Make Smarter Decisions Analyzing a Knowledge Graph Built With Memgraph
In the new age, actually having data is less and less of an issue. What to do with all that data and how it can help our business - that is the real issue. Data is stored in different locations using different storage mechanisms, and for most companies, it just sits there covered in a cloud of virtual dust. Ten years ago, Google announced it uses the concept of knowledge graphs for its search engine to provide more detailed results, which led to more and more companies employing such solutions to uncover knowledge in data. But companies can get the most value from knowledge graphs only with the right combination of connected data and systems to infer the knowledge.
With knowledge graphs and graph databases, companies quickly uncover hidden information from data stored and dispersed over different silos. The first step towards inferring new knowledge is to gather all the data stored in separate silos. But more needs to be done than just collecting data in one place. It’s necessary to examine patterns within the interconnected nodes and their relationships to deduce new relationships which will uncover knowledge. Graph databases are a natural solution to storing and exploring interconnected data, the very purpose of knowledge graphs. Companies using different storage solutions face performance, scalability and adaptability issues.
The Memgraph ecosystem is an ideal solution for knowledge graphs. Memgraph’s database is in-memory which boosts performance. It offers many out-of-the-box graph analytics algorithms within its open-source graph algorithm library that help analyze data and find patterns. Knowledge graphs can also be easily visualized with a visualization tool capable of quickly rendering large graphs.
Read on to learn how to start inferring new relationships and knowledge.
Infer knowledge quickly by using in-memory storage
The most common solution for inferring knowledge is the pattern-matching technique. For example, let’s say you want to examine relationships between employees and departments and find employees that belong to certain departments that work in the production section. The system needs to examine the relationship between employees and departments and check if each department is a part of the production section, then return only those that match the pattern.
Examining all those connected relationships is problematic for non-graph database solutions, especially relational databases. It would require multiple table joins. The complexity of a table join is often equal to the cardinality of the table multiplied by the table you want to join it with. For example, if there is a table of employees that needs to be joined with a table of departments through some inner table, complexity could be O(T1T2T3), where T1 is the first table, T2 is the second and T3 is the third table.
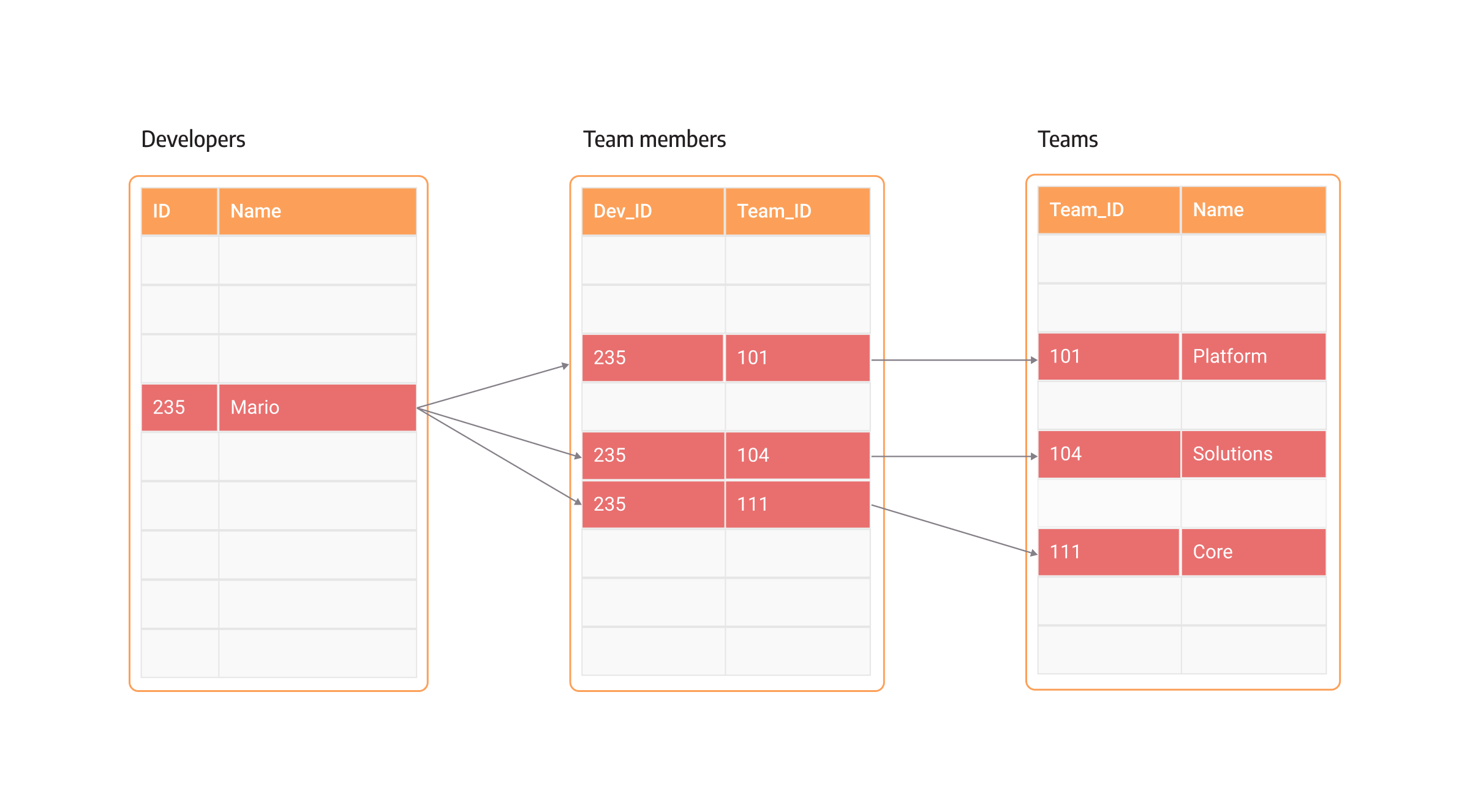
The image below shows the idea of table joins with employees and departments.
And here is what looking for such a pattern entails in a graph database.
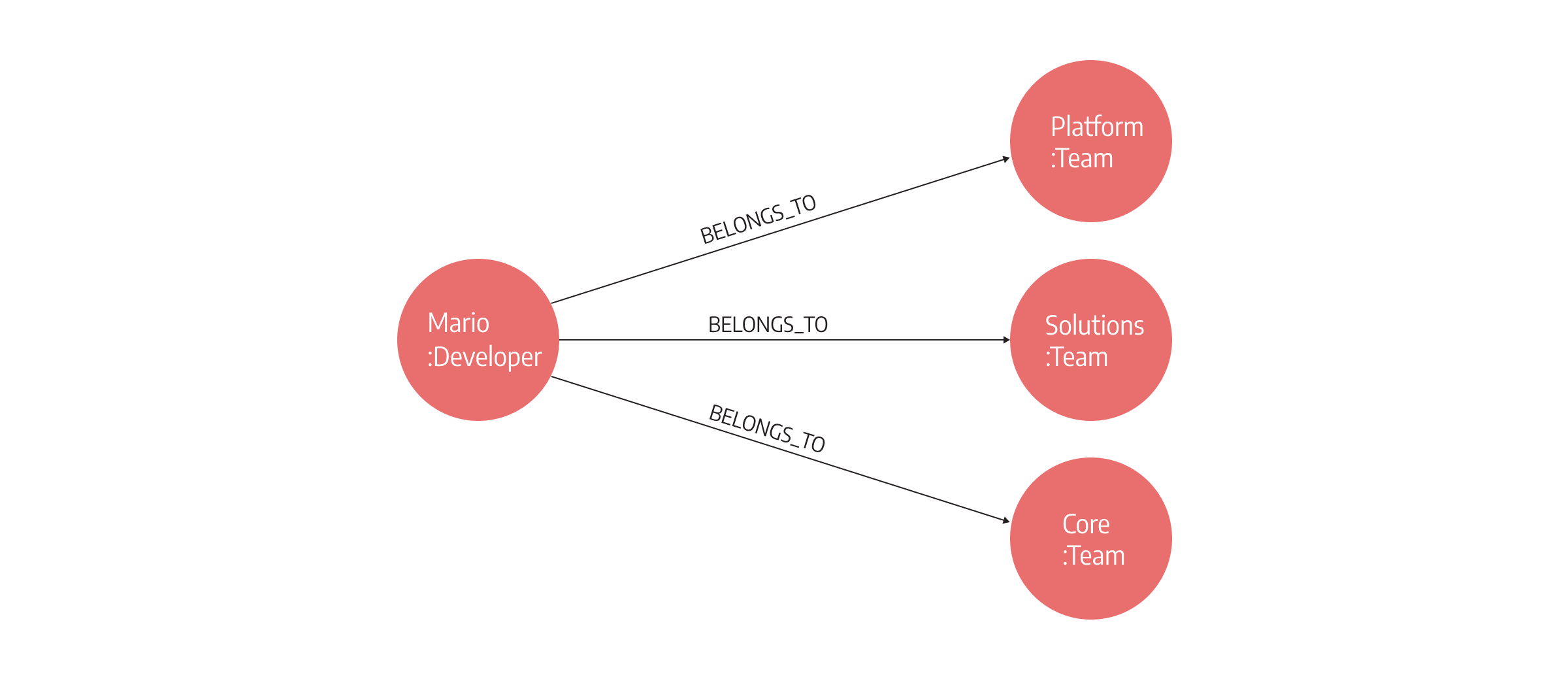
The pattern-matching technique can be described as hopping from one node to another. Node hopping is also great for checking if there is a certain dependency path between two sources. Graph databases work in terms of index-free adjacency, doing a direct memory walk when checking whether there is a relationship from one node to another.
That is why Memgraph performs pattern matching and node hopping exceptionally quickly compared to relational databases or any other solution.
Memgraph's storage engine stores data in memory. No time is wasted to move the data from disk to memory to be analyzed, as some graph databases and all graph libraries need to do. Graph libraries struggle with loading datasets in memory, as well as storing that data efficiently.
Even though data is stored in memory, there is no need to worry about losing it. Memgraph creates snapshots of data and write-ahead logs stored on the system’s disk drive to ensure data persistence.
Gain new insights without writing a single line of code
Let’s see how Memgraph can help you uncover hidden knowledge using the example of dependencies. Let’s say you are struggling to get answers to the following questions:
- What are all of the dependencies of a certain product?
- What are the top 10 most dependent parts in my system I always need to have ready?
The first question can be answered by using the descendants algorithm, which will find all dependencies of the product that needs to be made. The second question will be answered by PageRank, which will find the most dependent parts in the system. Luckily, there is no need to think about developing these algorithms, as in Memgraph, they are available out of the box as a part of the open-source Memgraph’s Advanced Graph Extensions (MAGE) library.
They are called in queries to perform analysis and provide you with results. Look at the examples below:
What are all of the dependencies of a certain product?
MATCH (n:Node {id:1})
CALL nxalg.descendants(n)
YIELD descendants
RETURN descendants;What are the top 10 most dependent parts in my system I always need to have ready?
CALL pagerank.get()
YIELD node, rank
SET node.rank = rank
RETURN node, rank
ORDER BY rank
LIMIT 10;Many other algorithms and procedures are also available, such as dynamic algorithms and integrations for reading data from different sources.
Dynamic algorithms will help you analyze data inputs in real time whenever a change in the database occurs. Unlike traditional static algorithms, dynamic algorithms quickly recalculate analytics results by analyzing only the local changes in the graph. There is no need to recalculate everything from the first node as dynamic algorithms consider the local nature of change and recalibrate stats in the graph. All dynamic algorithms in MAGE are developed in C++, which adds to their performance.
For graphs containing more than million nodes and edges, MAGE has integrated CUDA-powered graph analytics from NVIDIA. They will help you make the most of your complete setup, including graphics cards.
Design custom analytics without any performance degradation
Memgraph recognizes that flexibility is important and that the perfect solution that covers every use case doesn’t exist. Suppose your use case is not covered with any of the presented algorithms. You can develop custom-written algorithms which will return the value you require to make your business as successful and stress-free as possible. If you are versed in Python, C++, or Rust, jump to our documentation page and follow the directions on analyzing the knowledge graphs with your algorithms. The C++ API was designed especially for writing custom query modules as it comes close to writing code in Python, but taps into the performance capabilities of C++.
Analyze only the part of the graph that brings value
Knowledge graphs are heterogeneous graphs with a semantic layer on top, which adds new value. But most algorithms work only on homogeneous graphs. By combining the graph projection feature and MAGE analytics, it is possible to restrict analysis only to a specific part of the graph.
For example, let’s say you have a heterogenous graph consisting of different node labels like Hetionet. If you want to analyze which gene is mainly affected by diseases, you need to analyze only a part of the data. In some graph databases, you need to make a new graph instance that contains only those nodes and relationships you want to analyze. Such a process is painful, especially if the graph is complex and you need to filter out relationships from your CSV files or relational databases. In Memgraph, you can create a subgraph from the whole graph and perform an analysis only on the part of the data you need.
Here is how creating a subgraph and running a PageRank to find the most common symptoms when talking about diseases would look in Cypher:
MATCH (n:Disease)-[]->(m:Symptom)
WITH project(p) as disease_graph
CALL pagerank(disease_graph) YIELD node,rank
RETURN node, rank
ORDER BY rank DESC;Draw conclusions with the help of a visualization tool
The ecosystem would not be complete without a visualization tool. Visuals extend the human capacity to take in, comprehend, and synthesize large amounts of new information more efficiently, especially to find patterns and relationships.
Memgraph Lab offers custom visualizations that can render the current state of the graph in a matter of milliseconds. The extensive possibilities of customizations allow for making the best view for the user to make the most out of their perception skills. With visualized knowledge graph, it’s easier to grasp the processes happening in the system and start inferring knowledge and emplacing different systems to continue doing similar tasks for you. In the end, tools are here to help us make the most of the problem we want to solve.
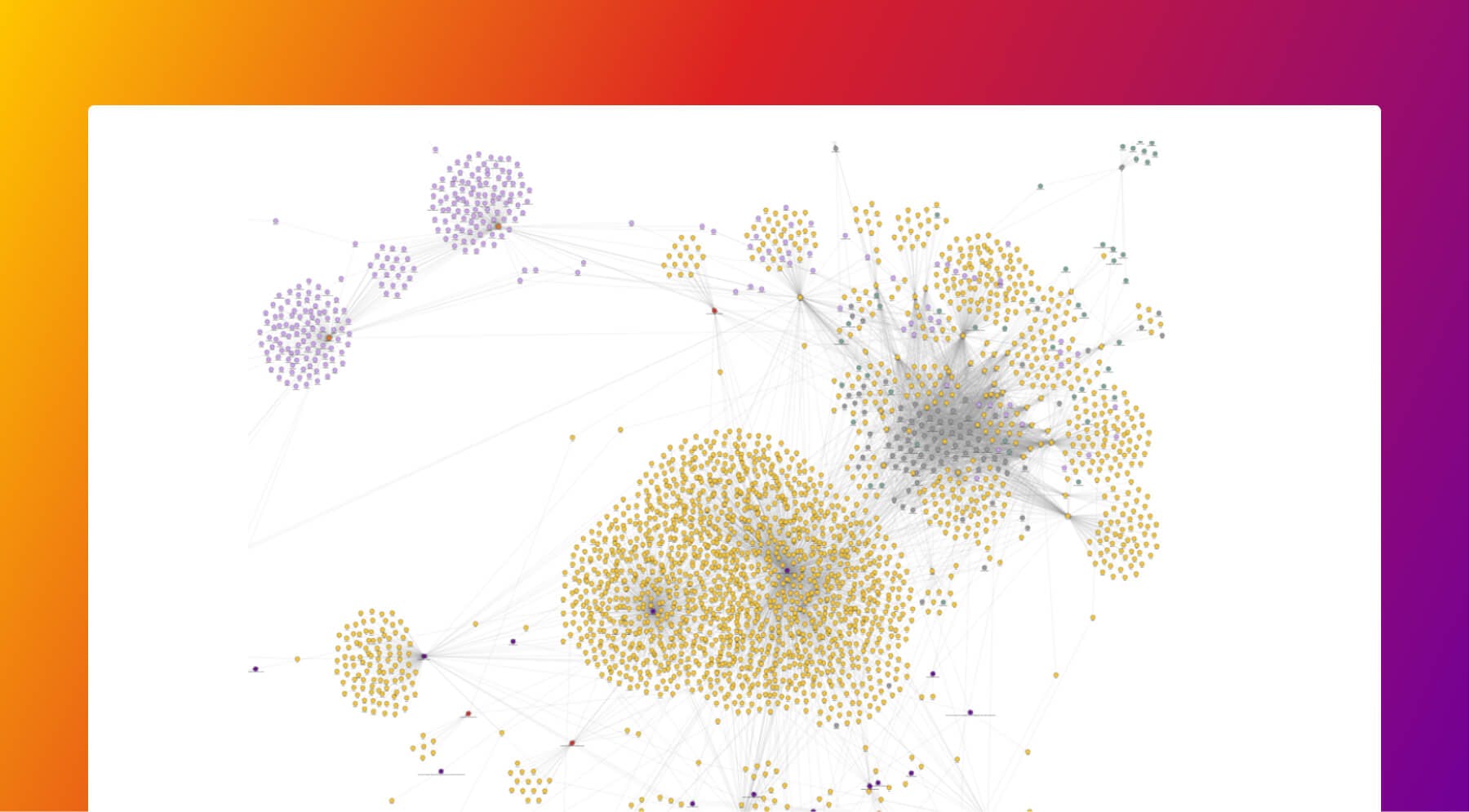
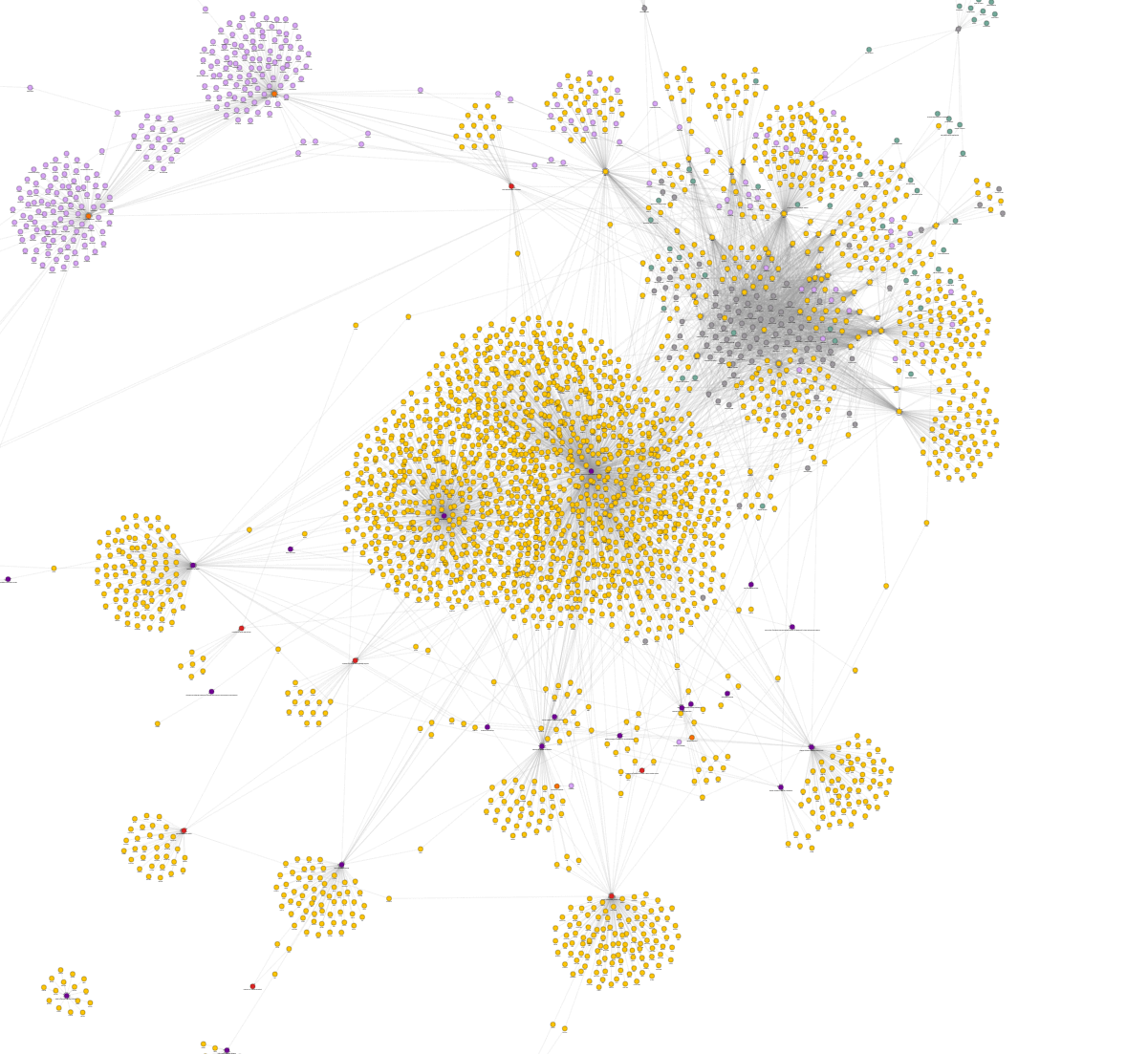
The image below shows how genes (in yellow) participate in certain biological processes (blue). Relationships between certain compounds (light purple) and genes are also easily observed. All these nodes are very interconnected, and a visual tool can help excerpts reach certain conclusions more easily.
Conclusion
While inferring knowledge is complex due to siloed data, the right toolset can make it a manageable task. Once the data is connected, the in-memory capabilities of Memgraph database allow you to quickly run analytics to infer new knowledge, from pattern matching to tracking descendants.
Memgraph also allows you to design custom graph analytics without suffering any performance degradation while writing C++ code in an almost pythonic way. And once you visualize data in Memgraph Lab, you can draw even more conclusions. All these small performance benefits accumulate and help your company gain a competitive edge when deciding the direction of that next big decision.