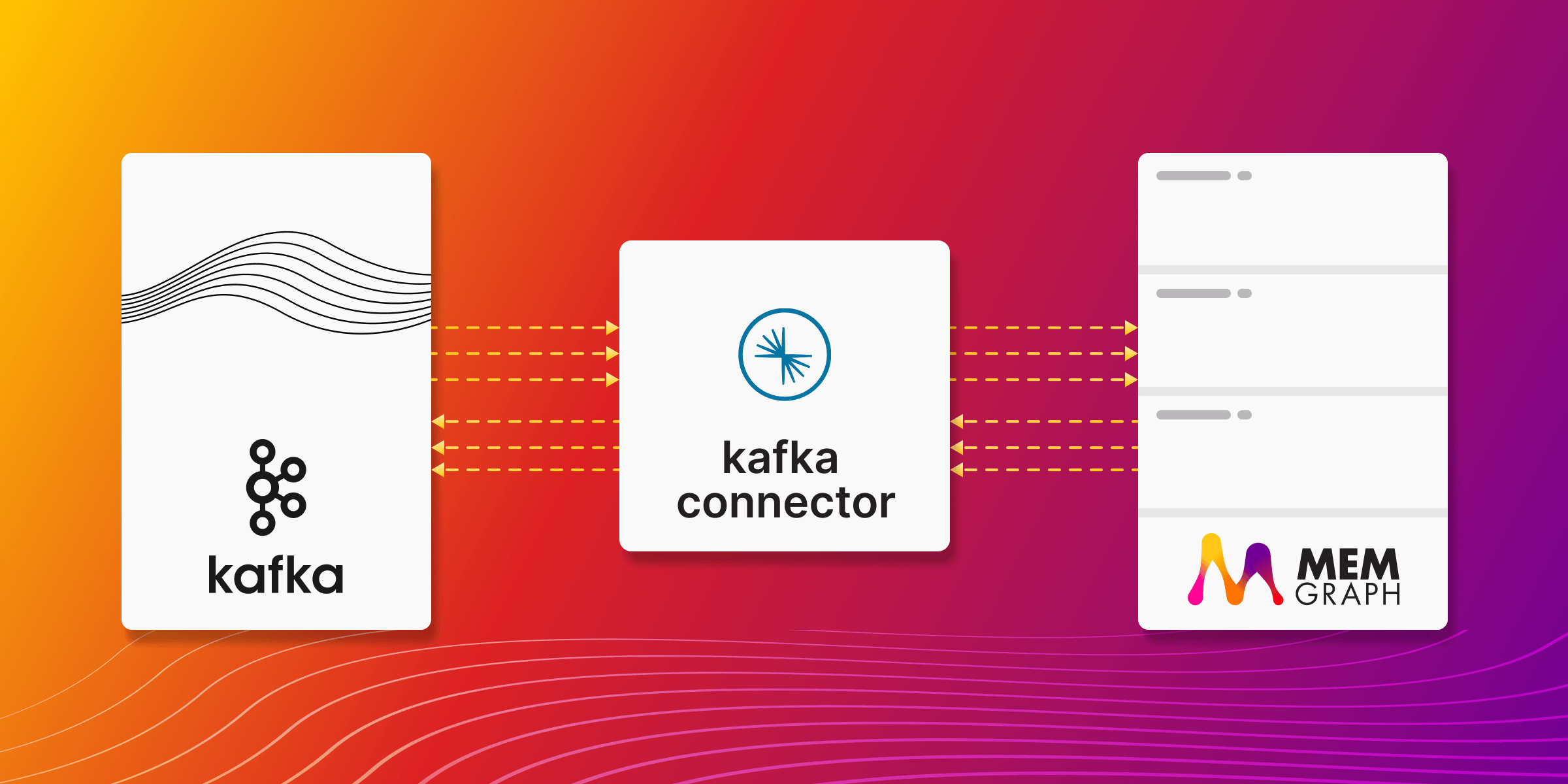
Integrating Confluent's Kafka Platform with Memgraph for Efficient Data Management
In today's world, data sources are everywhere, constantly producing and demanding data. The flow of data is increasing exponentially, a trend clearly visible in the number of connected devices around us. These devices are in a constant state of sending and receiving data, creating an unending stream of information. The critical question then becomes: how do we effectively process and store this data? Here, the integration of Confluent's Kafka platform with Memgraph offers a solution. Memgraph, as an in-memory graph database, is exceptional in rapid data ingestion and processing. Its capacity to handle large volumes of data quickly makes it an ideal choice for real-time data operations. This capability is significantly enhanced when integrated with Kafka, particularly the Kafka platform provided by Confluent.
Confluent’s Kafka platform extends the basic capabilities of Kafka, offering additional tools and services that streamline the implementation of Kafka in enterprise environments. It's known for its durability, scalability, and ability to handle high-throughput data streams, making it a robust choice for complex data architectures. Kafka acts as a versatile conduit, capturing and directing data from a myriad of sources, facilitating efficient processing and analysis. Together, Confluent's Kafka platform and Memgraph form a formidable pair. They empower organizations to not only manage today's vast and swift data streams effectively but also to extract valuable insights from this data. In this guide, we will explore using Docker Compose to orchestrate an environment that capitalizes on the strengths of both Kafka and Memgraph. This setup is designed to demonstrate the seamless integration of data flow between the two systems, ensuring that your data management is as dynamic and efficient as possible.
Kafka and Confluent Kafka: What's the Difference?
Although Kafka and Confluent Kafka sound similar, they are not exactly the same. There are similarities and overlaps, but also distinct differences. To avoid confusion, here's a brief explanation: Apache Kafka is an open-source stream-processing platform developed by the Apache Software Foundation, primarily focused on high-throughput, real-time data handling. It enables the building of robust data pipelines and streaming applications, facilitating the publishing, subscribing, storing, and processing of continuous data streams. Confluent Kafka, provided by Confluent, Inc., a company founded by the original creators of Apache Kafka, extends the basic Kafka platform. It includes the core functionalities of Apache Kafka and adds enterprise-ready features. These enhancements, like Kafka Connect and Kafka Streams, offer advanced capabilities for database integration, stream processing, and enterprise-grade security, scalability, and management. While Apache Kafka lays the groundwork, Confluent Kafka builds upon it, specifically tailoring to the needs of enterprise-level data architecture.
Integrating Kafka Connect with Memgraph to Ingeste IoT data streams
Internet of Things (IoT) devices, ranging from simple sensors to complex systems, continuously produce data. Much of this data comes in the form of streams – unending flows of information that capture everything from environmental conditions to user interactions. This is where Kafka, and by extension Confluent Kafka, becomes particularly valuable.Kafka's primary strength lies in its ability to handle these data streams efficiently.
Imagine the possibilities when this is extended with the capabilities that Memgraph brings as the primary datastore. Memgraph's in-memory processing power allows for rapid analysis and querying of data as it streams in from Kafka. This synergy enables not just the efficient ingestion of large volumes of IoT data, but also the ability to gain instant insights through real-time analytics. Memgraph enhances the data flow by providing a platform for complex queries and relationship mapping, crucial for understanding interconnected IoT networks. The combination of Kafka's robust data streaming with Memgraph's high-speed data processing and analysis opens up new horizons in IoT data management, making it possible to leverage real-time data for immediate decision-making and predictive analytics, enhancing the overall responsiveness and intelligence of IoT systems.
The integration of Confluent's Kafka platform with Memgraph as the primary datastore presents a unique opportunity to enable dynamic data flow in an IoT ecosystem. This section provides a quick start guide on setting up this integrated environment using Docker Compose, running within Docker containers.
Setting Up the Environment
The orchestration of this environment involves key components of Confluent's Kafka platform, each playing a crucial role:
- Zookeeper: A fundamental component for Kafka's operation, Zookeeper handles configuration management and synchronization across the Kafka ecosystem.
- Kafka Broker: This is the heart of Kafka, acting as the core message broker. It facilitates messaging and streaming capabilities, enabling the efficient flow of data.
- Schema Registry: Responsible for managing the schema of the data traversing through Kafka, the Schema Registry ensures consistency and structure in the data streams.
- Kafka Connect: This element acts as a bridge connecting Kafka with external systems, including Memgraph. It plays a critical role in the seamless data exchange between Kafka and the database.
Configuring the Data Flow
The integration aims to establish a dynamic, bidirectional data flow, leveraging Kafka Connect in two primary configurations:
- Source Instance Configuration: In this setup, Kafka Connect is configured with a source instance that listens for specific changes occurring within the Memgraph database. When changes are detected, they are published to a designated Kafka topic, such as
my-topic. - Sink Instance Setup: The sink instance within Kafka Connect subscribes to the
my-topictopic. It is responsible for processing the incoming messages from this topic and applying the corresponding changes back to the Memgraph database.
This configuration results in a seamless data flow between Memgraph and Kafka, exemplifying how Kafka can effectively act as a conduit for both sourcing events from and sinking data back into a graph database like Memgraph.
Practical Example: Kafka Connect with IoT Sensor Data
Imagine you have IoT devices equipped with temperature and humidity sensors. Periodically, these devices transmit their readings to Kafka. The data sent follows this format:
{"sensorId": "<sensorId>", "temperature": <temperature>, "humidity": <humidity>, "timestamp": "<timestamp>"}
In this setup, each message contains a sensor ID, temperature reading, humidity level, and a timestamp. This data structure is crucial for efficiently organizing and analyzing the sensor data. Next, we'll explore how to set up Kafka Connect and Memgraph to process and store these data streams. The aim is to demonstrate a seamless flow of data from the IoT devices to Kafka, and then into Memgraph for real-time analysis. Before starting, make sure you have Docker and Docker Compose installed on your system. It’s also helpful to have a basic understanding of Kafka, Memgraph, and Docker Compose.
Setting Up Your Project Environment
First, create a folder for your project. This will serve as the central location for all your project files. Once you've created the folder, change your working directory to this new folder using the command line.
Next, within this directory, create a file named docker-compose.yml. This file is crucial as it will define the configuration for your Docker Compose setup, orchestrating how Docker manages the Memgraph and Kafka containers.
Now, add the following content to your docker-compose.yml file:
---
version: "3"
services:
memgraph:
image: "memgraph/memgraph-platform"
hostname: memgraph
ports:
- "7687:7687"
- "3000:3000"
- "7444:7444"
volumes:
- mg_lib:/var/lib/memgraph
- mg_log:/var/log/memgraph
- mg_etc:/etc/memgraph
zookeeper:
image: confluentinc/cp-zookeeper:7.3.0
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
broker:
image: confluentinc/cp-server:7.3.0
hostname: broker
container_name: broker
depends_on:
- zookeeper
ports:
- "9092:9092"
- "9101:9101"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker:29092,PLAINTEXT_HOST://localhost:9092
KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_CONFLUENT_LICENSE_TOPIC_REPLICATION_FACTOR: 1
KAFKA_CONFLUENT_BALANCER_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_JMX_PORT: 9101
KAFKA_JMX_HOSTNAME: localhost
KAFKA_CONFLUENT_SCHEMA_REGISTRY_URL: http://schema-registry:8081
CONFLUENT_METRICS_REPORTER_BOOTSTRAP_SERVERS: broker:29092
CONFLUENT_METRICS_REPORTER_TOPIC_REPLICAS: 1
CONFLUENT_METRICS_ENABLE: 'true'
CONFLUENT_SUPPORT_CUSTOMER_ID: 'anonymous'
schema-registry:
image: confluentinc/cp-schema-registry:7.3.0
hostname: schema-registry
container_name: schema-registry
depends_on:
- broker
ports:
- "8081:8081"
environment:
SCHEMA_REGISTRY_HOST_NAME: schema-registry
SCHEMA_REGISTRY_KAFKASTORE_BOOTSTRAP_SERVERS: 'broker:29092'
SCHEMA_REGISTRY_LISTENERS: http://0.0.0.0:8081
connect:
image: cnfldemos/cp-server-connect-datagen:0.6.0-7.3.0
hostname: connect
container_name: connect
depends_on:
- broker
- schema-registry
ports:
- "8083:8083"
volumes:
- ./plugins:/tmp/connect-plugins
environment:
CONNECT_BOOTSTRAP_SERVERS: 'broker:29092'
CONNECT_REST_ADVERTISED_HOST_NAME: connect
CONNECT_GROUP_ID: compose-connect-group
CONNECT_CONFIG_STORAGE_TOPIC: docker-connect-configs
CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: 1
CONNECT_OFFSET_FLUSH_INTERVAL_MS: 10000
CONNECT_OFFSET_STORAGE_TOPIC: docker-connect-offsets
CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: 1
CONNECT_STATUS_STORAGE_TOPIC: docker-connect-status
CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: 1
CONNECT_KEY_CONVERTER: org.apache.kafka.connect.storage.StringConverter
CONNECT_VALUE_CONVERTER: io.confluent.connect.avro.AvroConverter
CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_URL: http://schema-registry:8081
# CLASSPATH required due to CC-2422
CLASSPATH: /usr/share/java/monitoring-interceptors/monitoring-interceptors-7.3.0.jar
CONNECT_PRODUCER_INTERCEPTOR_CLASSES: "io.confluent.monitoring.clients.interceptor.MonitoringProducerInterceptor"
CONNECT_CONSUMER_INTERCEPTOR_CLASSES: "io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor"
CONNECT_PLUGIN_PATH: "/usr/share/java,/usr/share/confluent-hub-components,/tmp/connect-plugins"
CONNECT_LOG4J_LOGGERS: org.apache.zookeeper=ERROR,org.I0Itec.zkclient=ERROR,org.reflections=ERROR
command:
- bash
- -c
- |
confluent-hub install --no-prompt neo4j/kafka-connect-neo4j:latest
/etc/confluent/docker/run
control-center:
image: confluentinc/cp-enterprise-control-center:7.3.0
hostname: control-center
container_name: control-center
depends_on:
- broker
- schema-registry
- connect
ports:
- "9021:9021"
environment:
CONTROL_CENTER_BOOTSTRAP_SERVERS: 'broker:29092'
CONTROL_CENTER_CONNECT_CONNECT-DEFAULT_CLUSTER: 'connect:8083'
CONTROL_CENTER_KSQL_KSQLDB1_URL: "http://ksqldb-server:8088"
CONTROL_CENTER_KSQL_KSQLDB1_ADVERTISED_URL: "http://localhost:8088"
CONTROL_CENTER_SCHEMA_REGISTRY_URL: "http://schema-registry:8081"
CONTROL_CENTER_REPLICATION_FACTOR: 1
CONTROL_CENTER_INTERNAL_TOPICS_PARTITIONS: 1
CONTROL_CENTER_MONITORING_INTERCEPTOR_TOPIC_PARTITIONS: 1
CONFLUENT_METRICS_TOPIC_REPLICATION: 1
PORT: 9021
volumes:
mg_lib:
mg_log:
mg_etc:
Starting the Docker Compose Environment
With your docker-compose.yml file set up, it's time to bring your Docker environment to life. Open your terminal and execute the following command:
docker compose up -d
This command prompts Docker Compose to read the configuration in your docker-compose.yml file and start up the containers in detached mode. This means they'll be running in the background, without tying up your terminal.
Verifying the Container Status
To ensure everything is running smoothly, you can check the status of your containers. In the terminal, run:
docker compose ps
This command will display a list of all the containers managed by Docker Compose for your project, along with their current status. Look for the 'Up' status next to each container, indicating that they are functioning correctly.
Connecting to Memgraph and Confluent Control Center
Once all containers are up and running, you can start interacting with them:
- Memgraph Lab: This is a visual user interface for working with Memgraph. Access it by navigating to https://localhost:3000 in your web browser. Here, you can run queries and visualize the data stored in Memgraph.
- Confluent Control Center: To manage and monitor your Kafka environment, visit http://localhost:9021/clusters. This web interface may take a minute or two to become fully operational as the Cluster initializes and becomes healthy.
Configuring Memgraph as the Source for Kafka
To begin, set up Memgraph as the source database for streaming sensor data into Kafka topics. This requires using AVRO for message serialization.
Create a Configuration File: Save the AVRO configuration settings in a file named source.memgraph.json in your local directory. This file enables Memgraph to communicate with Kafka, serializing messages in the AVRO format.
Include the following settings in your source.memgraph.json file:
{
"name": "Neo4jSourceConnectorAVRO",
"config": {
"topic": "my-topic",
"connector.class": "streams.kafka.connect.source.Neo4jSourceConnector",
"key.converter": "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url": "http://schema-registry:8081",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "http://schema-registry:8081",
"neo4j.server.uri": "bolt://memgraph:7687",
"neo4j.authentication.basic.username": "",
"neo4j.authentication.basic.password": "",
"neo4j.streaming.poll.interval.msecs": 5000,
"neo4j.streaming.property": "timestamp",
"neo4j.streaming.from": "LAST_COMMITTED",
"neo4j.enforce.schema": true,
"neo4j.source.query": "MATCH (sd:SensorData) RETURN sd.sensorId AS sensorId, sd.temperature AS temperature, sd.humidity AS humidity, sd.timestamp AS timestamp"
}
}
Initiate Source Instance: Execute a REST call to establish the Kafka Connect source instance:
curl -X POST http://localhost:8083/connectors \
-H "Content-Type:application/json" \
-H "Accept:application/json" \
-d @source.memgraph.json
Creating Sensor Data Nodes in Memgraph
Use Memgraph Lab to input sensor data into your database. Run these Cypher queries to create sensor data nodes:
CREATE (:SensorData {sensorId: 'S101', temperature: 22.5, humidity: 45, timestamp: localDateTime()});
CREATE (:SensorData {sensorId: 'S102', temperature: 24.1, humidity: 50, timestamp: localDateTime()});
CREATE (:SensorData {sensorId: 'S103', temperature: 23.3, humidity: 48, timestamp: localDateTime()});
These commands will generate new messages in the my-topic topic.
Setting Up the Sink Instance
To sink messages from the my-topic topic back to the Memgraph database:
Create Sink Configuration File: Save the following JSON configuration in a file named sink.memgraph.json within your local directory.
{
"name": "Neo4jSinkConnectorAVRO",
"config": {
"topics": "my-topic",
"connector.class": "streams.kafka.connect.sink.Neo4jSinkConnector",
"key.converter": "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url": "http://schema-registry:8081",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "http://schema-registry:8081",
"errors.retry.timeout": "-1",
"errors.retry.delay.max.ms": "1000",
"errors.tolerance": "all",
"errors.log.enable": true,
"errors.log.include.messages": true,
"neo4j.server.uri": "bolt://memgraph:7687",
"neo4j.authentication.basic.username": "",
"neo4j.authentication.basic.password": "",
"neo4j.topic.cypher.my-topic": "MERGE (s:SensorData {sensorId: event.sensorId}) ON CREATE SET s.temperature = event.temperature, s.humidity = event.humidity, s.timestamp = event.timestamp ON MATCH SET s.temperature = event.temperature, s.humidity = event.humidity, s.timestamp = event.timestamp"
}
}
Configure the Sink Instance: Execute the following REST call:
curl -X POST http://localhost:8083/connectors \
-H "Content-Type:application/json" \
-H "Accept:application/json" \
-d @sink.memgraph.json
Testing the Setup
Verify in Confluent Control Center: Visit http://localhost:9021/clusters to check the creation of the my-topic topic and the operational status of both source and sink connectors.
Query Sensor Data in Memgraph Lab: Execute MATCH (s:SensorData) RETURN s; in Memgraph Lab to view the processed sensor data.
Simulate Additional Data: To simulate more sensor data, run another Cypher query in Memgraph Lab:
CREATE (:SensorData {sensorId: 'S104', temperature: 21.7, humidity: 47, timestamp: localDateTime()});
This will create a new SensorData node and trigger the data flow through Kafka Connect.
Conclusion
Now that you have learned how to set up and configure Kafka Connect with Memgraph using Docker Compose, you are well-equipped to handle seamless data integration. This integration is not just about data flow; it's about transforming raw data into intelligence, enabling real-time decision-making and enhancing the overall responsiveness and performance of IoT systems.
The combination of Kafka's data streaming capabilities with Memgraph's rapid in-memory processing allows for not just effective data capture and storage, but also for real-time data analysis.