
Introduction to Stream Processing
What is stream processing?
Stream processing is a type of big data architecture in which the data is analyzed in real-time. It is used where up-to-date crucial information regarding any system is needed. We can get crucial and valuable insights in the duration of a few milliseconds through this system.
Generally, the computations on this incoming real-time data are independent and usually consist of few data elements or a small window of real-time data.
All of this processing happens asynchronously. The data source and the stream processing work independently without waiting for a response from one another.
Stream processing infrastructure overview
There are three primary components of stream processing infrastructure. You can learn more about each from the articles we linked to:
- Real-time data source
- Data processing software framework (streaming analytics tools)
- Streaming analytics users or consumers
The data processing framework acts as the brain in this architecture. It enables the developers to decide which data event stream is important, which to discard and which to keep.
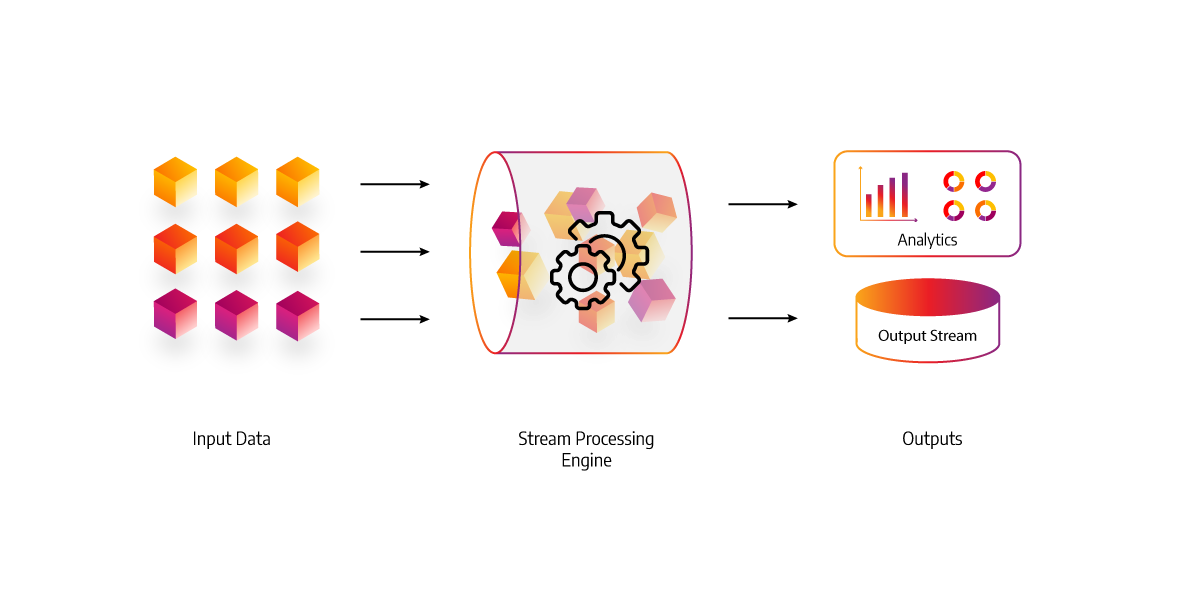
Stream processing vs batch processing
Stream processing is the process of analyzing and managing data in real-time – it’s the continuous, concurrent, and incremental evaluation of events as they happen. This means that, unlike traditional batch jobs, stream processing doesn’t need to wait until all the data has been collected before starting analysis or getting a result - you can start working on it straight away.
Batch processing refers to a method of processing high-volume data in batches or groups simultaneously, sequentially, and continuously, often at the end of a business cycle, e.g., the end of the month for payrolls. Batch processing makes calculations on an initially large dataset, which is then reduced to a smaller set of results. Here you can read more about batch processing examples.
If you want to learn more, take a look at our in-depth article about batch processing vs stream processing.
Stream processing examples and use cases
In most of the cases in stream processing, event data is generated because of some activity, and some action should be taken right away. Let's look at an example where we have many applications and are attempting to publish data to a Kafka topic (it allows developers to make applications that continuously produce and consume streams of data records). This information could be about who is using the application or about the application metrics. We'll call it accessibility data.
All of this data from numerous applications is published to a Kafka topic, which the security team needs to analyze and discover if something is wrong with our applications. As a result, all this data is streamed in real-time to Kafka.
What does stream mean in this context? It means that we are continuously pushing data into a Kafka topic, which is happening across apps.
For example, if we have 100 microservices, each of them publishes accessibility information about itself into a Kafka topic. We will use different frameworks like Apache Flink, Apache Storm, Beam, Memgraph, or Apache Spark to consume these messages in real-time from a Kafka topic and then process them into a data store. Since this is for security, we will filter out a lot of information that we get from the main Kafka topic, and we are going to publish only the required events we need to act upon.
So, based on the events we publish, we might have different applications which can consume these events and take actions in terms of alerting or directly going and shutting down systems, for example.
This is how we can create a stream processing framework, and the pipeline in which we are processing these messages in real-time is called a stream processing pipeline.
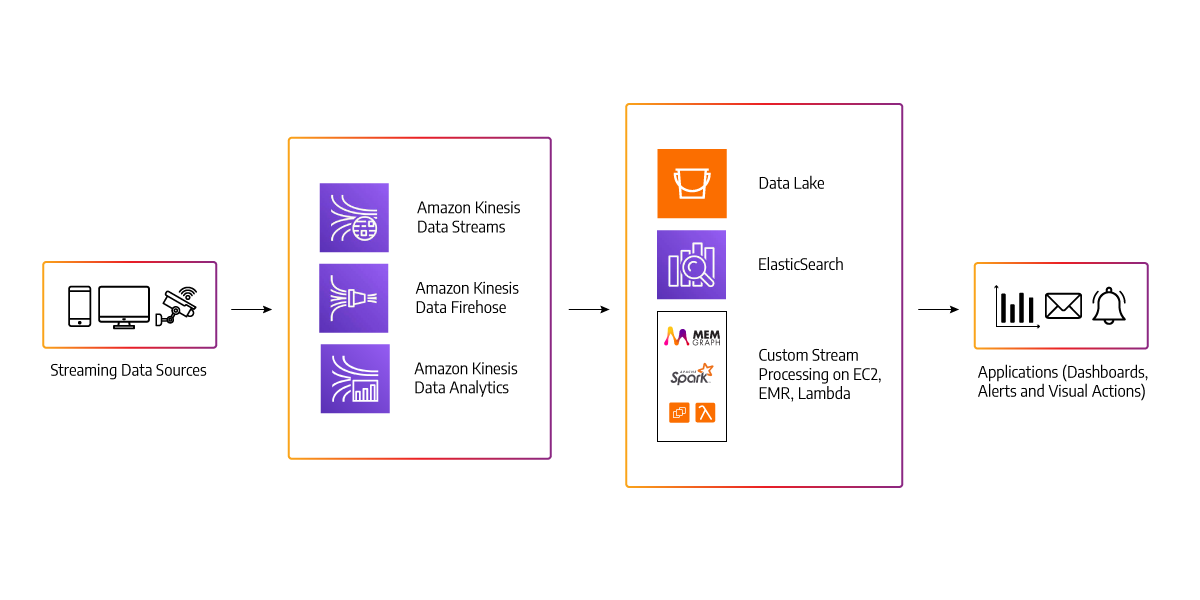
Real-time Analytics
Imagine having various front-end applications, including web browsers, mobile apps, and IoT devices, that capture a lot of user data. And let's say all of this data is gathered and sent to the Amazon API gateway.
Behind the API gateway is a real-time analytics service. The messages are pushed into the analytics service, which is subsequently pushed into Memgraph or Amazon Kinesis data streams (similar to Kafka). To process a large volume of data, you would first have to put it into AWS Kinesis data firehose and then store a copy of it in S3 bucket storage.
We'll need to process the data in real-time because we'll be getting it in real-time. We can use the Amazon Kinesis data analytics service, which can leverage Memgraph or Apache Flink to generate real-time reports and push them into the dashboard. This particular style of processing messages in real-time and generating reports is called streams or streaming architecture.
Netflix streaming
When it comes to how batches and streams are used in the industry, Netflix is a prime example of stream processing. By using Amazon Kinesis data streams to process terabytes of log data every day from each application, they are able to discover valuable information from that data.
This is what their architecture looks like:
- Multiple applications push data in the form of application logs and also VPC logs.
- The data is aggregated using Kinesis Data Streams.
- Processing is done by another application that consumes the data streams, aggregates and enriches them.
- The data is used to identify and trace application information flow across.
Fraud Detection use case
With the rise of online systems, there has been a rise in fraud. These days, common scams are faced by credit card companies, online payment systems, software as service companies, and many more. Most of these frauds are done by brute force attacks, logging in using botnet agents, etc.
These systems use batch processing, so fraud is not detected immediately. However, stream processing has enabled companies to see any fraudulent activity immediately. Any user trying to log in using fake/new Ip addresses, distinct locations shall quickly be detected by the algorithms and shall be asked to verify.
Credit cards and ATMs use stream processing to read the card details and then run algorithms that decide whether a transaction is fraudulent or not in real-time. Hence, any fraud is immediately prevented without making non-fraudulent customers wait.
IoT
More than 30 billion IoT devices will be installed by the year 2021. Such a rise in the IoT industry has also resulted in massive amounts of data. Even a tiny sensor is producing some amount of data every second.
Imagine the amount of data that billions of devices are producing in a second. Such an amount of data can be beneficial and provide valuable insights. So, there is a need for some techniques to collect, process, and analyze such data.
One such technique is batch processing, which collects data at a fixed period every 24 hours and then processes it. But it is not the most efficient method as some time-critical systems require information in real-time. Data processing for such systems is done by a technique called “Stream Processing.” Through this method, we can process the data right when its produced.
Stream processing even has applications in the healthcare industry. It helps doctors to monitor patients in real-time. The car industry is leveraging stream processing by using sensors and processing their outputs to power self-driving vehicles in real-time.
Advertising
Companies are using stream processing to improve their marketing methodologies by performing actions in real-time based on customers’ behavior. Companies can now give a specialized experience for individual users based on their interests and interactions with the system.
An example is when a new user signs up to a social media app and is immediately recommended to another user as a potential connection.
Another example is when a customer adds a food item to check out on a food delivery app, he is immediately offered a personalized discount.
One last example to understand the importance of stream processing is the recommendation systems of some websites. Whenever a user searches or clicks on a product, they are recommended a similar product in real-time.