Perform What-if Analysis of Your Network Directly in Storage Without Compromising Data Integrity
One of the most difficult jobs when deciding upon the company’s next steps is decision-making. We all faced hard decisions at least once in our lives. After weighing the pros and cons, as well as how will the outcome of a decision impact our future, we picked the best option for us and everybody around us.
On the company level, there can be much more at stake when making decisions, as they can affect dozens or hundreds of people, assets, components or software systems. Choosing the right option needs to be done with careful analysis to maximize profits and make optimal steps to preserve the environment for the people and the product.
To help make decisions, companies perform impact analyses or what-if scenarios. Based on the careful analysis of the provided data, the outcomes of certain decisions are weighed and the optimal resolution is made.
But is it really that easy?
The following article will showcase a practical example of impact analysis with Memgraph and Memgraph Lab, and how decision-making on networks can be effortless and efficient!
What is the difference between impact analysis and what-if scenarios?
In my experiences with clients, I have often heard the term “impact analysis” from people in leadership positions, whereas data scientists preferred “what-if scenarios”. So is there really any difference?
Here’s what the literature says about what-if scenarios:
“In scenario planning, a what-if scenario provides a way to consider the effects on a plan, project, or timeline if variability in factors exists. Instead of assuming each part of the process will adhere to some ideal, it involves examining the outcomes if certain things take more or less time, require more or less funding, result in unintended consequences, and so on.”
For impact analysis, the definition is as follows:
“An impact analysis (also known as change impact analysis) is a step-by-step process for determining the potential positive and negative consequences of a business decision. A company may also conduct an impact analysis to determine how they would respond to an unplanned disruptive event, such as a loss of data, a breakdown in the supply chain, or a natural disaster”.
In my opinion, you won’t be far off with any of the terms because one thing is for sure - the goal of both is to predict the outcome of a decision.
Difficulties when dealing with impact analysis in networks
Important events a platform handling impact analysis needs to be able to handle are updates and analytics on the network.
In the chemical industry, data scientists might alter the topology of the chemical plants by adding new reactors to see whether the topology yields better flow. In cloud computing, a cloud engineer might want to alter the number of provisioned resources to see whether the system achieved minimal cost with the same performance. Supply chain companies might add another line of production and see whether it maximizes their production.
Steps different industries take with what-if scenarios are:
- Do several updates on the network.
- Perform analytics.
- If the results are satisfying, continue with the updates or delete updates.
- If the results are unsatisfying, continue with the updates or delete updates.
Both updating the graph and deleting the updates are an option because, although the results might be great, the idea can be in its experimental stage, or the staff might want to explore more scenarios with the same network.
The theory of databases tells us that transactions can yield updates with an optional rollback or commit, so pure modifications to the network shouldn’t be a problem. The real question is actually, what kind of analytics needs to be performed, and are database systems capable of performing those kinds of analytics?
Database systems nowadays have various integrations with different types of data. Ride-hailing industries might use spatial data and spatial indexes to optimize the positions of taxi drivers in the city. Recording sensor data is a good use case for time series databases. Most relational databases now have functions to work efficiently with text data. However, when it comes to networks, all except graph databases fail to model any kind of efficient traversals or graph analytics in the network.
With insufficient tooling at the database level, there are only two possible workarounds:
- Clone the network and do the updates on the clone, then delete it.
- Load the network into memory, executing updates and analytics in the code.
Either way, committing changes will need to be done separately and cautiously. The first workaround sounds passable because data remains consistent, but it can double the memory and be a big problem in the case of large networks.
The second solution relies on the performance of data processing libraries, such as NetworkX, igraph, and similar. While some of them are really performant, like igraph, they still need topology to be loaded into the memory and worked with. Not only that, but if the results of the what-if scenario are unsatisfying, there needs to be a way to revert to the previous topology to try again with new modifications, and database systems are not designed to keep the transaction while there is ongoing external processing.
Solution ahead: What if you use Memgraph for your what-if scenarios?
If there was only a way to encapsulate storage and data processing. It would ease life dramatically to perform updates in the same transaction.
Fortunately, Memgraph offers a concept called query modules - execution of complex analytics procedures inside the query. Let’s look at the example below
MATCH (n)
CALL my_awesome_module.my_awesome_procedure(n)
YIELD result
RETURN result;This query also executes a procedure containing programmatic code, which allows for better expressibility directly on the database level. From simple aggregations to complex graph algorithms like community detection, everything that you can’t express with Cypher is implementable as a query module.
Furthermore, Memgraph developed Memgraph MAGE, a graph algorithm library with all the typical, streaming and even machine learning algorithms on graphs. Analytics like PageRank or centrality algorithms no longer need to be implemented inside application code, as they’re all contained in one platform - Memgraph.
If the algorithm you need is not in the library or it’s too custom to implement - you can always write your own. Memgraph supports C, C++, Python and Rust as possible interfaces for writing query modules and developing custom analytics.
How do query modules change the what-if scenario workflow? Let’s look at the query below:
BEGIN; // start of the transaction
// update 1
// update 2
CALL my_awesome_module.my_awesome_algorithm(...)
YIELD result
RETURN result;
ROLLBACK; // reverting updatesThe above flow ensures that the graph isn’t updated due to the experimental phase of testing the network topology, but it’s still yielding useful analytics. If the outcomes are satisfactory, the updates can be applied to the network by using COMMIT instead of ROLLBACK.
This workflow solves several issues:
- The graph is updated without committing the changes.
- Custom analytics are executed to show decision outcomes.
- Changes can be committed to update the graph.
- Changes can be rolled back.
- Data remained consistent at all times
- Risks are effectively minimized by running trial-and-error experiments without corrupting data
Let’s look at a practical example of what-if scenario implementation.
Showcase example with Memgraph Lab
The following example deals with a fictional chemical plant. The goal is to optimize the topology to yield maximum flow through the plant. All queries were run in Memgraph’s visualization tool, Memgraph Lab, which offers custom styling for maximum visibility over the network. The following query retrieves the initial topology of the chemical plant.
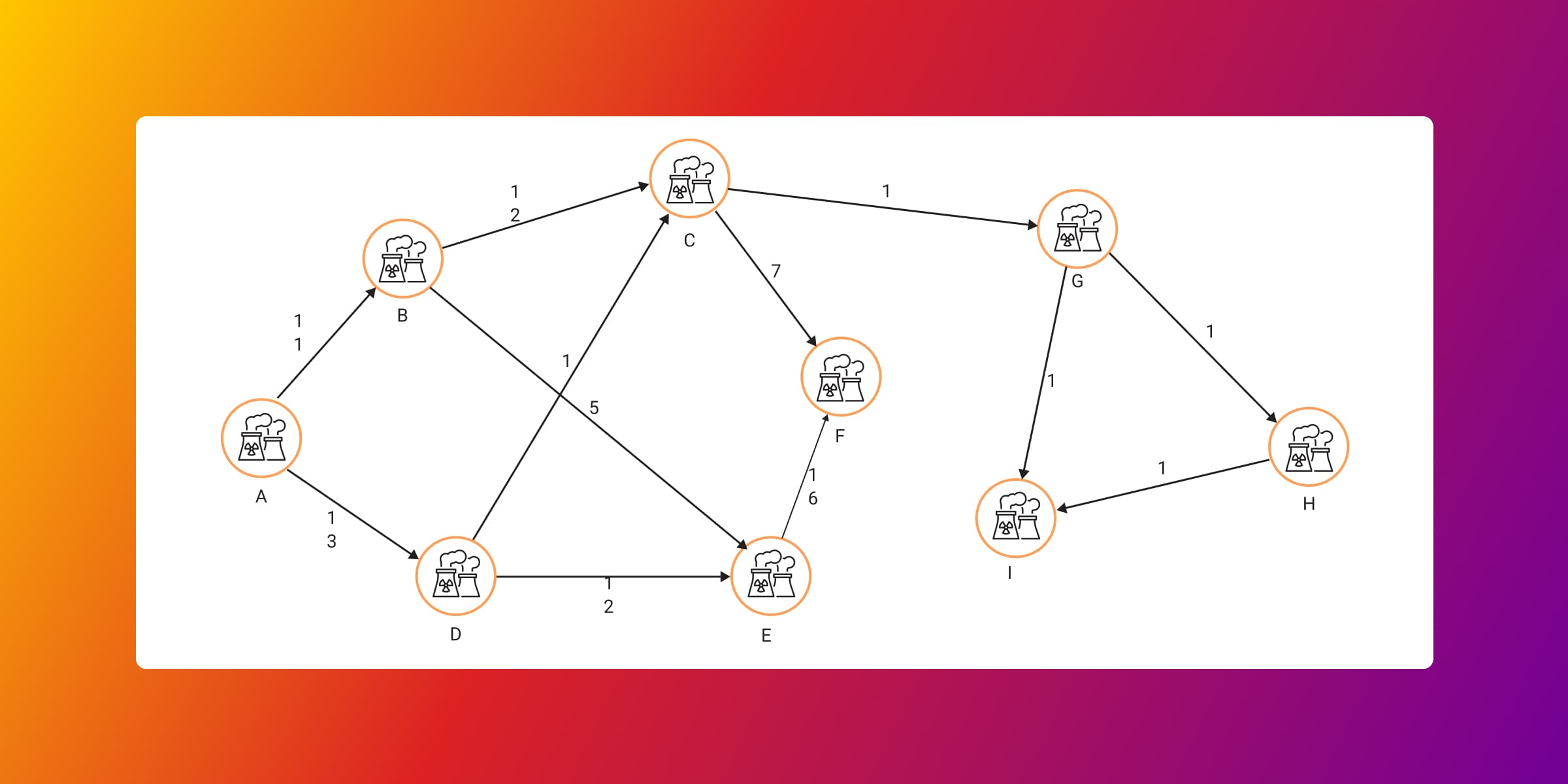
MATCH (n)-[r]->(m) RETURN n, r, m;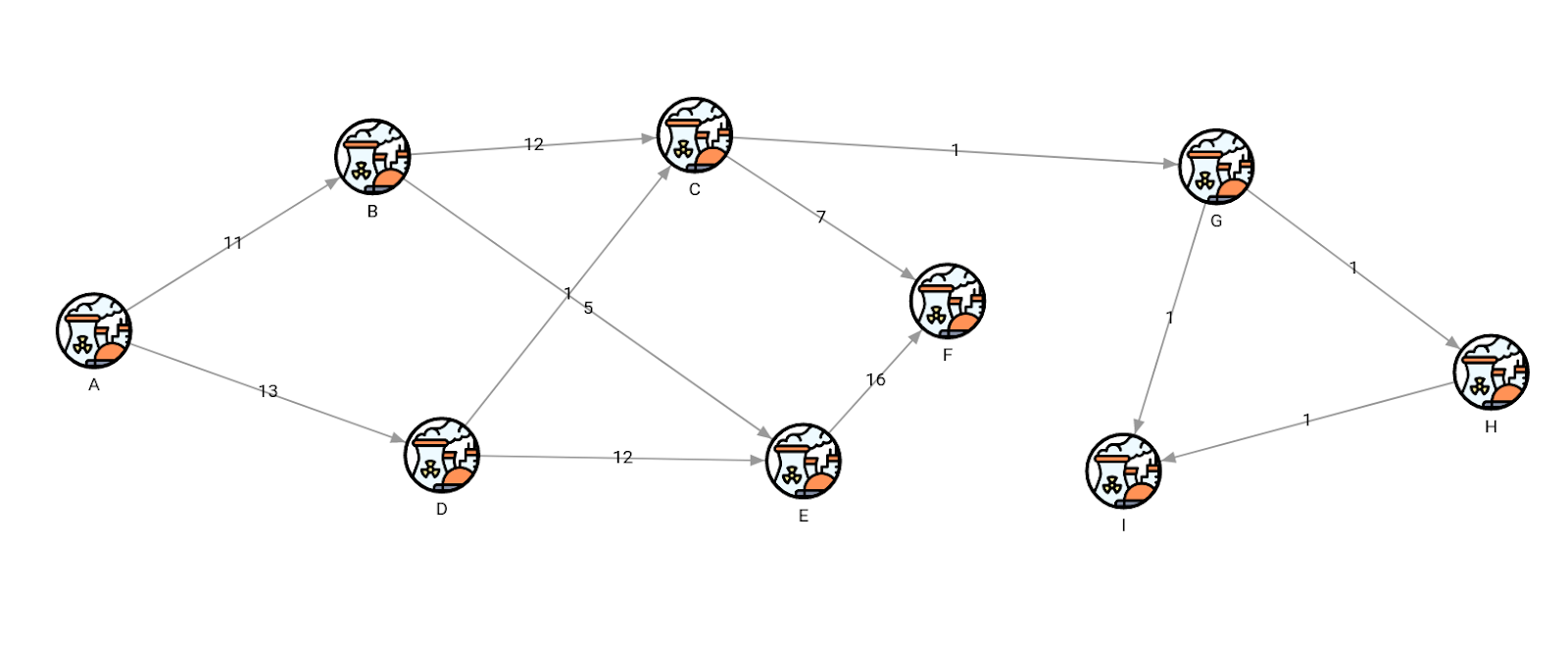
Each chemical plant component is named using a letter of the alphabet, and the relationships connecting the components symbolize pipes allowing a certain amount of flow displayed as numbers on the picture.
The first transactional query will update the graph by adding an additional plant component and show how the topology changed, then roll back the changes, so the change isn’t actually visible in the data.
BEGIN;
MATCH (i:I) MERGE (i)-[:CONNECTED_TO {flow: 1}]->(:J);
MATCH (n)-[r]->(m) RETURN n, r, m;
ROLLBACK;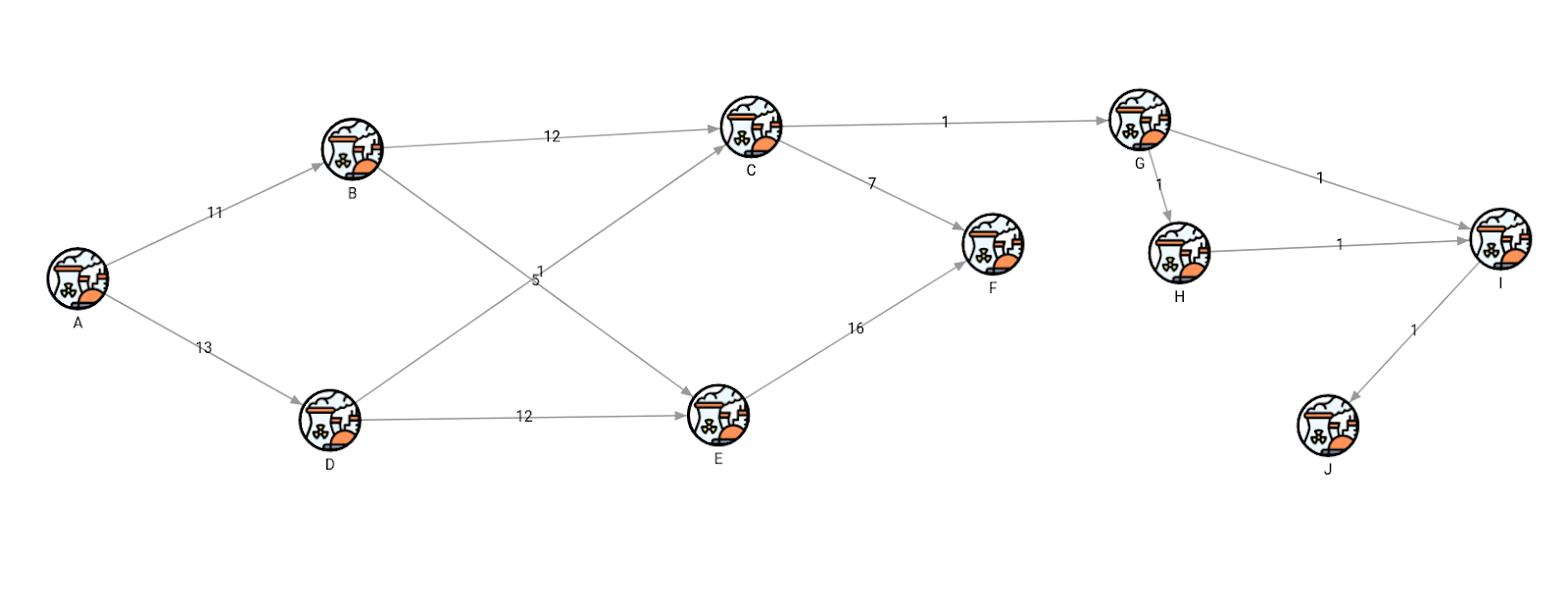
Because changes were rolled back, the original topology stays the same as in its initial state.
MATCH (n)-[r]->(m) RETURN n, r, m;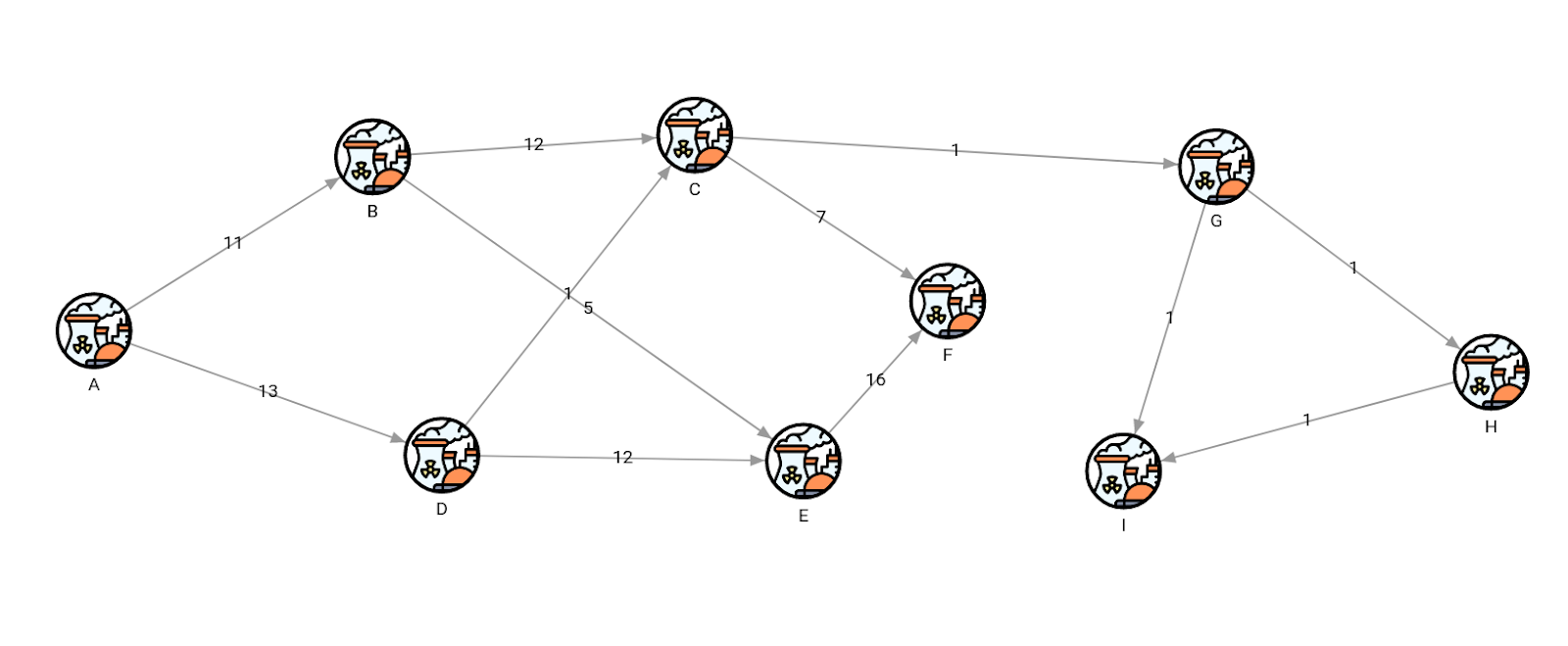
And that’s how queries using transactions operate. Let’s now do an impact analysis or what-if scenario.
In the following example, we will analyze flows from one point in the network for another. One of the more familiar graph algorithms used to calculate the flows is called maxflow. The maxflow algorithm in the query below will return the maximum flow of resources from component A to component F.
MATCH (a:A), (f:F)
CALL max_flow.get_flow(a, f, “flow”) YIELD max_flow
RETURN max_flow;
If you want to find out more about the Maxflow algorithm, it can be found in MAGE graph algorithm library along with many other graph algorithms.
Let’s look at the source of the network, which is the component A. It has 2 outgoing flows of 13 and 11, which would ideally total for a maximum flow of 24.
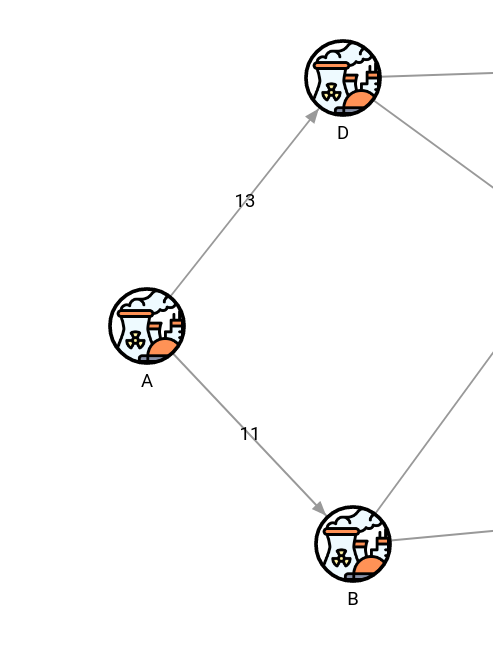
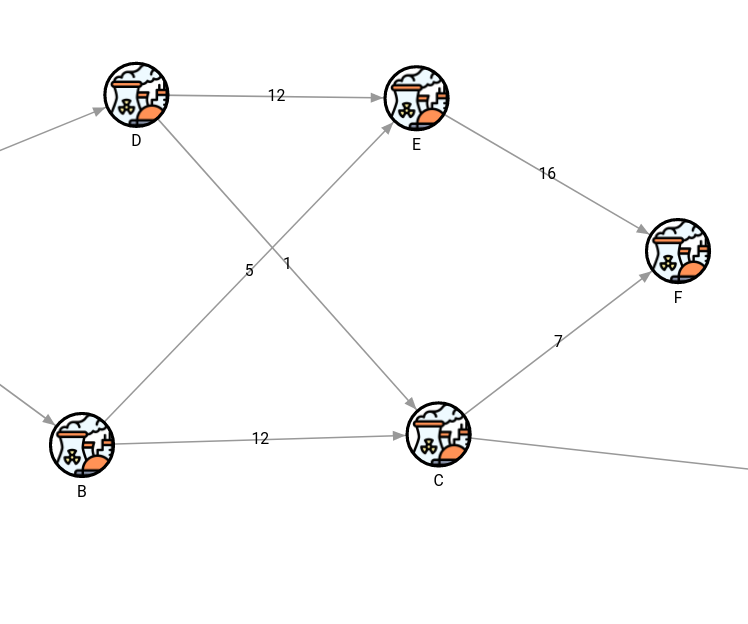
The algorithm calculated that the current maximum flow is 23. Surely, we can do a better job of increasing the flow to 24. However, it is not a straightforward job and might require trial and error until we get it right.
After inspecting the network, we have a potential solution to the problem by doing an upgrade on the relationship between components E and F. We will increase the flow between those nodes by 1, so the total input to node F equals 24 (17 from node E + 7 from node C).
BEGIN;
MATCH (e:E)-[r:CONNECTED_TO]->(f:F)
SET r.flow = 17;
MATCH (a:A), (f:F)
CALL max_flow.get_flow(a, f, “flow”) YIELD max_flow
RETURN max_flow;
ROLLBACK;
Once the flow between components E and F is upgraded, the maximum flow increased to 24, which is the full flow from the source! Because this upgrade solved the problem, the query is run again, but this time the update is committed and the stakeholders are informed about the positive impact on this part of the plant.
BEGIN;
MATCH (e:E)-[r:CONNECTED_TO]->(f:F)
SET r.flow = 17;
MATCH (a:A), (f:F)
CALL max_flow.get_flow(a, f, “flow”) YIELD max_flow
RETURN max_flow;
COMMIT;Let’s upgrade the relationship between components A and D to maximize the flow yet again.
BEGIN;
MATCH (a:A)-[r:CONNECTED_TO]->(d:D)
SET r.flow = 20;
MATCH (a:A), (f:F)
CALL max_flow.get_flow(a, f, “flow”) YIELD max_flow
RETURN max_flow;
ROLLBACK;However, the flow remains the same. So this upgrade did not actually yield better results, and there is no reason to commit it as different or more updates in the network are necessary to maximize the flow.

After noting the trial and rolling back the topology, the data is ready for more examples and experiments until we get a successful topology, and then actually update the plant on the field.
And that’s basically it! With a few commands, a little bit of knowledge about database transactions, and storage coupled with processing power, we are able to do complex impact analytics and what-if scenarios without any fear of losing or corrupting the data. How cool is that?
Conclusion
Although graph databases are the right tool for doing impact analysis and what-if scenarios on networks, what often makes the job difficult is putting analytics and storage in distinct buckets. Memgraph as a platform includes custom analytics on graph storage, minimizing the risks by doing quick and efficient network analysis.
Check out how Memgraph can also help with real-time analysis for even quicker decision-making. For any further questions, feel free to join our Discord server, and we’ll be happy to talk to you about further analyzing your network to optimize it, mitigate even more risks, and improve your business.