
Graph Database vs Relational Database
Choosing between a relational database and a graph database comes down to the questions you need to answer later. If your application mostly creates, updates, and looks up well-structured records, a relational model is often the right default. If you need to follow many hops across users, accounts, devices, services, or documents, a graph model usually maps the problem more directly.
That distinction matters for Memgraph users building fraud detection, access-control analysis, dependency mapping, GraphRAG, or other traversal-heavy workflows. This guide compares the two models, shows how Cypher differs from SQL, and ends with practical signals for when each database type fits best.
How Graph Databases Differ from Relational Databases
A graph database stores entities as nodes and connections as relationships.
Graph databases based on the labeled property graph model consist of four core parts:
- Nodes - the main entities in a graph. They are also sometimes referred to as vertices or points.
- Relationships - the connections between those entities. Sometimes they are referred to as edges or links.
- Labels - categories that group similar nodes together.
- Properties - key/value pairs stored within nodes or relationships.
Nodes and relationships define the graph itself. Labels and properties add the context that makes the graph useful for querying.
Graph databases commonly use Cypher, a declarative query language for property graph databases. It is popular because it lets you describe patterns in the graph directly instead of rebuilding those connections through joins.
Relational databases store data in tables made of rows and columns. Every row is a record, and every column is an attribute of that record. Relational databases rely on a predefined schema of tables that are connected through primary and foreign keys. They use Structured Query Language (SQL) to query, manage, and manipulate data. Relational databases are widely used in transactional applications such as e-commerce, banking, and inventory systems.
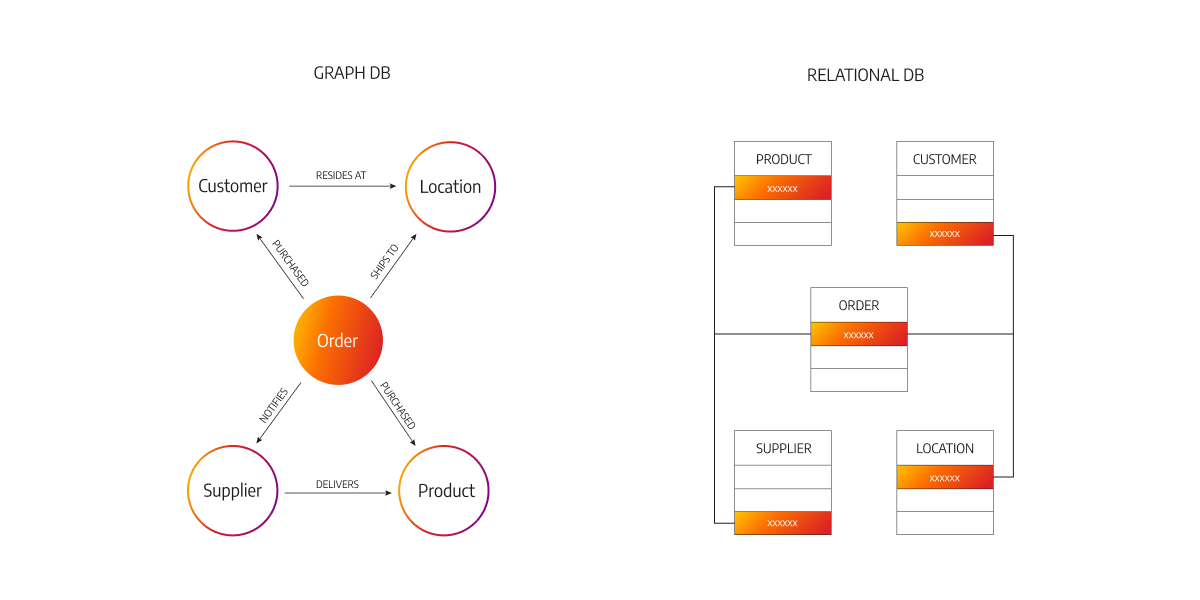
The image below shows the difference between the graph model and the relational model for the order management dataset.
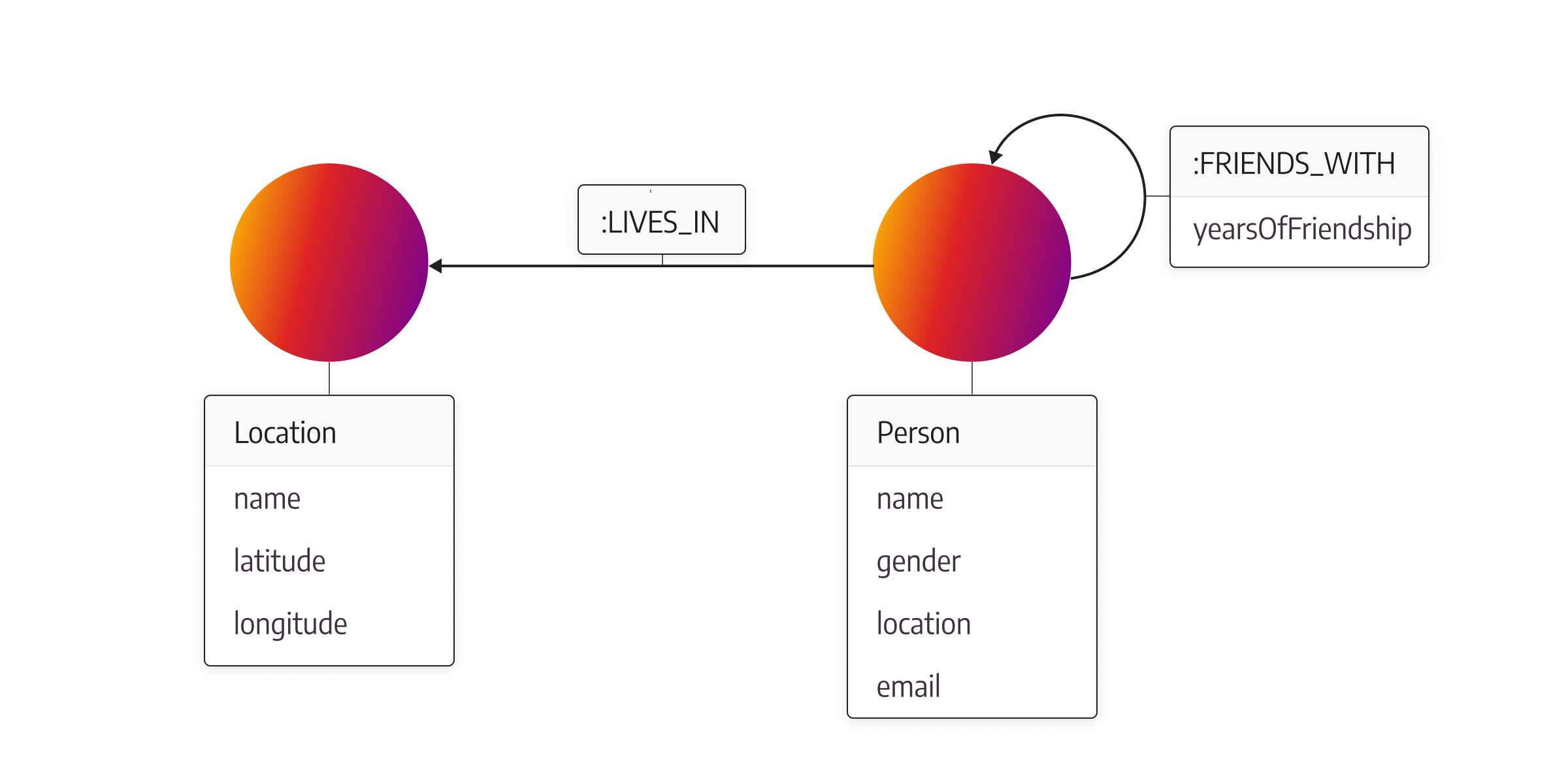
The image below shows a social network graph data model where nodes represent people in different social groups and their connections. Every person is represented with a node labeled Person. These nodes contain the properties name, gender, location, and email. The relationships between people are of the type FRIENDS_WITH and contain a yearsOfFriendship property to specify the duration of the friendship. Each person is assigned a location through LIVES_IN relationships with nodes labeled Location.
Each person is connected to other people through friendships, and a relational database would model that relationship in separate tables and join paths. If new kinds of connections appear, the table structure usually has to change as well. That is why relational databases are often less natural for relationship-first use cases where the main question is not just what the data is, but how it connects.
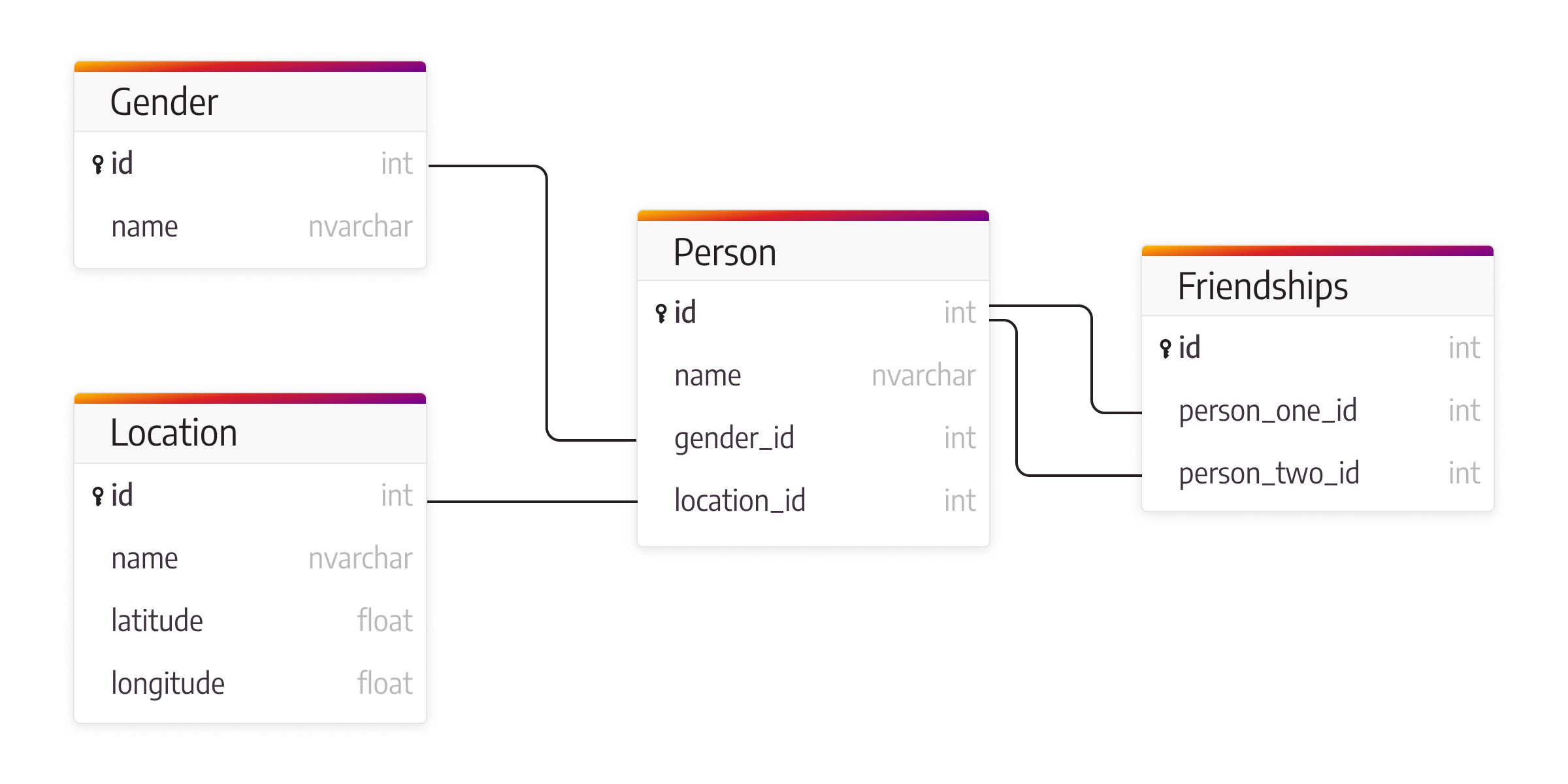
This is a simple example, but it shows the trade-off clearly. In relational databases, a new column must be added for each additional attribute, while graph databases can usually absorb new properties and relationship types with less schema friction.
Cypher vs. SQL
Cypher is a query language designed for working with graph databases. It is well suited to queries over highly connected data, especially when you need to express paths, neighborhoods, hierarchies, and many-to-many relationships. You can think of Cypher as mapping sentence structure to graph patterns: nouns become nodes, verbs become relationships, and modifiers become properties.

SQL is the standard language for relational databases. It is used to create tables, query them, and insert, update, or delete rows. Most relational database systems use SQL, including MySQL, Oracle, Microsoft SQL Server, PostgreSQL, and SQLite.
The difference between Cypher and SQL can be shown through an example dataset containing the genealogy of some ancient French kings around the 8th century AD from the MySQL Blog Archive. The easiest way to represent the dataset is with a graph:
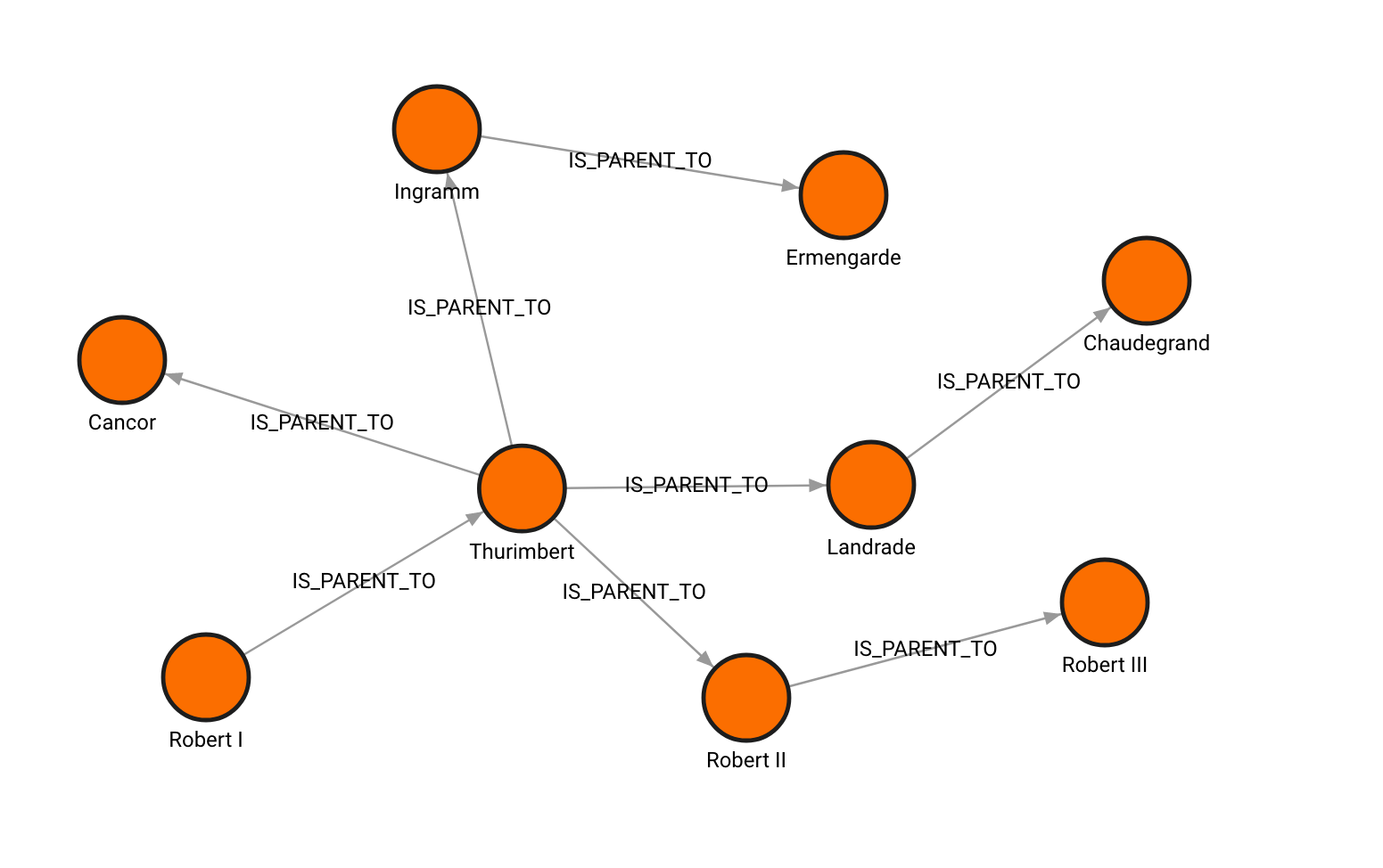
With breadth-first search and depth-first search, it is possible to obtain the descendants in a specific order. Here are the SQL and Cypher queries to find all descendants of Thurimbert:

To run the breadth-first search, that is, find all children and direct descendants first, grouped, use the following queries:

For the depth-first search, use the following queries:

This dataset is naturally hierarchical, which is why it fits a graph model well. Cypher keeps the traversal pattern in the foreground, while SQL keeps the table structure in the foreground. SQL can answer the same question with recursive common table expressions, but those queries usually become harder to read and maintain as the number of hops grows. On relationship-heavy workloads, Cypher is often easier to reason about and adapt.
Overall, the main differences between Cypher and SQL stem from the different data models they target. Cypher is designed for connected data and relationship traversal. SQL is designed for tabular data and set-based operations over a predefined schema. That difference matters more than syntax preference: the best query language is usually the one that matches the way your data is stored.
When to Use a Graph Database
Graph databases are not the right answer for every problem. In many systems, a relational database remains the better default. To decide whether a graph database is worth it, start with three questions.
1. Is Your Data Highly Connected?
Graph databases are built for data with an intrinsic need for relationship analysis. In relational databases, complex relationships are reconstructed through joins across multiple tables. That works well for many business applications, but the queries become harder to write and reason about when you repeatedly cross many tables to find indirect connections.
If the main value in your application comes from traversing those connections, a graph database is often a better fit. If the connections are secondary and the workload is mostly transactional, a relational database is usually the better choice.
In the social network example, if you remove most of the person-to-person relationships, the graph becomes much less interesting. At that point, the remaining structure starts to look more like ordinary record storage, which is where relational databases shine.
2. Is Retrieval More Important Than Storage Simplicity?
Graph databases are optimized for relationship-heavy retrieval and analysis. They are useful when you need to uncover patterns that are difficult to see in tables alone, such as communities, central entities, suspicious paths, or dependency chains.
In the social network example, if the data is stored only for logging interactions and not for later analysis, a graph database does not add much value. But if you want to identify the most influential users, recommend new connections, or group similar users into communities, graph algorithms such as PageRank, betweenness centrality, or node2vec become useful.
If your retrieval layer now includes graph-aware AI workflows, that signal is even stronger. GraphRAG pipelines, agent memory, and entity resolution workloads often depend on traversing connections between people, documents, tickets, files, or services before ranking the final context.
3. Does Your Data Model Change Often?
Graph databases are well suited to data models that evolve over time. Because they focus on entities and relationships instead of rigid table layouts, they usually handle new node properties and relationship types with less upfront migration work.
There are still clear advantages to a predefined and consistent table structure. Developers know how to work with relational schemas, and that familiarity matters. If you are storing stable business records such as names, dates of birth, and locations, without frequently adding new fields or changing how records connect, relational databases remain the simpler option.
A graph database is often a good fit if:
- Additional attributes will be added over time.
- Not all entities will have the same attributes.
- Relationship types are likely to expand.
To make the decision more concrete, here are a few use cases where graph databases often fit well.
Insurance Fraud Detection
Graph databases help investigators follow connections between people, claims, vehicles, addresses, devices, and service providers. That makes it easier to spot suspicious clusters, repeated patterns, and hidden relationships that are difficult to uncover with table joins alone. For this kind of relationship-heavy analysis, graphs are often a better fit than a purely relational model. See fraud detection in insurance for a concrete example.
Network Resource Optimization
With a graph database, you can model dependencies across supply chains, cloud infrastructure, chemical engineering systems, energy grids, and similar networks. That makes it easier to analyze routes, bottlenecks, and critical points in the topology. If the key question is how one part of the network affects another, a graph is often easier to query than a set of normalized tables. See how teams manage networks with graph technology.
Identity and Access Management
Access-control problems are naturally graph-shaped: users belong to groups, groups inherit roles, roles grant permissions, and permissions apply to resources. A graph model makes those paths explicit, which helps when you need to answer questions such as "Who can reach this resource through inherited roles?" or "What changed after this permission update?" Learn more about identity and access management with graphs.
When Not to Use a Graph Database
A graph database is not always the best solution. If your workload frequently scans most of the dataset by property values, bulk analytical systems or relational databases may be more efficient.
Databases are often used to look up information stored in key/value pairs. If the main job is storing user information and retrieving it by name or ID, a graph usually adds unnecessary complexity. If other entities are involved and the value comes from mapping many connections between them, then a graph can still help.
If most queries return a single node through a simple identifier lookup, skip graph databases. The same goes for models dominated by very large attributes such as BLOBs, CLOBs, or long text fields. Those can be linked from a graph when relationships matter, but they do not become graph problems on their own.
Back to the social network example: if each person had a long biography that needed to be stored and retrieved as a document, a graph would not be the obvious answer. If you also needed to connect those biographies to people, organizations, topics, and events mentioned inside them, then the graph part of the model would start to justify itself.
Choosing the Right Database
Use a relational database when your workload is mostly transactional, tabular, and driven by a predictable schema. Use a graph database when the main value comes from traversing relationships, following multi-hop paths, and evolving a connected model over time.
If that second path sounds familiar, explore graph use cases and the Memgraph docs to see where it fits. If you are comparing graph databases specifically, the Memgraph vs. Neo4j: Benchmark Performance Comparison will showcase how Memgraph compares to Neo4j.
Further Reading
- Webinar: Where Are the Tables? Demystifying Graphs for Relational Thinkers
- Webinar: From Tables to Knowledge Graphs: SQL2Graph for GraphRAG
- Blog: How to Use SQL2Graph Agentic Migration Tool: A Step-by-Step Guide
- Blog: From SQL to Graph: 5 Questions to Ask Before You Get Started
- Blog: SQL2Graph Agentic Migration: From Relational Thinking to Graph Reasoning