
RAG and Why Do You Need a Graph Database in Your Stack?
So you’ve heard about Retrieval-Augmented Generation (RAG) and how it supercharges Large Language Models (LLMs) like ChatGPT. Sounds great, right?
But then someone drops this bomb: “You need a graph database in your stack.” And you're thinking, Why? Can’t I just use a spreadsheet, a document store, or literally anything else?
If you’re serious about making RAG work for your data, a graph database is a must-have. Here’s why.
What Does RAG Actually Do?
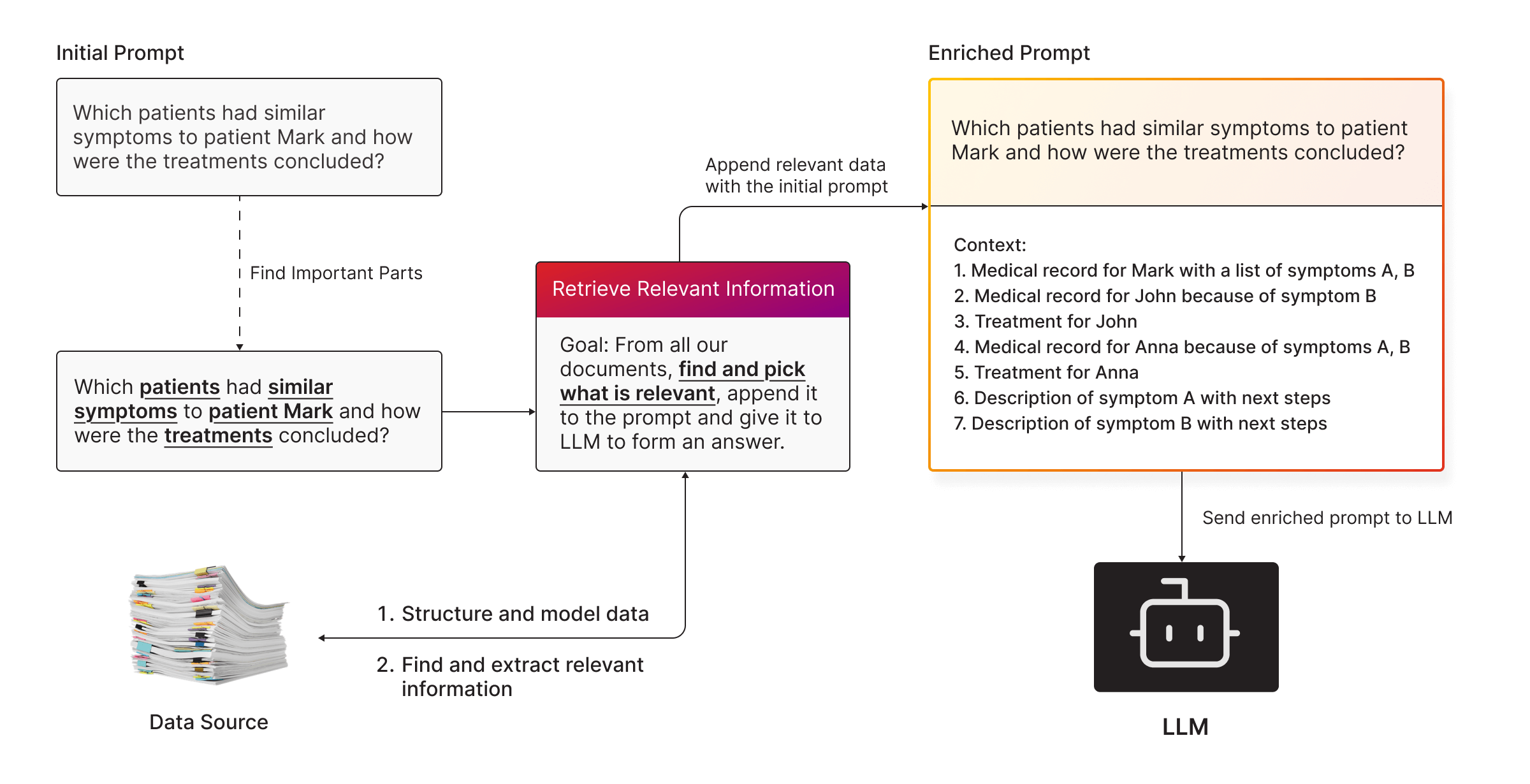
RAG is like giving your LLM a cheat sheet. Instead of expecting the LLM to know everything, you give it relevant info from your own data. Here’s the workflow:
- You ask a question. Example: “Which customers bought product X and also subscribed to service Y?”
- The system retrieves the relevant data. It searches your data for anything that can help answer the question.
- The data is appended to your prompt. Now, when the LLM generates its response, it has all the context it needs to give a precise answer.
Simple, right? But here’s the catch:
THE BETTER YOUR DATA RETRIEVAL, THE BETTER YOUR RESULTS!
Otherwise, it is garbage in, garbage out. And that’s where graph databases come in.
What’s a Graph Database?
A graph database is a way to store and query data that’s all about relationships. Instead of rows and columns (like a spreadsheet) or flat documents, you have:
- Nodes. The "things" in your data (e.g., customers, products, transactions).
- Edges. The connections between those things (e.g., "Customer A bought Product X").
It’s called a graph because the data looks like a web of connected dots—a graph structure.
Why is This Different?
In a regular database (like a relational database), relationships are more like a footnote. They’re there, but you have to jump through hoops to query them efficiently. In a graph database, relationships are front and center, and querying them is blazing fast.
Why Do You Need a Graph Database for RAG?
When you’re building a RAG system, you’re not just looking for single pieces of data. You’re looking for connections between data. And that’s where graph databases shine.
Here’s why you need one:
1. Relationships Matter
Most real-world questions aren’t just about one thing—they’re about how things are connected.
“Which users liked Product X and also referred a friend who subscribed to Service Y?”
Now, with a graph database, you can easily traverse those connections—users → referrals → subscriptions—without writing a novel-length query.
In a traditional database? Good luck joining 20 tables just to get your answer.
2. Multi-Hop Reasoning
Let’s say you’re working with customer data, and you want to find patterns across multiple steps:
Customer → Purchase → Product → Reviews.
A graph database can “hop” through these relationships in milliseconds. This is called multi-hop reasoning, and it’s critical for RAG because LLMs thrive on context-rich data.
Without a graph database, you’d be stuck piecing together these hops manually, and the process would be painfully slow.
3. Dynamic Data Updates
In the real world, your data changes all the time. New customers, new transactions, new connections. Graph databases can handle these updates in real time.
RAG systems need up-to-date context. A graph database ensures that when you ask a question, you’re querying the latest data—not something outdated.
4. Efficient Navigation
Graph databases don’t waste time searching through irrelevant data. Instead, they zero in on the specific “neighborhood” of nodes that matter for your query.
Imagine searching for a book in a library. A traditional database is like flipping through every book until you find the right one. A graph database is like being handed a map to the exact aisle, shelf, and row.
5. Algorithms for Context
Graph databases come with built-in algorithms that make finding relevant data easier. In our case, with Memgraph, it comes with:
- Community Detection (e.g., Louvain): Find clusters of related nodes.
- PageRank to prioritize important nodes (like Google ranking websites).
- Graph Traversals to explore connections like 1-hop neighbors or deep paths.
These tools help your RAG system surface the most relevant information before sending it to the LLM.
Why Not Use Something Else?
You might be wondering, ”Can’t I just use a relational database, a document store, or even a search engine like Elasticsearch?”
Sure, but here’s what happens:
- Relational databases. They’re fine for flat, structured data but choke when queries involve multiple relationships. Joining tables over and over again is a performance killer.
- Document stores: Great for storing blobs of unstructured data, but they don’t understand relationships.
- Search engines: Fantastic for keyword searches, but they can’t do multi-hop reasoning or relationship-based queries.
A graph database isn’t just faster—it’s built for the kind of relationship-heavy queries that RAG thrives on.
Real-World Example: Graph Databases in Medical Insights
Let’s say you’re managing patient data for a healthcare system. A provider asks:
"Which patients had symptoms similar to Patient Mark, and how were their treatments concluded?"
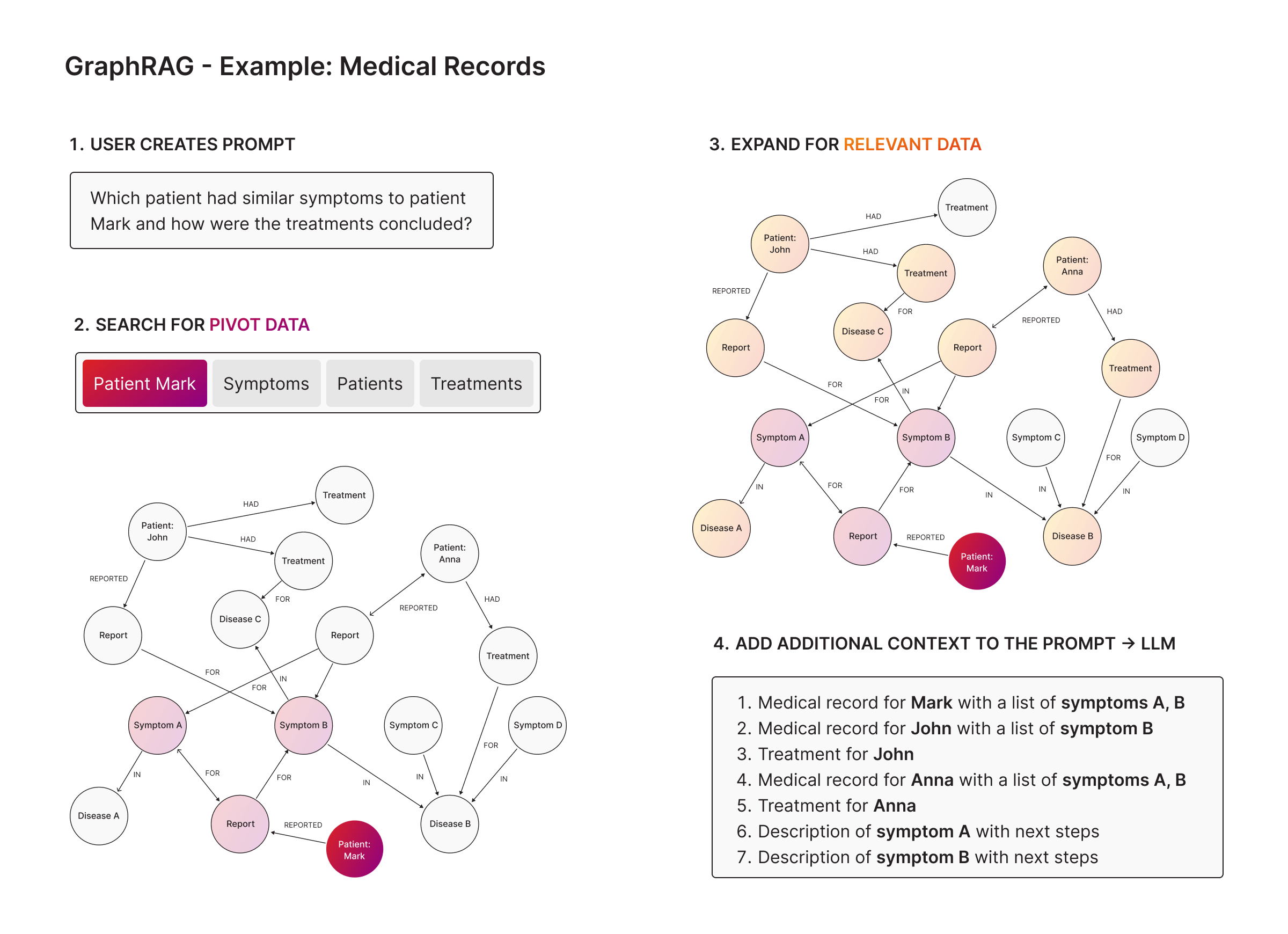
With a Graph Database:
- Start with Patient Mark (a node) and his symptoms.
- Traverse to other patients with matching symptoms via relationships in the graph (edges).
- Expand to include treatments and outcomes linked to these patients.
- Add relevant context like medical records, symptom descriptions, and treatment notes.
The whole query runs in milliseconds.
Without a Graph Database:
You’d have to stitch together data from multiple tables, probably write complex SQL joins, and wait… and wait… and wait.
TL;DR
If you want to build a RAG system that’s fast, flexible, and context-aware, you need a graph database. Here’s why:
- It’s all about relationships. Real-world questions are connection-heavy, and graph databases excel at traversing them.
- Multi-hop reasoning is easy. Hop through nodes like a pro to extract rich, meaningful data.
- Real-time updates keep you current. Perfect for dynamic data environments.
- Efficient navigation saves time. Graphs focus only on what matters for your query.
- Built-in algorithms improve relevance. Community detection, PageRank, and traversals are game-changers.
So, if you’re serious about making RAG work, a graph database isn’t optional—it’s essential. Your data (and your users) will thank you.