
Decoding Vector Search: The Secret Sauce Behind Smarter Data Retrieval
Memgraph recently released vector search as a new feature. We’ve talked about it here Simplify Data Retrieval with Memgraph’s Vector Search.
I wanted to take a moment and go back to explain the backstory to vector search and why it’s important from a perspective of a technical content writer who’s job is to translate engineerish into plain English. Vector search is growing in popularity due to its role in AI-driven applications, semantic search, and the need to process massive amounts of unstructured data effectively.
What Problem Are We Addressing with Vector Search?
- Dependence on exact-keyword matches
- Traditional search methods rely on exact terms or keywords, often missing contextually similar results.
- Limited to structured data
- Querying unstructured data like text, images, or video in a meaningful way has been a significant challenge.
- Scalability for high-dimensional data
- Handling vector embeddings for complex, high-dimensional data like images or video requires specialized techniques.
With the rise of large-scale, unstructured datasets and modern AI applications, vector search opens up the ability to query and analyze data contextually, overcoming these limitations.
Why Did We Build This Feature?
Vector search has been one of the most highly requested features, driven by customer demand. By implementing it, we:
- Offered more value for customers
- Vector search enables powerful features like contextual querying, semantic filtering, and advanced recommendations.
- Support LLM and knowledge graph use cases
- As Memgraph expands into the GenAI and GraphRAG ecosystems, vector search becomes a foundational tool for integrating LLM-powered applications.
- Enhance semantic search
- The good think about vector search is that, unlike traditional text search, it dentifies non-obvious results. For example, you can find similar data points even when exact terms don’t match.
However, there’s a trade-off—vector search can yield non-deterministic results. As new data is added, the results for the same query vector might significantly change due to shifts in the vector space.
What Are Vector Embeddings and Why Are They Used?
The magic lies in embedding models powered by neural networks. Vector embeddings are mathematical representations of data (like text, images, or audio) in a high-dimensional space. They transform unstructured data into vectors, enabling machines to process and understand it. Essentially, embeddings allow machines to grasp the context and meaning of data, making it computationally manageable and useful.
For example:
In natural language processing (NLP), embedding models like Word2Vec or BERT represent words as vectors, capturing their semantic meaning. For instance, "king" and "queen" may have similar vector representations because they share related concepts. In image processing, embeddings represent visual features of images, making them comparable in terms of similarity. For instance, two images of cats might produce similar embeddings despite differences in color or pose.
Take ChatGPT as an example. It has a vocabulary of roughly 50,000 tokens, where each token is represented by a vector of dimensionality around 50,000. These embeddings encode tokens in their semantic context. This transformation makes it possible for machines to "understand" meaning and relationships, enabling computations like addition, subtraction, or similarity comparison.
Why high-dimensional embeddings?
They capture subtle relationships between data points. For example, in a movie recommendation system, vectors for "action-packed" and "adventure-filled" genres might overlap in many dimensions, enabling precise, context-aware suggestions. However, the trade-off is that higher dimensionality demands more memory and computational power.
Embeddings vary in dimensionality based on model complexity. While some models work with lower-dimensional vectors (e.g., 380 dimensions), others, like ChatGPT, use much larger dimensions to achieve higher precision. Higher-dimensional embeddings provide greater precision but require more memory and computational power.
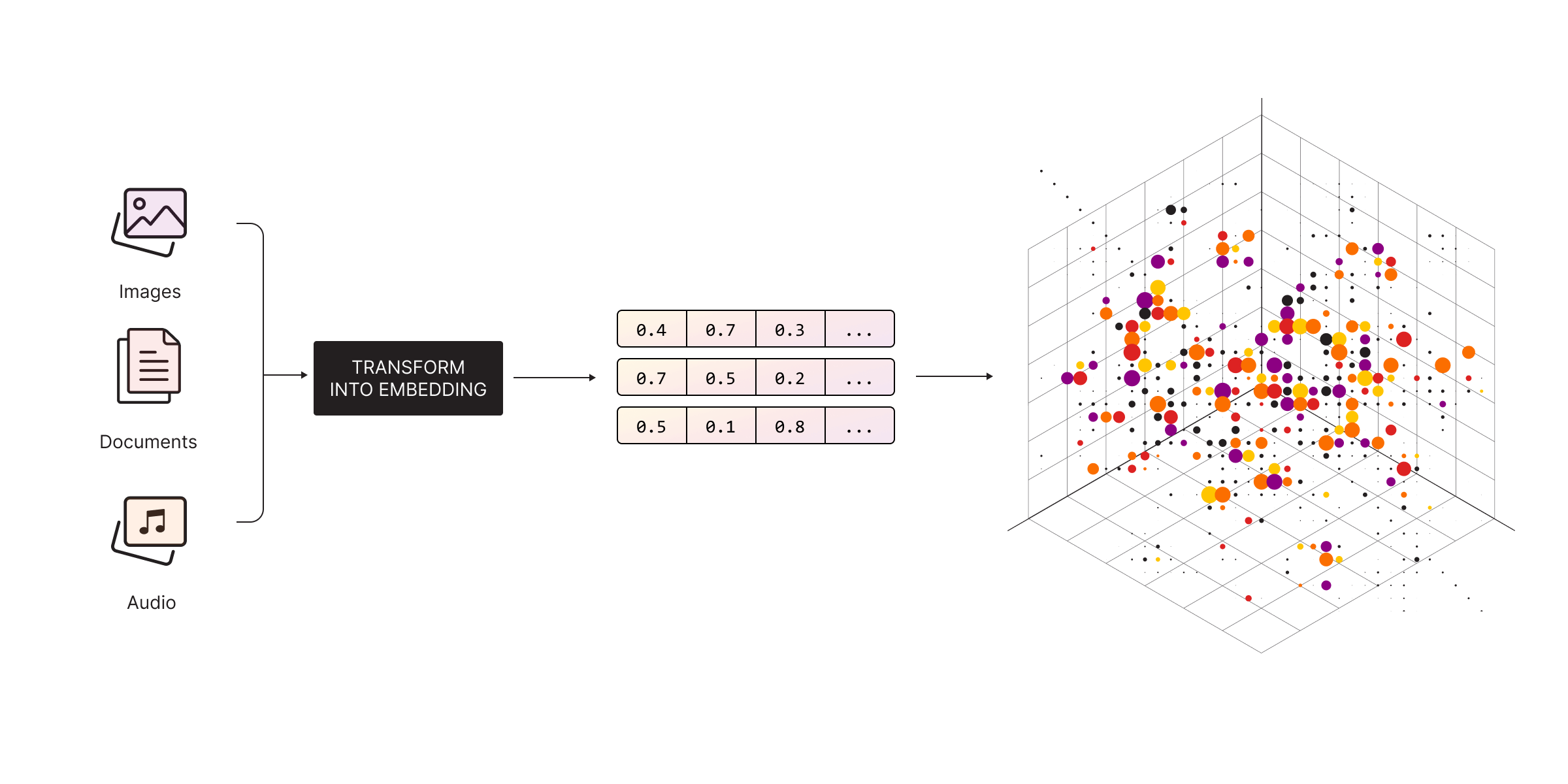
You following so far? 😀
Why Is Vector Search Useful in the Context of Pivot Search?
Pivot search involves querying data with multiple criteria or perspectives, and vector search enhances this by allowing:
- Contextual/semantic Querying. Finds nodes or records that are contextually similar rather than exact matches.
- Cross-domain connections. In a graph database, vector search can connect seemingly unrelated entities by their semantic meaning.
- Fuzzy search. Identifies matches despite minor errors, typos, or misspellings in the search query.
- Recommendation systems. Enables the creation of advanced systems for recommending contextually relevant items.
For example, imagine an e-commerce platform using a graph database for a recommendation engine. A user searches for "red running shoes." Vector search enables results to include contextually relevant items, such as "maroon athletic sneakers," which might not have exact keyword matches but are similar in meaning.
Here’s the catch…
In a large graph, vector search retrieves relevant data points based on their positions in vector space. However, poor data modeling could lead to missed nodes or connections, misdirecting the search. For instance, in a fraud detection use case, overlooking critical relationships between accounts could lead to incomplete analysis. This highlights the critical role of data modeling in ensuring search accuracy and relevance. By combining proper schema design with semantic filtering, you can maximize precision and uncover meaningful connections.
Pros and Cons of Using Vector Search for Knowledge Retrieval
- Go beyond exact matches to uncover hidden patterns and relationships.
- Combine vector similarity with graph relationships for richer queries.
- Applicable to diverse fields like recommendation systems, fraud detection, and knowledge retrieval.
- Handle large-scale unstructured data in real-time.
Let’s go over to cons.
- Requires significant computational and storage resources for high-dimensional vector data.
- Approximate methods used for scalability can, potentially, lead to less precise results.
- Improperly structured data can lead to inaccurate or irrelevant search results. (This can’t be overstated—data modeling is crucial!)
To mitigate these challenges, hybrid approaches often combine vector search with traditional methods to refine results. For example, vectors filter initial results, while exact matching refines precision. Memgraph also allows you to combine different types of pivot search and relevance expansion for more accurate knowledge retrieval. This approach works hand-in-hand in building GraphRAG-based solutions, where vector search complements real-time graph traversal.
Next Steps and Further Reading
Explore Memgraph’s vector search capabilities and learn how to use them in real-world applications. Whether you’re building a recommendation engine, fraud detection system, or AI-powered chatbot, Memgraph equips you with the tools you need to build GraphRAG solutions.
- Memgraph vector search tutorial to find movies based on their plots or descriptions
- Docs: Memgraph Vector Search
- Docs: Memgraph GraphRAG